分析&回答
基本类型划分
在Flink中,按照基本类型,对State做了以下两类的划分:
- Keyed State,和Key有关的状态类型,它只能被基于KeyedStream之上的操作,方法所使用。我们可以从逻辑上理解这种状态是一个并行度操作实例和一种Key的对应, <parallel-operator-instance, key>。保存State的数据结构:ValueState、ListState、MapState、ReducingState、AggregatingState<IN,OUT> 等
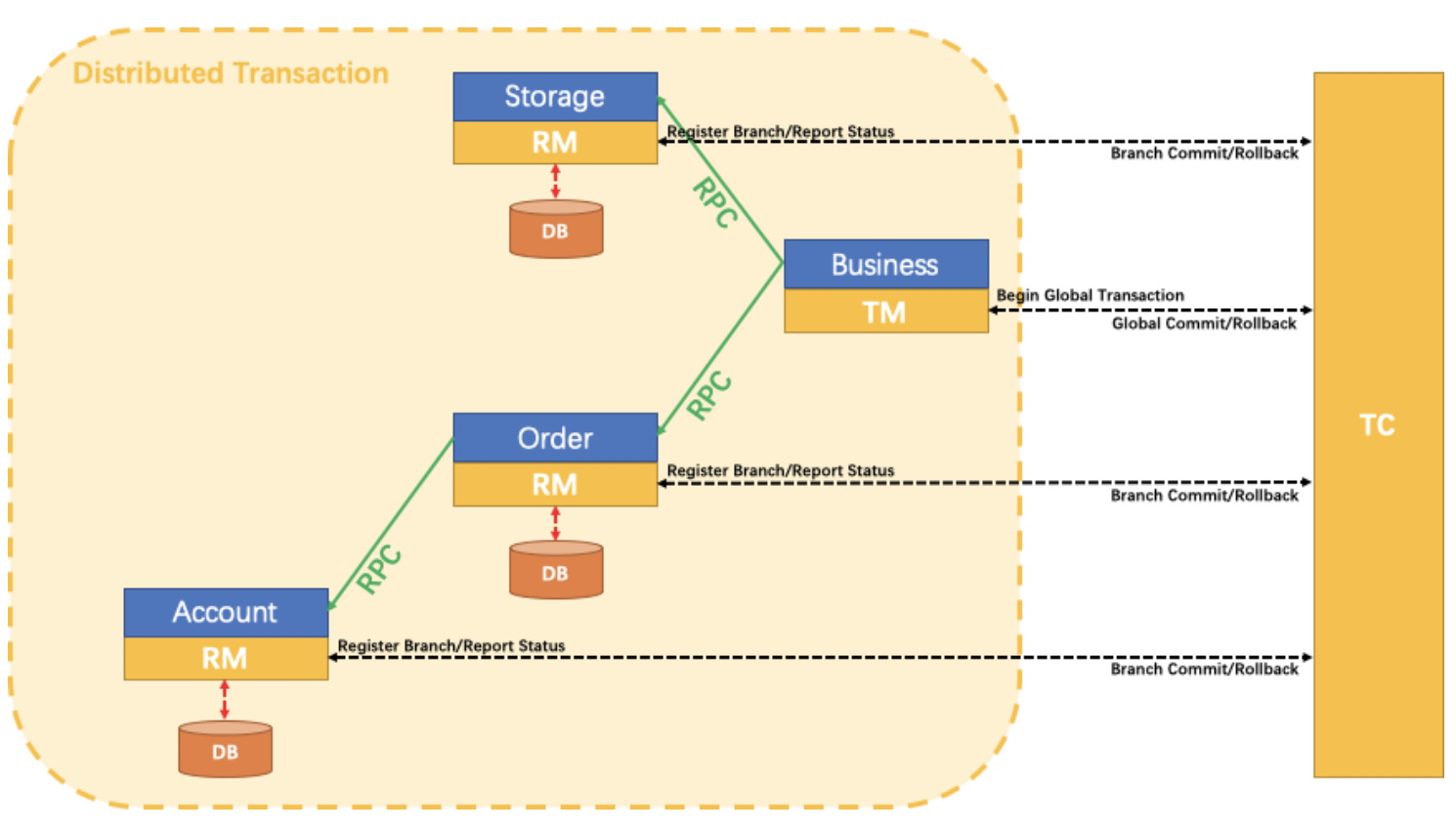
- Operator State(或者non-keyed state) ,它是和Key无关的一种状态类型。相应地我们从逻辑上去理解这个概念,它相当于一个并行度实例,对应一份状态数据。因为这里没有涉及Key的概念,所以在并行度(扩/缩容)发生变化的时候,这里会有状态数据的重分布的处理。⽐如:Flink中的KafkaConnector就使⽤了 Operator State,它会在每个Connector实例中,保存该实例消费Topic的所有(partition,offset)映射。如下图:

组织形式划分
但是在这里还有一种按照组织形式的划分,也可以理解为按照runtime层面的划分,又可以分为一下两类:
- Managed State,这类State的内部结构完全由Flink runtime内部来控制,包括如何将它们编码写入到checkpoint中等等。
- Raw State,这类State就比较显得灵活一些,它们被保留在操作运行实例内部的数据结构中。从Flink系统角度来观察,在checkpoint时,它只知道的是这些状态数据是以连续字节的形式被写入checkpoint中。等待进行状态恢复时,又从字节数据反序列化为状态对象。
Managed State可以在所有的data stream相关方法中被使用,官方也是推荐优先使用这类State,因为它能被Flink runtime内部做自动重分布而且能被更好地进行内存管理。
反思&扩展
State Time-To-Live (TTL)
在Flink内部,我们能够对State设置TTL,使其状态过期然后被系统清理掉。针对State TTL,可详见StateTtlConfig类的配置设置。
另类的一种State:Broadcast State模式
Broadcast State具有Broadcast流的特殊属性,它是一种小数据状态广播向其它流的形式,从而避免大数据流量的传输。在这里,其它流是对广播状态只有只读操作的允许,因为不同任务间没有跨任务的信息交流。一旦有运行实例对于广播状态数据进行更新了,就会造成状态不一致现象。
State的可查询性
State状态是一类能够反映任务当前执行情况的信息数据。所以当我们想要了解任务的执行情况时,我们就会想能不能够去查询里面的状态信息呢?Flink官方给出的答案是可以的,它有提供相关的API不过还不保证其完全稳定性。而且这里有一点需要注意,当我们对状态进行查询时,同时地它的信息被并发修改。Flink为了避免Job的处理延时,并没有对此做完全地同步控制。
除了通过API的获取方式外,这里还支持一种*QueryableStateStream 来获取状态数据的方式。任务状态数据将会更新到QueryableStateStream *流中,可以理解为是State的一个sink。
定制化State序列化/反序列实现
Flink内部支持定制化的State序列化器/反序列化实现。这里的序列化过程指的是将状态数据序列为字节数据写到checkpoint中,再从checkpoint文件字节数据反序列为状态对象数据。针对不同类型的State数据,可以定义各自不同的序列化/反序列的实现。
State的序列化演进
这来还存在异构序列化实现的演进问题,因为存在一种情况,任务在恢复状态数据时,会由新的序列化引入。如果出现新的序列化实现无法读取老的状态数据,那么需要做一个兼容性的改动,进行状态迁移,或者先用老的序列化实现读取老状态,然后新的状态用新的序列化方式写出。
State在Flink任务的运行时保存了非常重要的数据,明白如何去更好地使用State将会对我们了解,恢复任务有着很大的帮助。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!