本篇包括以下内容点:
· 数据库主要技术分类
· 图是什么?
· 图的模式
· 图数据库 VS.关系型数据库
· 图数据库VS.其他NOSQL的对比
· 并非所有的图数据库都一样!
根据Gartner预测,“到2025年,使用图技术进行数据和分析创新的比例将由2021年的10%提升至80%,这将大大促进企业进行快速决策。”

上图是笔者将数据库的主要技术轨迹做了个简单的分类,大家还可以结合我上篇的一个整理【嬴图 |一文了解数据库发展的里程碑事件都有哪些? - 知乎 (zhihu.com)】一起看。不难发现,在数据库技术50多年的发展历史中,它蓬勃的生命力以及新型数据库对传统数据库发出的挑战——其背后的推动因素主要是工业界和学术界亟需一种新型的、高效的、灵活的、高维的架构出现,以满足数据量的迅猛增长(Volume)、数据种类的多样性(Volume),数据产生速度的飞速提升(Volume)以及人们对数据价值的关注性(Volume)——也因此能够理解GQL为何成为了自1983年以来唯一一个继SQL后的国际标准,这也有力说明了图数据库技术对未来的影响力和重要性。

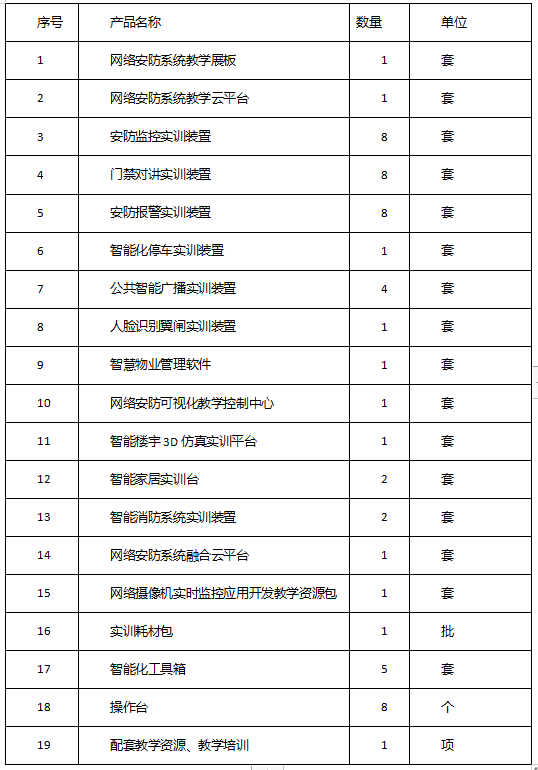
表1:5类主流数据库产品分析
| 分类 | 性能 | 可扩展性 | 灵活性 | 复杂性 |
| 键值存储数据库 | 高 | 高 | 高 | 无 |
| 文档数据库 | 高 | 可变 | 高 | 低 |
| 列存储数据库 | 高 | 可变 | 一般 | 低 |
| 图数据库 | 可变 | 高 | 高 | 高 |
| 关系型数据库 | 可变 | 可变 | 低 | 一般 |
图数据库(Graph Database)是基于图论实现的一种NoSQL数据库,可以存储实体的属性信息和实体之间的关系信息,且建模简单,性能强劲,搜索功能丰富,扩展性强。
图(Graph)由点和连接每对点的边所构成:
点(node):称之为顶点(Vertex)或点(node),也可以称作实体(Entity)。
边(edge):连接两个点(node)的边,在知识图谱范畴内也常被称作关系(relation、relationship)。
举例来说,当你查达芬奇与卢浮宫之间的关系时,你就可以关联出一张非常简单的人与物之间的图谱——“六度分隔理论”就源于图。

再如,我们日常生活中几乎天天都会使用的通勤工具——地铁。如果将车站作为“点”,相邻的两站用“边”相连,那么,这也可以连成一张典型的“图”。

我们可以随着自己的思考进行无限延展,通过节点和节点相关联,就能信手拈来地通过图数据去直接地构建真实世界中的属性和关系【更多阅读,见文库 | 什么是图?】。
图的模式共分为三种,分别是属性图、超图和三元组,因为图数据是需要存储到具体的图数据库中才能最终落实为具体的数据文件,而这个过程就自然涉及到了要采用什么实现方式来保存图数据。以Ultipa Graph 为例,它跟Nejo4一样,都是属性图(Property Graphs)——属性图模型更易于理解,能描述绝大部分图使用场景。
为什么图数据库的优势越来越突出? 比如在传统关系型数据库中,一旦涉及到多表关联查询时,计算量与表内数据量的笛卡尔乘积等比例增长,数据量越大,表关联越多、越复杂,效率越低。因为它是通过外键在主表中寻找匹配的主键记录来进行搜索、匹配计算操作,如果使用多对多的关系时,则必须还要再添加中间表来保存两个参与表的外键对应关系,这就进一步增加了链接(join)操作的成本。
而图数据库,非常灵活,不仅能能够通过点和边就能简洁地让人们面料数据之间的关系,而且采用的计算逻辑是近邻关联计算(查询)模式,计算复杂度低,效率指数级提升。见下图所示。

如用关系型数据库与图数据库做一个深度穿透,从第2—5层,性能的差异其实是指数级上升的。如在做1层穿透的时候,两者可能并没有本质的区别,从2层开始会出现指数级(10倍以上)的变化,直到用传统数据库做4—5层的穿透时,其已经不能返回任何结果了,也就是说,已经超出了机器的运算范畴从而罢工了。(感兴趣的读者可以详细阅读:图数据库与关系型数据库的区别⁴)。
从目前各大类型数据库的市场占有情况来看,关系型数据库仍是主流,但这是处于过去缺乏可替代方案的时代背景下,随着它无法hold住的场景越来越多,图数据库因为其天然的基因优势将成为弯道超车的利器。
表2:主流图数据库对比
| Nejo4j | JanusGraph | Ultipa Graph | |
| 知名度 | 最高 | 高 | 一般 |
| 开源生态 | 社区版开源,但限制较多;商业版闭源: | 开源;兼容Apache Tinkerpop 生态,主要由AWS和IBM提供云服务 | 闭源主要由Ultipa Cloud 提供云服务 |
| 图查询语言 | Cypher | Gremlin | UQL |
| 支持数据规模 | 社区版十亿级;企业版千亿级以上 | 百亿级以上 | 千亿级以上 |
| 大规模数据写入性能 | 在线导入速度慢 | 较慢 | 在线导入速度快 |
| 大规模数据查询性能 | 快,较稳定 | 较快 | 快,超稳定 |
| 功能完善程度 | 完善 | 完善 | 完善 |
| 数据导入工具 | 支持CSV在线导入;支持格式丰富 | 未提供支持 | Ultipa Transporter 支持全平台运行,支持格式丰富,提供文件例如TSV,CSV、Mysql,BigQuery 等数据导入能力以及 CSV 导出能力。 |
| 可视化界面 | 支持,功能丰富,支持可视化的数据建模、导入、分析等 | 不支持,需用户集成第三方界面 | 支持,功能丰富,支持2D、3D转换;支持可视化的数据建模、导入、分析等 |
| 内置常用图算法 | 提供安装算法包,提供了丰富的基本图算法 | 不支持 | 提供安装算法包,建有丰富的算法库,能以独立算法包的形式提供给用户。 |
| 基础功能(属性图的增删查改、持计划鵆、元数据、事务、缓存、查询优化、增量更新图等) | 支持 | 支持 | 支持 |
| ACID事务 | 支持 | 部分支持,根据后端存储而定。 | 支持 |
| chema约束 | 商业版支持,同时也支持Schema-Free | 支持,同时也支持Schema-Free | 支持,同时也支持Schema-Free |
| 图存储类型 | 支持本地存储,支持分布式存储,支持云托管存储 | 飞本地存储,支持分布式存储 | |
| 图分区 | 支持 | 支持 | 支持 |
| 高可用HA | 商业版支持 | 未提供支持 | 支持 |
从上文我们已知,NoSQL数据库能够流行起来的因素就是因为其能解决多数数据种类、大规模数据集合等等挑战,但是它们之间(简单将键值对、文档展开聊聊)又有哪些对比呢?
文档存储属于层次化结构,可以轻松地将数据存储为树结构,但正因此,它只能表达一种从上到下的从属关系,而树状在图数据库中只是其中的一种而已,其表现更为丰富。此外,树存储结构,会出现多次被嵌入的冗余数据,这就会增加更新数据的难度,也无法确保数据一致性的问题。
键值数据库,更适合少量数据关系的应用,因为它是按照键值对的形式进行组织、索引和存储,在数据量少的情况下,能有效地减少读写磁盘的次数,性能很高,但反之,一旦数据量大时,明显图就更能表现数据之间的复杂关系了。
最后,要说明的是,并非所有的图数据库都是一样的!有的图数据库只有存储能力而缺乏计算能力,有的可以计算,但是因为涉及到数据迁移效率又非常低下。还有一些图数据库采用NoSQL或MapReduce的架构实现,但是没有面对图计算的特点做充分的、深度的优化,最终的效果是越水平分布,效率越低。更有的厂家盲目地把所有数据都搬入内存,造成内存使用暴增,同样会产生频繁出现OOM而导致宕机的负面问题。正确的实现道路是“分布式+存算一体化+多级存储优化+图查询深度优化”,这里涉及到图数据库的知识点与挑战非常多,关于如何设计并实现真正的高性能分布式图数据库,感兴趣的读者可详细参阅高并发图数据库系统如何实现?³。【文/ 哪吒Emma】