目录
LeNet
LeNet在手写数字识别上的应用
LeNet在眼疾识别数据集iChallenge-PM上的应用
LeNet
LeNet是最早的卷积神经网络之一。1998年,Yann LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如 图1 所示,这里展示的是用于MNIST手写体数字识别任务中的LeNet-5模型:

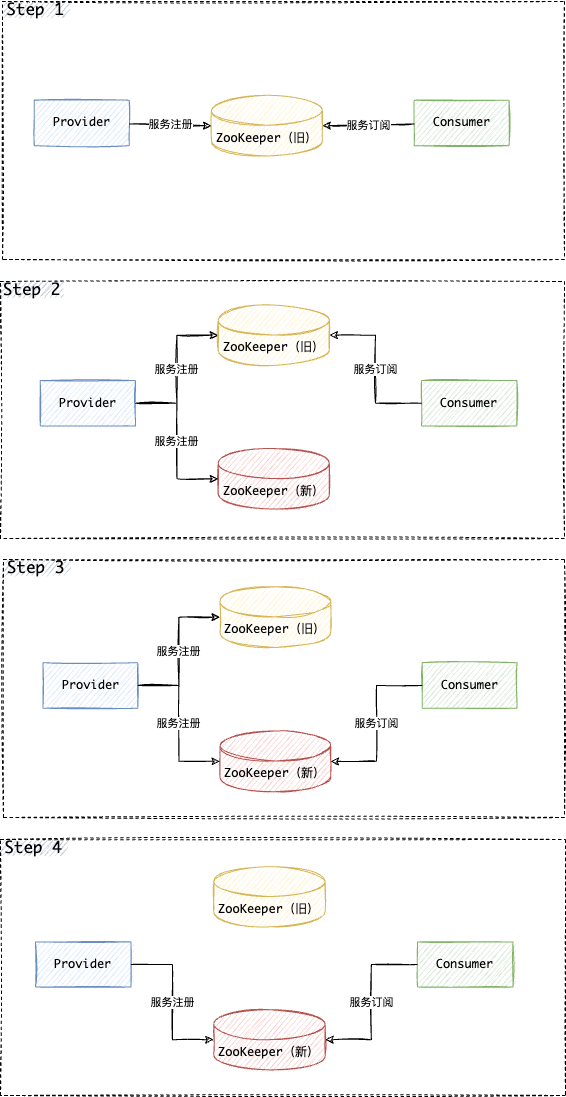
图1:LeNet模型网络结构示意图
-
第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用Sigmoid),图像尺寸从28减小到24。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到12。
-
第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到8,经过池化后变成4。
-
第三模块:包含4×4的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别的类别数是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
【提示】:
卷积层的输出特征图如何当作全连接层的输入使用呢?
卷积层的输出数据格式是[N,C,H,W][N, C, H, W][N,C,H,W],在输入全连接层的时候,会自动将数据拉平,
也就是对每个样本,自动将其转化为长度为KKK的向量,
![]()
LeNet在手写数字识别上的应用
LeNet网络的实现代码如下:
# 导入需要的包
import paddle
import numpy as np
from paddle.nn import Conv2D, MaxPool2D, Linear## 组网
import paddle.nn.functional as F# 定义 LeNet 网络结构
class LeNet(paddle.nn.Layer):def __init__(self, num_classes=1):super(LeNet, self).__init__()# 创建卷积和池化层# 创建第1个卷积层self.conv1 = Conv2D(in_channels=1, out_channels=6, kernel_size=5)self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)# 尺寸的逻辑:池化层未改变通道数;当前通道数为6# 创建第2个卷积层self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)# 创建第3个卷积层self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]# 输入size是[28,28],经过三次卷积和两次池化之后,C*H*W等于120self.fc1 = Linear(in_features=120, out_features=64)# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数self.fc2 = Linear(in_features=64, out_features=num_classes)# 网络的前向计算过程def forward(self, x):x = self.conv1(x)# 每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化x = F.sigmoid(x)x = self.max_pool1(x)x = F.sigmoid(x)x = self.conv2(x)x = self.max_pool2(x)x = self.conv3(x)# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]x = paddle.reshape(x, [x.shape[0], -1])x = self.fc1(x)x = F.sigmoid(x)x = self.fc2(x)return x飞桨会根据实际图像数据的尺寸和卷积核参数自动推断中间层数据的W和H等,只需要用户表达通道数即可。下面的程序使用随机数作为输入,查看经过LeNet-5的每一层作用之后,输出数据的形状。
# 输入数据形状是 [N, 1, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[3,1,28,28])
x = x.astype('float32')# 创建LeNet类的实例,指定模型名称和分类的类别数目
model = LeNet(num_classes=10)
# 通过调用LeNet从基类继承的sublayers()函数,
# 查看LeNet中所包含的子层
print(model.sublayers())
x = paddle.to_tensor(x)
for item in model.sublayers():# item是LeNet类中的一个子层# 查看经过子层之后的输出数据形状try:x = item(x)except:x = paddle.reshape(x, [x.shape[0], -1])x = item(x)if len(item.parameters())==2:# 查看卷积和全连接层的数据和参数的形状,# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数bprint(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)else:# 池化层没有参数print(item.full_name(), x.shape)卷积Conv2D的padding参数默认为0,stride参数默认为1,当输入形状为[Bx1x28x28]时,B是batch_size,经过第一层卷积(kernel_size=5, out_channels=6)和maxpool之后,得到形状为[Bx6x12x12]的特征图;经过第二层卷积(kernel_size=5, out_channels=16)和maxpool之后,得到形状为[Bx16x4x4]的特征图;经过第三层卷积(out_channels=120, kernel_size=4)之后,得到形状为[Bx120x1x1]的特征图,在FC层计算之前,将输入特征从卷积得到的四维特征reshape到格式为[B, 120x1x1]的特征,这也是LeNet中第一层全连接层输入shape为120的原因。
# -*- coding: utf-8 -*-
# LeNet 识别手写数字
import os
import random
import paddle
import numpy as np
import paddle
from paddle.vision.transforms import ToTensor
from paddle.vision.datasets import MNIST# 定义训练过程
def train(model, opt, train_loader, valid_loader):# 开启0号GPU训练use_gpu = Truepaddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')print('start training ... ')model.train()for epoch in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):img = data[0]label = data[1] # 计算模型输出logits = model(img)# 计算损失函数loss_func = paddle.nn.CrossEntropyLoss(reduction='none')loss = loss_func(logits, label)avg_loss = paddle.mean(loss)if batch_id % 2000 == 0:print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy())))avg_loss.backward()opt.step()opt.clear_grad()model.eval()accuracies = []losses = []for batch_id, data in enumerate(valid_loader()):img = data[0]label = data[1] # 计算模型输出logits = model(img)pred = F.softmax(logits)# 计算损失函数loss_func = paddle.nn.CrossEntropyLoss(reduction='none')loss = loss_func(logits, label)acc = paddle.metric.accuracy(pred, label)accuracies.append(acc.numpy())losses.append(loss.numpy())print("[validation] accuracy/loss: {:.4f}/{:.4f}".format(np.mean(accuracies), np.mean(losses)))model.train()# 保存模型参数paddle.save(model.state_dict(), 'mnist.pdparams')# 创建模型
model = LeNet(num_classes=10)
# 设置迭代轮数
EPOCH_NUM = 5
# 设置优化器为Momentum,学习率为0.001
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters())
# 定义数据读取器
train_loader = paddle.io.DataLoader(MNIST(mode='train', transform=ToTensor()), batch_size=10, shuffle=True)
valid_loader = paddle.io.DataLoader(MNIST(mode='test', transform=ToTensor()), batch_size=10)
# 启动训练过程
train(model, opt, train_loader, valid_loader)通过运行结果可以看出,LeNet在手写数字识别MNIST验证数据集上的准确率高达92%以上。那么对于其它数据集效果如何呢?我们通过眼疾识别数据集iChallenge-PM验证一下。
LeNet在眼疾识别数据集iChallenge-PM上的应用
iChallenge-PM是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。下面我们详细介绍LeNet在iChallenge-PM上的训练过程。
说明:
如今近视已经成为困扰人们健康的一项全球性负担,在近视人群中,有超过35%的人患有重度近视。近视会拉长眼睛的光轴,也可能引起视网膜或者络网膜的病变。随着近视度数的不断加深,高度近视有可能引发病理性病变,这将会导致以下几种症状:视网膜或者络网膜发生退化、视盘区域萎缩、漆裂样纹损害、Fuchs斑等。因此,及早发现近视患者眼睛的病变并采取治疗,显得非常重要。