系列文章目录
[Java基础] StringBuffer 和 StringBuilder 类应用及源码分析
[Java基础] 数组应用及源码分析
[Java基础] String,分析内存地址,源码
[JDK8环境下的HashMap类应用及源码分析] 第一篇 空构造函数初始化
[JDK8环境下的HashMap类应用及源码分析] 第二篇 看源码了解HashMap的扩容机制
[JDK8环境下的HashMap类应用及源码分析] 第三篇 修改capacity实验
[JDK8环境下的HashMap类应用及源码分析] 第四篇 HashMap哈希碰撞、HashMap存储结构、链表变红黑树

文章目录
- 系列文章目录
- 1、JDK8下的HashMap的数据结构
- 1.1、hash
- 1.2、key、value类型
- 1.3、Node
- 1.4、TreeNode
- 1.5、插入数据时的数据结构变化
- 2、实验
- 2.1、哈希碰撞
- 2.1.1、与位运算(&)
- 2.1.2、哈希碰撞
- 2.2、链表变红黑树
1、JDK8下的HashMap的数据结构
HashMap是一种基于数组和链表(或红黑树)的数据结构,它通过哈希函数将键映射到数组的一个位置,并在该位置存储一个键值对的节点。
HashMap的put方法在插入数据前,首先要计算键的哈希值(hash(key))和索引,然后在相应的位置插入或更新节点,如果节点数超过阈值(threshold),就会进行扩容(resize())或树化。
HashMap的get方法主要是根据键的哈希值和索引,找到对应的位置,然后遍历链表或红黑树,返回匹配的值。
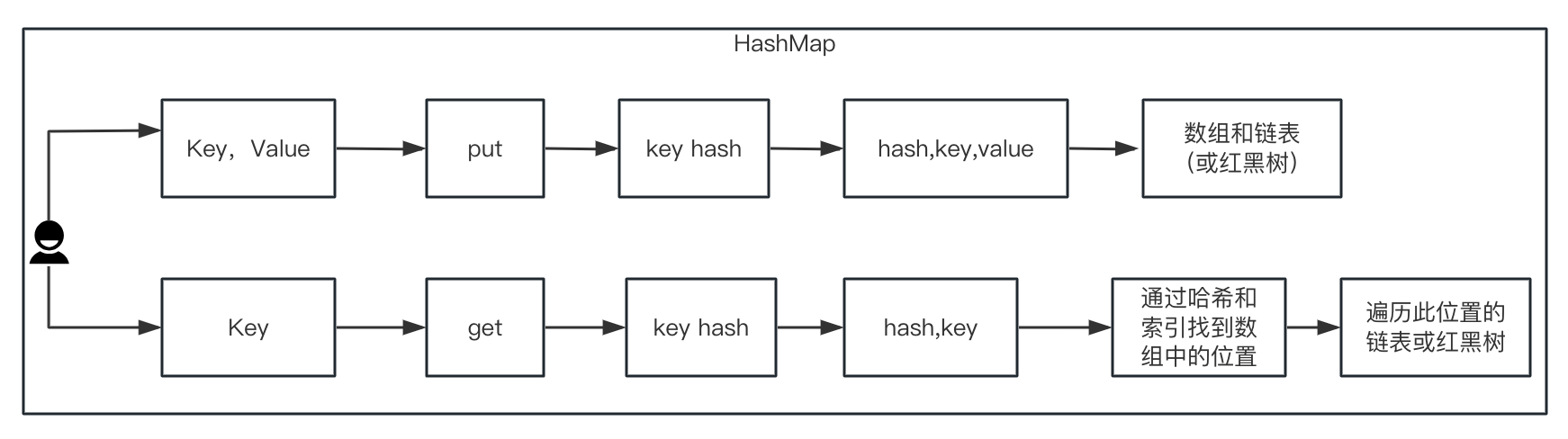
1.1、hash
public class HashMap {static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
}public class Object {public native int hashCode();
}public final class System {/*** Returns the same hash code for the given object as* would be returned by the default method hashCode(),* whether or not the given object's class overrides* hashCode().* The hash code for the null reference is zero.** @param x object for which the hashCode is to be calculated* @return the hashCode* @since JDK1.1*/public static native int identityHashCode(Object x);}下文引用自:深入解析Java对象和类在HotSpot VM内部的具体实现
对象哈希值
_mark中有一个hash code字段,表示对象的哈希值。每个Java对象都有自己的哈希值,如果没有重写Object.hashCode()方法,那么虚拟机会为它自动生成一个哈希值。哈希值生成的策略如代码清单3-4所示:
代码清单3-4 对象hash值生成策略
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0; if (hashCode == 0) { // Park-Miller随机数生成器 value =
os::random(); } else if (hashCode == 1) { // 每次STW时生成stwRandom做随机
intptr_t addrBits = cast_from_oop
Java层调用Object.hashCode()或者System.identityHashCode(),最终会调用虚拟机层的runtime/synchronizer的get_next_hash()生成哈希值。
1.2、key、value类型
static final int TREEIFY_THRESHOLD = 8; //链表转红黑树final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//判断table是否初始化if ((tab = table) == null || (n = tab.length) == 0)//如果是,调用 resize() 方法,进行初始化并赋值n = (tab = resize()).length;//通过hash获取下标,如果数据为nullif ((p = tab[i = (n - 1) & hash]) == null)// tab[i]下标没有值,创建新的Node并赋值tab[i] = newNode(hash, key, value, null);else {//tab[i] 下标的有数据,发生碰撞Node<K,V> e; K k;//判断tab[i]的hash值和传入的hash值相同,tab[i]的的key值和传入的key值相同if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))//如果是key值相同直接替换即可e = p;else if (p instanceof TreeNode)//判断数据结构为红黑树e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//数据结构是链表for (int binCount = 0; ; ++binCount) {//p的下一个节点为null,表示p就是最后一个节点if ((e = p.next) == null) {//创建新的Node节点并插入链表的尾部p.next = newNode(hash, key, value, null);//当元素>=8-1,链表转为树(红黑树)结构if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}//如果key在链表中已经存在,则退出循环if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;//更新p指向下一个节点,继续遍历p = e;}}//如果key在链表中已经存在,则修改其原先key的value值,并且返回老的value值if (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);//替换旧值时会调用的方法(默认实现为空)return oldValue;}}++modCount;//修改次数//根据map值判断是否要对map的大小扩容if (++size > threshold)resize();afterNodeInsertion(evict);//插入成功时会调用的方法(默认实现为空)return null;}
查看putVal源码,key、vlaue数据类型使用泛型,任意引用类型都可以(Java基础类型不可以,因为基本数据类型不能调用其hashcode()方法和equals()方法,进行比较,所以HashMap集合的key只能为引用数据类型,不能为基本数据类型,可以使用基本数据类型的包装类,例如Integer、Double、Long、Float等)。
1.3、Node
见【1.2】代码部分,tab变量的类型Node,实现了Map.Entry接口
Node里有hash、key、value等属性,也有next下一个节点变量(链表)
Node实现了toString、hashCode、equals等方法;
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}
}interface Entry<K,V> {K getKey();V getValue();V setValue(V value);boolean equals(Object o);int hashCode();public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> c1.getKey().compareTo(c2.getKey());}public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> c1.getValue().compareTo(c2.getValue());}public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {Objects.requireNonNull(cmp);return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());}public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp){Objects.requireNonNull(cmp);return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());}
}
1.4、TreeNode
见【1.2】代码部分,p变量的类型TreeNode,实现了LinkedHashMap.Entry接口
TreeNode里有red等属性,也有parent、left、right、prev等变量(红黑树)
TreeNode实现了treeify、find、putTreeVal等方法
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}}static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {...}final TreeNode<K,V> find(int h, Object k, Class<?> kc) {TreeNode<K,V> p = this;do {int ph, dir; K pk;TreeNode<K,V> pl = p.left, pr = p.right, q;if ((ph = p.hash) > h)p = pl;else if (ph < h)p = pr;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if (pl == null)p = pr;else if (pr == null)p = pl;else if ((kc != null ||(kc = comparableClassFor(k)) != null) &&(dir = compareComparables(kc, k, pk)) != 0)p = (dir < 0) ? pl : pr;else if ((q = pr.find(h, k, kc)) != null)return q;elsep = pl;} while (p != null);return null;}final TreeNode<K,V> getTreeNode(int h, Object k) {return ((parent != null) ? root() : this).find(h, k, null);}static int tieBreakOrder(Object a, Object b) {int d;if (a == null || b == null ||(d = a.getClass().getName().compareTo(b.getClass().getName())) == 0)d = (System.identityHashCode(a) <= System.identityHashCode(b) ?-1 : 1);return d;}final void treeify(Node<K,V>[] tab) {TreeNode<K,V> root = null;for (TreeNode<K,V> x = this, next; x != null; x = next) {next = (TreeNode<K,V>)x.next;x.left = x.right = null;if (root == null) {x.parent = null;x.red = false;root = x;}else {K k = x.key;int h = x.hash;Class<?> kc = null;for (TreeNode<K,V> p = root;;) {int dir, ph;K pk = p.key;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {x.parent = xp;if (dir <= 0)xp.left = x;elsexp.right = x;root = balanceInsertion(root, x);break;}}}}moveRootToFront(tab, root);}final Node<K,V> untreeify(HashMap<K,V> map) {Node<K,V> hd = null, tl = null;for (Node<K,V> q = this; q != null; q = q.next) {Node<K,V> p = map.replacementNode(q, null);if (tl == null)hd = p;elsetl.next = p;tl = p;}return hd;}/*** Tree version of putVal.*/final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {Class<?> kc = null;boolean searched = false;TreeNode<K,V> root = (parent != null) ? root() : this;for (TreeNode<K,V> p = root;;) {int dir, ph; K pk;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))return q;}dir = tieBreakOrder(k, pk);}TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;xp.next = x;x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;moveRootToFront(tab, balanceInsertion(root, x));return null;}}}final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,boolean movable) {...}final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {...}/* ------------------------------------------------------------ */// Red-black tree methods, all adapted from CLRstatic <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,TreeNode<K,V> p) {...return root;}static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,TreeNode<K,V> p) {...return root;}static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,TreeNode<K,V> x) {...}static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,TreeNode<K,V> x) {...}static <K,V> boolean checkInvariants(TreeNode<K,V> t) {...return true;}}
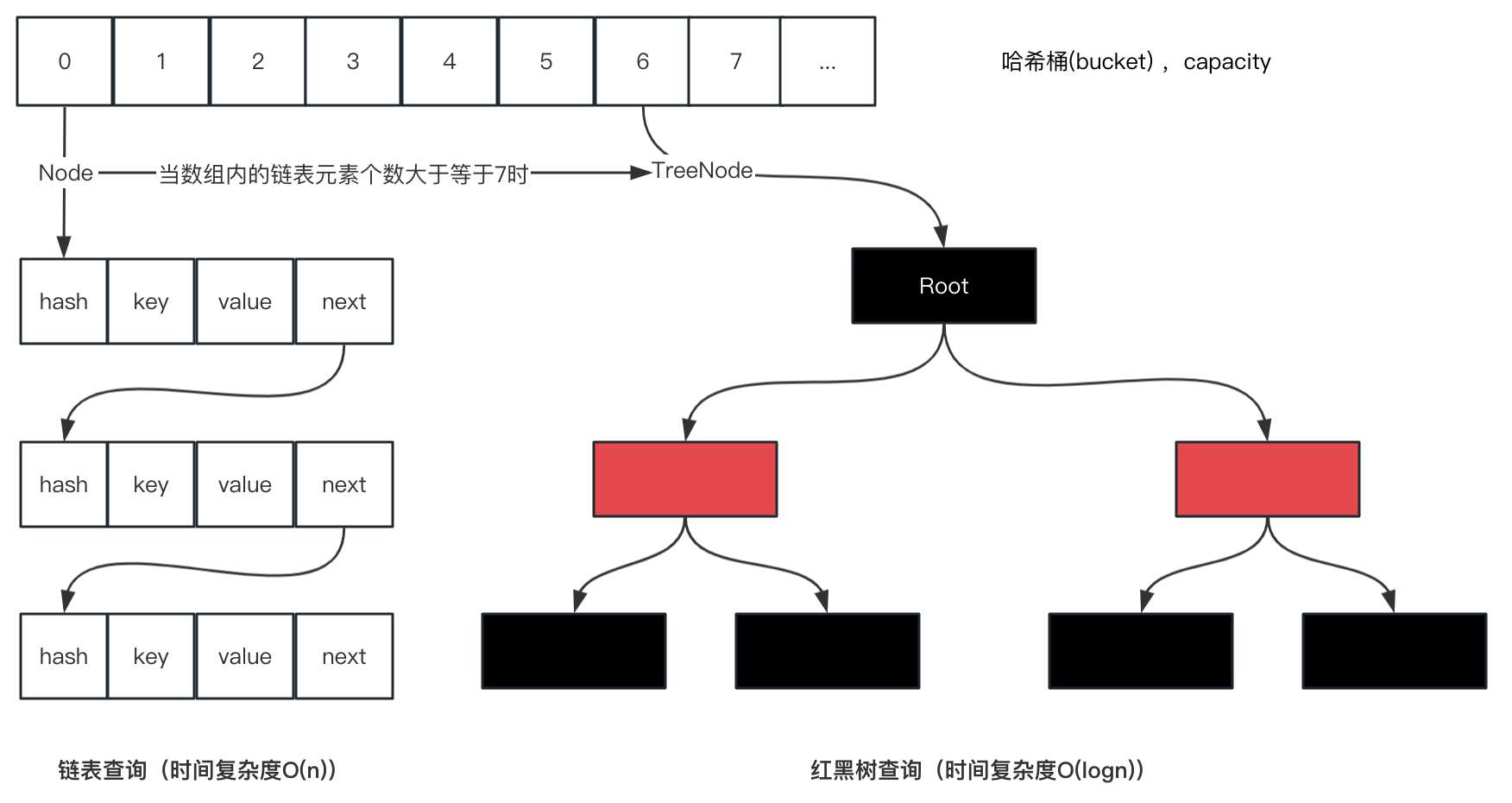
1.5、插入数据时的数据结构变化
见【1.2】代码,在插入数据时,数据结构有什么变化呢?
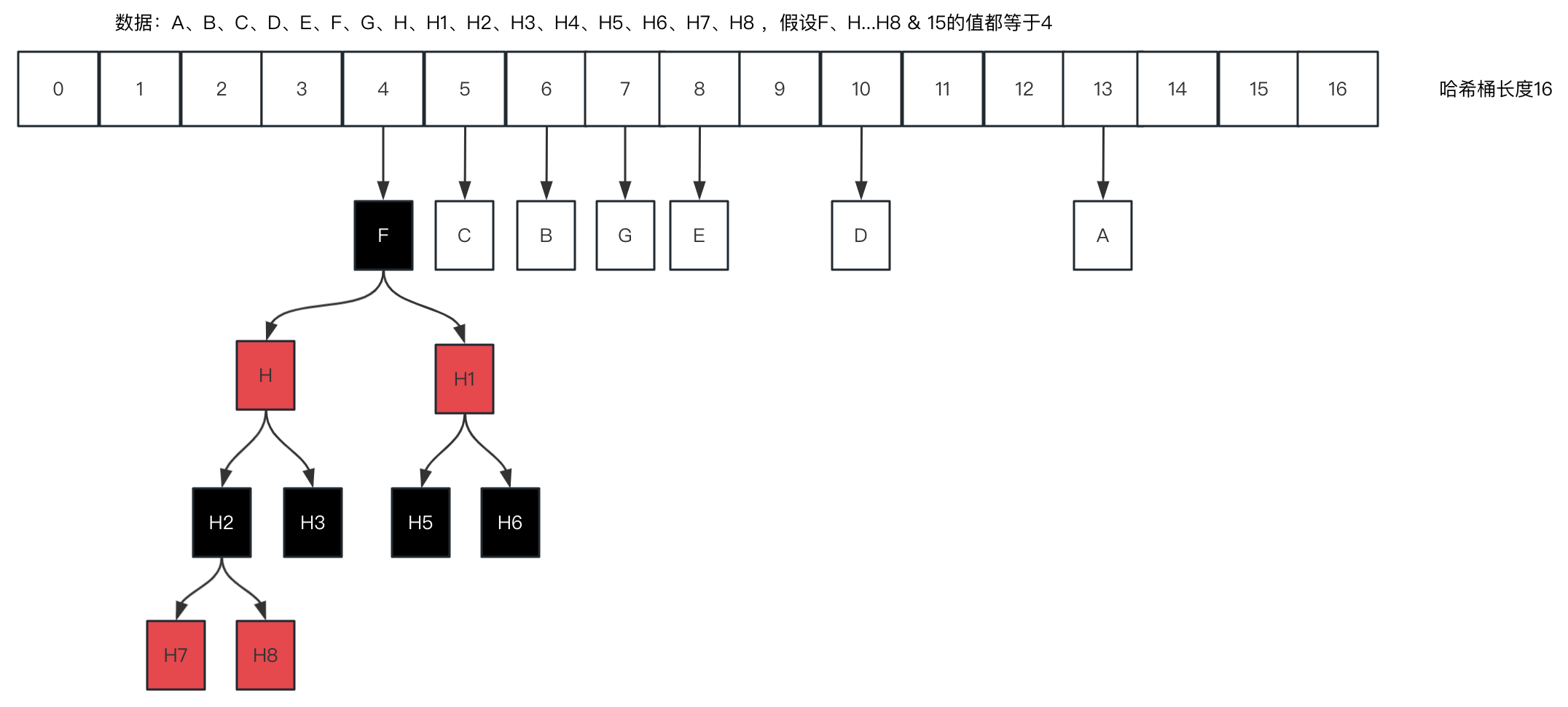
效果图可见【1】里的第二张图
- 判断table是否初始化
是->调用 resize() 方法,进行初始化并赋值 - 如果不是初始化,通过hash获取下标,如果数据为null
tab[i]下标没有值,创建新的Node并赋值 - tab[i] 下标的有数据,发生hash碰撞,有3种情况
1、判断tab[i]的hash值和传入的hash值相同,tab[i]的的key值和传入的key值相同
如果相同,直接替换
2、判断数据结构为红黑树
调用红黑树的数据插入函数putTreeVal
3、数据结构是链表
循环链表,如果p的下一个节点为null,表示p就是最后一个节点,此时在尾部插入新Node节点,如果此时元素个数大于等于7,链表转为红黑树结构
如果key在链表中已经存在,则退出循环
2、实验
实验里包括哈希碰撞和链表变红黑树,让我们一步步Debug跟踪源代码探个究竟
2.1、哈希碰撞
2.1.1、与位运算(&)
- 1、计算字符串"A" , “B” , “C” , “D” , “E” , “F” , “G” , "H"的hashCode
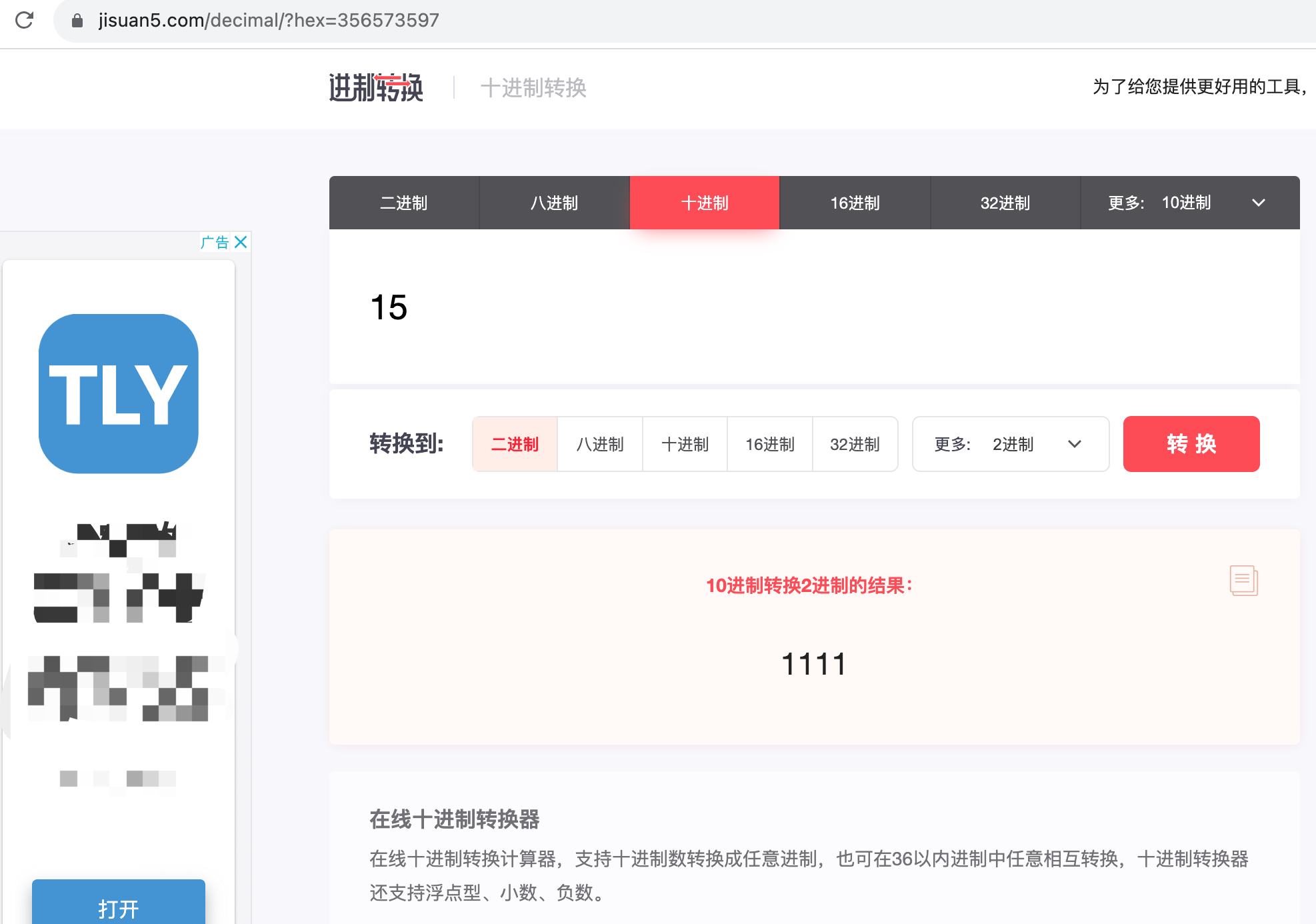
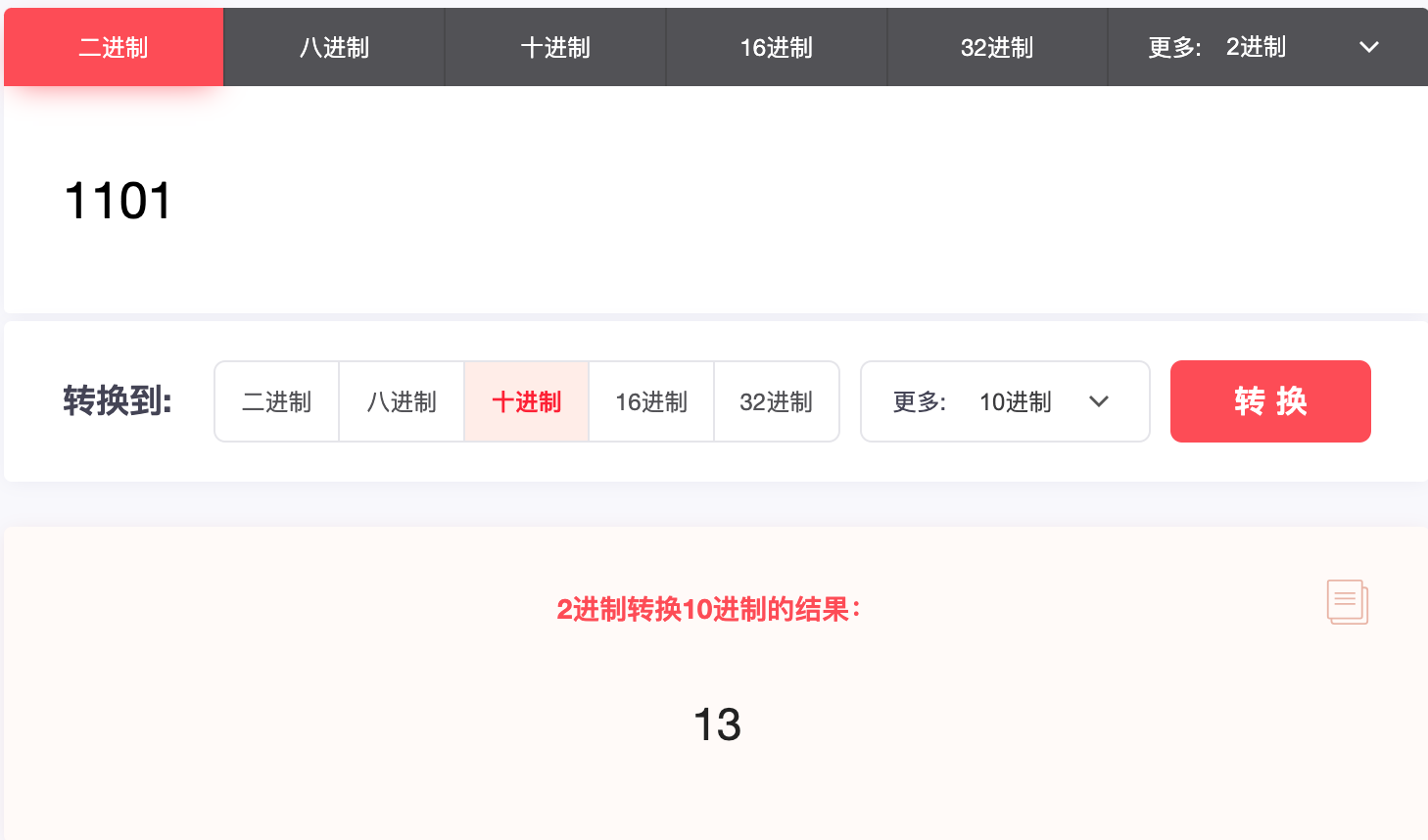
- 2、转换为2进制(https://jisuan5.com/decimal/?hex=356573597)
十进制的15转换2进制,结果:1111
此实验中"A"的hashCode=356573597,十进制的356573597转换2进制,结果:10101010000001110000110011101
356573597 & 15
= 10101010000001110000110011101 & 1111
= 10101010000001110000110011101 &
00000000000000000000000001111(高位补码0,对齐左边的数据)
= 00000000000000000000000001101 = 1101(高位的0可以省略掉) - 3、经过多次把15(2的4次方-1)改为其他数据的实验,我们发现2的幂次方-1,低位都是1,在做与位运算时,数据会平均分布;改为2的幂次方或其他数据,低位存在0,最终数据分布不均匀;
int n = 16 - 1; //二进制: 1111String[] strs = { "A" , "B" , "C" , "D" , "E" , "F" , "G" , "H"};for (int i = 0; i < strs.length; i++) {System.out.println("-------------------------");System.out.println(System.identityHashCode(strs[i]) );System.out.println("二进制:"+ Integer.toBinaryString(System.identityHashCode(strs[i])) );System.out.println( System.identityHashCode(strs[i]) & n );System.out.println("-------------------------");}-------------------------
356573597
二进制:10101010000001110000110011101
13
-------------------------
-------------------------
1735600054
二进制:1100111011100110010011110110110
6
-------------------------
-------------------------
21685669
二进制:1010010101110010110100101
5
-------------------------
-------------------------
2133927002
二进制:1111111001100010010010001011010
10
-------------------------
-------------------------
1836019240
二进制:1101101011011110110111000101000
8
-------------------------
-------------------------
325040804
二进制:10011010111111011101010100100
4
-------------------------
-------------------------
1173230247
二进制:1000101111011100001001010100111
7
-------------------------
-------------------------
856419764
二进制:110011000010111110110110110100
4
-------------------------
2.1.2、哈希碰撞
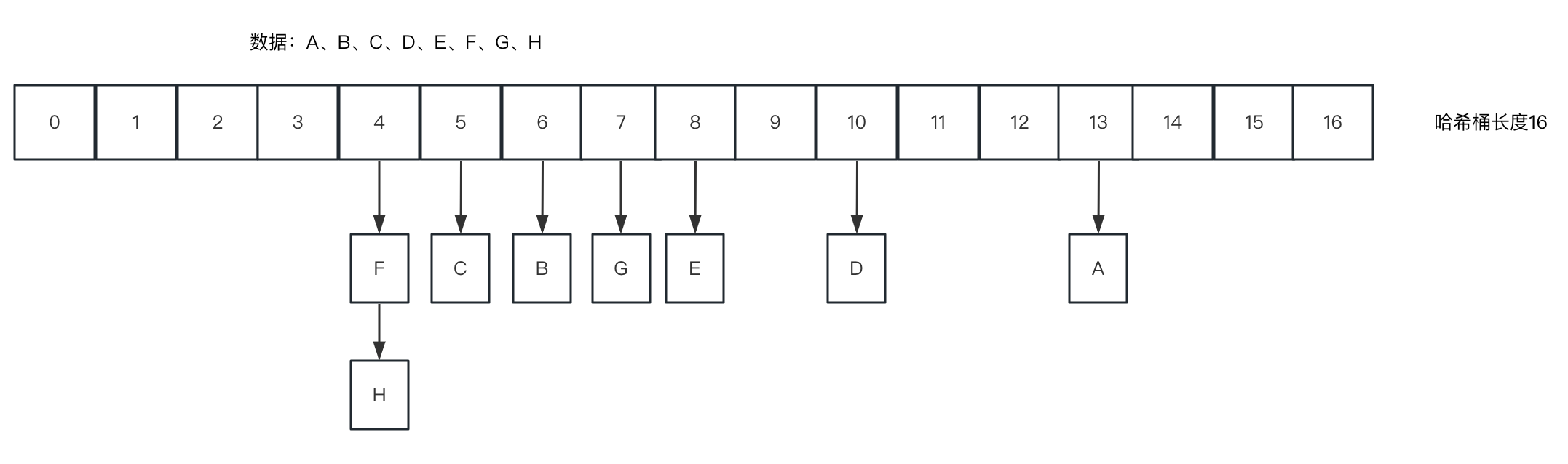
在【2.1.1】的代码案例中,F、H的哈希值与15进行与位运算后,值都是4,详细解释见【1.5】, 相当于计算在HashMap里的索引位置
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {...if ((p = tab[i = (n - 1) & hash]) == null)...
}
在此给出几种解决哈希碰撞(哈希冲突)的解决办法:
- 链地址法
遇到哈希碰撞的数据,在数组里索引相同,然后使用链表去存储发生碰撞的数据(JDK8的HashMap采用的此方法,且使用的尾插法)。 - 再哈希法
当遇到哈希碰撞问题时,在此哈希,直到冲突不在产生,这种方法不易产生聚集,但是增加了计算时间 - 开放地址法
当遇到哈希碰撞问题时,从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。然后把发生冲突的元素存入到该单元的一种方法。 - 建立公共溢出区
将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区
2.2、链表变红黑树
给定2个假设(在HashMap里,默认加载因子0.75,在大于12(16*0.75=12)长度时就会扩容成32,与位运算重新计算值也会变更,重新均衡的分布,详细解释见【1.5】)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {...//p的下一个节点为null,表示p就是最后一个节点if ((e = p.next) == null) {//创建新的Node节点并插入链表的尾部p.next = newNode(hash, key, value, null);//当元素>=8-1,链表转为树(红黑树)结构if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}...
}1、哈希桶不扩容;
2、(F、H…H8 ) & 15 都等于4,总共9个元素,在第7个元素加入时,会触发链表转红黑树,H7、H8插入时,直接走红黑树插入逻辑