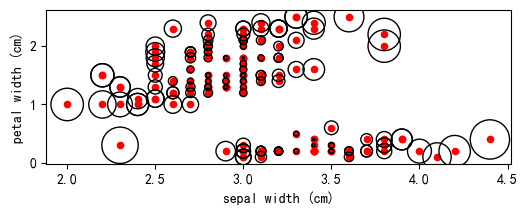
亚马逊云科技Amazon Kendra是一项由机器学习(ML)提供支持的企业搜索服务。Kendra内置数据源连接器,支持快速访问Amazon S3、AmazonRDS、AmazonFSX以及其他外部数据源,帮助用户自动提取文档并建立索引。Kendra支持超过30多种多国语言,支持简体中文与繁体中文。
Amazon Kendra与Amazon OpenSearch比较
Kendra和OpenSearch都可以用作搜索引擎,在二者的选择上,可以从两个方面进行考虑:
-
按搜索内容:如果搜索内容是以非结构化的、主要是人工生成的内容(例如客服网站、指导文档、专利、票据等各式文档)——并且需要更高的准确性、获得类似互联网搜索的基于自然语言的搜索体验,Kendra可能是更佳的选择。反之,如果搜索内容为结构化的、主要由机器生成的内容(例如日志、目录和数据库搜索),OpenSearch Service则更适合。
-
按搜索需求:如果需要外部连接器、UI和OOTB功能的完全托管搜索服务的客户,尤其是目前已经在使用其他商业文本搜索产品(例如Coveo、Lucidworks、Sinequa、Attivio、Mindbreeze Inspire和Algolia)对客户,建议选择Kendra。对于希望获得最大灵活性和能够访问功能的构建者,OpenSearch更适合。
Amazon Kendra适用场景
目前Kendra可支持繁体中文与简体中文的语意搜索,还可以通过了解文章或FAQ语义内容撷取答案回复用户。此外Kendra还支持同义字检索,查询建议与拼字检查,但相关功能目前只支持英文,建议如果要使用全功能的部分,以英文搜索为主。针对出海用户的多语言搜索场景,使用Kendra可以加速建置流程。
Kendra目前支持数十种不同的连接器(Connector),包含S3,RDS与外部的Atlassian Confluence,Jira,Web Crawler等,协助客户快速接入数据到Kendra进行搜索,减少用户在资料接入的负担。假设用户所在的搜索资料来源种类较多,建议可以考虑使用Kendra来加速搜索。
Kendra支持自定义文件(Custom Document Enrichment),将文档引入Kendra时,可以创建、修改或删除文档属性和内容。这意味着可以根据需求操纵和获取数据。自定义文件扩充支持以下两种操作:
更改元数据的基本操作:可以使用基本逻辑来操作文档字段和内容。这包括删除字段中的值、使用条件修改字段中的值或创建字段。
-
通过Lambda函数提取和更改元数据或内容:如果想超越基本逻辑并应用高级数据操作,可以结合Lambda函数进行实现,同时借助Lambda还可以快速其他亚马逊云科技服务。例如,使用光学字符识别(OCR),它解析图像中的文本,并将每张图像视为文本文档。或者使用Amazon Transcribe将视频內容转成文字后写入Kendra。
相较于单一文件搜索的Query API,Kendra还提供专为RAG使用案例设计的Retrieve API。使用Retrieve API,可以检索最多100个语义相关的段落,每个段落最多200个标记词,按相关性排序。这些段落是可以从多个文档和同一文档的多个部分中语义提取的文本摘录。针对提供搜索资料给大语言模型进行解析出准确的结果,有更大的助益。
不过Kendra在同义字设定,拼字矫正等功能的支持方面以英文检索为主,且与其他AI服务的搭配使用时需要考量语系的搭配。建议在出海场景,选定适当的语系和文件来源多样化的情况下,在写入索引器之前配置适当的文字处理工作,利用Kendra自动创建索引的能力可以达到最大程度的优化效果。
基于智能搜索的大语言模型增强解决方案指南
结合LangChain的各类功能接口和亚马逊云科技的基础服务,构建了亚马逊云科技基于智能搜索的大语言模型增强解决方案指南,在支持OpenSearch的同时,也同步支持Kendra服务(根据实际场景二选一即可)。
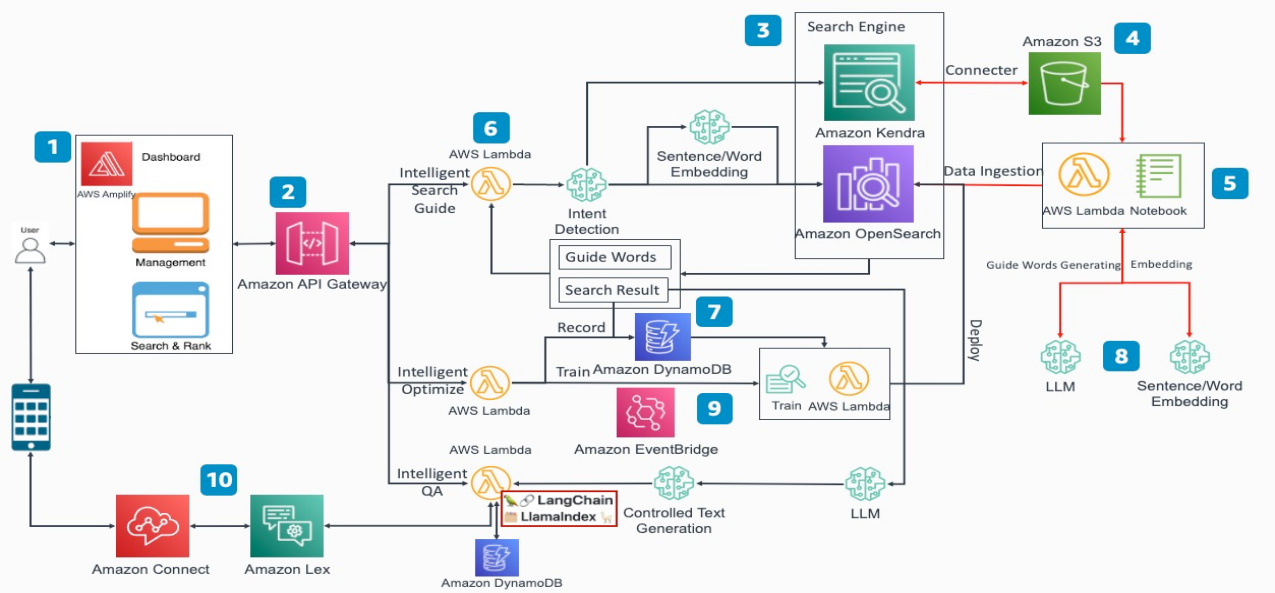
生成式人工智能应用程序需要根据用户请求和所使用的特定LLM来设计提示(Prompt),才能获得最佳的结果。对话式人工智能应用程序还需要管理聊天历史记录和上下文。生成式人工智能应用程序开发人员可以使用LangChain等开源框架,该框架提供与所选LLM集成的模块,以及用于聊天记录管理和提示工程等活动的编排工具。亚马逊云科技提供了Kendra Retriever类,它实现了LangChain检索器接口,应用程序可以将其与其他LangChain接口结合使用,以从Kendra索引检索到最正确的数据。
结论
由大型语言模型提供的生成式人工智能正在改变人们从信息中获取和应用见解的方式。然而对于企业客户,必须使用检索增强生成方法根据企业内容生成见解,确保回答资料的准确性。Kendra提供开箱即用的高精度语义搜索结果的功能,借助其Retrieve API(专为RAG设计)、全面的数据源连接器生态系统、对常见文件格式的支持以及安全性,可以快速开始部署自己的智能搜索应用。