论文信息
- 标题: Fully Attentional Network for Semantic Segmentation
- 论文链接: https://arxiv.org/pdf/2112.04108
- GitHub链接: https://github.com/maggiesong7/FullyAttentional

创新点
- 全注意力模块(FLA): 该模块能够在一个相似性图中同时捕捉空间和通道的注意力,解决了传统方法中存在的“注意力缺失”问题。FLA模块通过有效的特征响应收集,增强了模型对小物体和大物体的分割能力。
方法
-
特征提取: 使用ResNet-101或HRNetV2-W48作为基础网络提取特征图。
-
全注意力模块:
- 输入特征图经过卷积处理以减少通道数,得到 ( F i n ) ( F_{in}) (Fin)。
- 通过全注意力模块(FLA)处理 ( F i n ) ( F_{in} ) (Fin),生成经过注意力加权的特征图 ( F o u t ) ( F_{out} ) (Fout)。
- FLA模块结合了空间和通道的注意力机制,确保每个空间位置能够感知到其他位置的特征响应。
-
计算效率: 该方法在保持高性能的同时,显著降低了计算复杂度,适合实时应用。

全注意力模块
全注意力模块(Fully Attentional Block, FLA)是用于语义分割任务的一种新型注意力机制,旨在同时捕捉空间和通道的特征响应。FLA模块通过在单个相似性图中编码这两种注意力,解决了传统方法中存在的“注意力缺失”问题,尤其在处理小物体和大物体时表现出色。
FLA模块的结构主要包括以下几个部分:
-
输入特征图: 输入特征图 F i n F_{in} Fin 经过卷积处理以降低通道数,得到特征图 F i n F_{in} Fin。
-
全局上下文获取:
- 通过全局平均池化,FLA模块生成全局上下文信息,帮助每个空间位置捕捉特征响应。
- 该过程确保每个空间位置能够从具有相同水平和垂直坐标的全局上下文中获取信息。
-
自注意力机制:
- 使用自注意力机制来捕捉任意两个通道图和相关空间位置之间的相似性。
- 通过计算通道之间的相似度,FLA模块能够有效整合来自不同通道的信息。
-
特征更新:
- 通过生成的全注意力相似性 A A A 和特征图 V V V 进行矩阵乘法,更新每个通道图。
- 最终输出的特征图 F o u t F_{out} Fout 是通过将更新后的特征与输入特征图进行加权求和得到的
FLA模块的优势:
- 全面的上下文视图: FLA模块能够捕捉不同空间位置之间的关系,提供更全面的上下文信息。
- 增强特征辨别能力: 通过全局感受野的构建,FLA模块提高了特征的辨别能力,尤其在复杂场景中表现突出。
- 适应性强: FLA模块在处理不同类别和大小的物体时,能够有效提升分割精度,减少小物体的忽略和大物体的分割不一致问题。
效果
- FLANet在多个标准数据集上表现出色,具体性能如下:
- Cityscapes测试集: 83.6%
- ADE20K验证集: 46.99%
- PASCAL VOC测试集: 88.5%
这些结果表明,FLANet在处理复杂场景和多样化物体时,能够有效提高分割精度。
实验结果
-
对比实验: FLANet与传统的全卷积网络(FCN)和其他基于注意力的模型进行了比较,结果显示FLANet在整体准确率和平均交并比(mIoU)上均有显著提升。
-
消融实验: 通过逐步去除或替换模型中的不同组件,验证了全注意力模块在提升模型性能中的关键作用。
总结
FLANet通过引入全注意力机制,成功解决了传统语义分割模型在小物体和大物体分割中的不足。其在多个标准数据集上的优异表现,证明了该方法的有效性和创新性。未来的研究可以进一步探索如何将FLANet应用于更广泛的视觉任务中,以及如何优化其计算效率以适应实时应用场景。
代码
import torch
import torch.nn.functional
import torch.nn.functional as F
from torch import nn
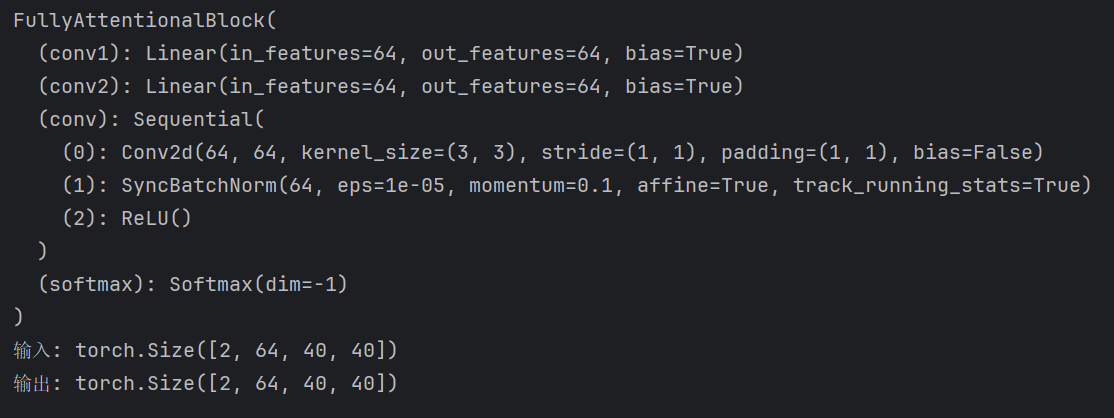
from torch.nn import SyncBatchNormclass FullyAttentionalBlock(nn.Module):def __init__(self, plane, norm_layer=SyncBatchNorm):super(FullyAttentionalBlock, self).__init__()self.conv1 = nn.Linear(plane, plane)self.conv2 = nn.Linear(plane, plane)self.conv = nn.Sequential(nn.Conv2d(plane, plane, 3, stride=1, padding=1, bias=False),norm_layer(plane),nn.ReLU())self.softmax = nn.Softmax(dim=-1)self.gamma = nn.Parameter(torch.zeros(1))def forward(self, x):batch_size, _, height, width = x.size()feat_h = x.permute(0, 3, 1, 2).contiguous().view(batch_size * width, -1, height)feat_w = x.permute(0, 2, 1, 3).contiguous().view(batch_size * height, -1, width)encode_h = self.conv1(F.avg_pool2d(x, [1, width]).view(batch_size, -1, height).permute(0, 2, 1).contiguous())encode_w = self.conv2(F.avg_pool2d(x, [height, 1]).view(batch_size, -1, width).permute(0, 2, 1).contiguous())energy_h = torch.matmul(feat_h, encode_h.repeat(width, 1, 1))energy_w = torch.matmul(feat_w, encode_w.repeat(height, 1, 1))full_relation_h = self.softmax(energy_h) # [b*w, c, c]full_relation_w = self.softmax(energy_w)full_aug_h = torch.bmm(full_relation_h, feat_h).view(batch_size, width, -1, height).permute(0, 2, 3, 1)full_aug_w = torch.bmm(full_relation_w, feat_w).view(batch_size, height, -1, width).permute(0, 2, 1, 3)out = self.gamma * (full_aug_h + full_aug_w) + xout = self.conv(out)return outif __name__ == "__main__":dim=64# 如果GPU可用,将模块移动到 GPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 输入张量 (batch_size, height, width,channels)x = torch.randn(2,dim,40,40).to(device)# 初始化 FullyAttentionalBlock 模块block = FullyAttentionalBlock(dim)print(block)block = block.to(device)# 前向传播output = block(x)print("输入:", x.shape)print("输出:", output.shape)



![python算法和数据结构刷题[5]:动态规划](https://i-blog.csdnimg.cn/direct/a18bf42fd18c4f35937d3793bd67de08.png)