目录
1.包装类
1.1基本数据类型以及它们所对应的包装类
1.2装箱和拆箱
1.3自动装箱和自动拆箱
2.什么是泛型
3.引出泛型
4.泛型类的使用
4.1语法
4.2示例
4.3类型推导
5.泛型是如何编译的
5.1擦除机制
5.2正确的写法
6.泛型的上届
6.1语法
6.2示例
1.包装类
在Java中,由于基本数据类型并不是继承于Object,为了在泛型代码中可以支持基本类型,Java给每个基本数据类型都对应了一个包装类。
1.1基本数据类型以及它们所对应的包装类
| 基本数据类型 | 包装类 |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Floar |
| double | Double |
| char | Character |
| boolean | Boolean |
注:除了int类型和char类型的包装类是Integer和Character,其它所有的基本数据类型对应的包装类都是它的首字母大写。
1.2装箱和拆箱
public static void main(String[] args) {int a=199;//装箱操作,新建一个Integer对象,将a的值存入对象的某个属性中Integer integer1=Integer.valueOf(a);Integer integer2=new Integer(a);//拆箱操作 将Ingeter中的值取出,存放进一个基本数据类型中int b=integer1.intValue();//比较两个包装类大小的时候,建议使用equals方法,而不是==System.out.println(integer2.equals(integer1));//无论是打印包装类类型的值 还是基本类型的值 结果都是一样的System.out.println(integer1);System.out.println(b);}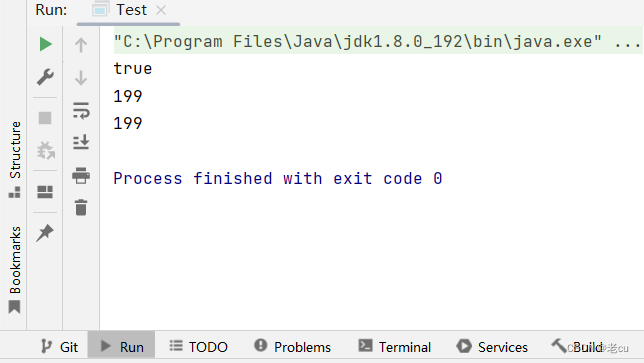
1.3自动装箱和自动拆箱
在使用过程中,装箱和拆箱带来不少的代码量,所以为了减少开发者的负担,Java提供了自动机制。
int i = 10;Integer ii = i; // 自动装箱Integer ij = (Integer)i; // 自动装箱int j = ii; // 自动拆箱int k = (int)ii; // 自动拆箱 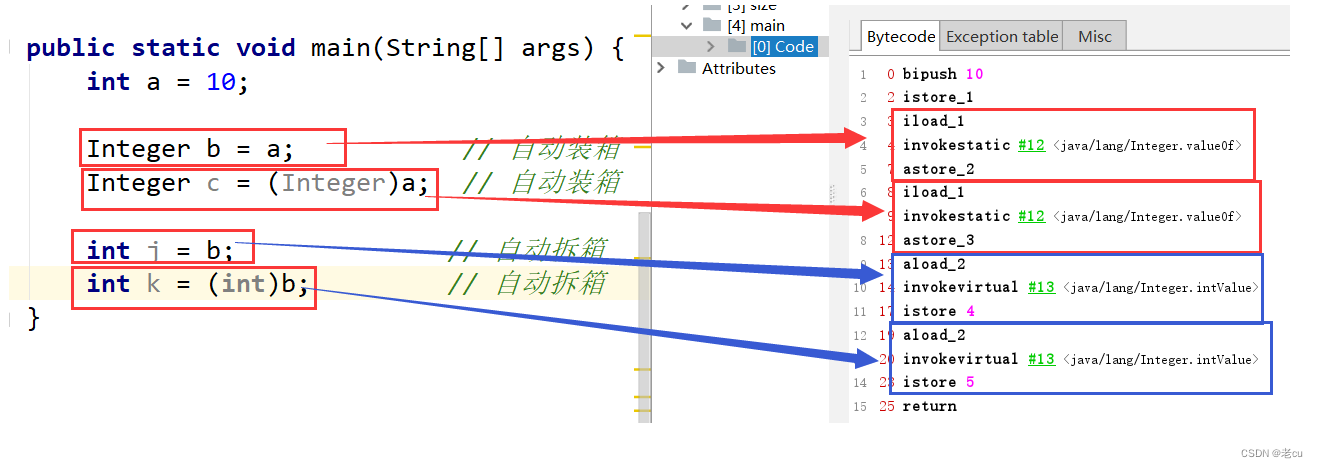
2.什么是泛型
一般的类和方法,只能使用具体的类型: 要么是基本类型,要么是自定义的类。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大。----- 来源《Java编程思想》对泛型的介绍。
泛型是在JDK1.5引入的新的语法,通俗讲,泛型:就是适用于许多许多类型。从代码上讲,就是对类型实现了参数化。
3.引出泛型
假设我们要实现一个类,类中包含一个数组成员,使得数组中可以存放任何类型的数据,也可以根据成员方法返回数组中某个下标的值。
在我们以前学过的数组中,一种数组只能存放同一种的元素。例如 int[] array=new int[10];
我们知道,所有类的父类都是Object类,那么我们可不可以定义一个Object类的数组呢?
让我们来试试看:
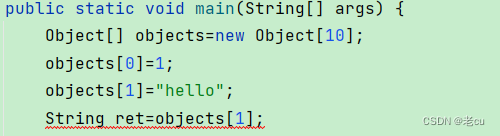
可以看到当我们存储不同的数据类型到我们的Object数组中的时候是可以的,但是当我们把它的值给String的时候,编译会报错,此时我们就只能进行强制类型转换,把它转换成String类型,才行。
虽然在这种情况下,当前数组任何数据都可以存放,但是,更多情况下,我们还是希望他只能够持有一种数据类型。而不是同时持有这么多类型。所以,泛型的主要目的:就是指定当前的容器,要持有什么类型的对象。让编译器去做检查。此时,就需要把类型,作为参数传递。需要什么类型,就传入什么类型。
public class MyArray <E>{// Object[] objects=new Object[10];E[] array= (E[]) new Object[10];//1public E getPos(int pos) {return this.array[pos];}public void setVal(int pos,E val) {this.array[pos] = val;}public static void main(String[] args) {MyArray<Integer> myArray=new MyArray<>();//2myArray.setVal(0,1);myArray.setVal(1,10);int a=myArray.getPos(0);//3System.out.println(a);myArray.setVal(2,"hello");//4}}代码解释:
1类名后的<E>代表占位符,表示当前类是一个泛型类
了解:【规范】类型形参一般使用一个大写字母表示,常用的名称有:
E 表示 Element
K 表示 Key
V 表示 Value
N 表示 Number
T 表示 Type
S, U, V 等等 - 第二、第三、第四个类型
2. 注释1处,不能new泛型类型的数组
E[] ts = new E[5];//是不对的
但是这样来写并不是足够好,答案是未必的。这个问题我们一会来给大家介绍。
3. 注释2处,类型后加入 <Integer> 指定当前类型
4. 注释3处,不需要进行强制类型转换
5. 注释4处,代码编译报错,此时因为在注释2处指定类当前的类型,此时在注释4处,编译器会在存放元素的时候帮助我们进行类型检查。
4.泛型类的使用
4.1语法
泛型类<类型实参>变量名;//定义一个泛型类引用
new 泛型类<类型实参>(构造方法实参);实例化一个泛型类对象
4.2示例
MyArray<Integer> list = new MyArray<Integer>();
注意:泛型只能接受类,所有的基本数据类型必须使用包装类
4.3类型推导
当编译器可以根据上下文推导出类型实参的时候,可以忽略类型实参的填写
MyArray<Integer> list = new MyArray<>(); // 可以推导出实例化需要的类型实参为 Integer
小结:
1. 泛型是将数据类型参数化,进行传递
2. 使用 <T> 表示当前类是一个泛型类。
3. 泛型目前为止的优点:数据类型参数化,编译时自动进行类型检查和转换
5.泛型是如何编译的
5.1擦除机制
那么,泛型到底是如何编译的呢?这个问题也是一个面试问题,泛型本质是一个很抽象的语法,要理解好它还是得需要一定的时间打磨。
首先,我们要明白一件事,那就是泛型是一种编译的时候的机制,它在编译的时候会做两件事,第一件事是类型检查,检查我们存入的数据是否是我们在一开始所指定的类型,第二件事就是类型转换。
在编译了以后,程序运行在jvm中了。我们要知道的是在jvm中是没有泛型的概念的。也就是说,泛型是一个编译机制,在编译完成以后,它仍然是一个Object。
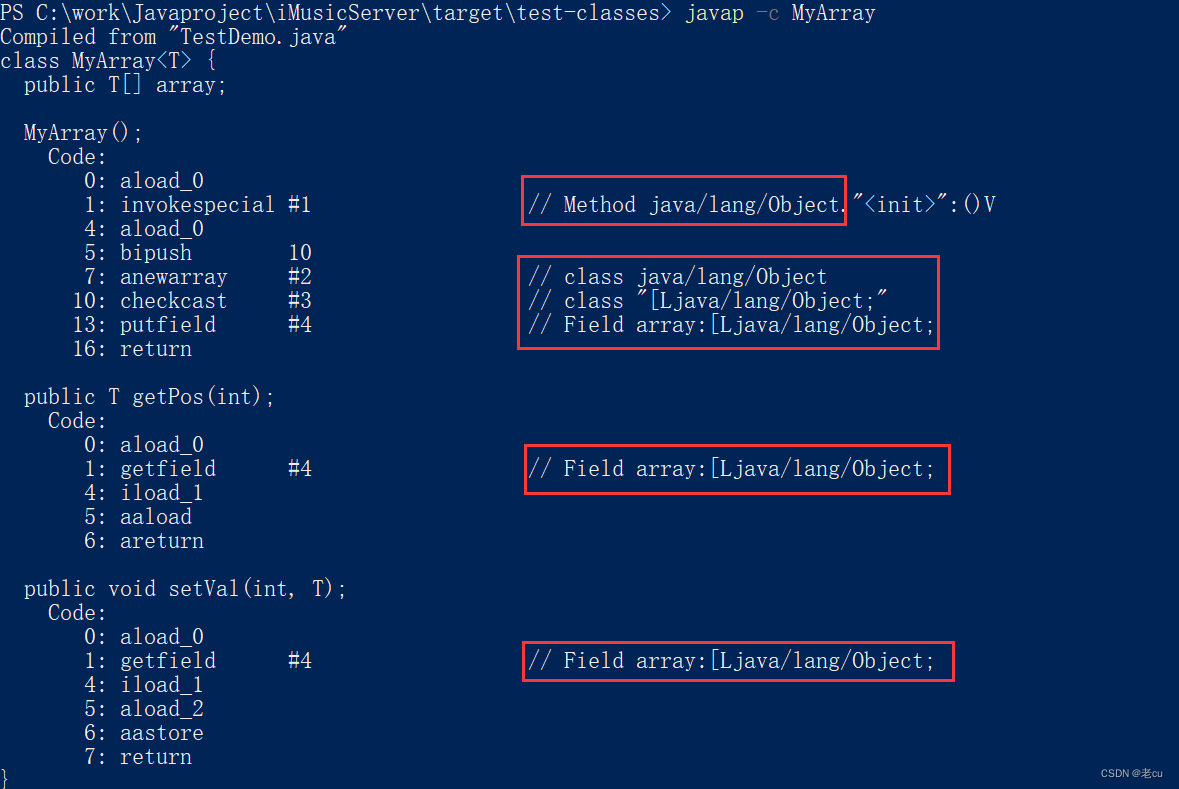
在编译的过程中,将所有的T都替换成Object的这种机制,我们称之为擦除机制。
5.2正确的写法
Java的泛型机制是在编译级别实现的,编译生成的字节码在运行期间并不会包含泛型的类型信息。
既然是这样,那么我们可不可以这样来定义一个泛型数组呢?
E[] array=new E[10];它是否就等价于 Object[] array=new Object[10];
答案是不能,如果这样写的话,编译器会报错。
我们来看看Java官方是如何来描述泛型的,打开ArraysList方法的源码看看
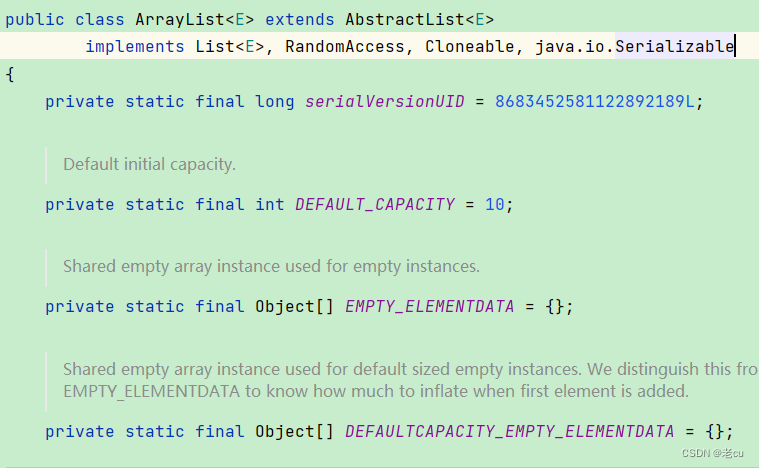
可以看到,在定义这些数组的时候,使用的是Object类型的数组,当我们使用的时候,我们来看看它的get方法
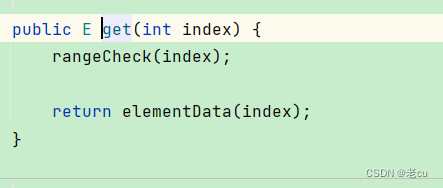
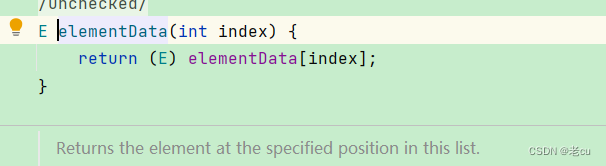
可以看到,定义的时候是Object类型的数组,但是在使用的时候,会强制类型转换为E类型。
6.泛型的上届
在定义泛型类的时候,有时需要对传入的类型变量有一定的约束,可以通过类型边界来约束
6.1语法
class 泛型类名称<类型形参 extends 类型边界> {
...
}
6.2示例
public class MyArray<E extends Number> {
...
}
只接受number的子类作为E的实例对象:

可以看到,当使用Integer类型的时候,是可以的。但是如果使用String类型就不行了。
注意:没有指定类型边界 E,可以视为 E extends Object