NÜWA: Visual Synthesis Pre-training for Neural visUalWorld creAtion
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2. 相关工作
2.1. 视觉自回归模型
2.2. 视觉稀疏自注意
3. 方法
3.1. 3D 数据表示
3.2. 3D Nearby Self-Attention
3.3. 3D 编码器-译码器
3.4. 训练目标
4. 实验
4.1. 实现细节
4.2. 与 SOTA 的对比
4.3. 消融研究
5. 结论
附录
A. 3D 稀疏注意力对比
S. 总结
S.1 主要贡献
S.2 架构和方法
0. 摘要
这篇论文介绍了一个名为 NÜWA 的统一多模态预训练模型,该模型可以用于各种视觉合成任务,包括生成新的或操纵现有的视觉数据(如图像和视频)。为了同时处理语言、图像和视频,作者设计了一个 3D transformer 编码器-解码器框架,该框架不仅可以处理视频作为 3D 数据,还可以适应文本和图像作为 1D 和 2D 数据。此外,还提出了一种 3D Nearby Attention(3DNA)机制,以考虑视觉数据的性质并减少计算复杂性。研究人员在 8 个下游任务上对 NUWA 进行了评估。与几个强基线模型相比,NUWA 在文本到图像生成、文本到视频生成、视频预测等任务上取得了最先进的结果。此外,它还展现出在文本引导的图像和视频操作任务上惊人的零样本能力。项目位于 https://github.com/microsoft/NUWA。
1. 简介
如今,网络变得比以往任何时候都更加注重视觉,因为图像和视频已经成为新的信息载体,并在许多实际应用中得到使用。在这个背景下,视觉合成成为越来越受欢迎的研究主题,旨在构建能够为各种视觉场景生成新的或操纵现有视觉数据(即图像和视频)的模型。
自回归模型在视觉合成任务中发挥着重要作用,因为与生成对抗网络(GANs)相比,它们具有显式的密度建模和稳定的训练优势。较早的视觉自回归模型,如 PixelCNN、PixelRNN、Image Transformer、iGPT 和 Video Transformer,以 “逐像素” 方式执行视觉合成。然而,由于它们在高维视觉数据上的高计算成本,这些方法只能用于低分辨率图像或视频,难以扩展。
最近,随着 VQ-VAE 作为一种离散的视觉标记方法的出现,可以将高效和大规模的预训练应用于图像(例如 DALL-E 和 CogView)和视频(例如 GODIVA)的视觉合成任务。尽管取得了巨大的成功,但这些解决方案仍然存在限制,它们将图像和视频分开处理,专注于生成其中之一。这限制了模型从图像和视频数据中受益的能力。
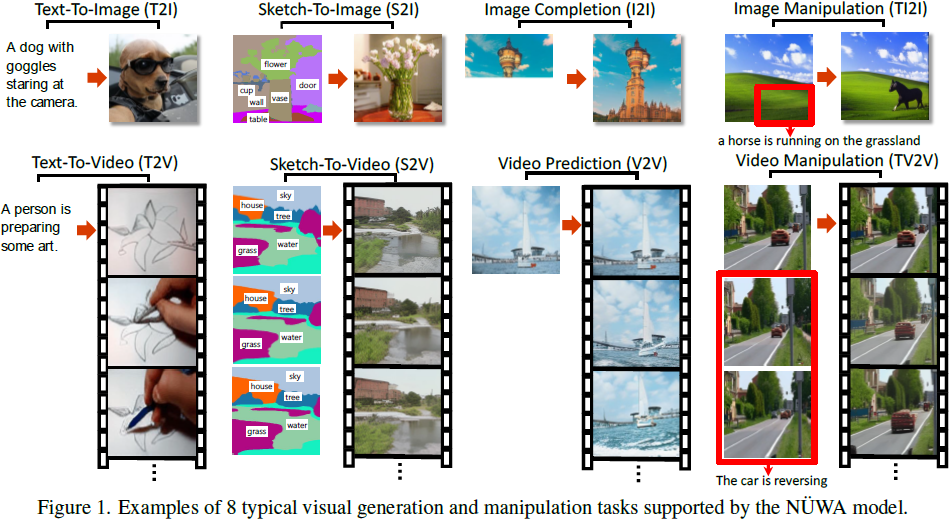
在本文中,我们提出 NUWA,这是一个统一的多模态预训练模型,旨在支持图像和视频的视觉合成任务,并进行了 8 个下游视觉合成实验,如图 1 所示。这项工作的主要贡献有三个方面:
- 我们提出 NUWA,这是一个通用的 3D transformer 编码器-解码器框架,同时针对不同的视觉合成任务涵盖了语言、图像和视频。它由一个自适应编码器和一个被 8 个视觉合成任务共享的解码器组成,编码器可以接受文本或视觉草图作为输入。
- 我们在框架中提出了 3D Nearby Attention(3DNA)机制,以考虑空间和时间轴的局部特性。3DNA 不仅减少了计算复杂性,还提高了生成结果的视觉质量。
- 与多个强基线方法相比,NUWA 在文本到图像生成、文本到视频生成、视频预测等方面取得了最先进的结果。此外,NUWA 展现出令人惊讶的零样本学习能力,不仅可以进行文本引导的图像处理,还可以进行文本引导的视频处理。
2. 相关工作
2.1. 视觉自回归模型
本文提出的方法沿着基于自回归模型的视觉合成研究方向发展。早期的视觉自回归模型 [5、28、39、41、44] 以 “逐像素” 的方式执行视觉合成。然而,由于在对高维数据进行建模时的高计算成本,这些方法只能应用于低分辨率图像或视频,很难进行扩展。
最近,基于 VQ-VAE 的 [40] 视觉自回归模型被提出用于视觉合成任务。通过将图像转换为离散的视觉标记,这种方法可以进行高效且大规模的文本到图像生成的预训练(例如 DALL-E [33] 和 CogView [9]),文本到视频生成(例如 GODIVA [45]),以及视频预测(例如 LVT [31] 和VideoGPT [48]),生成的图像或视频具有更高的分辨率。然而,这些模型中没有一个同时使用图像和视频进行训练。但直觉告诉我们,这些任务可以从两种类型的视觉数据中受益。
与这些工作相比,NUWA 是一个统一的自回归视觉合成模型,它通过覆盖图像和视频的视觉数据进行了预训练,并支持各种下游任务。我们还在第 4.3 节验证了不同预训练任务的有效性。此外,NUWA 在视觉标记化方面使用的是 VQ-GAN [11],而不是 VQ-VAE,根据我们的实验,这可以带来更好的生成质量。
2.2. 视觉稀疏自注意
如何处理自注意力引入的二次复杂性问题是另一个挑战,特别是对于高分辨率图像合成或视频合成等任务。
与 NLP 类似,已经探索了稀疏注意机制来缓解视觉合成中的这一问题。[31, 44] 将视觉数据分成不同部分(或块),然后为合成任务执行按块稀疏注意。然而,这种方法单独处理不同的块,并没有建模它们之间的关系。[15,33,45] 提出在视觉合成任务中使用轴向稀疏注意,沿着视觉数据表示(representation)的轴进行稀疏注意。这种机制使训练非常高效,对于像 DALL-E [33]、CogView [9] 和 GODIVA [45] 这样的大规模预训练模型非常友好。然而,由于自注意力中使用的上下文有限,生成的视觉内容的质量可能会受到损害。[6, 28, 32] 提出在视觉合成任务中使用局部稀疏注意,允许模型看到更多的上下文。但这些工作仅适用于图像。
与这些工作相比,NUWA提出了一种 3D 近距离注意机制,将局部稀疏注意扩展到图像和视频。我们还在第 4.3 节中验证了局部稀疏注意对于视觉生成的优越性。
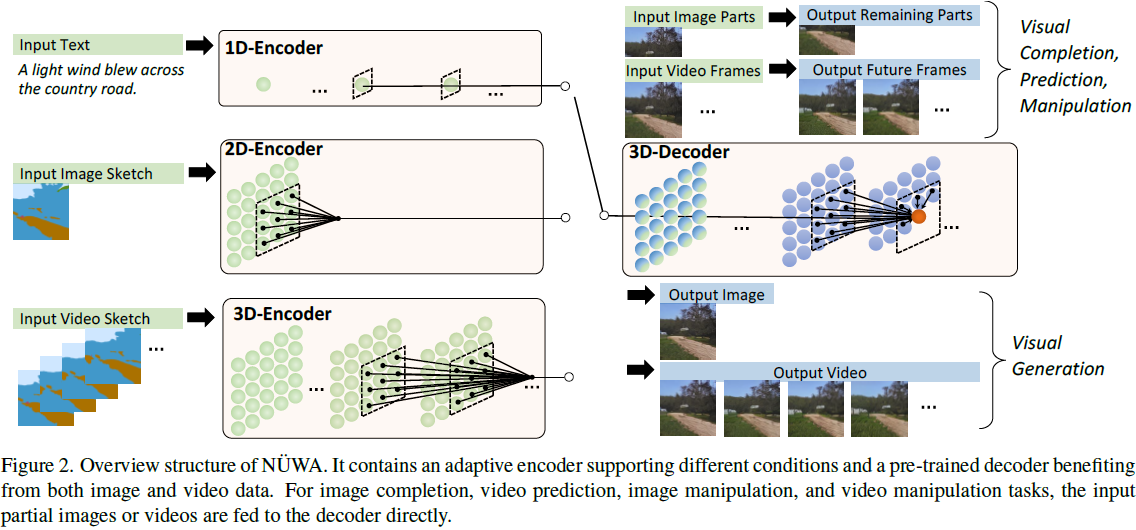
3. 方法
3.1. 3D 数据表示
为了涵盖所有文本、图像和视频或它们的草图,我们将它们都视为标记,并定义一个统一的 3D 表示符号 X ∈ R^(h*w*s*d),其中 h 和 w 分别表示空间轴上的标记数量(高度和宽度),s 表示时间轴上的标记数量,d 是每个标记的维度。接下来,我们介绍如何为不同的模态获得这个统一的表示。
文本自然是离散的,按照 Transformer [42] 的方法,我们使用小写字节对编码(byte pair encoding,BPE)对其进行标记化,并将其嵌入到 R^(1*1*s*d) 中。我们使用占位符 1,因为文本没有空间维度。
图像自然是连续像素。给定一个原始图像 I ∈ R^(H*W*C),其中 H 表示高度,W 表示宽度,C 表示通道数,VQ-VAE [40] 训练一个可学习的码本来建立原始连续像素和离散标记之间的桥梁,如等式(1)和(2)所示:
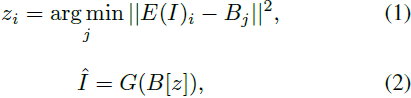
这里,E 是一个编码器,将图像 I 编码为 h * w 的网格特征,即 E(I) ∈ R^(h * w * d_B),B ∈ R^(N * d_B) 是一个可学习的码本,包含 N 个视觉标记,其中每个 E(I) 的网格被搜索以找到最接近的标记。搜索得到的结果 z ∈ {0, 1, ..., N-1}^(h * w) 通过 B 进行嵌入,然后通过解码器 G 重构成^I。VQ-VAE 的训练损失可以写成等式 (3):
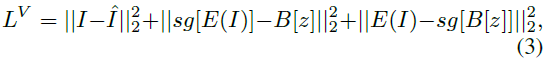
其中,
![]()
严格约束了 I 和 ^I 之间的像素精确匹配,这限制了模型的泛化能力。最近,VQ-GAN [11] 通过添加感知损失和 GAN 损失来增强 VQ-VAE 的训练,从而缓解 I 和 ^I 之间的精确约束,侧重于高级语义匹配,如等式 (4) 和 (5) 所示:

在训练 VQ-GAN 后,B[z] ∈ R^(h*w*1*d) 最终用作图像的表示。我们使用占位符1,因为图像没有时间维度。
视频可以被视为图像的时间扩展,而像 VideoGPT [48] 和 VideoGen [51] 这样的最近研究将 VQ-VAE 编码器的卷积从 2D 扩展到 3D,并训练了视频特定的表示。然而,这种方法无法为图像和视频共享一个通用的码书。在这篇论文中,我们展示了简单地使用 2D VQ-GAN 来对视频的每一帧进行编码,可以生成时间连贯的视频,同时受益于图像和视频数据。生成的表示被表示为R^(h*w*s*d),其中 s 表示帧数。
对于图像素描,我们将它们视为带有特殊通道的图像。每个值表示像素类别的图像分割矩阵R^(H*W) 可以以一种 one-hot 的方式 R^(H*W*C) 表示,其中 C 是分割类别的数量。通过训练额外的图像素描的 VQ-GAN,我们最终获得了嵌入的图像表示 R^(h*w*1*d)。类似地,对于视频素描,表示为 R^(h*w*s*d)。
3.2. 3D Nearby Self-Attention
在这一部分,我们基于前面的 3D 数据表示,定义了一个统一的 3D Nearby Self-Attention (3DNA) 模块,支持自注意力和交叉注意力。我们首先在公式 (6) 中给出了 3DNA 的定义,并在公式 (7) 到 (11) 中介绍了详细的实现细节:
![]()
![]()
其中,X 和 C 是在第 3.1 节中介绍的 3D 表示。如果 C = X,3DNA 表示对目标 X 的自注意力,如果 C ≠ X,则 3DNA 是在给定 C 的条件下对目标 X 的交叉注意力。W 表示可学习的权重。
我们从 X 下的坐标 (i, j, k) 开始介绍 3DNA。通过线性投影,C 下的相应坐标 (i', j', k') 为
![]()
然后,宽度、高度和时间范围为 e^w、 e^h、 e^s ∈ R^+ 的 (i', j', k') 周围的局部邻域如公式 (7) 所示:

![]()
其中,N 是条件 C 的子张量,包含 (i, j, k) 需要关注的相应邻域信息。
位置 (i, j, k) 的具有三个可学习的权重
![]()
的输出张量如公式 (8) 到 (11) 所示:
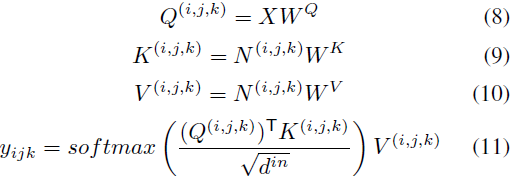
其中,位置(i, j, k)查询并收集条件 C 中的相应邻域信息。这也处理了 C = X 的情况,(i, j, k)仅需查询自身邻域的位置。3NDA 不仅降低了全局注意力的复杂度
![]()
而且表现出更出色的性能,我们将在第 4.3 节中进行讨论。
3.3. 3D 编码器-译码器
在这一部分,我们介绍基于 3DNA 构建的 3D 编码器-解码器。为了在 C ∈ R^(h' * w' * s' * d^in) 的条件下生成目标 Y ∈ R(h * w * s * d^out),Y 和 C 的位置编码分别由三个不同的考虑了高度、宽度和时间轴的可学习词汇表更新,如等式 (12)、(13) 所示:
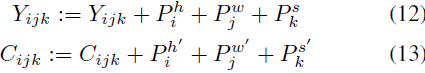
然后,条件 C 被馈送到一个具有 L个 3DNA 层堆叠的编码器中,以建模自注意力交互,第 l 个层如等式 (14) 所示:
![]()
同样,解码器也是由 L 个 3DNA 层堆叠而成的。解码器计算生成结果的自注意力和生成结果与条件之间的交叉注意力。第 l 层在等式 (15) 中表示。
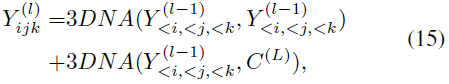
其中 <i, <j, <k 表示当前已生成的标记。初始标记
![]()
是在训练阶段学习的特殊 <bos> 标记。
3.4. 训练目标
我们在三个任务上训练我们的模型,分别是文本到图像(T2I),视频预测(V2V)和文本到视频(T2V)。三个任务的训练目标是交叉熵,分别表示为等式(16)中的三个部分,
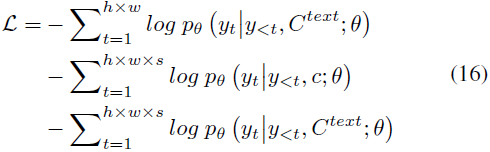
对于 T2I 和 T2V 任务,C^text 表示文本条件。对于 V2V 任务,因为没有文本输入,我们使用一个特殊词 “None” 的固定 3D 表示 c。 θ 表示模型参数。
4. 实验
根据第 3.4 节,我们首先在三个数据集上预训练 NUWA:
- Conceptual Captions [22] 用于文本到图像(T2I)生成,包括 290 万个文本-图像对;
- Moments in Time [26] 用于视频预测(V2V),包括 72.7 万个视频;
- VATEX 数据集 [43] 用于文本到视频(T2V)生成,包括 24.1 万个文本-视频对。
接下来,我们首先在第 4.1 节介绍实现细节,然后在第 4.2 节与最先进的模型进行比较,最后在第 4.3 节进行消融研究,研究不同部分的影响。
4.1. 实现细节
在第 3.1 节中,我们设置文本、图像和视频的 3D 表示大小如下。对于文本,3D 表示的大小为 1*1*77*1280。对于图像,3D表示的大小为 21*21*1*1280。对于视频,3D 表示的大小为 21*21*10*1280,我们从帧速率为 2.5 fps 的视频中采样 10 帧。尽管默认的视觉分辨率是 336*336,但为了与现有模型进行公平比较,我们预训练了不同分辨率的模型。对于用于图像和视频的 VQ-GAN 模型,等式(1)中网格特征 E(I) 的大小为 441*256,码本 B 的大小为 12,288。
在第 3.2 节,不同的模态使用不同的稀疏程度。对于文本,我们设置 (e^w, e^h, e^s) = (1, 1, 1),其中 1 表示始终在注意力中使用完整的文本。对于图像和图像草图,(e^w, e^h, e^s) = (3, 3, 1)。对于视频和视频草图,(e^w, e^h, e^s) = (3, 3, 3)。
我们在 64 个 A100 GPU上进行了两周的预训练,将等式(14)中的层 L 设置为 24,使用学习率为 1e-3 的 Adam [17] 优化器,批量大小为 128,warm-up 占总共 50M 步的 5%。最终的预训练模型总共有 870M 个参数。


4.2. 与 SOTA 的对比
文本到图像(T2I)微调:我们在 MSCOCO [22] 数据集上对 NUWA 进行了定量比较,如表 1 所示,并在图 3 中进行了定性比较。与 DALL-E [33] 一样,我们使用模糊 FID 分数(FID-k)和Inception 分数(IS)[35] 来定量评估图像的质量和多样性,与 GODIVA [45] 一样,我们使用CLIPSIM 度量,它结合了 CLIP [29] 模型来计算输入文本和生成图像之间的语义相似度。为了公平比较,所有模型都使用 256*256 的分辨率。我们为每个文本生成 60 张图像,并通过 CLIP [29] 选择最佳图像。在表 1 中,NUWA 的 FID-0 得分为 12.9,CLIPSIM 为 0.3429,明显优于 CogView [9]。尽管 XMC-GAN [50] 报告了显著的 FID 分数为 9.3,但我们发现与 XMC-GAN 论文中完全相同的样本相比,NUWA 生成的图像更加逼真(请参见图 3)。特别是在最后一个示例中,男孩的脸很清晰,气球也正确生成。


文本到视频(T2V)微调:我们在 Kinetics [16] 数据集上对 NUWA 进行了定量比较,如表 2 所示,并在图 4 中进行了定性比较。与 TFGAN [2] 一样,我们使用 FID-img 和 FID-vid 指标来评估视觉质量,使用生成的视频标签的准确性来评估语义一致性。如表 2 所示,NUWA 在上述所有指标上表现最佳。在图 4 中,我们还展示了生成未见文本的强大零样本能力,例如 “在游泳池打高尔夫” 或 “在海上奔跑”。

视频预测(V2V)微调:我们在 BAIR Robot Pushing [10] 数据集上对 NUWA 进行了定量比较,如表 3 所示。Cond.表示给定的帧数用于预测未来的帧。为了公平比较,所有模型都使用 64×64 的分辨率。尽管只给出一帧作为条件(Cond.),NUWA 仍然将 FVD [38] 得分从 94±2 显著提高到86.9,推动了当前的最佳性能。

草图到图像(S2I)微调:我们在 MSCOCO stuff [22] 数据集上对 NUWA 进行了定性比较,如图 5 所示。NUWA 生成了多样性极高的逼真巴士图像,与 Taming-Transformers [11] 和 SPADE [27] 相比。甚至巴士窗户的反射都非常清晰可见。

图像补全(I2I)零样本评估:我们在零样本环境下对 NUWA 进行了定性比较,如图 6 所示。给出塔的上半部分,与 Taming Transformers [11] 相比,NUWA 展现了对塔的下半部分的更丰富想象力,包括建筑物、湖泊、花朵、草地、树木、山脉等。

文本引导的图像操作(TI2I)零样本评估:我们在零样本环境下对 NUWA 进行了定性比较,如图 7所示。与 Paint By Word [3] 相比,NUWA 展现出强大的操作能力,能够生成高质量与文本一致的结果,同时不改变图像的其他部分。例如,在第三行,NUWA 生成的蓝色消防车更加逼真,而背后的建筑物没有发生变化。这要归功于在各种视觉任务上进行的多任务预训练所学到的真实世界的视觉模式。另一个优势是 NUWA 的推理速度,实际上只需 50 秒即可生成一幅图像,而 Paint By Words 在推理期间需要额外的训练,需要大约 300 秒才能收敛。
草图到视频(S2V)微调和文本引导视频操作(TV2V)零样本评估:据我们所知,开放领域的 S2V 和 TV2V 是本文首次提出的任务。由于没有比较对象,我们将它们安排在第 4.3 节的消融研究中。
在附录中提供了更详细的比较、样本,包括人工评估。
4.3. 消融研究
上面的表 4 显示了不同 VQ-VAE(VQ-GAN)设置的有效性。我们在 ImageNet [34] 和OpenImages [19] 上进行了实验。R 表示原始分辨率,D 表示离散标记的数量。压缩率表示为 Fx,其中 x 是 √R 除以 √D 的商。在表 4 的前两行中,VQ-GAN 在 Fr´echet Inception Distance(FID)[14] 和结构相似性矩阵(SSIM)分数方面明显优于 VQ-VAE。比较第 2 行和第 3 行,我们发现离散标记的数量是导致更高视觉质量的关键因素,而不是压缩率。尽管第 2 行和第 4 行具有相同的压缩率 F16,它们的 FID 分数分别为 6.04 和 4.79。因此,重要的不仅仅是我们将原始图像压缩多少,还有多少个离散标记用于表示图像。这符合认知逻辑,仅使用一个标记来表示人脸太模糊了。实际上,我们发现,通常情况下,使用 16^2 个离散标记会导致性能不佳,尤其是对于人脸,而使用 32^2 个令牌表现最佳。然而,更多的离散标记意味着更多的计算,特别是对于视频。最后,我们在预训练中使用了一个折衷版本:21^2个 标记。通过在 Open Images 数据集上进行训练,我们进一步将 21^2 版本的 FID 分数从 4.79 提高到 4.31。
表 4 的下半部分显示了素描的 VQ-GAN 性能。MSCOCO [22] 上的 VQ-GAN-Seg 用于草图到图像(S2I)任务的训练,VSPW [24] 上的 VQ-GAN-Seg 用于草图到视频(S2V)任务的训练。所有这些骨干都在像素精度(PA)和频率加权的交集联合(Frequency Weighted Intersection over Union,FWIoU)方面表现良好,这表明我们模型中使用的 3D 素描表示的质量很高。图 8 还显示了一些 336*336 图像和素描的重建样本。
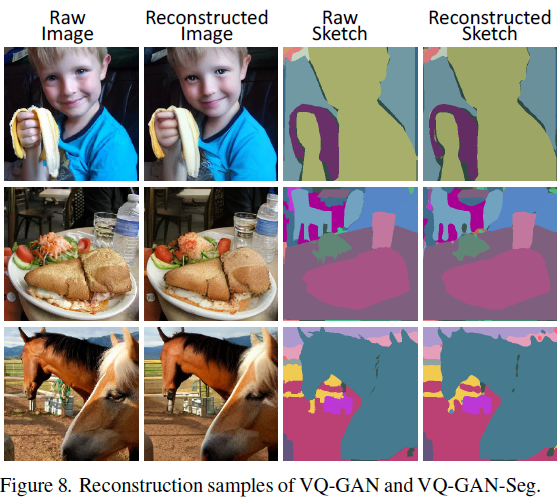
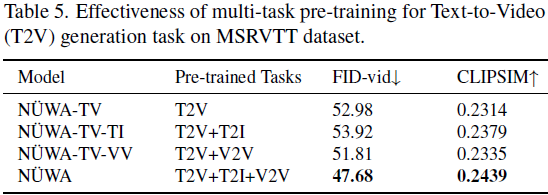
表 5 显示了多任务预训练在文本到视频(T2V)生成任务中的有效性。我们在具有自然描述和真实世界视频的挑战性数据集 MSR-VTT [46] 上进行研究。与仅在单个 T2V 任务上进行训练(第 1 行)相比,同时在 T2V 和 T2I 上进行训练(第 2 行)将 CLIPSIM 从 0.2314 提高到 0.2379。这是因为 T2I 有助于建立文本和图像之间的联系,从而有助于 T2V 任务的语义一致性。相反,同时在 T2V 和 V2V 上进行训练(第 3 行)将 FVD 分数从 52.98 提高到 51.81。这是因为 V2V 有助于学习通用的无条件视频模式,从而有助于 T2V 任务的视觉质量。作为 NUWA 的默认设置,同时进行所有三个任务的训练获得了最佳性能。
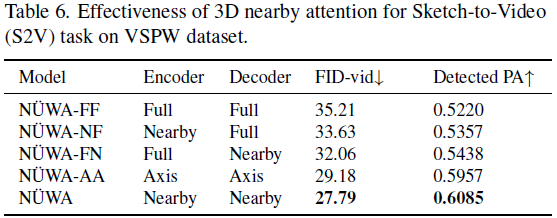
表 6 显示了在 VSPW [24] 数据集上进行的草图到视频(S2V)任务的 3D 邻域注意力的有效性。我们研究了 S2V 任务,因为该任务的编码器和解码器都使用了 3D 视频数据。为了评估 S2V 的语义一致性,我们提出了一种新的度量标准,称为检测到的 PA,它使用语义分割模型 [49] 对生成的视频的每帧进行分割,然后计算生成的片段与输入视频草图之间的像素准确度。在最后一行的默认NUWA 设置中,使用了 3D 近场编码器和 3D 近场解码器,实现了最佳的 FID-vid 和检测到的 PA。如果编码器或解码器之一被全注意力替换,性能会下降,显示出关注邻域条件和邻域生成结果比简单考虑所有信息更好。我们将邻域稀疏和轴向稀疏进行了两方面的比较。首先,邻域稀疏和轴向稀疏的计算复杂性分别为
![]()
![]()
对于生成长视频(更大的 s),邻域稀疏将更加高效。其次,邻域稀疏在视觉生成任务中的性能优于轴向稀疏,这是因为邻域稀疏关注 “邻域” 位置,其中包含空间和时间轴之间的交互,而轴向稀疏将不同轴分开处理,并仅考虑相同轴上的交互。

图 9 展示了本文提出的一个新任务,我们称之为 “文本引导视频操作(TV2V)”。 TV2V 旨在通过文本引导从选择的帧开始更改视频的未来。所有样本都从第二帧开始更改视频的未来。第一行显示原始视频帧,其中潜水员在水中游泳。将 “The diver is swimming to the surface” 输入 NUWA 的编码器并提供第一帧视频后,NUWA 成功生成了第二行中潜水员游向水面的视频。第三行显示另一个成功的示例,其中潜水员游向底部。如果我们想让潜水员飞向天空呢?第四行显示 NUWA 也可以做到,潜水员像火箭一样向上飞行。
5. 结论
在本文中,我们提出 NUWA 作为一个统一的预训练模型,可以用于 8 个视觉合成任务,生成新的图像和视频,或操纵现有的图像和视频。本文的一些贡献包括:(1)一个通用的 3D 编码器-解码器框架,同时涵盖文本、图像和视频;(2)一种考虑了空间和时间轴邻域特征的稀疏注意机制;(3)在 8 个合成任务上进行了全面的实验。这是我们构建 AI 平台的第一步,旨在实现视觉世界的创造,并帮助内容创作者。
附录
A. 3D 稀疏注意力对比
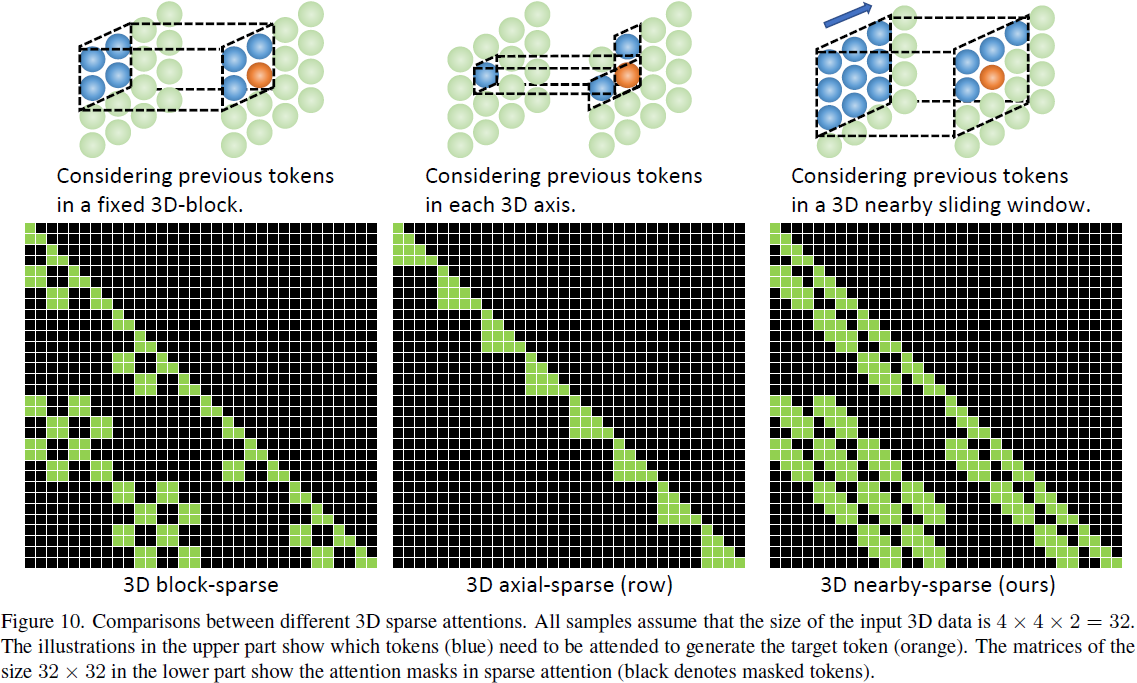
图 10 显示了不同 3D 稀疏注意力之间的比较。假设我们有一个大小为 4x4x2 的 3D 数据,3D 块稀疏注意力的思想是将 3D 数据分成几个固定的块,并分别处理这些块。有很多分块的方法,比如在时间、空间或两者同时分块。图 10 中的 3D 块稀疏示例考虑了时间和空间的分块。3D 数据被分成4 个部分,每个部分的大小为 2x2x2。为了生成橙色标记,3D 块稀疏注意力考虑了固定 3D 块内的先前标记。尽管 3D 块稀疏注意力考虑了空间和时间轴,但对于 3D 块边缘的标记来说,这些空间和时间信息是有限且固定的。只有部分邻域信息被考虑,因为 3D 块外部的某些邻域信息对于块内的标记是不可见的。3D 轴稀疏注意力的思想是考虑沿轴的先前标记。尽管 3D 轴稀疏注意力考虑了空间和时间轴,但这些空间和时间信息沿着轴有限。只有沿轴考虑的部分领域信息,不在轴上的某些邻域信息不会在 3D 轴注意力中考虑。在本文中,我们提出了 3D 邻域稀疏,它考虑了完整的邻域信息,并为每个标记动态生成 3D 邻域注意块。注意力矩阵还显示了作为受关注部分的证据(蓝色),3D 邻域稀疏的光滑性比 3D 块稀疏和 3D 轴稀疏更好。
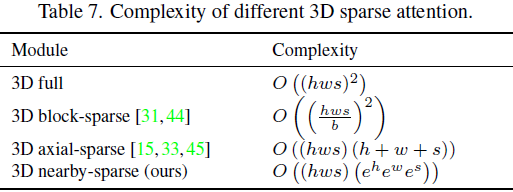
表 7 显示了不同 3D 稀疏注意力的复杂度。 h,w,s 表示 3D 数据的空间高度、空间宽度和时间长度。不同的稀疏机制在不同的情况下都有其计算优势。 例如,对于具有大 h, w, s 的长视频或高分辨率帧,通常 (e^h·e^w·e^s) < (h+w+s), 此时 3D 邻域稀疏注意力比 3D 轴稀疏注意力更有效。如果可以将 3D 数据分成几个没有依赖关系的部分,那么 3D 块稀疏将是一个不错的选择。例如,一部卡通片由几集组成,每一集都讲述一个独立的故事,我们可以简单地将这些故事分开,因为它们之间没有关系。
S. 总结
S.1 主要贡献
本文提出了一个统一多模态预训练模型 NÜWA,设计了一个 3D transformer 编码器-解码器框架来同时处理语言、图像和视频。还提出了一种 3D Nearby Attention(3DNA)机制,以考虑视觉数据的连续性,提升生成质量并减少计算复杂性。
S.2 架构和方法
本文使用的架构如图 2 所示。首先使用适应性的编码器把输入(文本、图像和/或视频)统一编码为 3D 表示。然后使用预训练的解码器解码 3D 表示,从而完成下游任务。相比于以往的仅使用图像或者视频进行预训练的模型,NÜWA 同时使用图像和视频进行训练,从而可以获得更好的性能。
8 个下游任务:文本到图像(T2I),文本到视频(T2V),视频预测(V2V),草图到图像(S2I),图像补全(I2I),文本引导的图像操作(TI2I),草图到视频(S2V)和文本引导视频操作(TV2V)。
3D 数据表示。把文本、图像、视频转化为 3D 符号表示 X ∈ R^(h*w*s*d),h 和 w 分别表示空间轴上的标记数量(高度和宽度),s 表示时间轴上的标记数量,d 是每个标记的维度。
- 文本:使用 BPE 对其进行标记化,获得 X ∈ R^(1*1*s*d)。由于文本没有空间维度,所以使用占位符 1。
- 图像:使用 VQ-GAN,基于可学习码本进行标记化,获得 X ∈ R^(h*w*1*d)。由于图像没有时间维度,使用占位符 1。
- 视频:使用 2D VQ-GAN 对视频的每一帧进行标记化,获得 X ∈ R^(h*w*s*d)。
3D 邻域自注意(3D Nearby Self-Attention,3DNA)。使用注意力机制时,不仅关注当前坐标的标记,还关注该标记的邻域(图 2 中的黑色方框)。
3D 编码器-译码器。编码器和译码器均由 L 个 3DNA 层堆叠而成。编码器建模条件的自注意力,译码器计算生成结果的自注意力以及生成结果与条件之间的交叉注意力。