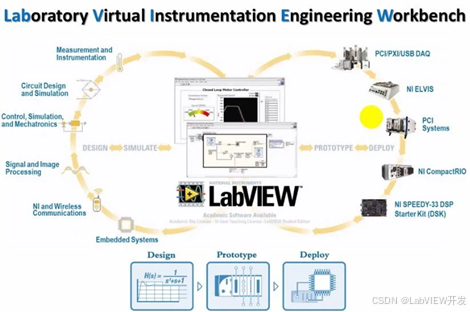
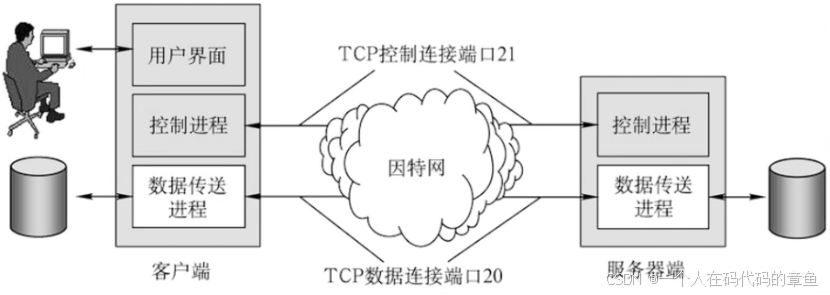
.NET学习资料
.NET学习资料
.NET学习资料
在 C# 编程中,类与对象是面向对象编程的核心概念。它们让开发者能够将数据和操作数据的方法封装在一起,从而构建出模块化、可维护且易于扩展的程序。下面将详细介绍 C# 中类与对象的相关知识。
一、类的定义
类是一种用户自定义的数据类型,它是对象的模板或蓝图。在 C# 中,使用class关键字来定义类。类可以包含字段、属性、方法、构造函数和事件等成员。
1.1 字段
字段是类中用于存储数据的变量。例如,定义一个表示人的类Person,可以包含姓名和年龄的字段:
class Person
{public string Name;public int Age;
}
这里的Name和Age就是Person类的字段,public关键字表示这些字段可以从类的外部访问。
1.2 属性
属性提供了一种灵活的机制来读取、写入或计算私有字段的值。属性有get和set访问器。例如,将上述Person类的字段改为属性:
class Person
{private string name;private int age;public string Name{get { return name; }set { name = value; }}public int Age{get { return age; }set { age = value; }}
}
在这个例子中,Name和Age属性通过get访问器返回私有字段的值,通过set访问器设置私有字段的值。这样可以在设置值时进行一些验证或额外的操作。
1.3 方法
方法是类中执行特定任务的代码块。例如,为Person类添加一个介绍自己的方法:
class Person
{private string name;private int age;public string Name{get { return name; }set { name = value; }}public int Age{get { return age; }set { age = value; }}public void Introduce(){Console.WriteLine($"我叫{Name},今年{Age}岁。");}
}
Introduce方法使用Console.WriteLine输出人的姓名和年龄信息。
1.4 构造函数
构造函数是一种特殊的方法,用于在创建对象时初始化对象的状态。构造函数的名称与类名相同,并且没有返回类型。例如,为Person类添加构造函数:
class Person
{private string name;private int age;public string Name{get { return name; }set { name = value; }}public int Age{get { return age; }set { age = value; }}public Person(string n, int a){name = n;age = a;}public void Introduce(){Console.WriteLine($"我叫{Name},今年{Age}岁。");}
}
这个构造函数接受两个参数n和a,用于初始化name和age字段。
二、对象的创建和使用
2.1 对象的创建
使用new关键字来创建类的对象。例如,创建Person类的对象:
Person person = new Person("张三", 25);
这行代码创建了一个Person类的对象person,并通过构造函数初始化了其姓名为 “张三”,年龄为 25。
2.2 对象的使用
创建对象后,可以通过对象访问其属性和方法。例如:
Person person = new Person("张三", 25);
Console.WriteLine(person.Name);
person.Age = 26;
person.Introduce();
第一行代码创建对象并初始化。第二行通过对象person访问Name属性获取姓名并输出。第三行通过对象person修改Age属性的值。第四行调用person对象的Introduce方法,输出人的介绍信息。
三、类的继承
继承是面向对象编程的重要特性之一,它允许一个类(子类)继承另一个类(父类)的属性和方法。在 C# 中,使用冒号:来表示继承关系。例如:
class Student : Person
{public string School { get; set; }public Student(string n, int a, string s) : base(n, a){School = s;}public new void Introduce(){Console.WriteLine($"我叫{Name},今年{Age}岁,在{School}上学。");}
}
在这个例子中,Student类继承自Person类,它不仅拥有Person类的所有属性和方法,还新增了School属性和重写了Introduce方法。构造函数中使用base关键字调用父类的构造函数来初始化继承自父类的字段。
四、多态
多态是指同一个方法在不同的对象上调用时,可以表现出不同的行为。在 C# 中,多态主要通过方法重写和接口实现来实现。在上述Student类中重写Introduce方法就是多态的体现。当调用Student对象的Introduce方法时,执行的是Student类中重写后的方法,而调用Person对象的Introduce方法时,执行的是Person类中的方法。
五、总结
C# 中的类与对象是构建面向对象程序的基础。通过类的定义,可以将相关的数据和行为封装在一起,提高代码的可维护性和可复用性。对象则是类的具体实例,通过创建和使用对象,可以实现程序的各种功能。继承和多态进一步增强了面向对象编程的灵活性和扩展性。深入理解和掌握类与对象的概念和使用方法,对于成为一名优秀的 C# 开发者至关重要。随着学习的深入,可以进一步探索类的其他特性,如静态成员、嵌套类等,以开发出更复杂和强大的应用程序。

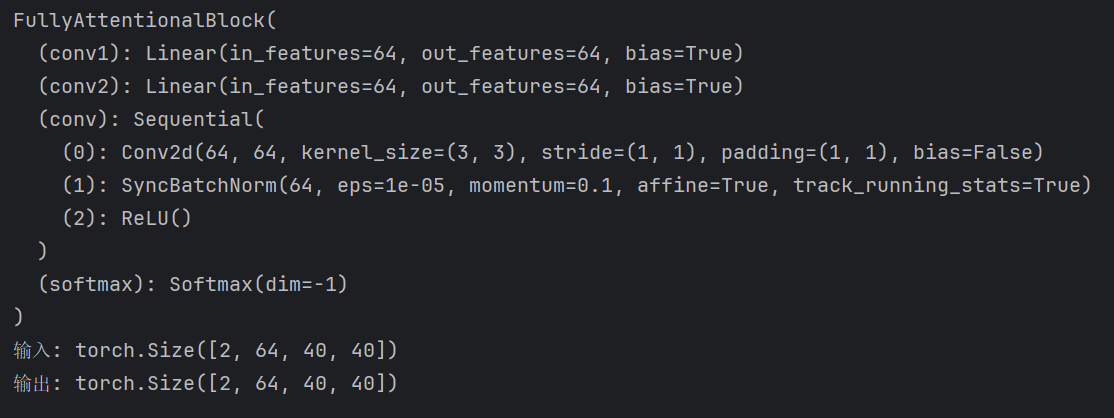



![python算法和数据结构刷题[5]:动态规划](https://i-blog.csdnimg.cn/direct/a18bf42fd18c4f35937d3793bd67de08.png)