在整个课程中,你看到过类似模型在这个任务上表现良好,或者这个微调模型在性能上相对于基础模型有显著提升等陈述。
这些陈述是什么意思?如何形式化你的微调模型在你起初的预训练模型上的性能改进?让我们探讨一些由大型语言模型开发者使用的指标,你可以用这些指标评估你自己的模型的性能,并与世界上的其他模型进行比较。
在传统的机器学习中,你可以通过观察模型在已知输出的训练和验证数据集上的表现来评估模型的表现。

你可以计算诸如准确率这样的简单指标,准确率表示所有预测中正确的比例,因为模型是确定性的。
但是在大型语言模型中,输出是非确定性的,基于语言的评估要困难得多。
以句子为例,Mike really loves drinking tea. 这句话与 Mike adores sipping tea. 相似。但是如何衡量相似性呢?

让我们看看另外两个句子:Mike does not drink coffee. 和 Mike does drink coffee. 这两个句子之间只有一个词的差异,但含义完全不同。

对于像我们这样具有有机软脑的人类来说,我们可以看出相似之处和不同之处。但当你在数百万个句子上训练模型时,你需要一种自动化的结构化方法来进行测量。
ROUGE和BLEU是两个广泛使用的用于不同任务的评估指标。ROUGE代表Recall Oriented Under Generated summaries Evaluation回忆定向自动摘要评估,主要用于通过将自动生成的摘要与人工生成的参考摘要进行比较来评估其质量。

另一方面,BLEU代表Billingual Evaluation双语评估研究,是一种用于评估机器翻译文本质量的算法,同样是通过将其与人工生成的翻译进行比较来评估的。

现在,单词BLEU是法语中的“蓝色”。你可能听到人们称之为“蓝色”,但我将坚持使用原始的BLEU。
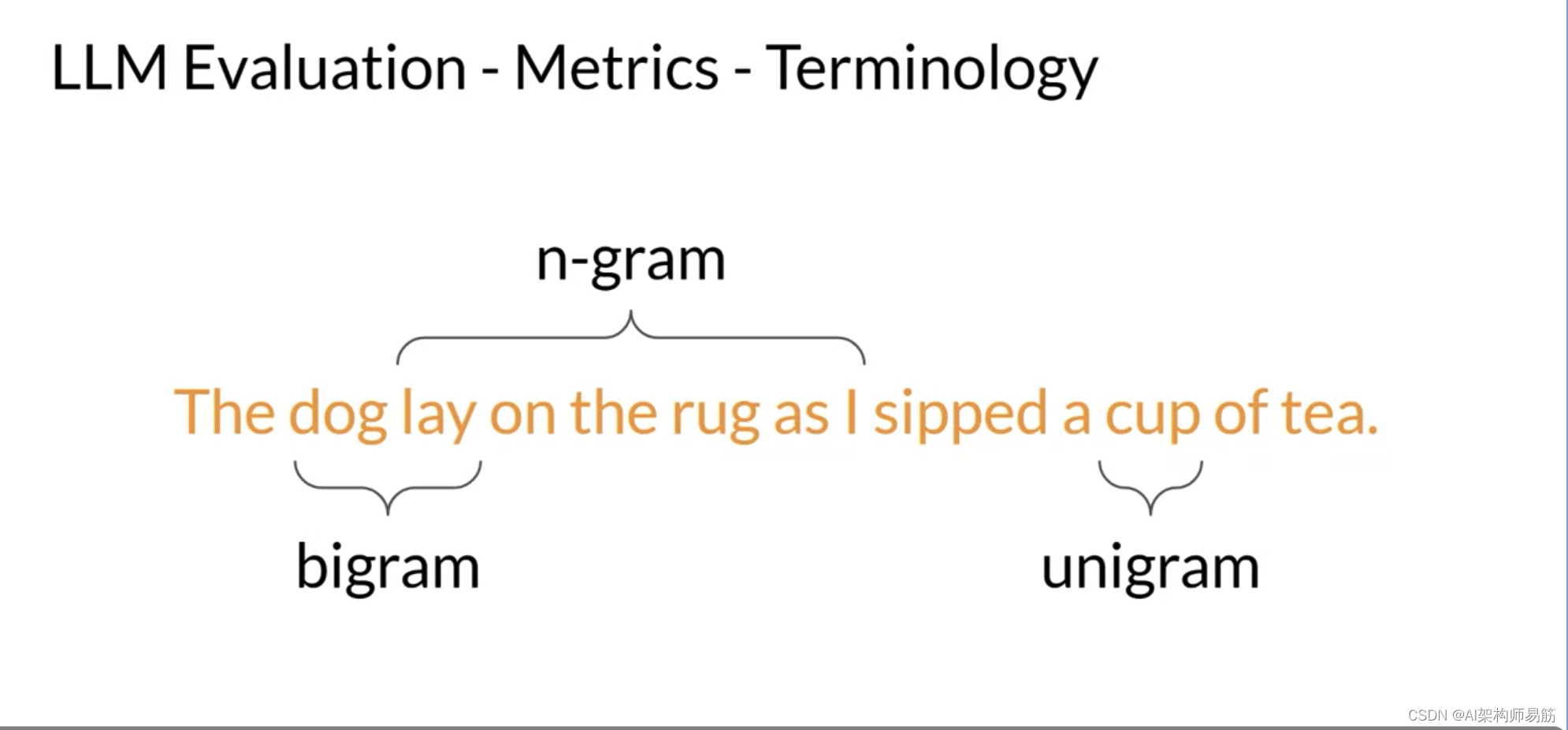
在开始计算指标之前,让我们先复习一些术语。在语言的解剖学中,一个unigram等同于一个单词。一个bigram是两个单词,n-gram是n个单词的组合。
非常简单的东西。首先,让我们看一下ROUGE-1指标。
为此,让我们看一个人工生成的参考句子:It is cold outside 和一个生成的输出:very cold outside。
你可以执行类似于其他机器学习任务的简单度量计算,使用召回率、精确率和F1。
召回率指标测量了参考和生成输出之间匹配的单词或unigram数量,除以参考中的单词或unigram数量。在这种情况下,完全匹配的单词得分为1,因为所有生成的单词都与参考中的单词匹配。

精确率测量了unigram匹配除以输出大小。

F1分数是这两个值的调和平均。

这些都是非常基本的指标,只关注单个单词,因此名称中有“1”,并且不考虑单词的顺序。它可能具有误导性。生成得分高但主观上可能较差的句子是完全可能的。
暂停片刻,想象一下,如果模型生成的句子只是多了一个单词,而不是 “It is not cold outside.”,得分将是相同的。

通过考虑一次从参考和生成句子中获取两个词的bigram或两个词的组合,你能够计算ROUGE-2。

现在,你可以使用bigram匹配来计算召回率、精确率和F1分数,而不是使用单个单词。你会注意到分数比ROUGE-1分数要低。

在较长的句子中,bigram不匹配的可能性更大,分数可能更低。
与继续计算ROUGE分数的n-gram增大到三个或四个不同,让我们采取不同的方法。
相反,你将寻找在生成输出和参考输出中都存在的最长公共子序列。在这种情况下,最长匹配子序列是 “it is” 和 “cold outside”,每个子序列的长度都为2。

现在,你可以使用LCS值来计算召回率、精确率和F1分数,其中召回率和精确率计算中的分子都是最长公共子序列的长度,即2。总体上,这三个量被称为Rouge-L分数。与所有ROUGE分数一样,你需要将值放在上下文中进行解释。

只有在为相同的任务确定了分数时,你才能使用这些分数来比较模型的能力。
例如,摘要任务。不同任务的Rouge分数不能相互比较。
正如你所见,简单的Rouge分数的一个特定问题是,不好的完成可能会得到很好的分数。
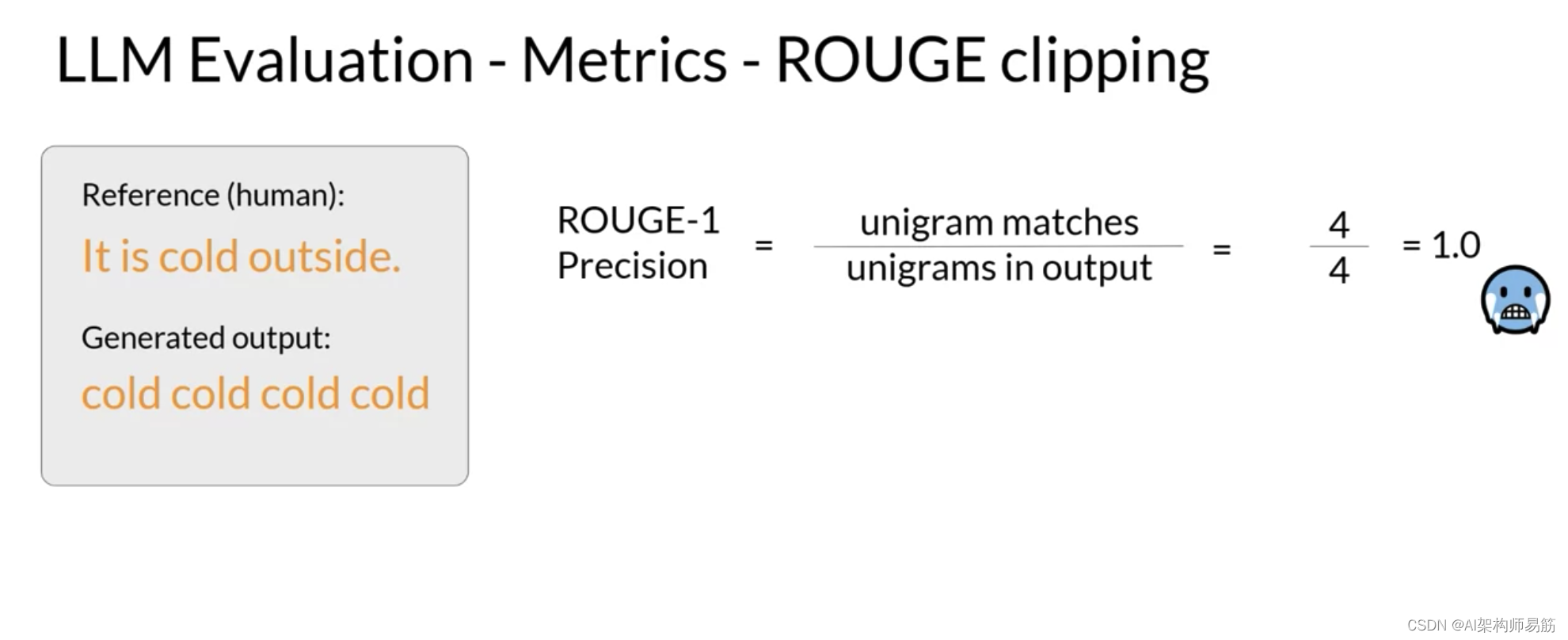
例如,考虑以下生成的输出:cold, cold, cold, cold。由于这个生成的输出包含了参考句子中的一个单词,它的分数会相当高,即使同一个单词多次重复。
Rouge-1精确率分数将是完美的。
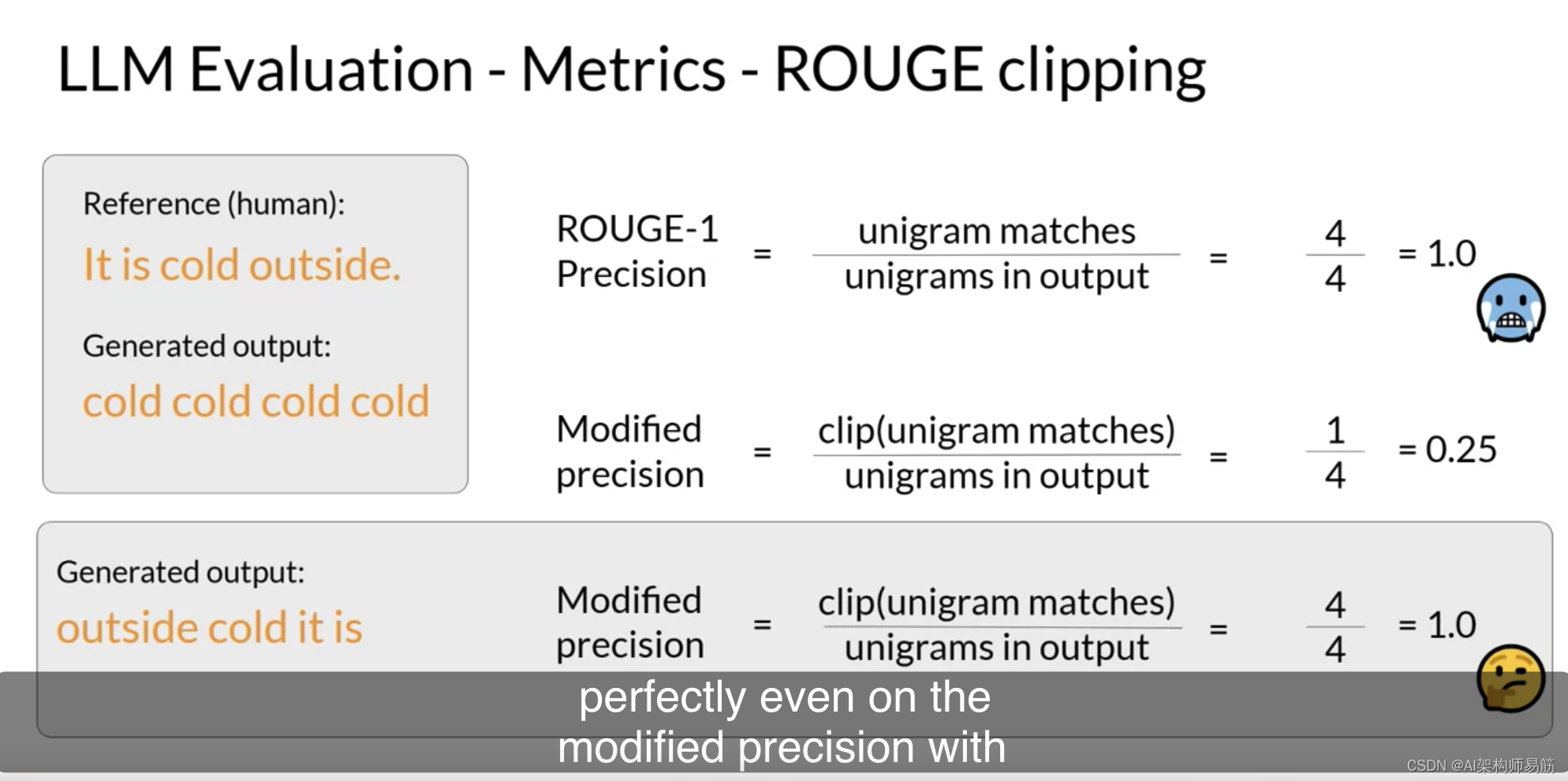
你可以通过使用剪辑函数来解决这个问题,将unigram匹配的数量限制为参考中该unigram的最大计数。
在这种情况下,参考中出现了一个 “cold”,因此在带有unigram匹配剪辑的修改精确率下,分数大幅降低。

然而,如果生成的单词都存在,但顺序不同,你仍然会面临挑战。
例如,对于这个生成的句子:“outside cold it is.”,即使在带有剪辑函数的修改精确率下,这个句子仍然是完美的,因为在参考中的所有单词和生成的输出都存在。
虽然使用不同的ROUGE分数可以帮助解决这个问题,但选择一个计算最有用分数的n-gram大小将取决于句子、句子大小和你的用例。
需要注意的是,许多语言模型库(例如,Hugging Face,你在第一周的实验中使用过)都包含了Rouge分数的实现,你可以用它来轻松评估模型的输出。
在本周的实验中,你将有机会尝试使用Rouge分数,并将其用于比较模型在微调前后的性能。
评估模型性能的另一个有用分数是BLEU分数,它代表双语评估研究。提醒一下,BLEU分数对于评估机器翻译文本的质量非常有用。
该分数本身是通过多个n-gram大小的平均精确率来计算的,就像我们之前看过的Rouge-1分数一样,但是计算的是一系列n-gram大小,并进行平均。
让我们更详细地看看这个指标的测量方法以及如何计算。
BLEU分数通过检查机器生成的翻译中有多少个n-gram与参考翻译中的n-gram相匹配来量化翻译质量。

为了计算分数,你需要在一系列不同的n-gram大小上计算平均精确率。如果你手动计算,你将进行多次计算,然后将所有结果平均,以找到BLEU分数。
在这个示例中,让我们看一个较长的句子,以便更好地了解分数的值。
人类提供的参考句子是:“I am very happy to say that I am drinking a warm cup of tea.”。现在,由于你已经深入研究了这些单独的计算,我将使用标准库展示BLEU的结果。
使用来自Hugging Face等提供商的预编写库来计算BLEU分数非常简单,我已经为我们的每个候选句子计算了BLEU分数。
第一个候选句子是:“I am very happy that I am drinking a cup of tea.”,BLEU分数为0.495。
随着我们越来越接近原始句子,得分也越来越接近1。

无论如何,Rouge和BLEU都是相当简单的指标,并且计算成本相对较低。
你可以在迭代模型时使用它们进行简单的参考,但不应仅凭此来报告大型语言模型的最终评估。
对于摘要任务,使用Rouge进行诊断性评估,对于翻译任务,使用BLEU。
然而,为了全面评估模型的性能,你需要查看研究人员开发的评估基准之一。在下一个视频中,让我们更详细地看看其中一些。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/8Wvg3/model-evaluation