目录
一.思路模型见文末名片,比赛开始9.7晚上第一时间更新
二.国赛常用算法之随机森林
3.思路获取见此
一.思路模型见文末名片,比赛开始9.7晚上第一时间更新
二.国赛常用算法之随机森林

# -*- coding: utf-8 -*-
"""
@author: Administrator
"""'''step1 调用包'''
import pandas as pd
from sklearn.model_selection import train_test_split
#随机森林
from sklearn.ensemble import RandomForestClassifier
#调用准确率计算函数
from sklearn.metrics import accuracy_score'''step2 导入数据'''
data = pd.read_excel('data_virus.xlsx')'''step3 数据预处理'''
# 把带类标号数据(用于训练和检验)
# 和待判(最后5行)数据分开
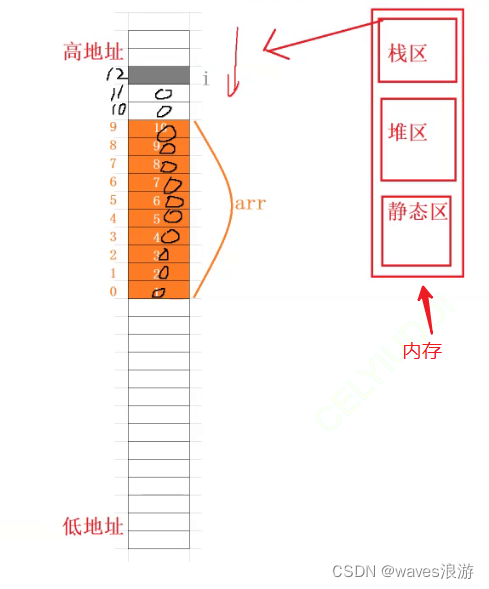
data_used = data.iloc[:112,:]
#Python从0开始计数,故上一行代码从第0行取到第77行
#共提取了112行。#最后5行为待判集合
data_unused = data.iloc[113:,:]'''step4 划分数据集'''
#(将带类标号数据#划分为训练集(75%)
#和检验集(25%)#将类别列和特征列拆分,
#便于下面调用划分函数
y_data=data_used.iloc[:,0]
x_data=data_used.iloc[:,1:]#调用sklearn中的函数划分上述数据
x_train, x_test, y_train, y_test = train_test_split(x_data,y_data,test_size=0.25,random_state=0)'''step5 模型计算(训练、检验、评价)'''
#step5.1 训练模型
model_RF = RandomForestClassifier()
model_RF.fit(x_train, y_train)#step5.2 检验模型
pred_test = model_RF.predict(x_test)#step5.3 模型评价(准确率)
#这里y_test为真实检验集类标号
#pred_test为模型预测的检验集类标号
#比较二者即可得到准确率
acc_test = accuracy_score(y_test,pred_test)
print('检验准确率为:',acc_test)'''step6 预测结果'''
#模型训练完,检验效果满意,即可对最后5行
#未知类别样本进行预测(分类)
x_unused = data_unused.iloc[:,1:]
pred_unused = model_RF.predict(x_unused)
print('待判样本预测类别为:0-人类/1-病毒\n',pred_unused)