目录
一、部署Zookeeper
1 拉取Zookeeper镜像
2 运行Zookeeper
二、部署Kafka
1 拉取Kafka镜像
2 运行Kafka
三、验证是否部署成功
1 进入到kafka容器中
2 创建topic 生产者
3 生产者发送消息
4 消费者消费消息
四、搭建kafka管理平台
五、SpringBoot整合Kafka
1、导入依赖
2、修改配置
3、生产者
4、消费者
5、测试发送消息
6、测试收到消息
一、部署Zookeeper
1 拉取Zookeeper镜像
docker pull wurstmeister/zookeeper
- 1
2 运行Zookeeper
docker run --restart=always --name zookeeper \
--log-driver json-file \
--log-opt max-size=100m \
--log-opt max-file=2 \
-p 2181:2181 \
-v /etc/localtime:/etc/localtime \
-d wurstmeister/zookeeper二、部署Kafka
1 拉取Kafka镜像
docker pull wurstmeister/kafka
2 运行Kafka
docker run --restart=always --name kafka \
--log-driver json-file \
--log-opt max-size=100m \
--log-opt max-file=2 \-p 9092:9092 \-e KAFKA_BROKER_ID=0 \-e KAFKA_ZOOKEEPER_CONNECT=192.168.8.102:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.8.102:9092 \-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \-v /etc/localtime:/etc/localtime \-d wurstmeister/kafka
参数说明:
-e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
-e KAFKA_ZOOKEEPER_CONNECT=172.16.0.13:2181/kafka 配置zookeeper管理kafka的路径172.16.0.13:2181/kafka
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.16.0.13:9092 把kafka的地址端口注册给zookeeper,如果是远程访问要改成外网IP,类如Java程序访问出现无法连接。
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口
-v /etc/localtime:/etc/localtime 容器时间同步虚拟机的时间
三、验证是否部署成功
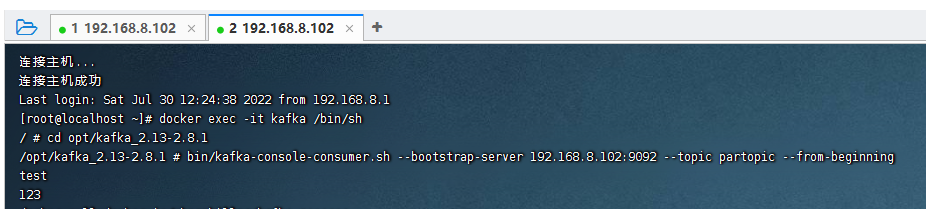
1 进入到kafka容器中
docker exec -it kafka /bin/sh
2 创建topic 生产者
cd opt/kafka_2.13-2.8.1bin/kafka-topics.sh --create --zookeeper 192.168.8.102:2181 --replication-factor 1 --partitions 1 --topic partopic

3 生产者发送消息
bin/kafka-console-producer.sh --broker-list 192.168.8.102:9092 --topic partopic

4 消费者消费消息
- 新打开个ssh窗口
- 跟前面步骤一样进入到容器
bin/kafka-console-consumer.sh --bootstrap-server 192.168.8.102:9092 --topic partopic --from-beginning
四、搭建kafka管理平台
docker search kafdrop

docker run -d --rm -p 9000:9000 \-e JVM_OPTS="-Xms32M -Xmx64M" \-e KAFKA_BROKERCONNECT=<host:port,host:port> \-e SERVER_SERVLET_CONTEXTPATH="/" \obsidiandynamics/kafdrop<host:port,host:port> 为 外网集群地址 多个用逗号分隔 例如xxx.xxx.xxx.xxx:9092,yyy.yyy.yyy.yyy:9092 尖角号不留上面的命令是百度的以下是我自己尝试的
docker run -d --name kafdrop -p 9001:9001 \-e JVM_OPTS="-Xms32M -Xmx64M -Dserver.port=9001" \-e KAFKA_BROKERCONNECT=192.168.58.130:9092 \-e SERVER_SERVLET_CONTEXTPATH="/" \obsidiandynamics/kafdrop因为我docker启动了其他东西占用了9001端口,而这个kafdrop其实就是一个springboot项目,以jar命令的形式启动访问地址:Kafdrop: Broker List

五、SpringBoot整合Kafka
1、导入依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>2、修改配置
spring:kafka:bootstrap-servers: 192.168.58.130:9092 #部署linux的kafka的ip地址和端口号producer:# 发生错误后,消息重发的次数。retries: 1#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。batch-size: 16384# 设置生产者内存缓冲区的大小。buffer-memory: 33554432# 键的序列化方式key-serializer: org.apache.kafka.common.serialization.StringSerializer# 值的序列化方式value-serializer: org.apache.kafka.common.serialization.StringSerializer# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。acks: 1consumer:# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5Dauto-commit-interval: 1S# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录auto-offset-reset: earliest# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量enable-auto-commit: false# 键的反序列化方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 值的反序列化方式value-deserializer: org.apache.kafka.common.serialization.StringDeserializerlistener:# 在侦听器容器中运行的线程数。concurrency: 5#listner负责ack,每调用一次,就立即commitack-mode: manual_immediatemissing-topics-fatal: false本次测试:linux地址:192.168.58.130
spring.kafka.bootstrap-servers=192.168.58.130:9092
advertised.listeners=192.168.58.130:9092
3、生产者
import com.alibaba.fastjson.JSON;import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;/*** 事件的生产者*/
@Slf4j
@Component
public class KafkaProducer {@Autowiredpublic KafkaTemplate kafkaTemplate;/** 主题 */public static final String TOPIC_TEST = "Test";/** 消费者组 */public static final String TOPIC_GROUP = "test-consumer-group";public void send(Object obj){String obj2String = JSON.toJSONString(obj);log.info("准备发送消息为:{}",obj2String);//发送消息ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj);//回调future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onFailure(Throwable ex) {//发送失败的处理log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + ex.getMessage());}@Overridepublic void onSuccess(SendResult<String, Object> result) {//成功的处理log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + result.toString());}});}}4、消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;import java.util.Optional;/*** 事件消费者*/
@Component
public class KafkaConsumer {private Logger logger = LoggerFactory.getLogger(org.apache.kafka.clients.consumer.KafkaConsumer.class);@KafkaListener(topics = KafkaProducer.TOPIC_TEST,groupId = KafkaProducer.TOPIC_GROUP)public void topicTest(ConsumerRecord<?,?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){Optional<?> message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();logger.info("topic_test 消费了: Topic:" + topic + ",Message:" + msg);ack.acknowledge();}}
}5、测试发送消息
@Testvoid kafkaTest(){kafkaProducer.send("Hello Kafka");}6、测试收到消息
![]()