文章目录
- 一、数据源获取
- 1、从集合中获取
- 2、从外部存储系统创建
- 3、从其它RDD中创建
- 4、分区规则—load数据时
- 二、转换算子(Transformation)
- 1、Value类型
- 1.1 map()_
- 1.2 mapPartitions()
- 1.3 mapPartitionsWithIndex(不常用)
- 1.4 filterMap()_扁平化(合并流)
- 1.5 groupBy()_分组
- 1.6 filter()_过滤
- 1.7 distinct()_去重
- 1.8 coalesce()_合并分区
- 1.9 repartition()_重新分区
- 1.10 sortBy()_排序
- 1.11 map和mapPartitions区别
- 1.12 coalesce和repartition区别
- 2、双-Value类型
- 2.1 intersection()_交集
- 2.2 union()_并集不去重
- 2.3 subtract()_差集
- 2.4 zip()_拉链
- 3、Key—Value类型
- 3.1 partitionBy()_按照K重新分区
- 3.2 groupByKey()_按照K重新分组
- 3.3 reduceByKey()_按照K聚合V
- 3.4 aggregateByKey()_不同逻辑的归约
- 3.5 sortByKey()_按照K进行排序
- 3.6 mapValues()_只对V进行操作
- 3.7 join()_等同于sql内连接
- 3.8 cogroup()_类似于sql全连接
- 3.9 自定义分区器
- 3.10 reduceByKey和groupByKey区别
- 三、行动算子(Action)
- 1、collect()_以数组的形式返回数据集
- 2、count()_返回RDD中元素个数
- 3、first()_返回RDD中的第一个元素
- 4、take()_返回由RDD前n个元素组成的数组
- 5、takeOrdered()_返回排序后前n个元素
- 6、countByKey()_统计每种key的个数
- 7、saveAsTextFile(path)_保存成Text文件
- 8、saveAsSequenceFile(path)_保存成Sequencefile文件
- 9、saveAsObjectFile(path)_序列化成对象保存到文件
- 10、foreach()_遍历RDD中每一个元素
一、数据源获取
1、从集合中获取
sc.parallelize(list)
sc.makeRDD(list)
sc.makeRDD(list, 2)
val list: List[Int] = List(1, 2, 3, 4, 5)
// 从List中创建RDD
val rdd01: RDD[Int] = sc.parallelize(list)
// 底层调用parallelize。从结合list中获取数据
val rdd02: RDD[Int] = sc.makeRDD(list)
// 2:分区数量为2
val rdd03: RDD[Int] = sc.makeRDD(list, 2)
2、从外部存储系统创建
// 从文件中获取
sc.textFile("input/1.txt")
// 无论文件中存储的是什么数据,读取过来都当字符串进行处理
val rdd04: RDD[String] = sc.textFile("input/1.txt")
3、从其它RDD中创建
在其它执行步骤完成后,生成新的RDD对象
val rdd05: RDD[String] = rdd04.map(_ * 2)
4、分区规则—load数据时
从集合中创建
从文件中创建
二、转换算子(Transformation)
// 1、创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCore").setMaster("local[*]")
// 2、创建SparkContext,该对象时提交Spark APP 的入口
val sc = new SparkContext(conf)
// 3、创建RDD
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// 4、具体执行步骤
val rdd01: RDD[Int] = rdd.map(x => x * 20)
// 5、打印结果
println(rdd01.collect().toList)
// 6、关闭连接
sc.stop()
1、Value类型
1.1 map()_
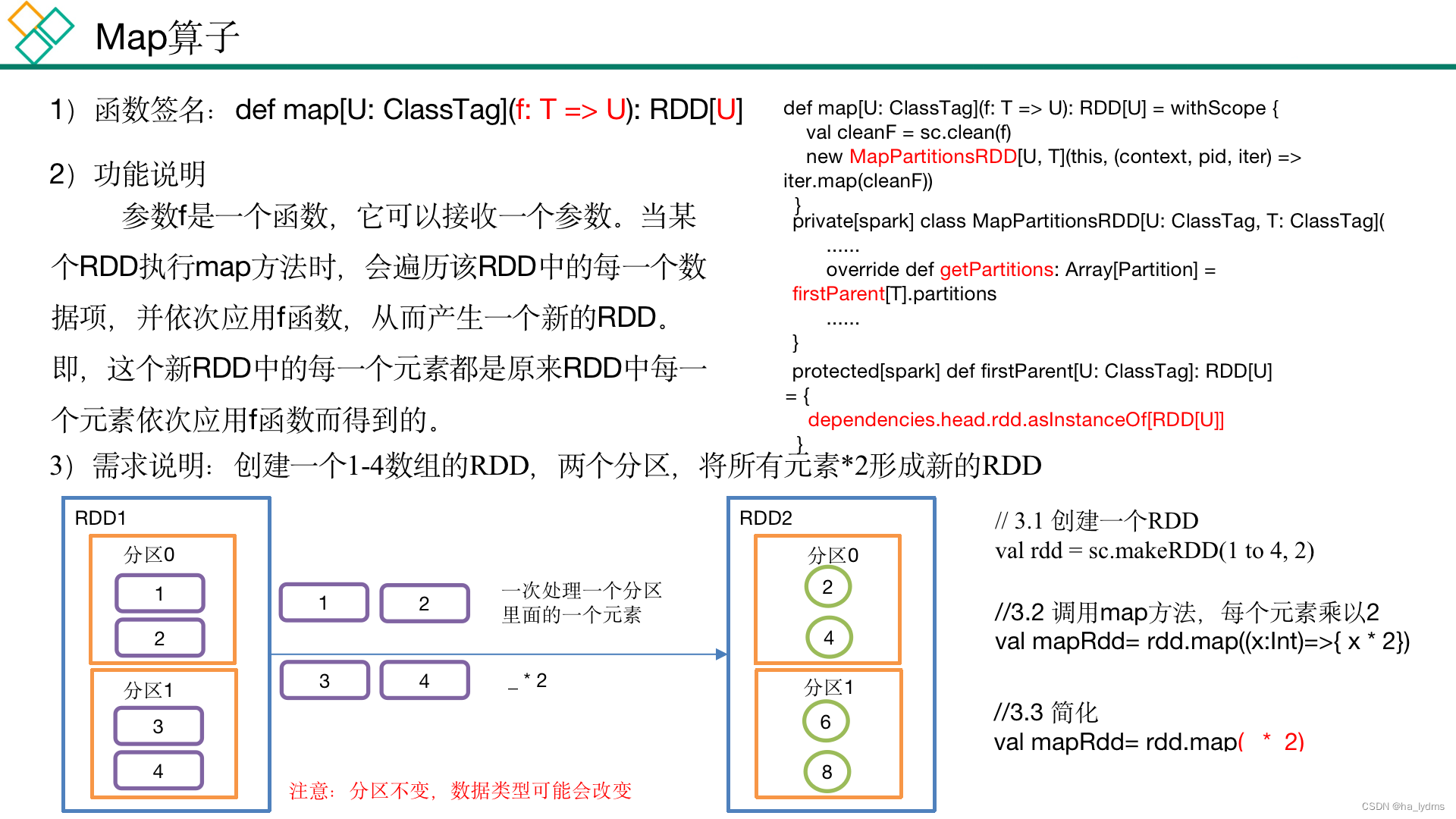
// 4、具体执行步骤
val rdd01: RDD[Int] = rdd.map(x => x * 20)
// 4、具体执行步骤
val rdd02: RDD[Int] = rdd01.map(_ * 20)
1.2 mapPartitions()
以分区为单位执行的map()

1.3 mapPartitionsWithIndex(不常用)
- 里面的函数针对每个分区操作,分区有多少个,函数就执行多少次。
- 函数的第一个参数代表分区号。
- 函数的第二个参数代表分区数据迭代器。
/**** @param f 分区编号* @param preservesPartitioning 分区数据迭代器*/
def mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean = false): RDD[U] = withScope {}
rdd03.mapPartitionsWithIndex((index, items) => {items.map((index, _))
})
// 指定迭代器规则,并使用分区数据迭代器
rdd03.mapPartitionsWithIndex((index, items) => {items.map((index, _))
}, preservesPartitioning = true)
1.4 filterMap()_扁平化(合并流)
扁平化(合并流)
功能说明
- 与map操作类似,将RDD中的每一个元素通过应用f函数依次转换为新的元素,并封装到RDD中。
- 区别:在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的RDD中。

def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {}
val rdd08: RDD[List[Int]] = sc.makeRDD(List(List(1, 2), List(3, 4), List(5, 6)), 2)
val rdd09: RDD[Int] = rdd08.flatMap(list => list)
// List(1, 2, 3, 4, 5, 6)
println(rdd09.collect().toList)
1.5 groupBy()_分组
分组
按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。
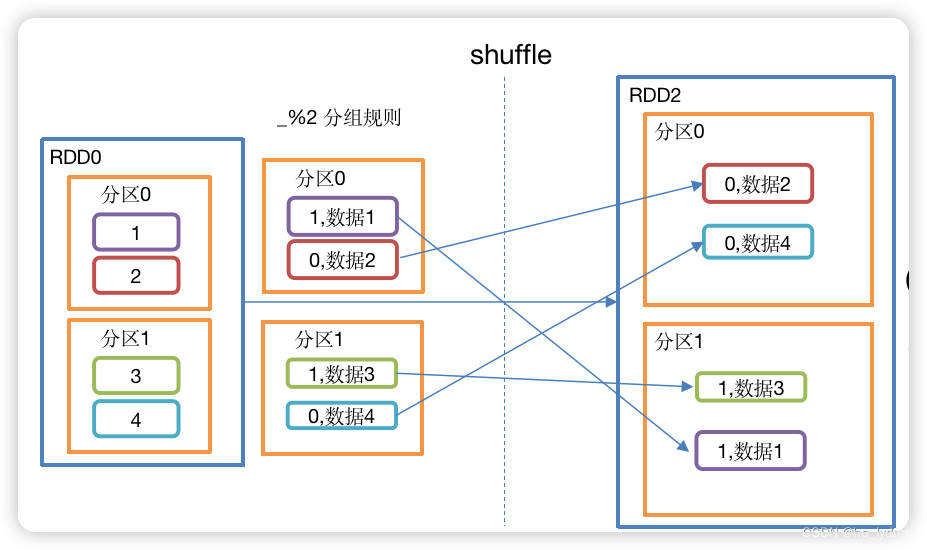

def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {groupBy[K](f, defaultPartitioner(this))
}
案例
// 3.2 将每个分区的数据放到一个数组并收集到Driver端打印
rdd.groupBy((x)=>{x%2})
// 简化
rdd.groupBy(_%2)
val rdd10: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
// (0,CompactBuffer(2, 4, 6, 8))
// (1,CompactBuffer(1, 3, 5, 7, 9))
rdd10.groupBy(_ % 2).collect().foreach(println)
val rdd11: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 3)
// 按照数字相同进行分区
// (3,CompactBuffer(3))
// (4,CompactBuffer(4))
// (1,CompactBuffer(1))
// (5,CompactBuffer(5))
// (2,CompactBuffer(2))
rdd11.groupBy(a => a).collect().foreach(println)
1.6 filter()_过滤
过滤
接收一个返回值为布尔类型的函数作为参数。当某个RDD调用filter方法时,会对该RDD中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的RDD中。
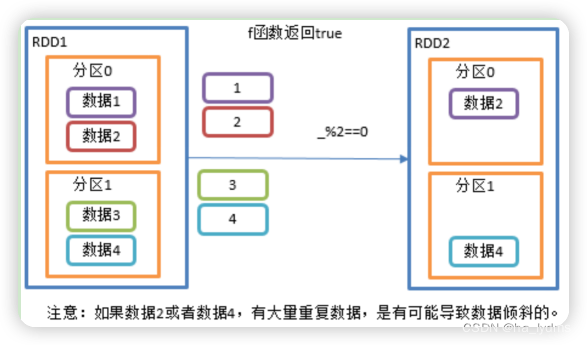
rdd11.filter(a => a % 2 == 0)
rdd11.filter(_% 2 == 0)
val rdd11: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
val rdd110: RDD[Int] = rdd11.filter(a => a % 2 == 0)
// List(2, 4, 6, 8)
println(rdd110.collect().toList)
1.7 distinct()_去重
去重
- 对内部的元素去重,并将去重后的元素放到新的RDD中。
- 默认情况下,distinct会生成与原RDD分区个数一致的分区数。
- 用分布式的方式去重比HashSet集合方式不容易OOM。
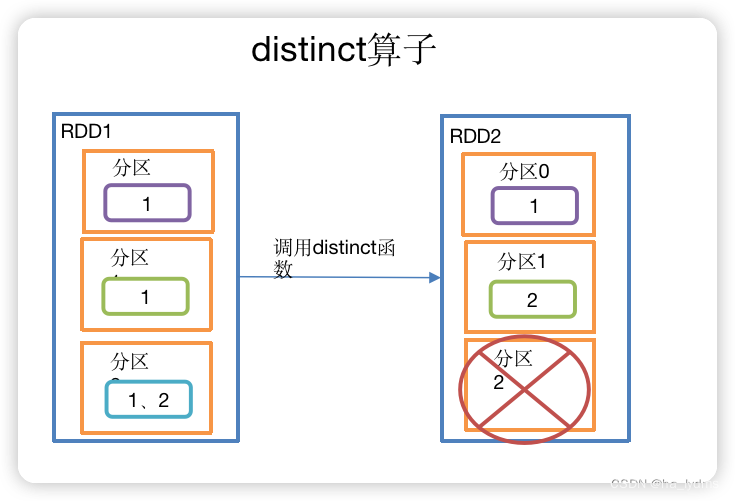
// 去重
rdd.distinct()
// 去重(2并发度)
rdd.distinct(2)
val rdd12: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 2, 3), 3)
// List(3, 4, 1, 2)
println(rdd12.distinct().collect().toList)
// List(4, 2, 1, 3)(采用多个Task提高并发读)
println(rdd12.distinct(2).collect().toList)
1.8 coalesce()_合并分区
合并分区
- Coalesce算子包括:配置执行Shuffle和配置不执行Shuffle两种方式。
- 缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。
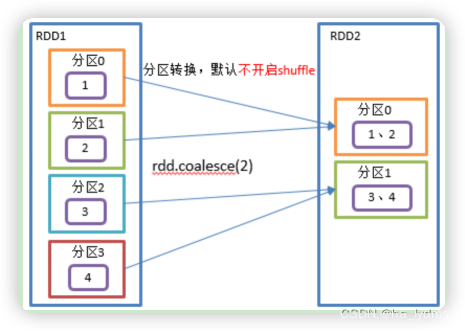
rdd13.coalesce(2)
rdd14.coalesce(2, shuffle = true)
缩减分区并执行Shuffer
val rdd14: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
// 缩减分区为2个
val rdd131: RDD[Int] = rdd13.coalesce(2)
// 缩减分区为2个,并执行Shuffer
val rdd141: RDD[Int] = rdd14.coalesce(2, shuffle = true)
1.9 repartition()_重新分区
重新分区
- 执行Shuffle。
- 该操作内部其实执行的是coalesce操作,参数shuffle的默认值为true。
- 无论是将分区数多的RDD转换为分区数少的RDD,还是将分区数少的RDD转换为分区数多的RDD,repartition操作都可以完成,因为无论如何都会经shuffle过程。
- 分区规则不是hash,因为平时使用的分区都是按照hash来实现的,repartition一般是对hash的结果不满意,想要打散重新分区。
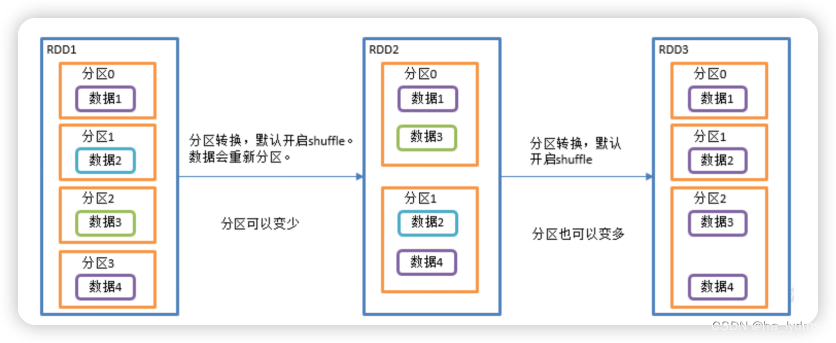
rdd.repartition(2)
val rdd15: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
// 重新分区
val rdd151: RDD[Int] = rdd15.repartition(2)
1.10 sortBy()_排序
排序
- 该操作用于排序数据。
- 在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排列。
- 排序后新产生的RDD的分区数与原RDD的分区数一致。
- 实现正序和倒序排序。
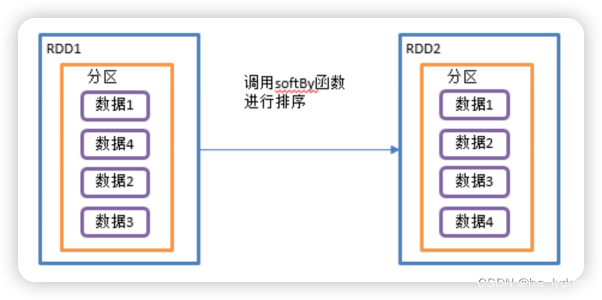
// 正序
rdd.sortBy(num => num)
// 倒叙
rdd.sortBy(num => num, ascending = false)
案例:
val rdd16: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
// 重新排序,默认升序
val rdd161: RDD[Int] = rdd16.sortBy(num => num)
// 重新排序,配置降序
val rdd162: RDD[Int] = rdd16.sortBy(num => num, ascending = false)
val rdd17: RDD[(Int, Int)] = sc.makeRDD(List((1, 2), (3, 4), (5, 6)))
// 先按照第1个值升序,在按第2个值排序
val rdd171: RDD[(Int, Int)] = rdd17.sortBy(num => num)
1.11 map和mapPartitions区别
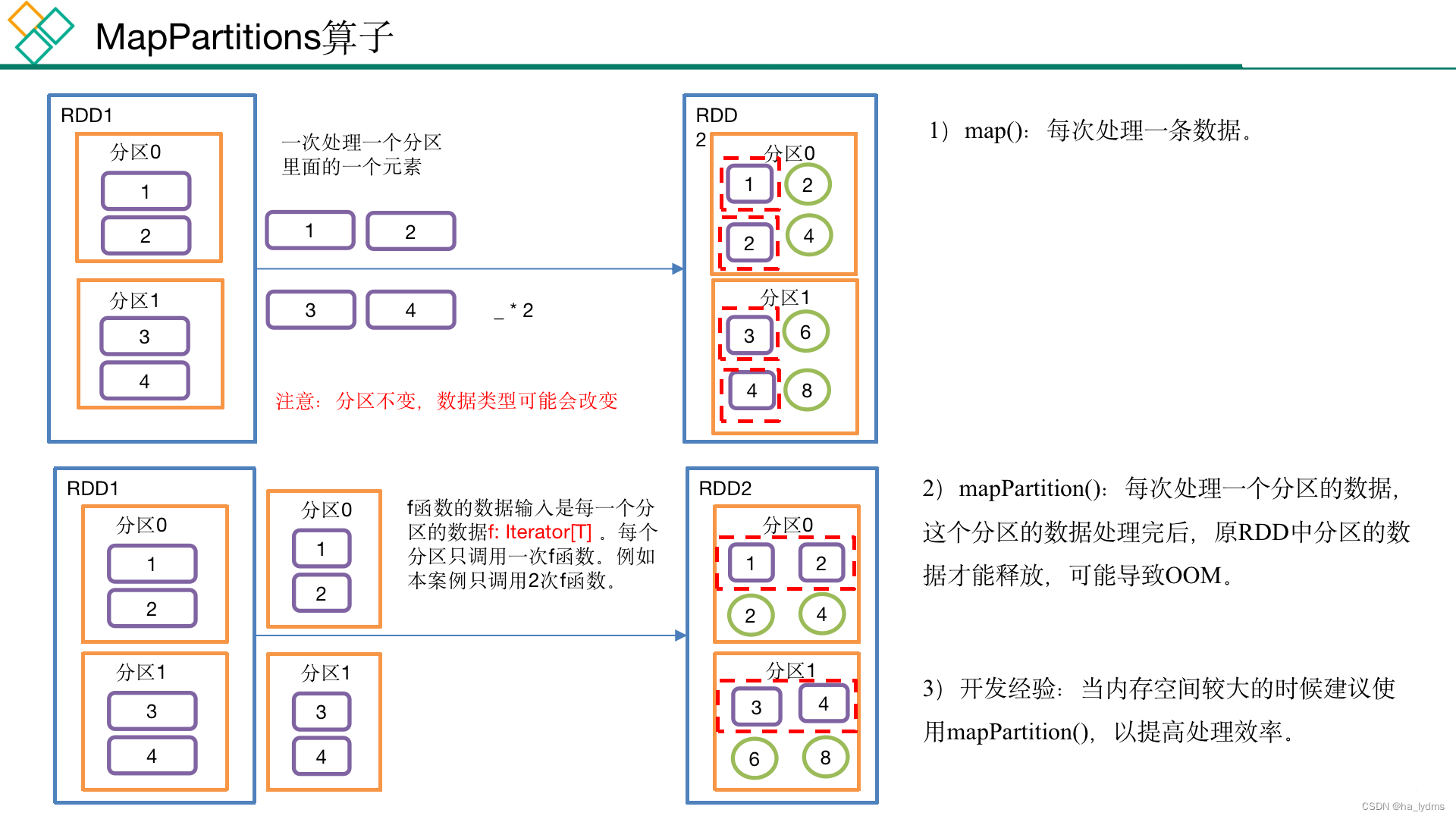
map与mapPartitions的区别
- 函数针对的对象不一样
- map的函数是针对每个元素操作
- mapPartitions的函数是针对每个分区操作
- 函数的返回值不一样
- map的函数是针对每个元素操作,要求返回一个新的元素,map生成的新RDD元素个数 = 原RDD元素个数
- mapPartitions的函数是针对分区操作,要求返回新分区的迭代器,mapPartitions生成新RDD元素个数不一定=原RDD元素个数
- 元素内存回收的时机不一样
- map对元素操作完成之后就可以垃圾回收了
- mapPartitions必须要等到分区数据迭代器里面数据全部处理完成之后才会统一垃圾回收,如果分区数据比较大可能出现内存溢出,此时可以用map代替。
val rdd02: RDD[Int] = rdd01.mapPartitions(a => a.map(b => b * 2))
val rdd03: RDD[Int] = rdd02.mapPartitions(a => a.map(_ * 2))
1.12 coalesce和repartition区别
- coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle: Boolean = false/true决定。
- repartition实际上是调用的coalesce,进行shuffle。源码如下:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {coalesce(numPartitions, shuffle = true)
}
- coalesce一般为缩减分区,如果扩大分区,不使用shuffle是没有意义的,repartition扩大分区执行shuffle。
2、双-Value类型
2.1 intersection()_交集
并集不去重
- 对源RDD和参数RDD求交集后返回一个新的RDD。
- 利用shuffle的原理进行求交集 ,需要将所有的数据落盘shuffle 效率很低
- 不推荐使用
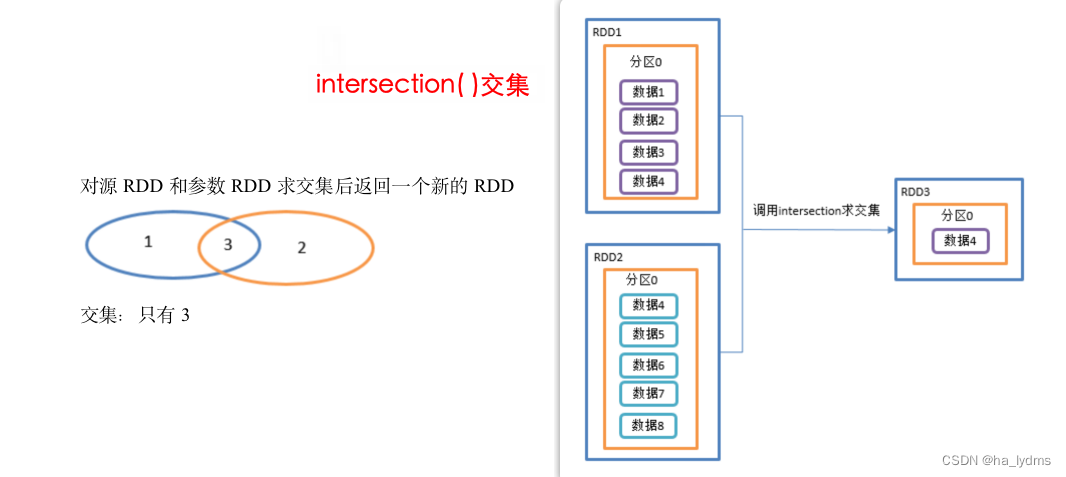
println(rdd01.intersection(rdd02)
val rdd01: RDD[Int] = sc.makeRDD(1 to 4)
val rdd02: RDD[Int] = sc.makeRDD(4 to 8)
// 取交集
// 利用shuffle的原理进行求交集 需要将所有的数据落盘shuffle 效率很低 不推荐使用
println(rdd01.intersection(rdd02).collect().toList)
2.2 union()_并集不去重
并集不去重
- 对源RDD和参数RDD求并集后返回一个新的RDD
- 由于不走shuffle ,效率高 。
- 所有会使用到
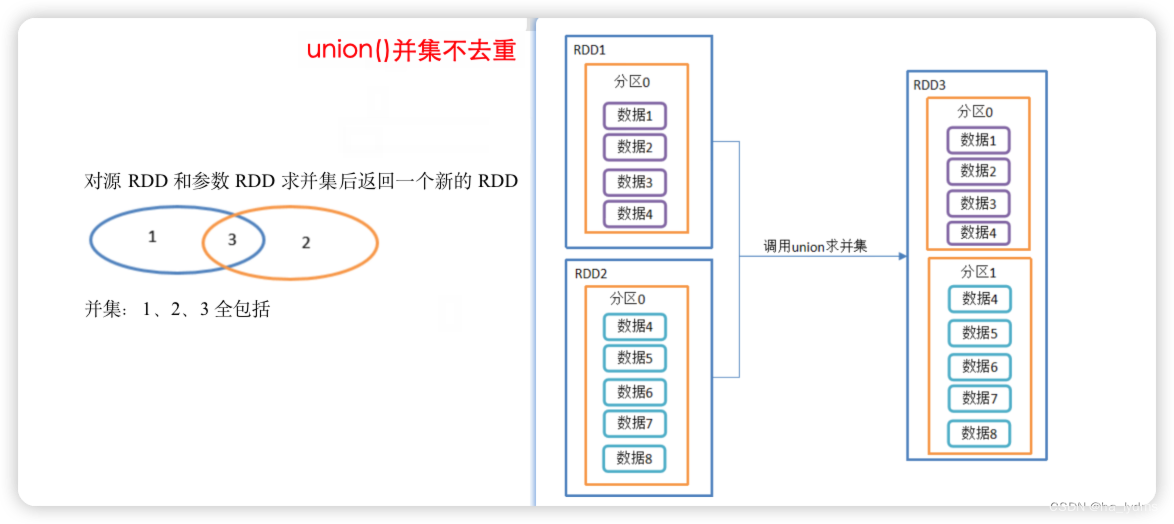
rdd1.union(rdd2)
val rdd01: RDD[Int] = sc.makeRDD(1 to 4)
val rdd02: RDD[Int] = sc.makeRDD(4 to 8)
// 由于不走shuffle 效率高 所有会使用到
rdd1.union(rdd2).collect().foreach(println)
2.3 subtract()_差集
差集
- 计算差的一种函数,去除两个RDD中相同元素,不同的RDD将保留下来。
- 同样使用shuffle的原理,将两个RDD的数据写入到相同的位置,进行求差集
- 需要走shuffle 效率低,不推荐使用
- 在rdd01的数据中,与rdd02相差的数据(1,2,3)
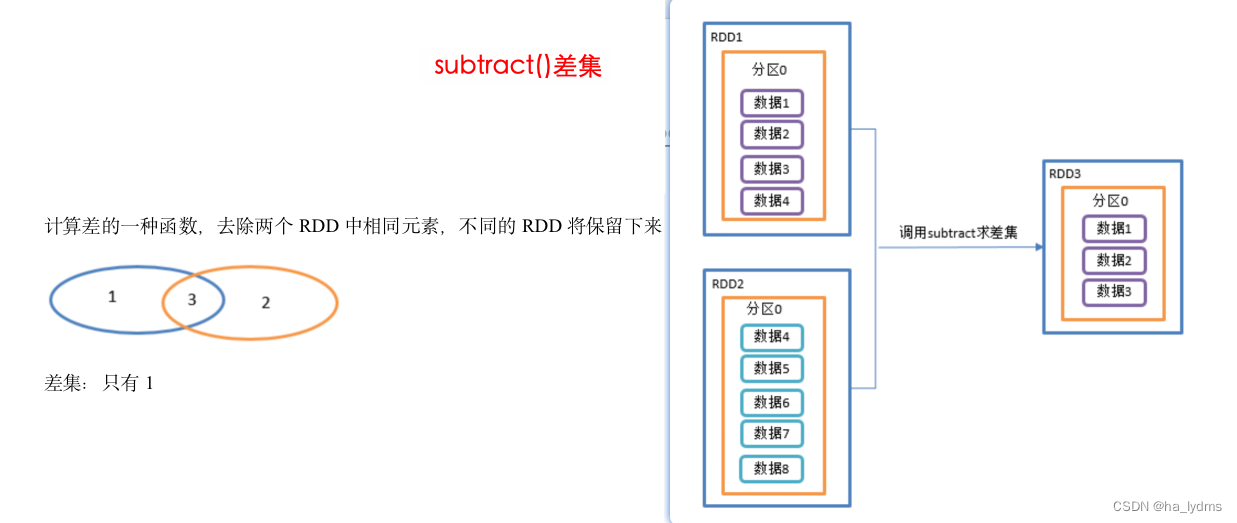
// 计算第一个RDD与第二个RDD的差集并打印
rdd01.subtract(rdd02)
val rdd01: RDD[Int] = sc.makeRDD(1 to 4)
val rdd02: RDD[Int] = sc.makeRDD(4 to 8)
// 同样使用shuffle的原理 将两个RDD的数据写入到相同的位置 进行求差集
// 需要走shuffle 效率低 不推荐使用
// 在rdd01的数据中,与rdd02相差的数据(1,2,3)
rdd01.subtract(rdd02).collect().foreach(println)
2.4 zip()_拉链
拉链
- 该操作可以将两个RDD中的元素,以键值对的形式进行合并。
- 其中,键值对中的Key为第1个RDD中的元素,Value为第2个RDD中的元素。
- 将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
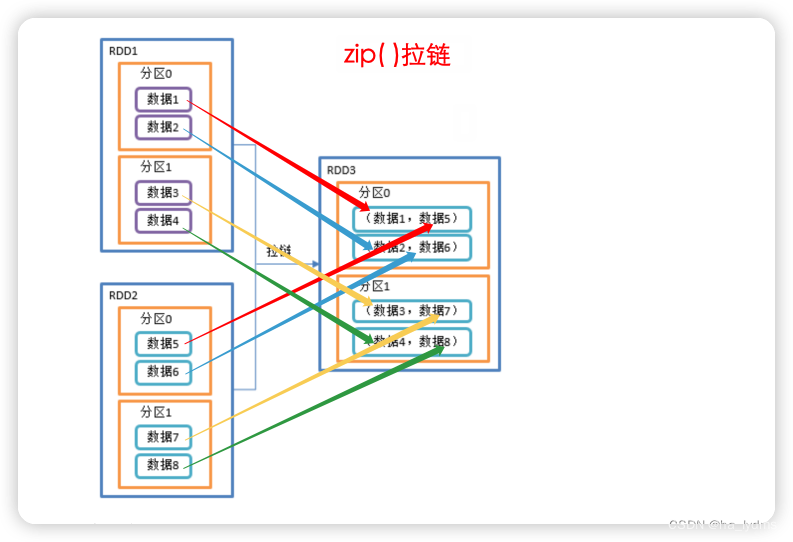
val rdd01: RDD[Int] = sc.makeRDD(Array(1, 2, 3), 3)
val rdd02: RDD[String] = sc.makeRDD(Array("a", "b", "c"), 3)
// List((1,a), (2,b), (3,c))
println(rdd01.zip(rdd02).collect().toList)
// List((a,1), (b,2), (c,3))
println(rdd02.zip(rdd01).collect().toList)
反例:
val rdd02: RDD[String] = sc.makeRDD(Array("a", "b", "c"), 3)val rdd03: RDD[String] = sc.makeRDD(Array("a", "b"), 3)
// 元素个数不同,不能拉链
// SparkException: Can only zip RDDs with same number of elements in each partition
println(rdd03.zip(rdd02).collect().toList)
val rdd04: RDD[String] = sc.makeRDD(Array("a", "b", "c"), 2)
// 分区数不同,不能拉链
// java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions: List(2, 3)
println(rdd04.zip(rdd02).collect().toList)
3、Key—Value类型
3.1 partitionBy()_按照K重新分区
按照K重新分区
- 将RDD[K,V]中的K按照指定Partitioner重新进行分区;
- 如果原有的RDD和新的RDD是一致的话就不进行分区,否则会产生Shuffle过程。
- 分区数量会改变。
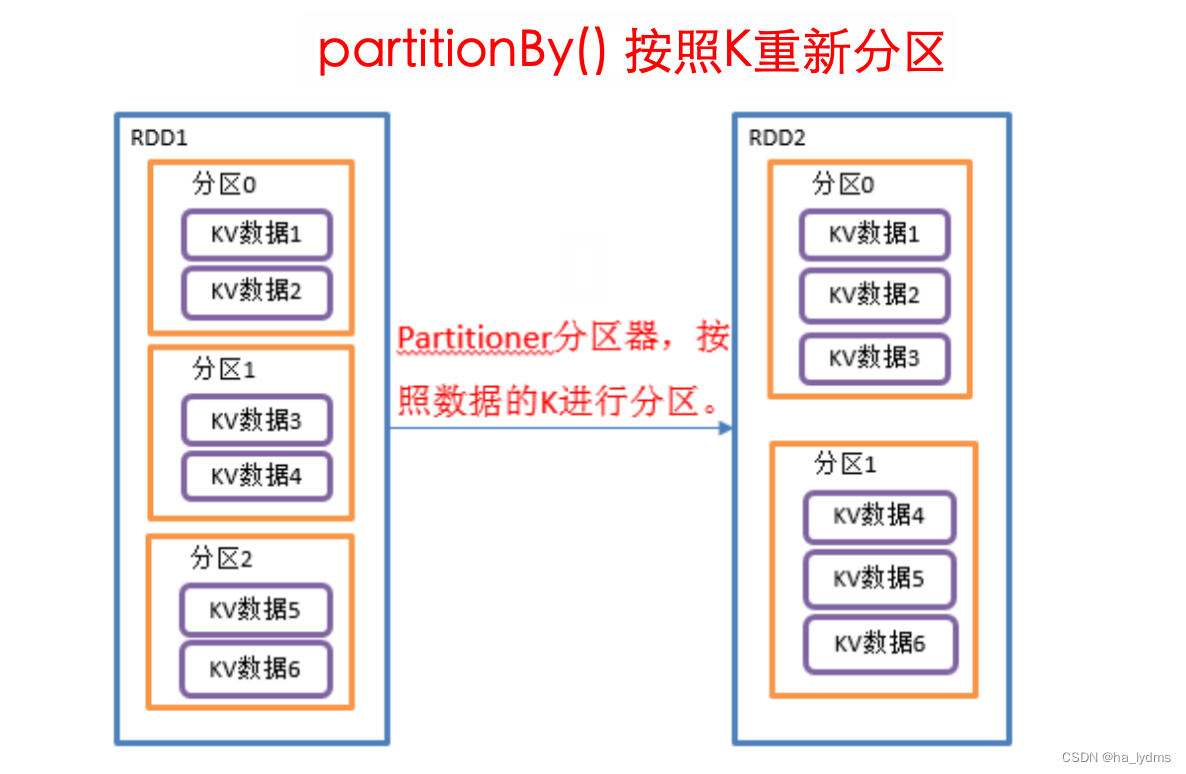
// 使用hash计算方式重分区,并重分区后分区数量 = 2
rdd01.partitionBy(new HashPartitioner(2))
val rdd01: RDD[(Int, String)] = sc.makeRDD(Array((111, "aaa"), (222, "bbbb"), (333, "ccccc")), 3)
val rdd02: RDD[(Int, String)] = rdd01.partitionBy(new HashPartitioner(2))// 打印重分区后的分区数量
// (0,(2,bbbb))
// (1,(1,aaa))
// (1,(3,ccccc))
val rdd03: RDD[(Int, (Int, String))] = rdd02.mapPartitionsWithIndex((index, datas) => {datas.map((index, _))
})
rdd03.collect().foreach(println)
3.2 groupByKey()_按照K重新分组
按照K重新分组
- groupByKey对每个key进行操作,但只生成一个seq,并不进行聚合。
- 该操作可以指定分区器或者分区数(默认使用HashPartitioner)。
- 分区数量不会改变。
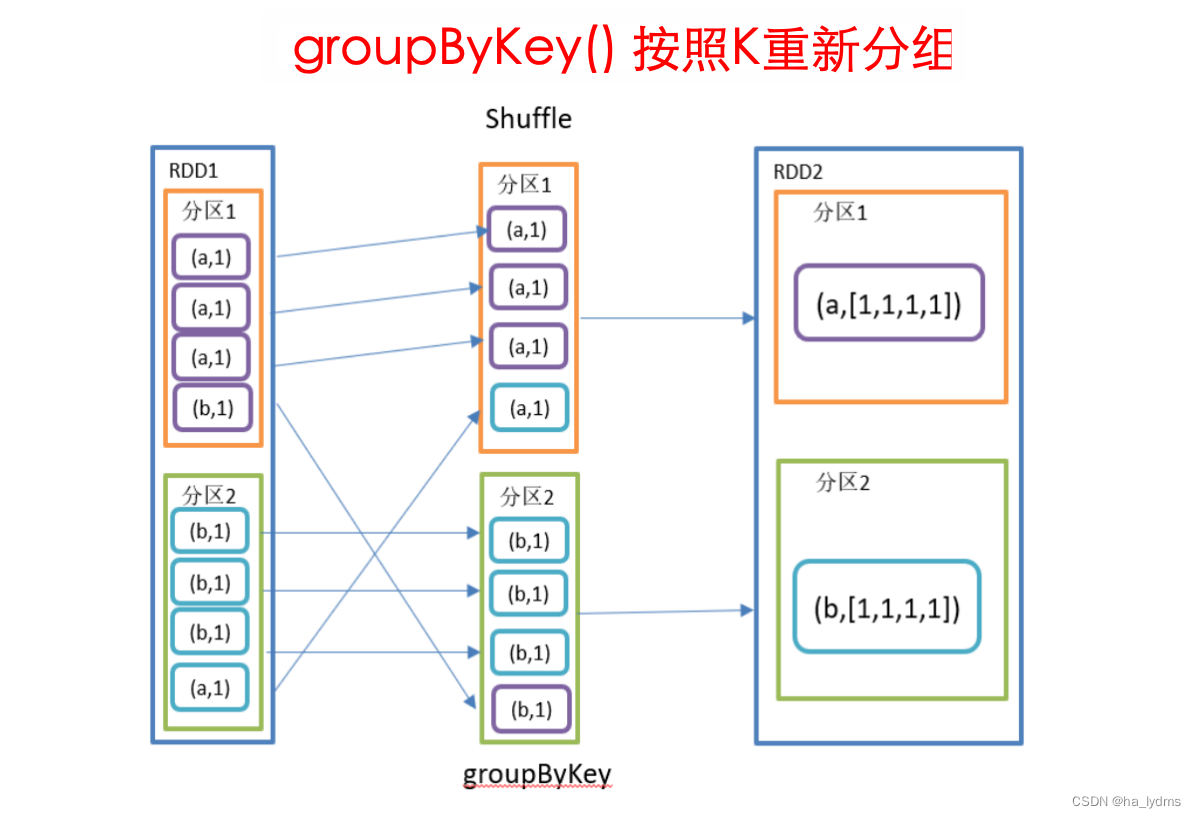
rdd001.groupByKey()
val rdd001: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 5), ("a", 5), ("b", 2)
val rdd002: RDD[(String, Iterable[Int])] = rdd001.groupByKey()
// (a,CompactBuffer(1, 5))
// (b,CompactBuffer(5, 2))
rdd002.collect().foreach(println)
3.3 reduceByKey()_按照K聚合V
按照K聚合V
- 该操作可以将RDD[K,V]中的元素按照相同的K对V进行聚合。
- 其存在多种重载形式,还可以设置新RDD的分区数。
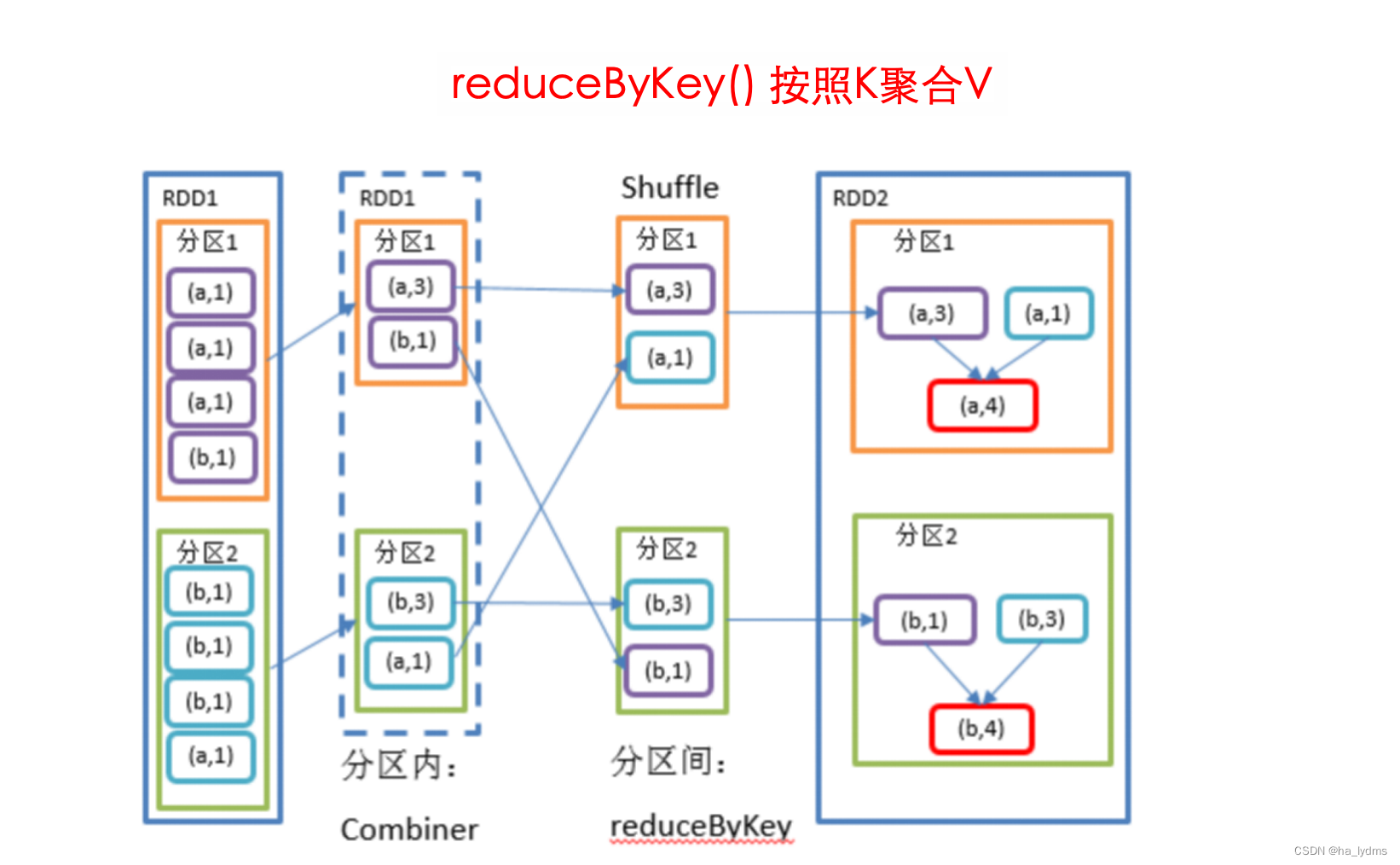
rdd01.reduceByKey((v1, v2) => (v1 + v2))
val rdd01: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 5), ("a", 5), ("b", 2)))
val rdd02: RDD[(String, Int)] = rdd01.reduceByKey((v1, v2) => (v1 + v2))
// List((a,6), (b,7))
println(rdd02.collect().toList)
3.4 aggregateByKey()_不同逻辑的归约
分区内和分区间逻辑不同的归约
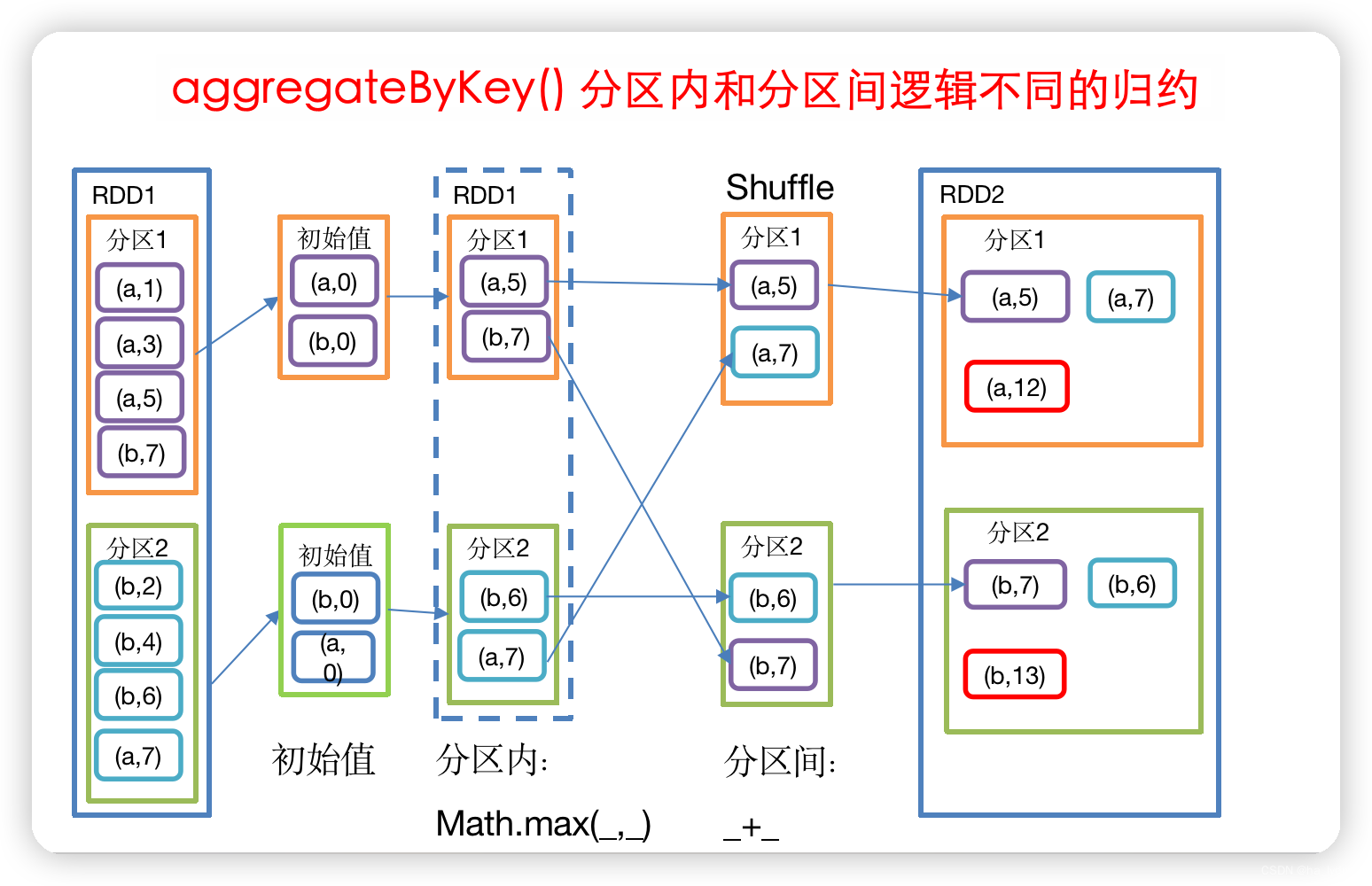
// zeroValue(初始值):给每一个分区中的每一种key一个初始值;
// seqOp(分区内):函数用于在每一个分区中用初始值逐步迭代value;
// combOp(分区间):函数用于合并每个分区中的结果。def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)] = self.withScope {}
// 分区初始值=0,分区内取最大值,分区间求和
rdd01.aggregateByKey(0)(math.max(_, _), _ + _)
val rdd01: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 5), ("a", 5), ("b", 2)))
// 取出每个分区相同key对应值的最大值,然后相加
val rdd02: RDD[(String, Int)] = rdd01.aggregateByKey(0)(math.max(_, _), _ + _)
// List((a,6), (b,7))
println(rdd02.collect().toList)
3.5 sortByKey()_按照K进行排序
按照K进行排序
- 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD。
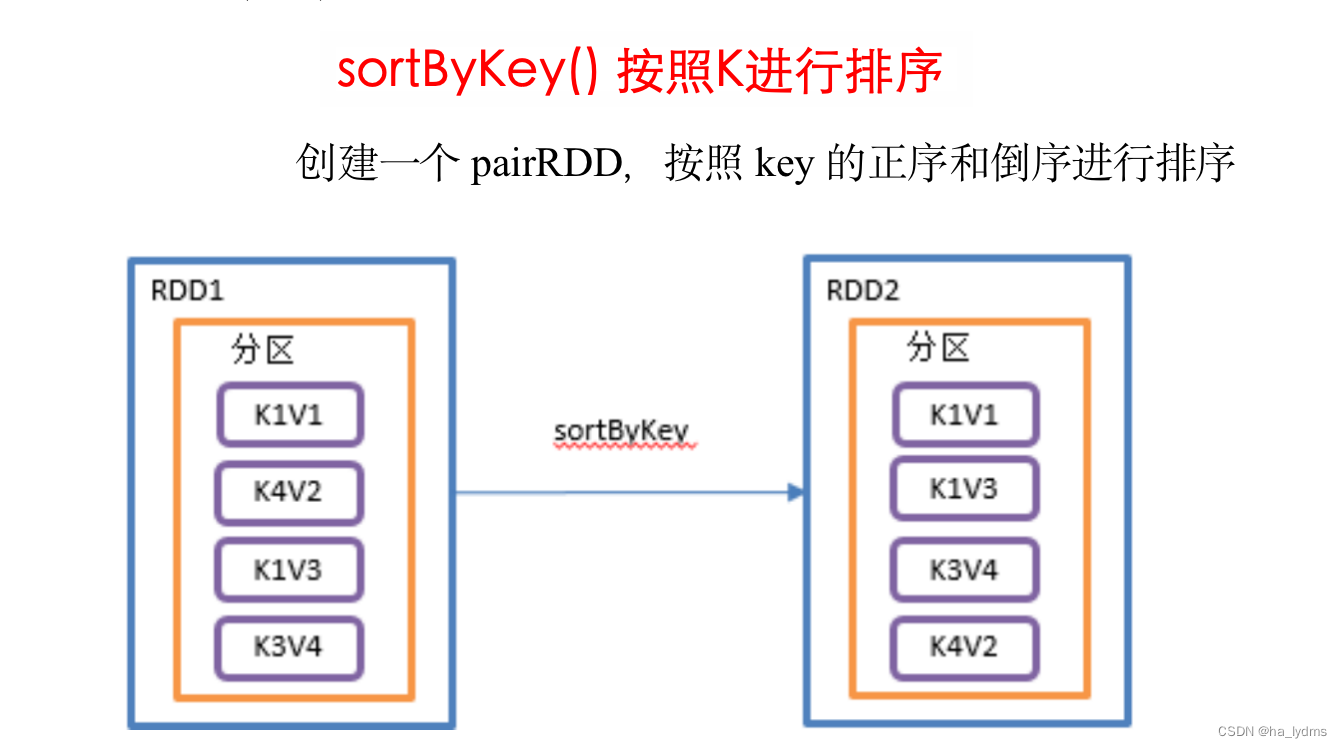
// 按照key的正序(默认正序)
rdd01.sortByKey(ascending = true)
// 按照key的倒序排列
rdd01.sortByKey(ascending = false)
val rdd01: RDD[(Int, String)] = sc.makeRDD(Array((3, "aa"), (6, "cc"), (2, "bb"), 1, "dd"))
// 按照key的正序(默认正序)
println(rdd01.sortByKey(ascending = true).collect().toList)
// 按照key的倒序排列
println(rdd01.sortByKey(ascending = false).collect().toList)
3.6 mapValues()_只对V进行操作
只对V进行操作
- 针对于(K,V)形式的类型只对V进行操作
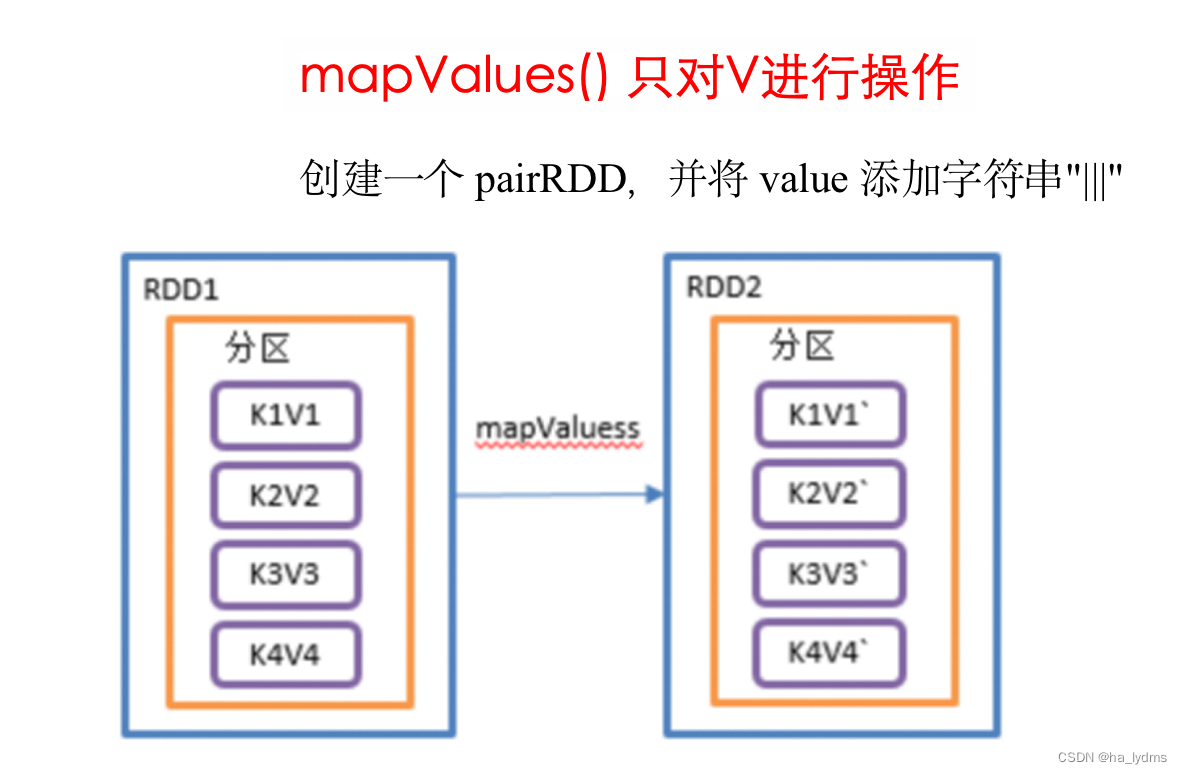
rdd01.mapValues(_ + "|||")
val rdd01: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (1, "d"), (2, "b"), (3, "c")))
// 对Value值添加字符串|||
// List((1,a|||), (1,d|||), (2,b|||), (3,c|||))
println(rdd01.mapValues(_ + "|||").collect().toList)
3.7 join()_等同于sql内连接
join() 等同于sql里的内连接,关联上的要,关联不上的舍弃
- 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD。
- 类似于SQL中的join(内联)
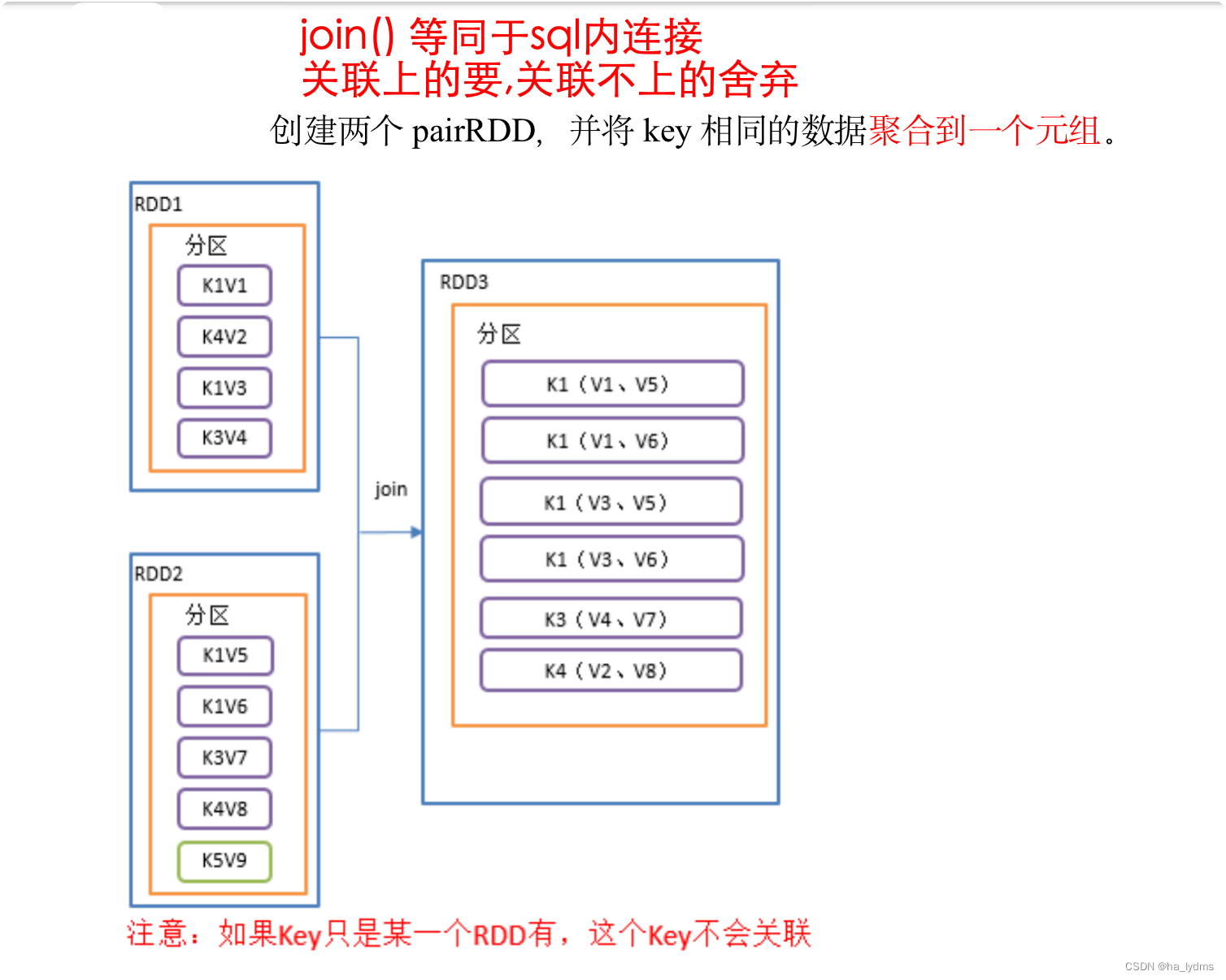
// 按key进行 内联join
rdd01.join(rdd02)
val rdd01: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd02: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
// 按key进行 内联join
// List((1,(a,4)), (2,(b,5)))
println(rdd01.join(rdd02).collect().toList)
3.8 cogroup()_类似于sql全连接
cogroup() 类似于sql的全连接,但是在同一个RDD中对key聚合
- 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD。
- 操作两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。
- 取并集
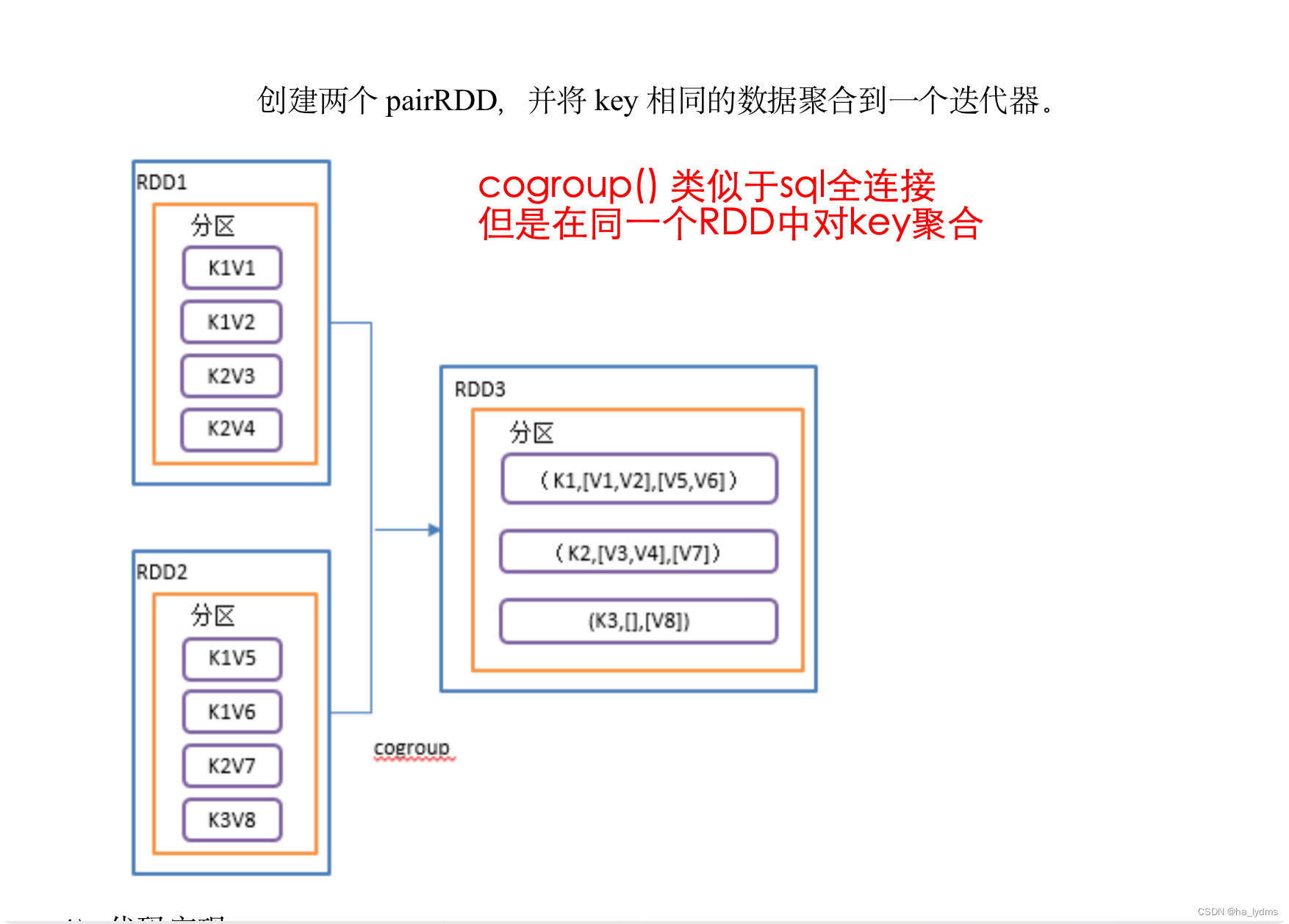
// cogroup 合并两个RDD,取并集
rdd01.cogroup(rdd02)
val rdd01: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd02: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
// cogroup 两个RDD并打印
// List((1,(CompactBuffer(a),CompactBuffer(4))), (2,(CompactBuffer(b),CompactBuffer(5)))
// (3,(CompactBuffer(c),CompactBuffer())), (4,(CompactBuffer(),CompactBuffer(6))))
println(rdd01.cogroup(rdd02).collect().toList)
cogroup后结果处理
val rdd01: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 1), (3, 5)))
val rdd02: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
// cogroup后类型为Iterable,key调用其sum进行值求和(相同的key)
val value1: RDD[(Int, (Iterable[Int], Iterable[Int]))] = rdd01.cogroup(rdd02)
val value: RDD[(Int, (Int, Int))] = value1.mapValues(a => {(a._1.sum, a._2.sum)
})
3.9 自定义分区器
要实现自定义分区器,需要继承org.apache.spark.Partitioner类,并实现下面三个方法。
- numPartitions: Int:返回创建出来的分区数。
- getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
- equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样Spark才可以判断两个RDD的分区方式是否相同。
val rdd01: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd02: RDD[(Int, String)] = rdd01.partitionBy(new MyParTition(2))
println(rdd02.collect().toList)
class MyParTition(num: Int) extends Partitioner {// 设置分区数override def numPartitions: Int = num// 具体分区逻辑override def getPartition(key: Any): Int = {// 采用模式匹配。依据不同的类型,采用不同的处理逻辑// 字符串:放入0号分区。整数:取模分区个数key match {case s: String => 0case i: Int => i % numPartitionscase _ => 0}}
}
3.10 reduceByKey和groupByKey区别
- reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[K,V]。
- groupByKey:按照key进行分组,直接进行shuffle。
- 开发指导:在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑,后续会学习功能更加强大的归约算子,能够在预聚合的情况下实现求平均值。
三、行动算子(Action)
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。
1、collect()_以数组的形式返回数据集
以数组的形式返回数据集
- 在驱动程序中,以数组Array的形式返回数据集的所有元素。
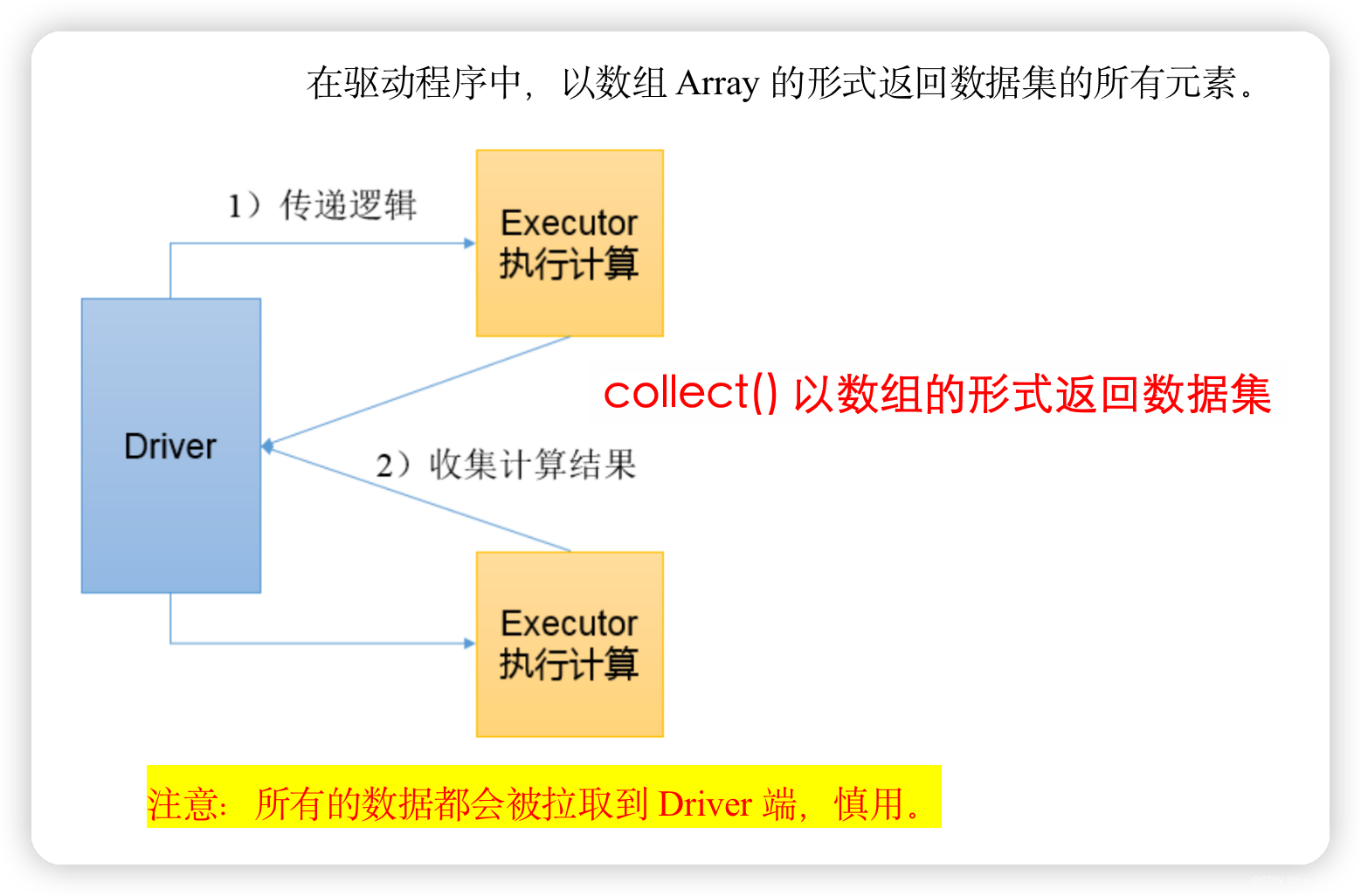
rdd02.collect().toList
2、count()_返回RDD中元素个数
返回RDD中元素个数
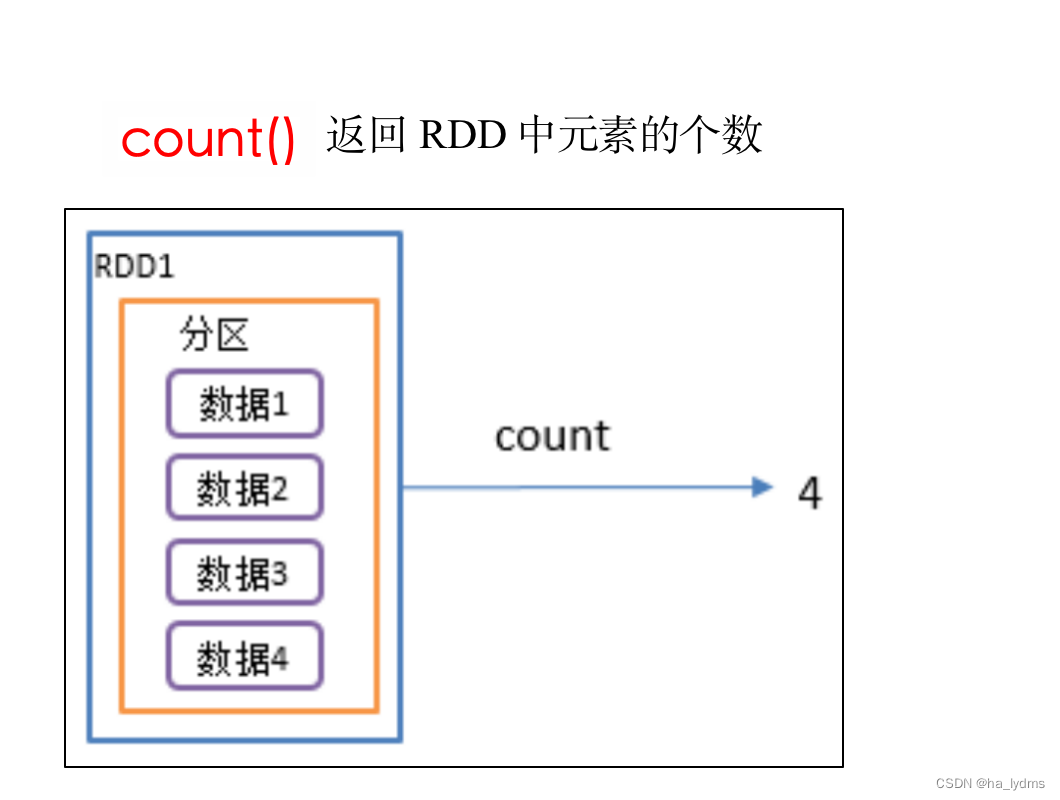
println(rdd01.count())
3、first()_返回RDD中的第一个元素
返回RDD中的第一个元素
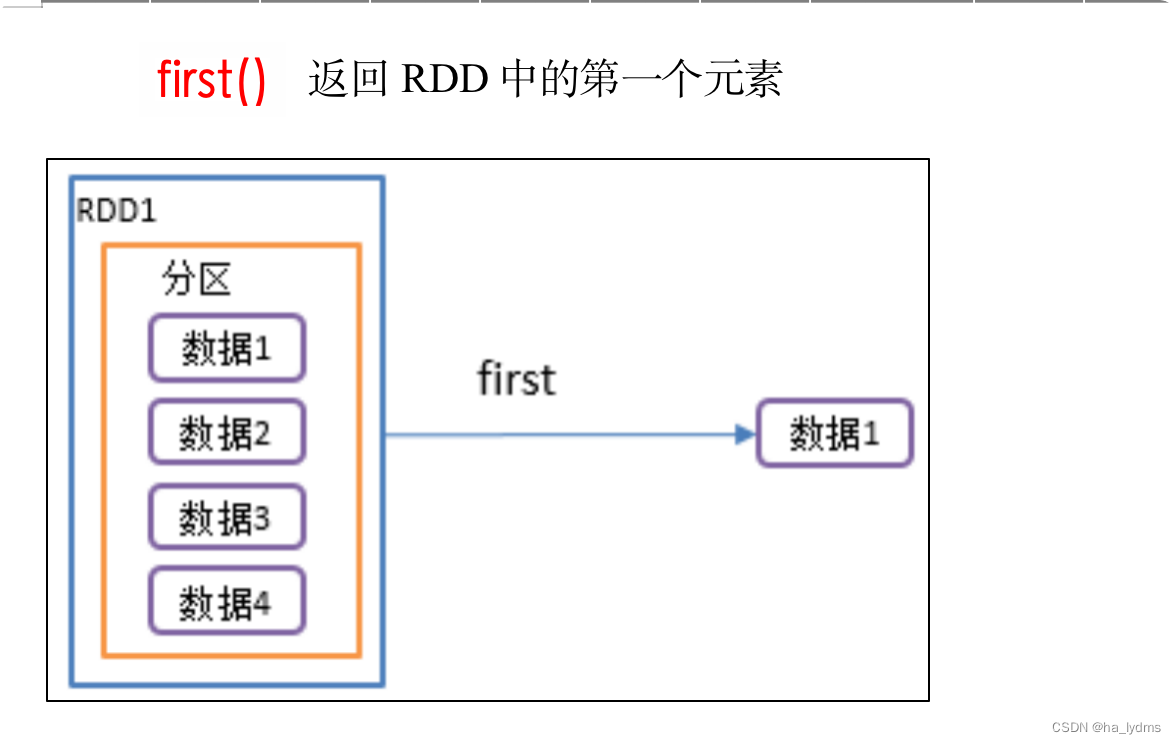
println(rdd01.first())
4、take()_返回由RDD前n个元素组成的数组
返回由RDD前n个元素组成的数组
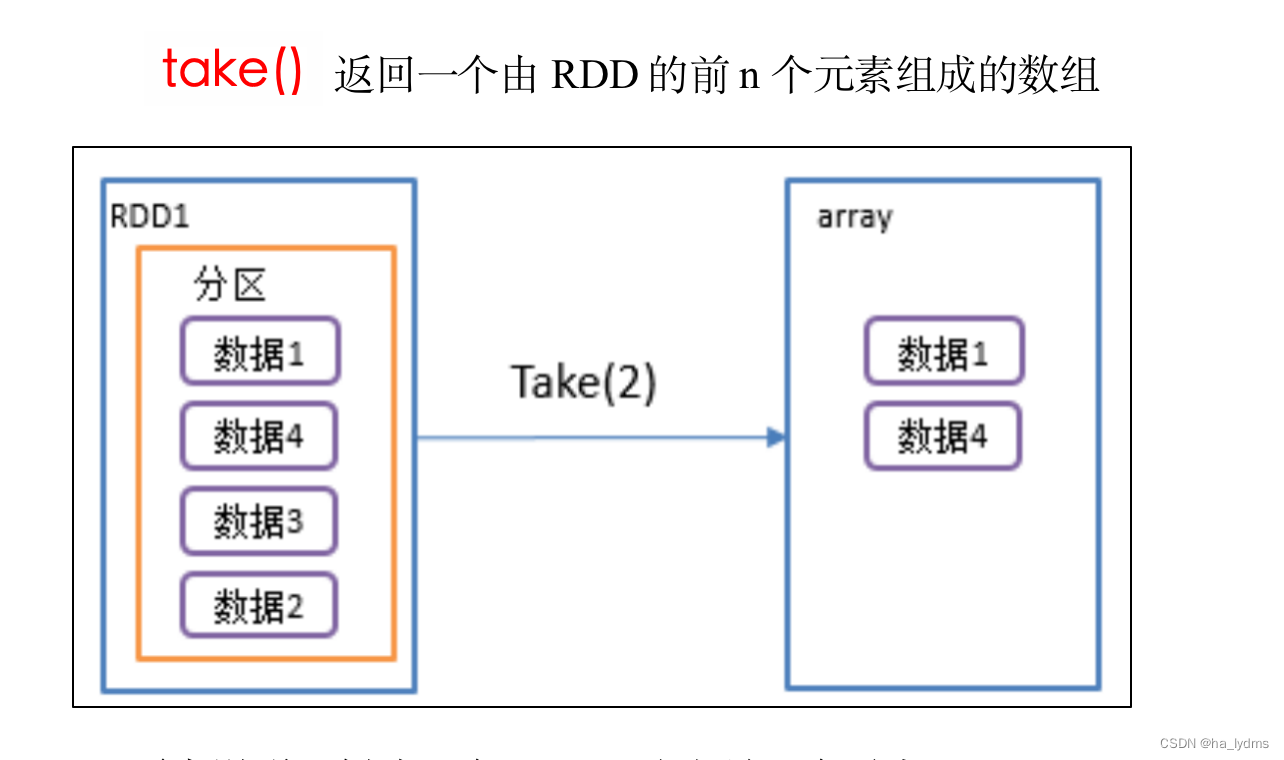
// 返回由前3个元素组成的数组
rdd01.take(3)
val number: Array[(Int, String)] = rdd01.take(3)
5、takeOrdered()_返回排序后前n个元素
返回该RDD排序后前n个元素组成的数组
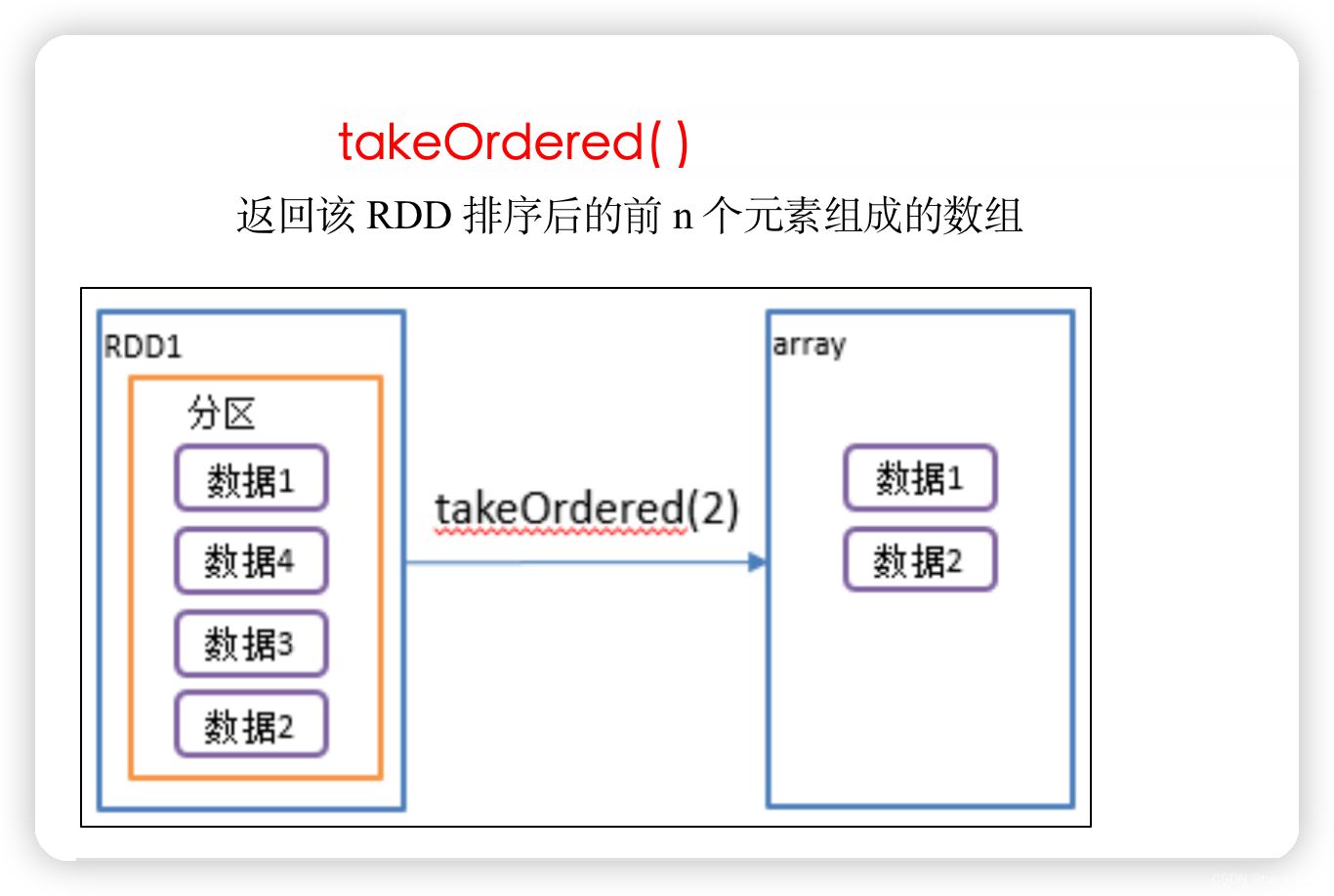
// returns Array(2)
sc.parallelize(Seq(10, 4, 2, 12, 3)).takeOrdered(1)// returns Array(2, 3)
sc.parallelize(Seq(2, 3, 4, 5, 6)).takeOrdered(2)// List(1, 2)
val rdd02: Array[Int] = sc.makeRDD(List(1, 3, 2, 4)).takeOrdered(2)
println(rdd02.toList)
6、countByKey()_统计每种key的个数
统计每种key的个数
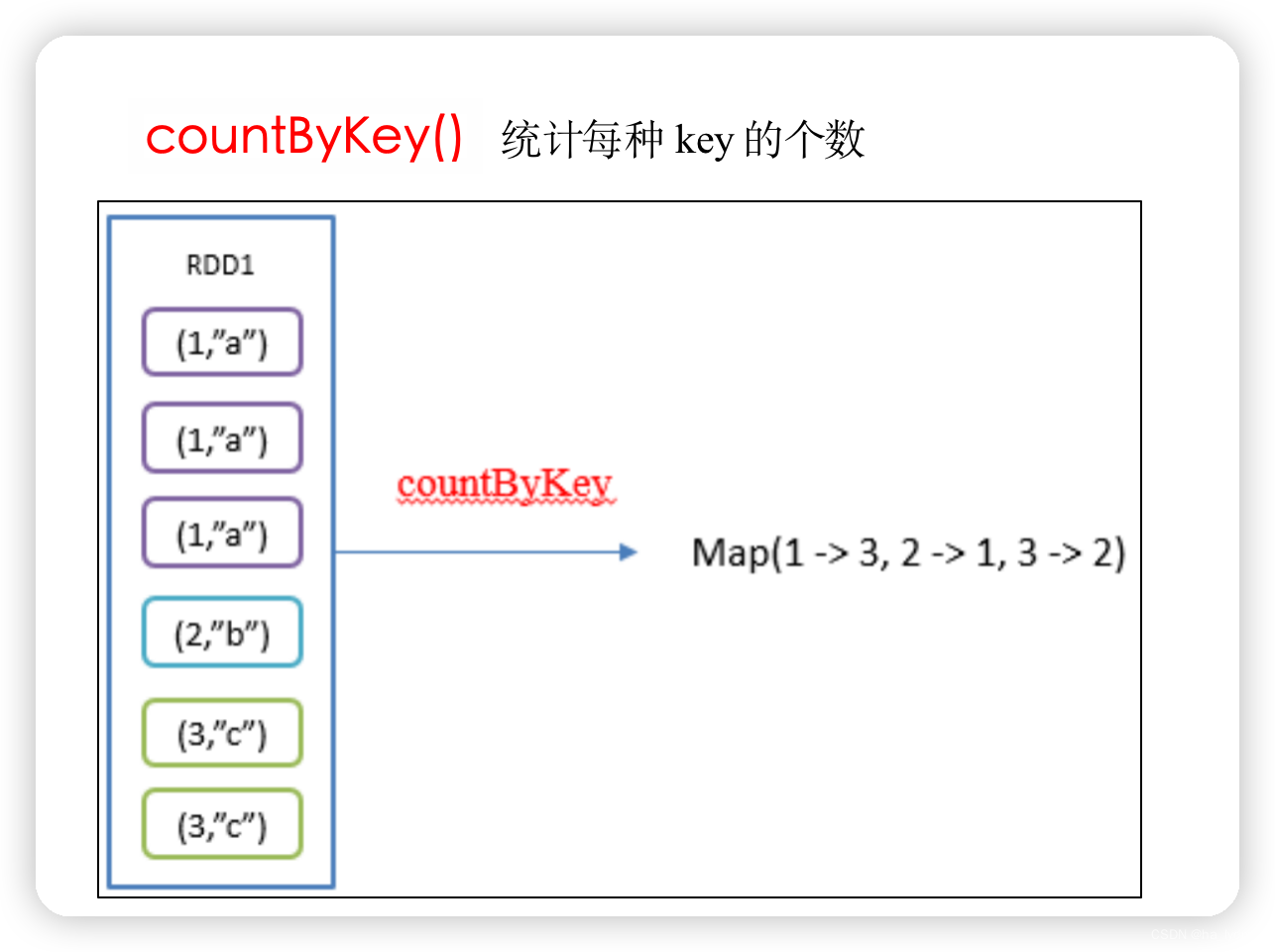
rdd01.countByKey()
val rdd01: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))
val rdd02: collection.Map[Int, Long] = rdd01.countByKey()
// Map(1 -> 3, 2 -> 1, 3 -> 2)
println(rdd02)
7、saveAsTextFile(path)_保存成Text文件
保存成Text文件
- 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
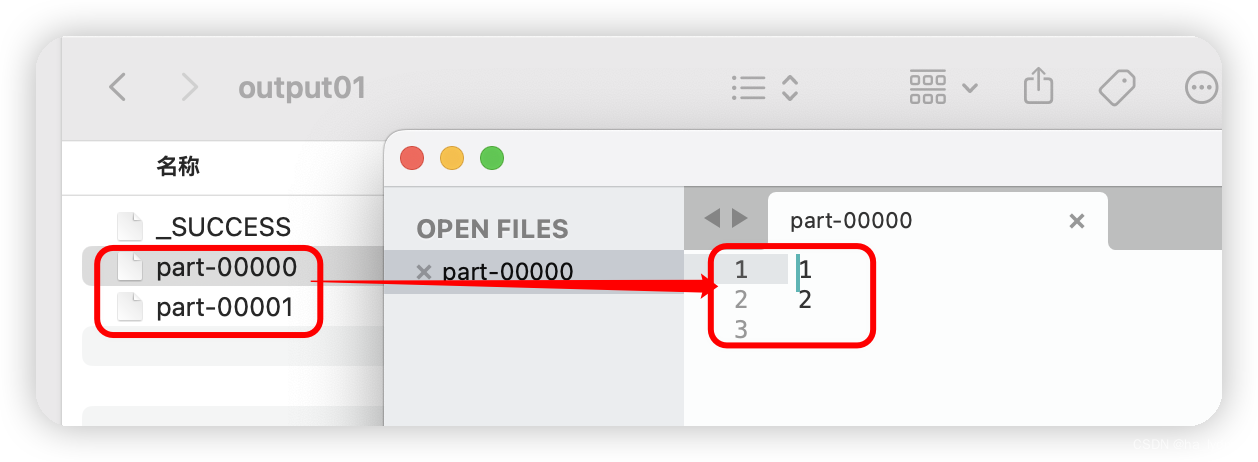
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// 保存到本地Text文件
rdd.saveAsTextFile("output01")
8、saveAsSequenceFile(path)_保存成Sequencefile文件
保存成Sequencefile文件
- 将数据集中的元素以Hadoop Sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
- 只有kv类型RDD有该操作,单值的没有
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// 保存成Sequencefile文件
rdd.saveAsObjectFile("output02")
9、saveAsObjectFile(path)_序列化成对象保存到文件
序列化成对象保存到文件
- 用于将RDD中的元素序列化成对象,存储到文件中。
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// 序列化成对象保存到文件
rdd.map((_, 1)).saveAsObjectFile("output03")
10、foreach()_遍历RDD中每一个元素
遍历RDD中每一个元素
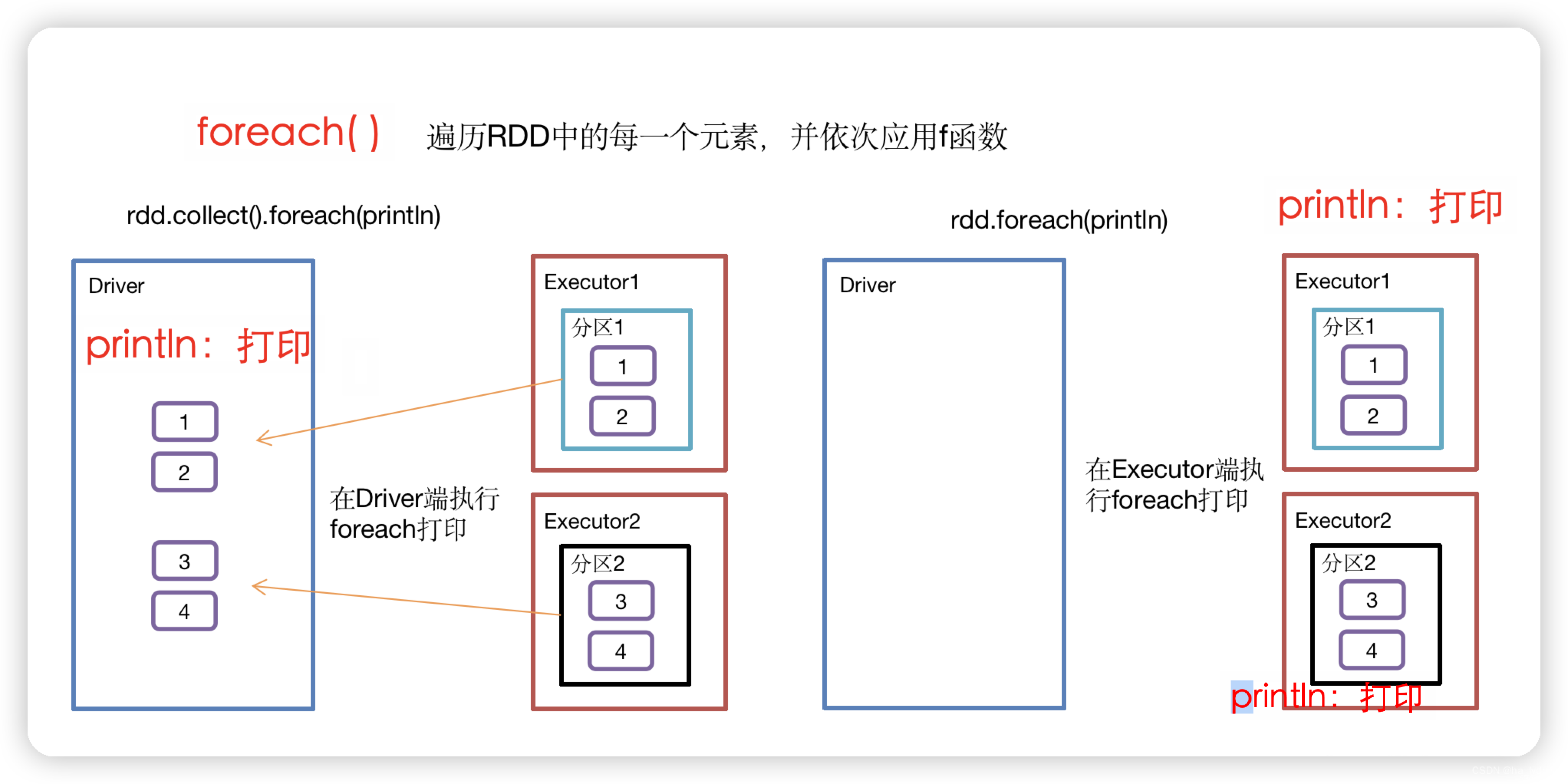
// 收集后打印
rdd.collect().foreach(println)
// 分布式打印
rdd.foreach(println)






![[ZenTao]源码阅读:自定义任务类型](https://img-blog.csdnimg.cn/df668dcdb6bd4744984c6c76e393a892.png)