嗨,亲爱的爬虫开发者们!在当今的数据驱动时代,大规模数据的爬取对于许多领域的研究和应用至关重要在本文中,我将与你分享大规模数据爬取的实战经验,重点介绍增量和分布式爬虫架构的应用,帮助你高效地处理海量数据。
1.增量爬虫
增量爬虫是指只爬取新增或更新的数据,而不是重新爬取整个网站的所有数据。这种方式可以大大提高爬虫的效率和性能。
实现方法:
-记录数据状态:对已经爬取的数据进行标记或记录,例如使用数据库或缓存来保存已经访问的URL和相关数据的状态。
-定期检查更新:定期运行增量爬虫,通过比对已有数据和目标网站的差异来确定新增或更新的内容。
-增量数据处理:对新增或更新的数据进行处理,例如存储到数据库、更新索引或进行进一步的分析。
2.分布式爬虫架构
分布式爬虫架构是指将爬虫任务分解为多个子任务,并在多台机器上并行执行,以提高爬取效率和处理能力。
实现方法:
-任务分配和调度:使用任务调度器将爬虫任务分配给不同的爬虫节点,确保任务的均衡分布和高效执行。
-数据通信和同步:爬虫节点之间需要进行数据通信和同步,例如使用消息队列或分布式存储系统来传递任务和数据。
-分布式数据处理:将爬取的数据分布式存储,例如使用分布式数据库或文件系统来存储和管理海量数据。
应用场景:
-搜索引擎索引:分布式爬虫架构可用于搜索引擎的网页抓取和索引构建,以提供准确和及时的搜索结果。
-大数据分析:大规模数据爬取和增量更新可用于大数据分析和机器学习任务,帮助挖掘有价值的信息和模式。
-商业情报收集:分布式爬虫可以帮助企业收集竞争对手的信息、市场趋势和用户反馈,支持决策和战略规划。
下面提供两组对应的爬虫示例代码:
pytho import requests from bs4 import BeautifulSoup #增量爬虫示例 def incremental_crawler(): #获取已爬取的URL列表 crawled_urls=get_crawled_urls_from_database()#从数据库中获取已爬取的URL列表 #获取目标网站的最新数据 url='https://www.example.com'#替换为目标网站的URL response=requests.get(url) if response.status_code==200: soup=BeautifulSoup(response.text,'html.parser') links=soup.find_all('a')#根据实际网页结构修改选择器 for link in links: href=link.get('href') if href not in crawled_urls: #处理新增的链接 process_link(href) #将已爬取的URL保存到数据库 save_crawled_url_to_database(href) else: print('Failed to retrieve data from the website.') #分布式爬虫架构示例 def distributed_crawler(): #任务分配和调度代码 #爬虫节点代码 def crawler(url): response=requests.get(url) if response.status_code==200: #数据处理代码 process_data(response.text) else: print('Failed to retrieve data from',url) #数据通信和同步代码 #分布式数据处理代码 def process_data(data): #数据存储或进一步处理的代码 #主程序 if __name__=='__main__': #获取待爬取的URL列表 urls=get_urls_to_crawl_from_queue()#从任务队列中获取待爬取的URL列表 #并行执行爬虫任务 for url in urls: crawler(url) #运行示例代码 if __name__=='__main__': incremental_crawler() print('---') ditributed_crawler()
请注意,以上示例代码只提供了一个基本的框架,具体的实现方式需要根据实际需求和系统架构进行调整。同时,在进行大规模数据爬取时,需要遵守相关的法律法规和网站的使用条款,确保合法合规地进行数据爬取和处理。
大规模数据爬取是一个复杂而挑战性的任务,但通过使用增量和分布式爬虫架构,我们可以提高爬虫的效率和性能,更好地处理海量数据。希望以上实战经验对你在大规模数据爬取的旅程中有所帮助!如果你有任何问题或想法,请在评论区分享!让我们一起探索大数据爬取的精彩世界!
希望以上示例代码和实战经验对你在大规模数据爬取的实践中有所帮助!如果您有更多的见解,欢迎评论区留言讨论
大规模数据爬取 - 增量和分布式爬虫架构实战
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/114867.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章


Docker consul 容器服务自动发现和更新
目录
一、什么是服务注册与发现
二、Docker-consul集群
1.Docker-consul
consul提供的一些关键特性
2.registrator
3.Consul-template
三、Docker-consul实现过程
以配置nginx负载均衡为例
先配置consul-agent ,有两种模式server和client
四、Docker-cons…
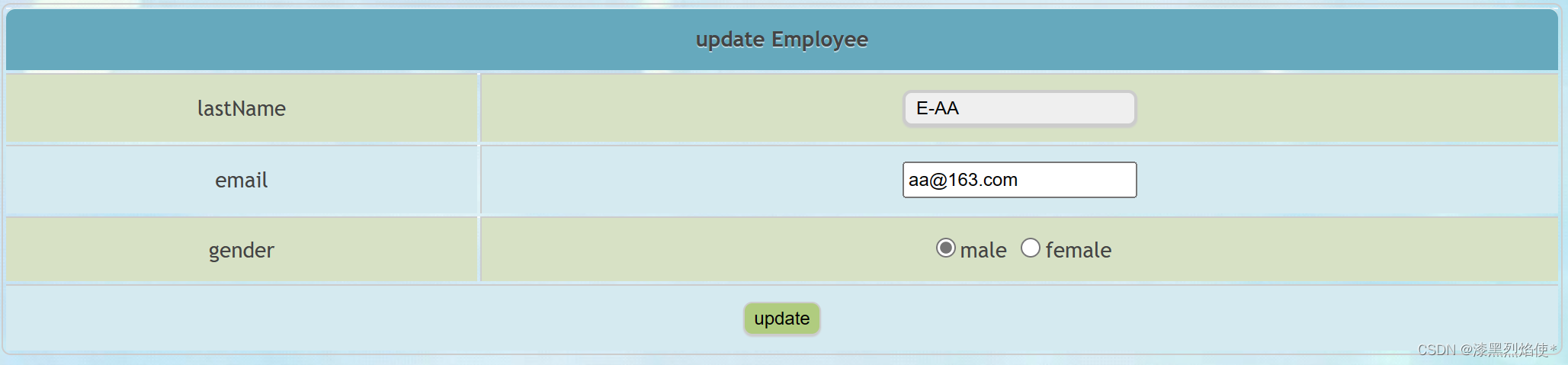
39.RESTful案例
RESTful案例
准备环境
Employee.java
public class Employee {private Integer id;private String lastName;private String email;//1 male, 0 femaleprivate Integer gender;
}
//省略get、set和构造方法EmployeeDao.java
package com.atguigu.SpringMVC.dao;import com.…
matlab使用教程(24)—常微分方程(ODE)求解器
1.常微分方程 常微分方程 (ODE) 包含与一个自变量 t(通常称为时间)相关的因变量 y 的一个或多个导数。此处用于表示 y 关于 t 的导数的表示法对于一阶导数为 y ′ ,对于二阶导数为 y ′′,依此类推。ODE 的阶数等于 y 在方程中…

Angular安全专辑之四 —— 避免服务端可能的资源耗尽(NodeJS)
express-rate-limit是一个简单实用的npm包,用于在Express应用程序中实现速率限制。它可以帮助防止DDoS攻击和暴力破解,同时还允许对API端点进行流控。 express-rate-limit及其主要功能 express-rate-limit是Express框架的一个流行中间件,它允许根据IP地址或其他标准轻松地对请求…
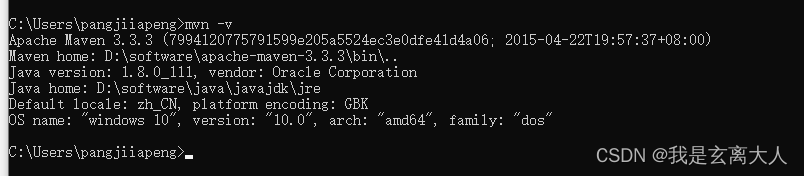
win10 maven 安装环境变量设置不成功
maven 按照正常步骤设置环境变量 输入命令总是不能正常现实mvn的版本
解决方案:
1.删除掉设置的用户环境变量
2.将maven的完整目录写入系统变量path中
3.将该路径放到所有变量的最前面 4.点击确定,重新打开cmd 输入 mvn -v 正常了
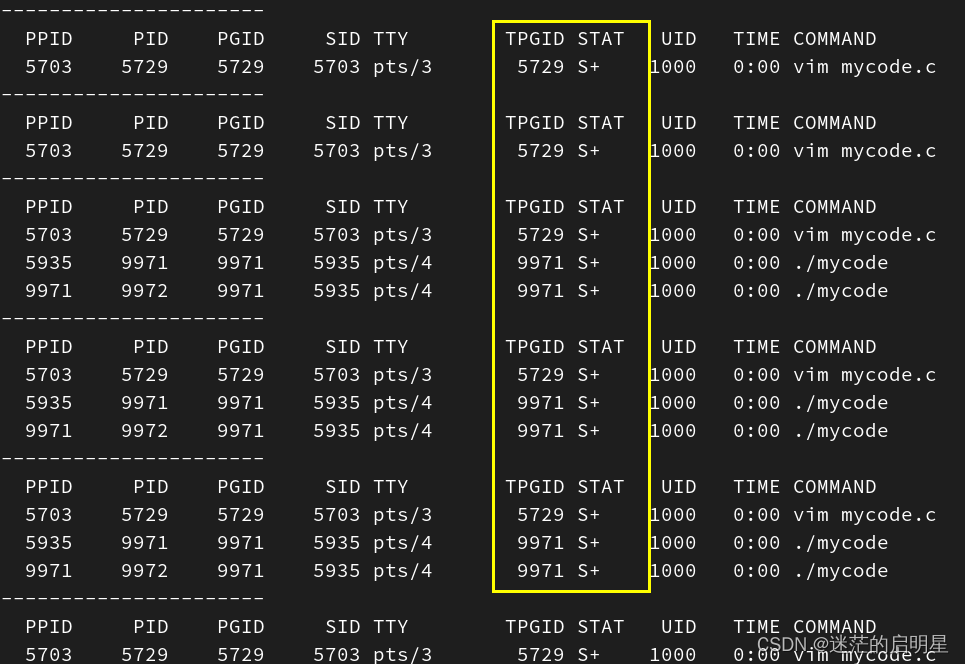
《Linux从练气到飞升》No.19 进程等待
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…
RHCE——十三、Shell自动化运维编程基础
Shell 一、为什么学习和使用Shell编程二、Shell是什么1、shell起源2、查看当前系统支持的shell3、查看当前系统默认shell4、Shell 概念 三、Shell 程序设计语言1、Shell 也是一种脚本语言2、用途 四、如何学好shell1、熟练掌握shell编程基础知识2、建议 五、Shell脚本的基本元素…
![cmd: Union[List[str], str], ^ SyntaxError: invalid syntax](https://img-blog.csdnimg.cn/5104ee24fdb648a69193069ba7e1e2b4.png)
cmd: Union[List[str], str], ^ SyntaxError: invalid syntax
跑项目在调用from easyprocess import EasyProcess 遇到报错:
cmd: Union[List[str], str], ^ SyntaxError: invalid syntax猜测是EasyProcess版本与python版本不对应
pip show EasyProcess查证一下:
WARNING: pip is being invoked by an old…

基于 Spring 前后端分离版本的论坛系统
访问地址:http://8.130.142.126:18080/sign-in.html
代码获取:基于 Spring 前后端分离版本的论坛系统: 基于 Spring 前后端分离版本的论坛系统
一.前置知识
1.软件生命周期
a. 可行性研究:通过分析软件开发要求,确定软件项目的性质、目标和规模&am…

龙蜥开发者说 :戮力同心,砥砺前行,为国产操作系统发展出一份力 | 第 23 期
「龙蜥开发者说」第 23 期来了!开发者与开源社区相辅相成,相互成就,这些个人在龙蜥社区的使用心得、实践总结和技术成长经历都是宝贵的,我们希望在这里让更多人看见技术的力量。本期故事,我们邀请了龙蜥社区开发者李崇…
C++项目:网络版本在线五子棋对战
目录 1.项目介绍
2.开发环境
3.核心技术
4. 环境搭建
5.websocketpp
5.1原理解析
5.2报文格式
5.3websocketpp常用接口介绍
5.4websocket服务器
6.JsonCpp使用
6.1Json数据格式
6.2JsonCpp介绍
7.MySQL API
7.1MySQL API介绍
7.2MySQL API使用
7.3实现增删改查…
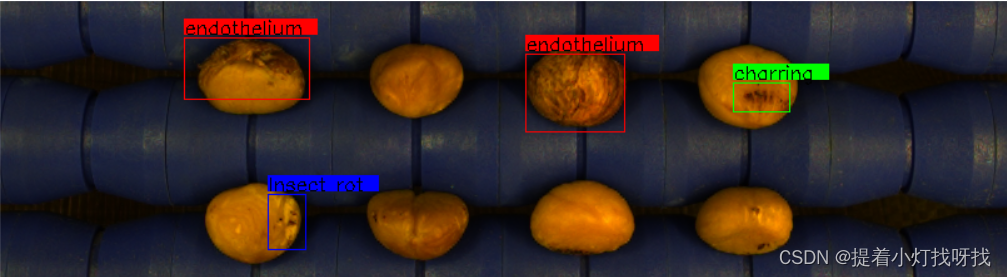
目标检测后的图像上绘制边界框和标签
效果如图所示,有个遗憾就是CV2在图像上显示中文有点难,也不想用别的了,所以改成了英文,代码在下面了,一定要注意一点,就是标注文件的读取一定要根据自己的实际情况改一下,我的所有图像的标注文件…

汽车售后接待vr虚拟仿真实操演练作为岗位培训的重要工具和手段
汽车虚拟仿真教学软件是一种基于虚拟现实技术的教学辅助工具。它能够模拟真实的汽车环境和操作场景,让学生能够通过虚拟仿真来学习和实践汽车相关知识和技能。与传统的教学方式相比,汽车虚拟仿真教学软件具有更高的视觉沉浸感和互动性,能够更…

Bytebase 2.7.0 - 新增分支(Branching)功能
🚀 新功能
新增支持与 Git 类似的分支(Branching)功能来管理 schema 变更。支持搜索所有历史工单。支持导出审计日志。
🎄 改进
变更数据库工单详情页面全新改版。优化工单搜索体验。SQL 审核规则支持针对不同数据库进行独立配…

【广州华锐互动】VR党建多媒体互动展厅:随时随地开展党史教育
随着科技的不断发展,虚拟现实(VR)技术已经逐渐渗透到各个领域,其中党建教育尤为受益。为了更好地传承红色基因,弘扬党的优良传统,广州华锐互动推出了VR党建多媒体互动展厅,让广大党员干部和人民群众通过现代科技手段&a…
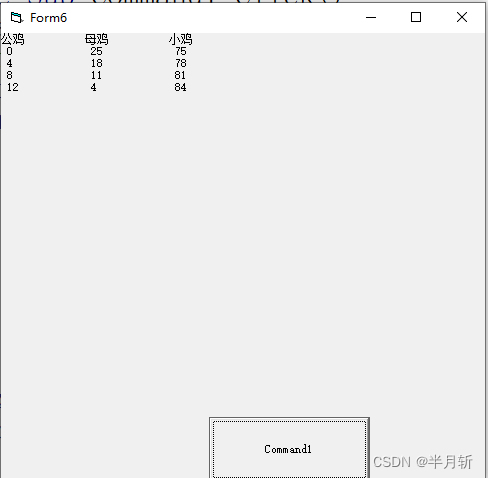
VB:百元买百鸡问题
VB:百元买百鸡问题
Private Sub Command1_Click()ClsRem 百元买百鸡问题Print "公鸡", "母鸡", "小鸡"For x 0 To 20For y 0 To 33z 100 - x - yIf z Mod 3 0 ThenIf 5 * x 3 * y z / 3 100 ThenPrint x, y, zEnd IfEnd IfNe…
最新文章
- 手机网站焦点图代码/杯子软文营销300字
- 济宁做网站的公司/域名查询平台
- 培训网络营销的机构/seo数据统计分析工具有哪些
- 河北廊坊做网站/网络广告营销
- 提供低价网站建设/产品推广的目的和意义
- 潍坊网站建设怎样/天津网站优化
- 本地部署webrtc应用怎么把http协议改成https协议?
- 面向未来的教育技术:智能成绩管理系统的开发
- Mac Android studio 升级LadyBug 版本,所产生的bug
- zabbix监控山石系列Hillstone监控模版(适用于zabbix7及以上)
- UE5 渲染管线 学习笔记
- ArcGIS Pro 3.4新功能3:空间统计新特性,基于森林和增强分类与回归,过滤空间自相关
推荐文章
- 妙用EXECEL与JMAIL发送员工工资条
- 旅行季《乡村振兴战略下传统村落文化旅游设计》许少辉八一著作想象和世界一样宽广
- # Java手写LRU缓存算法
- (01)fastapi的基础学习——开启学习之路
- (13)DroneCAN 适配器节点(二)
- (35)远程识别(又称无人机识别)(二)
- (5) 归并排序
- (C++)复原IP地址
- (C++)字符串相加
- (C语言贪吃蛇)16.贪吃蛇食物位置随机(完结撒花)
- (Git)git clone报错——SSL certificate problem: self signed certificate
- (k8s)kubernetes 挂载 minio csi 的方式(pod挂载pvc存在csi驱动问题,挂载不上)