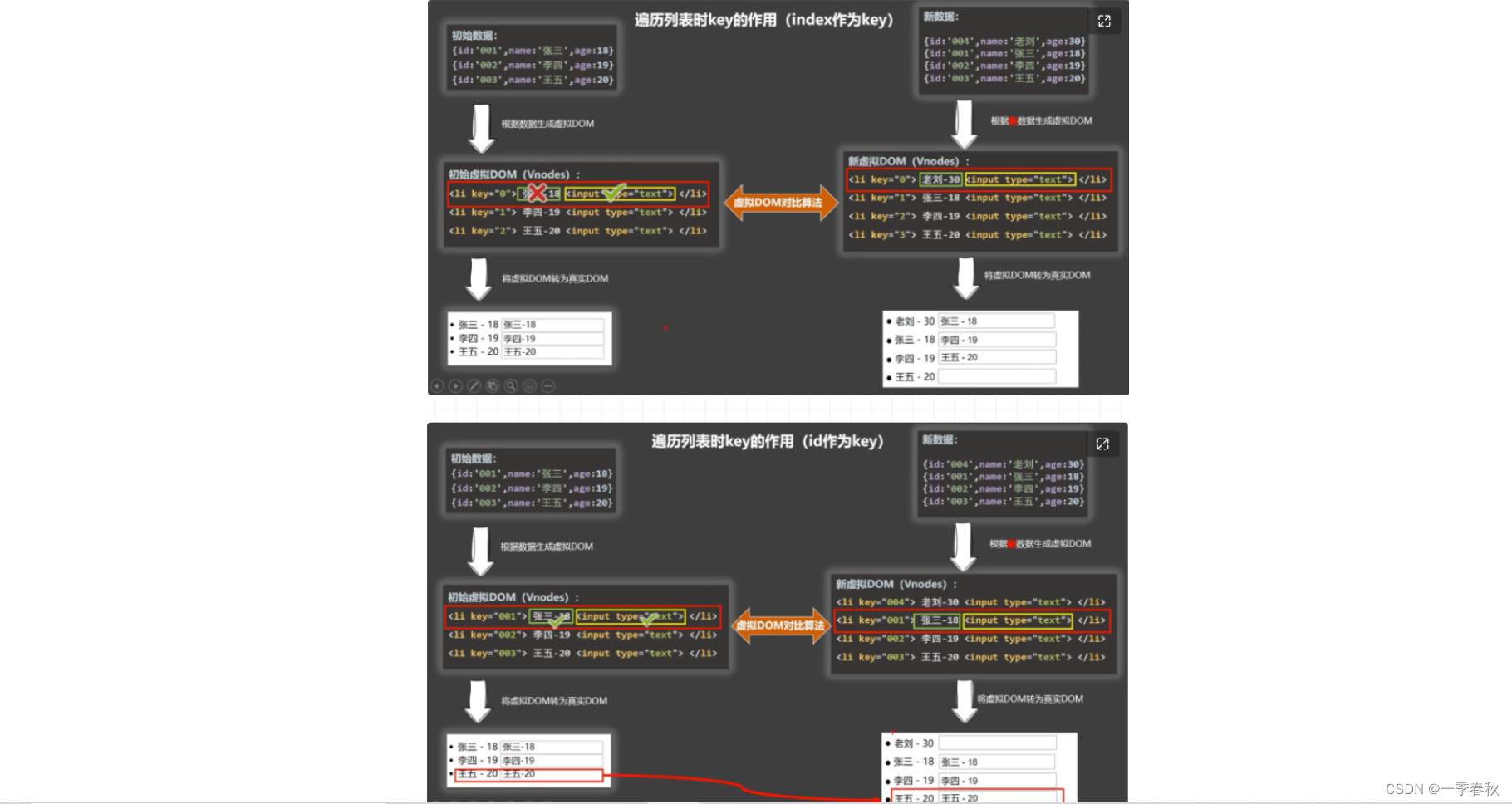
概要
人们对智能语音助手的需求不断提高,语音识别技术也随之迅速发展。在这篇文章中,我们将介绍如何使用Python的SpeechRecognition和pydub等库来实现语音识别和处理,从而打造属于自己的智能语音助手。
1. 什么是语音识别?
语音识别,也称为语音转文本(STT),是一种技术,可以将人类语音转换为计算机可以理解的文本形式。这种技术已经被广泛应用于许多领域,包括自然语言处理、机器翻译、语音识别等。
SpeechRecognition是Python中最受欢迎的语音识别库之一。它支持多种后端引擎(如Google,IBM和CMU Sphinx),并具有良好的跨平台性。
2. 如何使用SpeechRecognition进行语音识别?
使用SpeechRecognition进行语音识别非常简单。下面是一个基本的例子:
import speech_recognition as srr = sr.Recognizer()with sr.AudioFile('audio.wav') as source:audio = r.record(source)text = r.recognize_google(audio)print(text)
在这个例子中,我们使用sr.AudioFile打开音频文件,使用r.record记录音频,并使用r.recognize_google识别音频中的文本。SpeechRecognition支持多种引擎,如Google,IBM和CMU Sphinx。您可以根据需要选择不同的引擎。
3. 语音识别的局限性
虽然语音识别技术已经非常先进,但仍然存在一些局限性。例如:
-
多音字:当一个单词有多个不同的发音或拼写时,语音识别系统可能会出现困难。
-
噪音:如果音频中有太多的噪音,语音识别系统可能会受到干扰。
-
口音和方言:语音识别系统可能会难以处理来自不同口音和方言的人的语音。
4. 如何处理音频文件?
音频文件通常以.mp3,.wav等格式存在。pydub是一个强大的Python库,可以用于处理音频文件。以下是一些常见的用法:
-
从音频文件中提取音频片段
from pydub import AudioSegmentsong = AudioSegment.from_mp3("song.mp3")
extract = song[20*1000:30*1000] #提取20到30秒
extract.export("extract.mp3", format="mp3")
-
合并多个音频文件
from pydub import AudioSegmentsound1 = AudioSegment.from_wav("sound1.wav")
sound2 = AudioSegment.from_wav("sound2.wav")
combined = sound1 + sound2
combined.export("combined.wav", format="wav")
-
调整音频音量
from pydub import AudioSegmentsound = AudioSegment.from_wav("sound.wav")
louder = sound + 10 #增加10分贝
louder.export("louder.wav", format="wav")
5. 如何使用语音识别和处理来打造智能语音助手?
我们可以将语音识别和处理技术与其他技术(如自然语言处理和机器学习)相结合,以创建强大的智能语音助手。下面是一个简单的例子,用于通过语音命令控制智能家居设备:
import speech_recognition as sr
import pyttsx3engine = pyttsx3.init()def process_command(command):if "灯" in command:if "开" in command:print("开灯")engine.say("已开灯")engine.runAndWait()elif "关" in command:print("关灯")engine.say("已关灯")engine.runAndWait()r = sr.Recognizer()while True:with sr.Microphone() as source:print("请说话")audio = r.listen(source)try:text = r.recognize_google(audio, language='zh-CN')print(f"您说了: {text}")process_command(text)except Exception as e:print(e)
在这个例子中,我们使用SpeechRecognition来识别语音命令,并使用pyttsx3来回复用户。我们还定义了一个process_command函数,用于处理不同的命令。
可以看到这种命令解析其实就是市面上大部分所谓AI智能助手的处理方案——穷举法。如果想更加智能,更通用地理解语义,可考虑融合NLP技术,相关文章可以看底部链接。
语音识别和处理技术已经变得非常成熟,可以在许多领域中得到广泛应用。使用Python的SpeechRecognition和pydub等库,我们可以很容易地实现语音识别和处理。将这些技术与其他技术(如自然语言处理和机器学习)相结合,可以创建强大的智能语音助手,为人们带来更好的生活体验。