Windows在设计之初没有考虑过对大数量的多CPU和NUMA架构的设备的支持,大部分关于CPU的设计按照64个为上限来设计。核心数越来越多的多核处理器的进入市场使得微软不得不做较大的改动来进行支持,因此Windows 的进程、线程和NUMA API在各个版本中行为不一样,新版本逐步引入了新的API,微软官方文档中的介绍较为分散。本文旨在梳理和对比API的变动情况,同时考虑到对主流用户的兼容性,重点介绍使用Win7 API进行开发,并附带介绍Win 10 20385中的行为变化。
注1:以下正文中使用“处理器”、“cpu”、”核”的概念时,如没有特别说明,均是指“逻辑处理器”,即包括超线程核在内的不可再划分的处理器单元。
注2:以下正文中使用“节点”、“node”的概念时,如没有特别说明,均是指“逻辑node”,即包括由于单个物理node上cpu个数超过64而被Windows进一步划分成多个虚拟node的节点。
一、处理器组的概念
逻辑处理器与处理器组的关系
从Windows 7开始,当cpu数超过64时windows会将cpu分成处理器组(processor group),一个group最大能有64个cpu(由MAXIMUM_PROCESSORS宏定义),一般会将node内的所有cpu分到同一个group中,一个group也可以包括多个cpu较少的node,但cpu较多的node会被拆成多个虚拟node分别分配给不同group(会导致获取到的最大node数比实际的物理node数多!)。
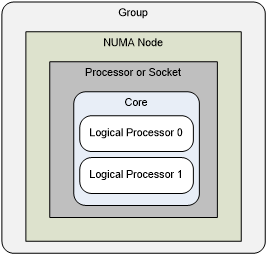
逻辑处理器由其组号及其组内编号标识,使用PROCESSOR_NUMBER 结构体表示,处理器亲和性则使用GROUP_AFFINITY结构体表示。例如,对于一个128核,划分为2个group的系统,全局编号为0的逻辑处理器,在组编号下Group = 0, Number = 0;全局编号为65的逻辑处理器,在组编号下为Group = 1, Number = 1。
typedef struct _PROCESSOR_NUMBER {WORD Group;BYTE Number;BYTE Reserved;
} PROCESSOR_NUMBER, *PPROCESSOR_NUMBER;typedef struct _GROUP_AFFINITY {KAFFINITY Mask;WORD Group;WORD Reserved[3];
} GROUP_AFFINITY, *PGROUP_AFFINITY;微软官方提供了一个命令行工具用于查看系统中拓扑和Group信息,
https://learn.microsoft.com/en-us/sysinternals/downloads/coreinfo,在任务管理器-详细信息-设置相关性中也可以看到Group信息。
NUMA节点与处理器组的关系
- + 一个(逻辑)node必定映射到某个group上
- + 一个group内可以有一或多个(逻辑)node
- + 一个(物理)node可能映射到一或多个group上
进程、线程与处理器组的关系
一个线程只能属于一个group,但由于进程内的不同线程可以处于不同group中,所以一个进程可以属于多个group。默认情况下,windows使用轮询算法为新的进程分配一个group,新创建的线程则继承创建它的线程的group,除非显式地指定线程的group亲和性。也就是说,如果程序代码不对设备上的group做识别,只是创建新的线程和使用旧的接口设置处理器亲和性的话,则最大能利用的cpu数只有group内的64个。
二、NUMA API
按照函数名排序
| 函数 | 描述 | 最低支持版本 |
|---|---|---|
| AllocateUserPhysicalPagesNuma | 分配要映射和取消映射的任何 地址窗口扩展 (指定进程的 AWE) 区域中的物理内存页,并为物理内存指定 NUMA 节点。 | WinVista |
| CreateFileMappingNuma | 为指定文件创建或打开命名或未命名的文件映射对象,并为物理内存指定 NUMA 节点。 | WinVista |
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | WinXP(SP3) |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | Win7 |
| GetNumaAvailableMemoryNode | 检索指定UCHAR节点中的可用内存量。 | WinXP(SP2) |
| GetNumaAvailableMemoryNodeEx | 检索指定USHORT节点中的可用内存量。 | Win7 |
| GetNumaHighestNodeNumber | 检索当前具有的最大数目的节点。 | WinXP(SP2) |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | WinXP(SP2) |
| GetNumaNodeProcessorMask2 | 检索指定节点的多组处理器掩码。 | Win10 20348 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | Win7 |
| GetNumaProcessorNode | 检索指定处理器的UCHAR节点号。 | WinXP(SP2) |
| GetNumaProcessorNodeEx | 检索指定处理器的USHORT 节点号。 | Win7 |
| GetNumaProximityNode | 检索指定邻近度标识符的UCHAR节点号。 | WinVista |
| GetNumaProximityNodeEx | 检索节点号作为指定邻近标识符的USHORT值。 | Win7 |
| GetProcessDefaultCpuSetMasks | 检索由 SetProcessDefaultCpuSetMasks 或 SetProcessDefaultCpuSets 设置的进程默认集中 CPU 集的列表。 | Win10 20348 |
| GetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| MapViewOfFileExNuma | 将映射的文件视图映射到调用进程的地址空间,并指定物理内存的 NUMA 节点。 | WinVista |
| SetProcessDefaultCpuSetMasks | 为指定进程中的线程设置默认的 CPU 集分配。 | Win10 20348 |
| SetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| VirtualAllocExNuma | 在指定进程的虚拟地址空间中保留或提交内存区域,并为物理内存指定 NUMA 节点。 | WinVista |
可以发现,和NumaNode有关的函数,在Win7中添加的Ex版本都将Node的类型由UCHAR改为了USHORT以支持更大的node数。
按照最低版本排序
| 函数 | 描述 | 最低支持版本 |
|---|---|---|
| GetNumaAvailableMemoryNode | 检索指定UCHAR节点中的可用内存量。 | WinXP(SP2) |
| GetNumaHighestNodeNumber | 检索当前具有的最大数目的节点。 | WinXP(SP2) |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | WinXP(SP2) |
| GetNumaProcessorNode | 检索指定处理器的UCHAR节点号。 | WinXP(SP2) |
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | WinXP(SP3) |
| GetNumaProximityNode | 检索指定邻近度标识符的UCHAR节点号。 | WinVista |
| AllocateUserPhysicalPagesNuma | 分配要映射和取消映射的任何 地址窗口扩展 (指定进程的 AWE) 区域中的物理内存页,并为物理内存指定 NUMA 节点。 | WinVista |
| CreateFileMappingNuma | 为指定文件创建或打开命名或未命名的文件映射对象,并为物理内存指定 NUMA 节点。 | WinVista |
| MapViewOfFileExNuma | 将映射的文件视图映射到调用进程的地址空间,并指定物理内存的 NUMA 节点。 | WinVista |
| VirtualAllocExNuma | 在指定进程的虚拟地址空间中保留或提交内存区域,并为物理内存指定 NUMA 节点。 | WinVista |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | Win7 |
| GetNumaAvailableMemoryNodeEx | 检索指定USHORT节点中的可用内存量。 | Win7 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | Win7 |
| GetNumaProcessorNodeEx | 检索指定处理器的USHORT 节点号。 | Win7 |
| GetNumaProximityNodeEx | 检索节点号作为指定邻近标识符的USHORT值。 | Win7 |
| GetProcessDefaultCpuSetMasks | 检索由 SetProcessDefaultCpuSetMasks 或 SetProcessDefaultCpuSets 设置的进程默认集中 CPU 集的列表。 | Win10 20348 |
| GetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| SetProcessDefaultCpuSetMasks | 为指定进程中的线程设置默认的 CPU 集分配。 | Win10 20348 |
| SetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| GetNumaNodeProcessorMask2 | 检索指定节点的多组处理器掩码。 | Win10 20348 |
三、进程、线程API
| 函数 | 描述 | 最低版本 |
|---|---|---|
| GetProcessAffinityMask | 检索指定进程的进程关联掩码和系统的系统关联掩码。 | WinXP |
| SetProcessAffinityMask | 为指定进程的线程设置处理器关联掩码。 | WinXP |
| SetThreadAffinityMask | 为指定线程设置处理器关联掩码。 | WinXP |
| GetProcessGroupAffinity | 检索指定进程的处理器组相关性。 | Win7 |
| GetThreadGroupAffinity | 检索指定线程的处理器组相关性。 | Win7 |
| SetThreadGroupAffinity | 设置指定线程的处理器组相关性。 | Win7 |
| SetThreadIdealProcessor | 设置线程的首选处理器。 系统尽可能在其首选处理器上计划线程。 | WinXP |
| SetThreadIdealProcessorEx | 设置指定线程的首选处理器,并选择性地检索上一个首选处理器。 | Win7 |
| CreateRemoteThreadEx | 创建线程。 | Win7 |
| GetActiveProcessorCount | 返回处理器组或系统中的活动处理器数。 | Win7 |
| GetActiveProcessorGroupCount | 返回系统中活动处理器组的数目。 | Win7 |
| GetCurrentProcessorNumber | 检索调用此函数时当前线程运行所在的处理器号。 | WinVista |
| GetCurrentProcessorNumberEx | 检索调用此函数时当前线程运行所在的处理器组和编号。 | Win7 |
Win7 引入的另一个变化是,SetThreadAffinityMask 和 SetThreadGroupAffinity 现在允许传入的Mask参数为0,代表使用组内的所有CPU。
四、受处理器分组影响的API
只有在系统中处理器数大于64时才会发生分组,否则系统中只有一个group 0,现有的函数在行为上没有变化。
| 函数 | 描述 | 影响 |
|---|---|---|
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | 改动较多,参阅官方文档。主要变化是只能获取当前group中的处理器信息。 |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | Win7新增。参阅官方文档。能够获取所有组的处理器信息。 |
| GetNumaHighestNodeNumber | 检索当前具有的最大数目的节点。 | 返回的node数可能大于真实的物理node数。 |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | 如果调用线程与指定的node不在同一group内,返回的处理器掩码为0。 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | Win7新增。可以不考虑线程所在group,检索任意node。 |
| GetNumaProcessorNode | 检索指定处理器的UCHAR节点号。 | 传入的Processor参数变成组内编号。 |
| GetNumaProcessorNodeEx | 检索指定处理器的USHORT 节点号。 | Win7新增。传入的Processor参数类型为PPROCESSOR_NUMBER。 |
| GetProcessAffinityMask | 检索指定进程的进程关联掩码和系统的系统关联掩码。 | 返回的是组内掩码,如果进程处于多个group,则返回的掩码都为0。 |
| SetProcessAffinityMask | 为指定进程的线程设置处理器关联掩码。 | 传入的参数变为组内掩码;如果进程处于多个group,则返回值为0。 |
| SetThreadAffinityMask | 为指定线程设置处理器关联掩码。 | 传入的参数变为组内掩码。 |
| GetProcessGroupAffinity | 检索指定进程的处理器组相关性。 | Win7新增。 |
| GetThreadGroupAffinity | 检索指定线程的处理器组相关性。 | Win7新增。 |
| SetThreadGroupAffinity | 设置指定线程的处理器组相关性。 | Win7新增。 |
| SetThreadIdealProcessor | 设置线程的首选处理器。 系统尽可能在其首选处理器上计划线程。 | 传入参数变为组内编号。 |
| SetThreadIdealProcessorEx | 设置指定线程的首选处理器,并选择性地检索上一个首选处理器。 | Win7新增。传入的参数类型为PPROCESSOR_NUMBER。 |
| CreateRemoteThreadEx | 创建线程。 | Win7新增。允许用户在创建时指定线程的组亲和性。 |
| GetCurrentProcessorNumber | 检索调用此函数时当前线程运行所在的处理器号。 | 返回值变为组内编号。 |
| GetCurrentProcessorNumberEx | 检索调用此函数时当前线程运行所在的处理器组和编号。 | Win7新增。返回的参数类型为PPROCESSOR_NUMBER。 |
| GetSystemInfo | 检索有关当前系统的信息。 | 返回的 NumberOfProcessors 和 ActiveProcessorsAffinityMask 变为组内处理器信息。 |
总结一下,对于不识别group的现有函数,在引入group后其使用的处理器编号参数的含义变为组内编号,返回的处理器信息只有组内处理器信息。
五、内存绑定策略
Linux下的libnuma提供了独立的线程绑定策略和内存绑定策略,这给予了开发者将线程固定在某个cpu/node上运行的同时却能够在任意node上进行内存分配的灵活性。很可惜,Windows不提供这样的灵活性,没有独立的内存绑定策略,其默认的NUMA内存策略只有一种:在当前执行线程所在的node上进行内存分配,内存不足时到临近节点上分配。意味着我们在做NUMA内存管理时,只能在进行内存分配前,将当前线程切换到指定的cpu/node上运行。
虽然没有提供内存绑定策略这样灵活的机制,但是使用VirtualAllocExNuma函数依然可以在不改变处理器亲和性的情况下在任意的node上进行内存分配,但不方便的地方就是需要自己做内存页管理。具体请参考官方示例:从 NUMA 节点分配内存 - Win32 apps | Microsoft Learn
六、NUMA开发实例
如文章开头提到的,我们重点使用Win7提供的API,以下实例旨在提供一种类似于Linux上的全局逻辑处理器号的开发体验,让实际开发中不需要使用到group号+组内编号这样别扭的形式。
#include <iostream>
#include <string>
#include <windows.h>int max_group = 0;
int max_node = 0;
int max_cpu = 0;// 初始化
void NumaInitMaxCounts() {WORD group;ULONG node;// 获取最大的NUMA节点号GetNumaHighestNodeNumber(&node); // start from 0max_node = node + 1;// 获取系统中的processor group和总的cpu个数max_group = GetActiveProcessorGroupCount();for (group = 0; group < max_group; group++) {max_cpu += GetActiveProcessorCount(group); // 将所有group的cpu个数累加}
}// 将全局cpu号转换为组内编号
int NumaGetProcessorGroup(int cpu, _Out_ PROCESSOR_NUMBER *proc_num) {WORD group;int count;if (cpu < 0 || cpu >= max_cpu) {printf("NumaGetProcessorGroup: Invalid cpu %d", cpu);return -1;}for (group = 0; group < max_group; group++) {count = GetActiveProcessorCount(group);if (count - cpu - 1 >= 0) {proc_num->Group = group;proc_num->Number = cpu;return 0;}elsecpu -= count;}// should not reach herereturn -2;
}// 获取全局cpu号所在的node号
int NumaGetProcessorNode(int cpu) {BOOL bret;USHORT node;PROCESSOR_NUMBER proc_num = {};if (cpu < 0 || cpu >= max_cpu) {printf("NumaGetProcessorNode: Invalid cpu %d", cpu);return -1;}// 首先获取cpu组内编号if (NumaGetProcessorGroup(cpu, &proc_num) != 0)return -2;// 获取node号bret = GetNumaProcessorNodeEx(&proc_num, &node);if (!bret)return -2;return node;
}// 绑定线程到node上运行、分配内存
int NumaBindNode(USHORT node) {GROUP_AFFINITY gaffinity;GROUP_AFFINITY prev_gaffinity;BOOL bret;if (node >= max_node) {printf("NumaBindNode: Invalid node %u", node);return -1;}// 获取node下的所有cpu maskbret = GetNumaNodeProcessorMaskEx(node, &gaffinity);if (!bret)return -2;// 设置当前线程组CPU亲和性bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, &prev_gaffinity);if (!bret)return -2;return 0;
}// 绑定线程到cpu(全局cpu号)上运行、分配内存
int NumaBindProcessor(int cpu) {BOOL bret;int ret;PROCESSOR_NUMBER proc_num = {};GROUP_AFFINITY gaffinity = {};GROUP_AFFINITY prev_gaffinity = {};if (cpu < 0 || cpu >= max_cpu) {printf("NumaBindProcessor: Invalid cpu %d", cpu);return -1;}// 首先获取cpu组内编号ret = NumaGetProcessorGroup(cpu, &proc_num);if (ret < 0)return ret;gaffinity.Group = proc_num.Group;gaffinity.Mask = 1LL << proc_num.Number;// 设置当前线程组CPU亲和性bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, &prev_gaffinity);if (!bret)return -2;return 0;
}上述实例中提供了两种使用方式,一种是基于全局逻辑处理器号NumaBindProcessor(),以及基于node号的NumaBindNode()。
尽管(逻辑)node和group不是一种从属的关系,而是一种单映射关系(一个node对应于一个group,反之不然),但是node下的cpu是从属于某个group下的,这一点从GetNumaNodeProcessorMaskEx()返回的Mask中带有Group号可以看到,因此我们还是应当使用识别group的API来设置进程、线程亲和性。
七、从 Windows 10 内部版本 20348 开始的行为
没错,又变了!(-_-||)但幸好影响到的现有API只有4个。
Win 10 Build 20348,这个版本并没有发布给普通的Win 10用户,它与Windows Server 2022发布版本的版本号一致,在Windows SDK页面上也注明了该版本主要用于Server开发的用途,新增的API函数参考页面则直接注明最低支持版本为Win 11。所以,如果使用该API开发的话,基本上等同于目标群体为Win 11/Win Server 2022用户。
从 Windows 10 内部版本 20348 (部分文档中称为Iron Build)开始,为更好地支持包含 64 个以上处理器的NUMA系统,部分NUMA及相关函数的行为发生了变动。
创建“假”节点以适应组和节点之间的 1:1 映射的关系会导致出现混淆行为,即报告的 NUMA 节点数与物理节点数不符,因此,从 Windows 10 Build 20348 开始,OS 行为已做更改,停止创建"假"节点并允许多个组与一个node相关联,因此现在可以报告系统的真实 NUMA 拓扑。
作为 OS 的这些更改的一部分,许多 NUMA API 已更改,以支持报告node上的多个组。同时为兼容旧API,系统默认为每个节点分配一个主组。
由于删除节点拆分可能会影响现有应用程序,因此允许使用注册表值来选择重新启用旧的节点拆分行为。 可以通过在HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\NUMA下创建名为“SplitLargeNodes”的 REG_DWORD 值来重新启用节点拆分。 对此设置的更改需要重启才会生效。
reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\NUMA" /v SplitLargeNodes /t REG_DWORD /d 1从 Windows 11 和 Windows Server 2022 开始,在具有 64 个以上的处理器的设备上,进程和线程的相关性默认情况下将包括所有处理器组中的所有处理器。
新增及改动的API
| 函数 | 描述 | 影响 |
|---|---|---|
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | RelationNumaNode 返回的是调用线程所在group的信息。 |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | RelationNumaNode 返回的是node所对应主group的信息,GroupCount的值为1。新增RelationNumaNodeEx。 |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | 只返回node所对应主group的信息,并且仅在调用线程属于该group时返回。 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | 只返回node所对应主group的信息。 |
| GetProcessDefaultCpuSetMasks | 检索由 SetProcessDefaultCpuSetMasks 或 SetProcessDefaultCpuSets 设置的进程默认集中 CPU 集的列表。 | 新增。 |
| GetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | 新增。 |
| SetProcessDefaultCpuSetMasks | 为指定进程中的线程设置默认的 CPU 集分配。 | 新增。 |
| SetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | 新增。 |
| GetNumaNodeProcessorMask2 | 检索指定节点的多组处理器掩码。 | 新增。 |
为了适应新的行为,建议新的代码都使用GetNumaNodeProcessorMask2。
八、进程、线程对亲和性的继承
Linux下将线程作为调度的单元,不区分进程和线程,新的线程/进程直接继承创建它的线程的处理器亲和性和内存策略。但是Windows下区分进程和线程,Mask和Group又拥有不同的继承策略:
| 进程 | 线程 | |
| Mask | 新进程默认继承父进程的掩码 | 新线程默认继承进程(process)的掩码 |
| Group | 新进程由OS以轮转方式分配一个Group | 新线程默认继承创建它的线程(thread)的Group |
如果需要在创建时指定亲和性,可以使用:
CreateRemoteThreadEx() + PROC_THREAD_ATTRIBUTE_GROUP_AFFINITY
CreateProcess() + INHERIT_PARENT_AFFINITY,注意如果父进程属于多个group,则从中随机选取一个分配给新进程。
参考:
> Process Creation Flags (WinBase.h) - Win32 apps | Microsoft Learn
> MoreThan64proc.docx "Group, Process, and Thread Affinity" 小节
验证线程对Mask的继承:
#include <iostream>
#include <string>
#include <windows.h>DWORD __stdcall func2(LPVOID arg) {BOOL bret;GROUP_AFFINITY gaffinity = {};GROUP_AFFINITY prev_gaffinity = {};PROCESSOR_NUMBER proc_num = {};bret = GetThreadGroupAffinity(GetCurrentThread(), &gaffinity);printf("ret = %d, Thread 2 ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, gaffinity.Group, gaffinity.Mask);GetCurrentProcessorNumberEx(&proc_num);printf("Thread 2 CurrentProcessorGroup = %u, CurrentProcessorNum = %u\n", proc_num.Group, proc_num.Number);Sleep(100);return 0;
}DWORD __stdcall func1(LPVOID arg) {BOOL bret;GROUP_AFFINITY gaffinity = {};GROUP_AFFINITY prev_gaffinity = {};gaffinity.Group = 0;gaffinity.Mask = 1; // 设置线程1 使用 CPU 0bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, &prev_gaffinity);printf("ret = %d, Thread 1 prev ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, prev_gaffinity.Group, prev_gaffinity.Mask);bret = GetThreadGroupAffinity(GetCurrentThread(), &gaffinity);printf("ret = %d, Thread 1 new ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, gaffinity.Group, gaffinity.Mask);// 创建线程2CreateThread(NULL, 4096, func2, NULL, 0, NULL);Sleep(500);return 0;
}int main() {BOOL bret;PROCESSOR_NUMBER proc_num = {};GROUP_AFFINITY gaffinity = {};DWORD_PTR mask;DWORD_PTR sysmask;// 设置process Mask为 CPU 0~3mask = pow(2, 4) - 1;SetProcessAffinityMask(GetCurrentProcess(), mask);bret = GetProcessAffinityMask(GetCurrentProcess(), &mask, &sysmask);printf("ret = %d, ProcessAffinityMask = %llu, SystemMask = %llu\n", bret, mask, sysmask);// 设置process Mask为 CPU 0 + CPU 1gaffinity.Group = 0;gaffinity.Mask = mask = pow(2, 2) - 1;bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, nullptr);bret = GetThreadGroupAffinity(GetCurrentThread(), &gaffinity);printf("ret = %d, Main ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, gaffinity.Group, gaffinity.Mask);CreateThread(NULL, 4096, func1, NULL, 0, NULL);Sleep(1000);return 0;
}在我的有4个处理器设备上运行的结果如下:
ret = 1, ProcessAffinityMask = 15, SystemMask = 15
ret = 1, Main ThreadGroupAffinity Group = 0, Mask = 3
ret = 1, Thread 1 prev ThreadGroupAffinity Group = 0, Mask = 15
ret = 1, Thread 1 new ThreadGroupAffinity Group = 0, Mask = 1
ret = 1, Thread 2 ThreadGroupAffinity Group = 0, Mask = 15
Thread 2 CurrentProcessorGroup = 0, CurrentProcessorNum = 1
九、总结
1. 自Win7引入处理器组开始,原有的不识别group的函数,参数和返回值都变成组内编号/信息。
2. 自Win10 20348 由于node可以关联多个group,引入“主组”之后,原有的node相关不支持多个group的函数,参数和返回值都变成主组信息。
参考资料
NUMA 支持 - Win32 apps | Microsoft Learn
处理器组 - Win32 apps | Microsoft Learn
What's New in Processes and Threads - Win32 apps | Microsoft Learn
download.microsoft.com/download/a/d/f/adf1347d-08dc-41a4-9084-623b1194d4b2/
MoreThan64proc.docx
White Paper "Supporting Systems That Have More Than 64 Processors" 介绍处理器组最全面的文档!
从 NUMA 节点分配内存 - Win32 apps | Microsoft Learn
Windows SDK and emulator archive | Microsoft Developer
Windows Server 2022 Now Generally Available - Microsoft Community Hub
Coreinfo - Sysinternals | Microsoft Learnhhansh