1.Spark的提交过程(YarnCluster)
1.命令输入脚本启动,启动submit任务

2.解析参数
看是cluster还是yarn单点模式
3.创建客户端YarnClusterApplication
4.封装提交命令交给RM
5.RM在NM上启动ApplicationMaster(AM) 注意AM消耗的资源都是container的
6.AM根据参数启动Driver并且初始化SparkContext
7.Driver向RM申请资源,(YarnRM Client)
8.RM返回资源可用列表
9.Driver调用资源,找到空闲的NM,进行Executor注册,然后进行任务的切分和分配.
10.Executor 启动线程池,根据优先算法依次启动task线程.

2.任务的调度
如果是Client模式,则Driver就是本机了,Executor 会直接交互本机,远程访问提交,不能停止,同时所有Executor会交互本机,而本机资源不足,会导致系统和网络崩溃.
根据宽依赖进行Stage划分,根据分区做Task划分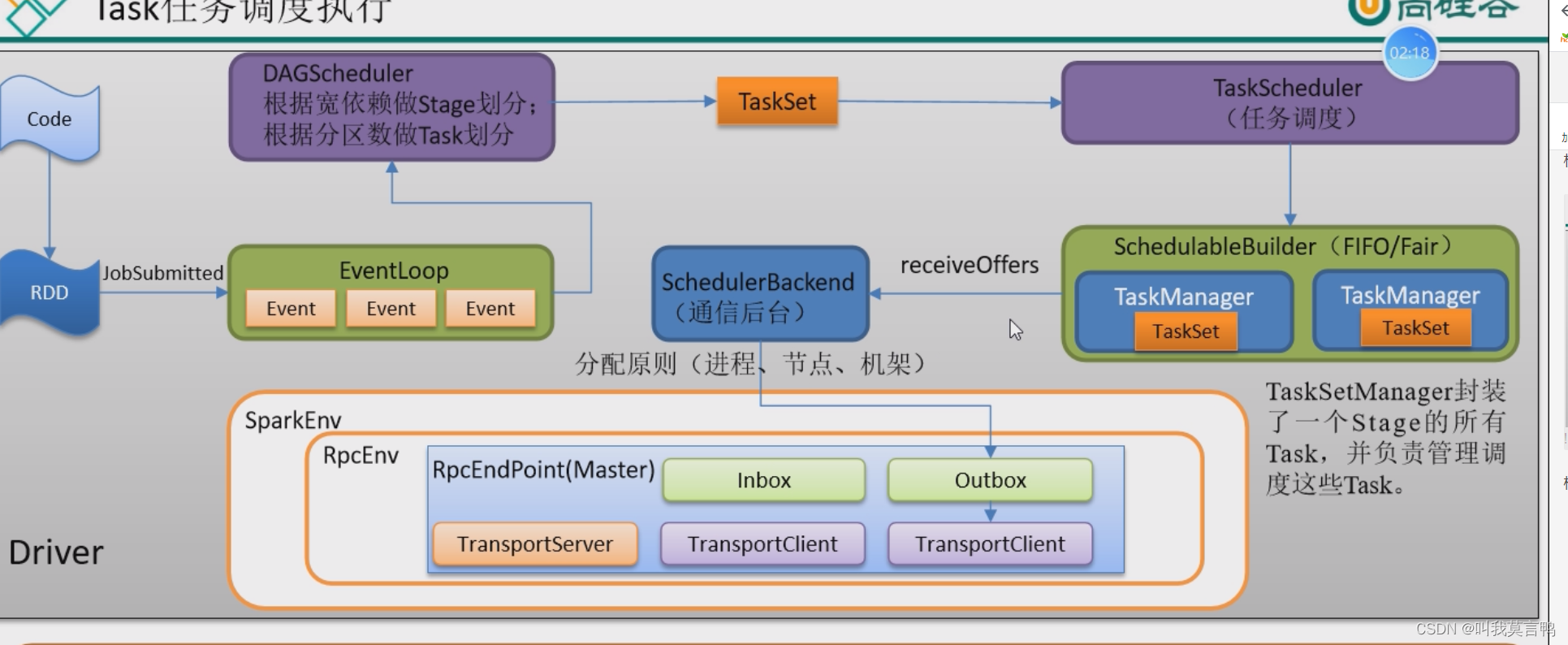
关于本地化调度
其实就是由近到远,依次尝试
如何由近到远?按照等级进行尝试,从高等级到低等级,降级机制.如何避免多次访问通一个节点? 黑名单机制

同一个进程-同一个节点->同一个机架->无所谓->任意地方,不在一个机架
3. Shuffle的原理

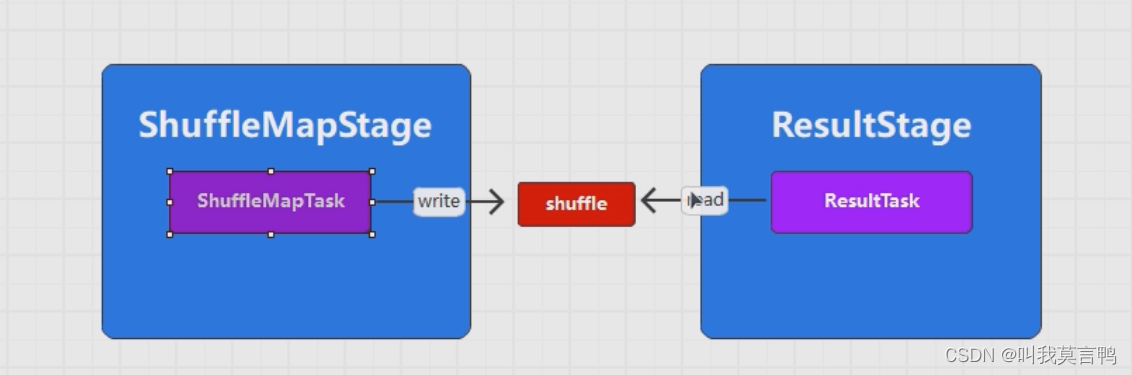
1. shuffle为什么那么慢?
因为shuffle要进行排序聚合操作,而且还要落盘
2.针对问题,如何优化?
- 针对排序聚合操作 在shuffle之前进行提前聚合,减少shuffle聚合的数据量,达到加速
- 落盘操作 增大缓冲区大小和溢出占比,减少溢写次数.
- 直接不排序
3.1 HashShuffle
一个task的一个分区一个文件
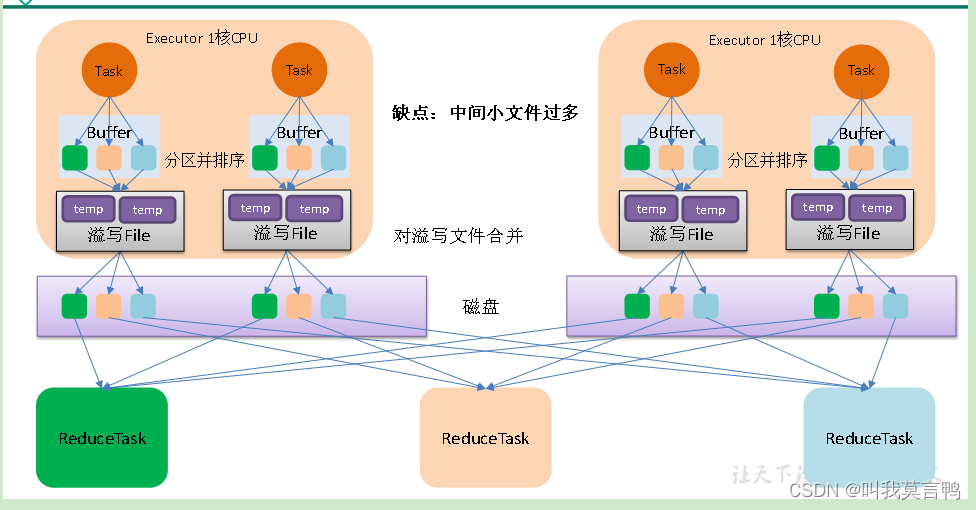
3.2HashShuffle的第二版流程
一个核按分区数划分文件数
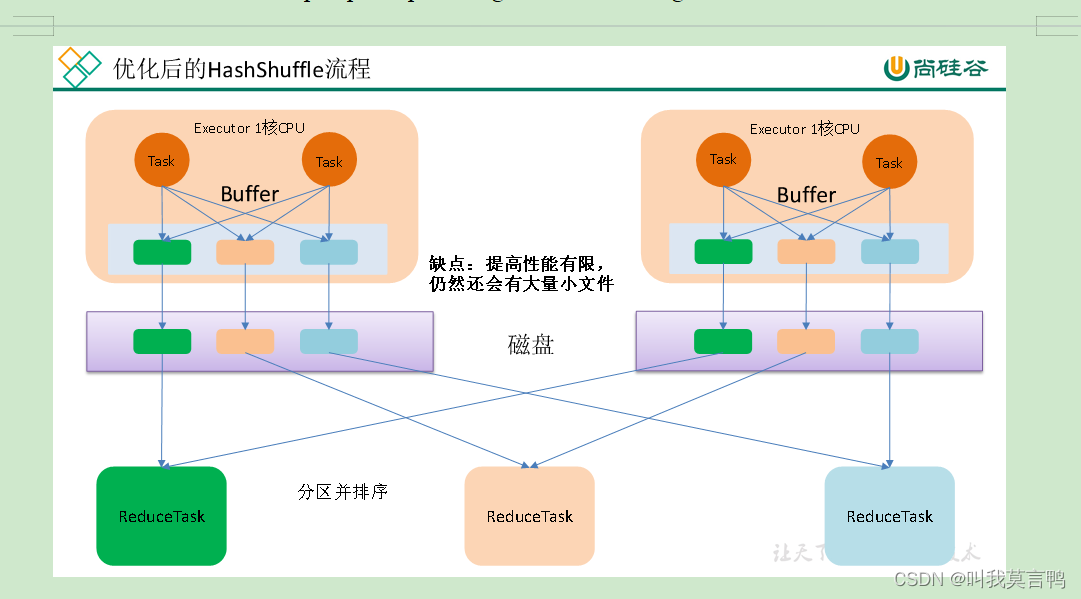
3.3 SortShuffle
全部写入到一个文件中,保证文件内容有序,同时,使用稀疏索引来确定数据的位置
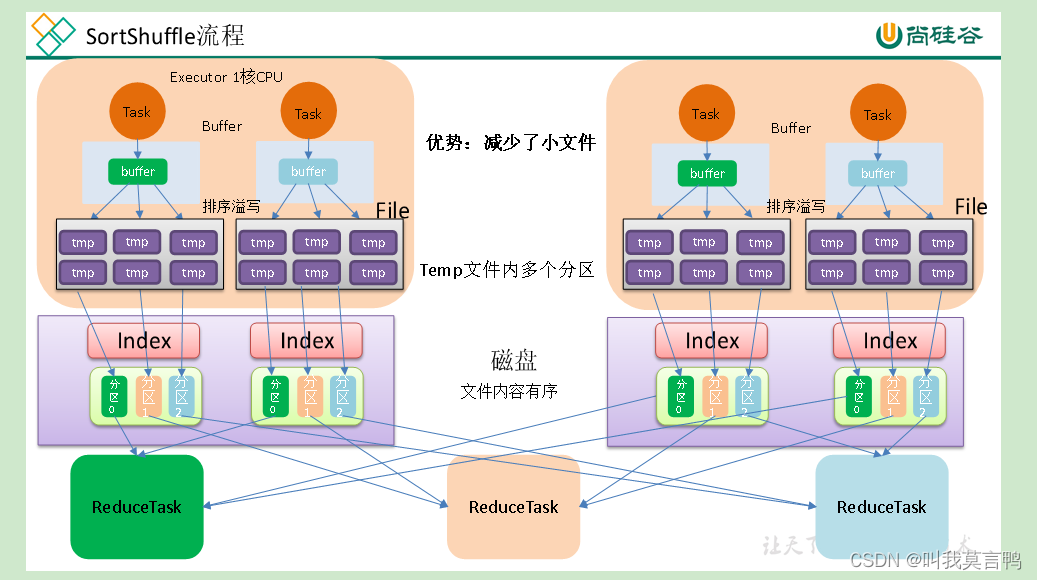
3.4bypassShuffle
对比3.3直接忽略排序
要求
- 当reducetask数量小于等于200才能使用
- 不是聚合类的shuffle(reduceByKey) groupby可以
通过hash不进行排序,存入
4.内存
堆内内存: JVM管理的内存
堆外内存: 操作系统管理的内存
JVM默认站 1/64 最大 1/4 超出则内存溢出
1.JVM三大块:
堆:存储程序运行时构建的对象(引用)
栈: 存储方法执行的内容(压栈,栈帧), 与JAVA的栈一致
方法区: 存储类的全部信息
2.关于堆的考虑
根据存活时长存储在不同的
新生代:
老年代
轻量级 Minor GC 对应新生代
重量级 Major GC 对应老年代
当新生代满了后,触发Minor GC,按时间排序,将旧对象放入老年代
老年代满了之后,触发Major GC,如果还不能解决问题,就出现堆内存溢出
3.Spark的内存分块
Storange 存储 广播变量
Execution 执行 shuffle sort
Other 其他 元数据 SparkContest 框架中的类对象
Yarn是将资源分配给节点(Driver,Executor),然后每个节点中资源的调配,就是由Spark自己决定






![八路参考文献:[八一新书]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑工业出版社,2022.](https://img-blog.csdnimg.cn/e945cb7f038b4607bb3cedd41845b0e6.jpeg#pic_center)