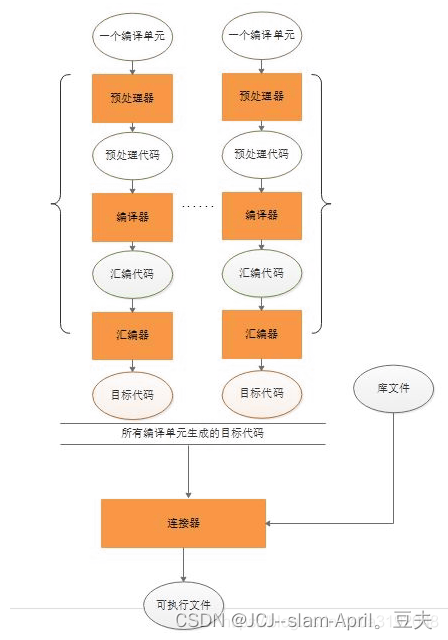
在上一篇博文中,博主完成了MMDetection框架的环境部署与推理过程,下面进行该框架的训练过程,训练的入口文件为tools/train.py,我们需要配置的内容如下:
parser.add_argument('--config',default="/home/ubuntu/programs/mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_2x_coco.py", help='train config file path')
parser.add_argument('--work-dir',default="output/", help='the dir to save logs and models')
首先是指明要训练模型的配置文件,这里博主使用的是Faster-RCNN,该模型的骨干网络为ResNet50,使用的是COCO数据集,随后指明保存的路径。
此外,我们可以指定预训练模型,即指定resume参数,由于博主使用的是自制数据集,直接使用其权重模型会报错,所以我们就直接从头开始训练。
自定义数据集
博主使用的是自定义数据集,那么就需要修改几个内容:
首先是数据集的配置,修改mmdet文件下的datasets/coco.py:
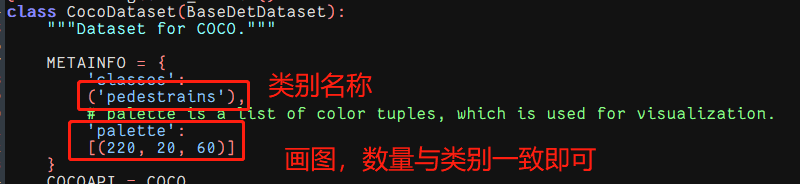
随后修改mmdet/evaluation/functional/下的class_names.py:
def coco_classes() -> list:"""Class names of COCO."""return ['pedestrains']
这里需要一提的是,在MMdetection文件下有一个mmdet文件,而我们配置的环境中也有一个mmdet文件,默认是使用系统里的文件的,因此博主先前一直是修改的mmdetetcion里面的mmdet文件,这会报错:
data_bytes = np.concatenate(data_list) File "<__array_function__ internals>", line 6, in concatenate
这时就要修改环境中mmdet文件了,当然也可以把这个包删掉,但对博主而言无所谓,因为博主并不打算在上面修改代码。该包的路径:
/home/ubuntu/.conda/envs/mmdet/lib/python3.7/site-packages/mmdet/
完成上面的配置后,只需要再修改faster-rcnn中的类别数目即可,默认是80,我们改为1:
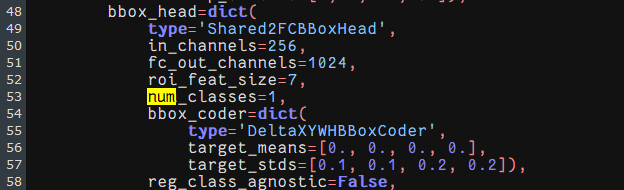
随后便可以运行了,完成一个epoch用时大约50分钟,还是可以接受的。
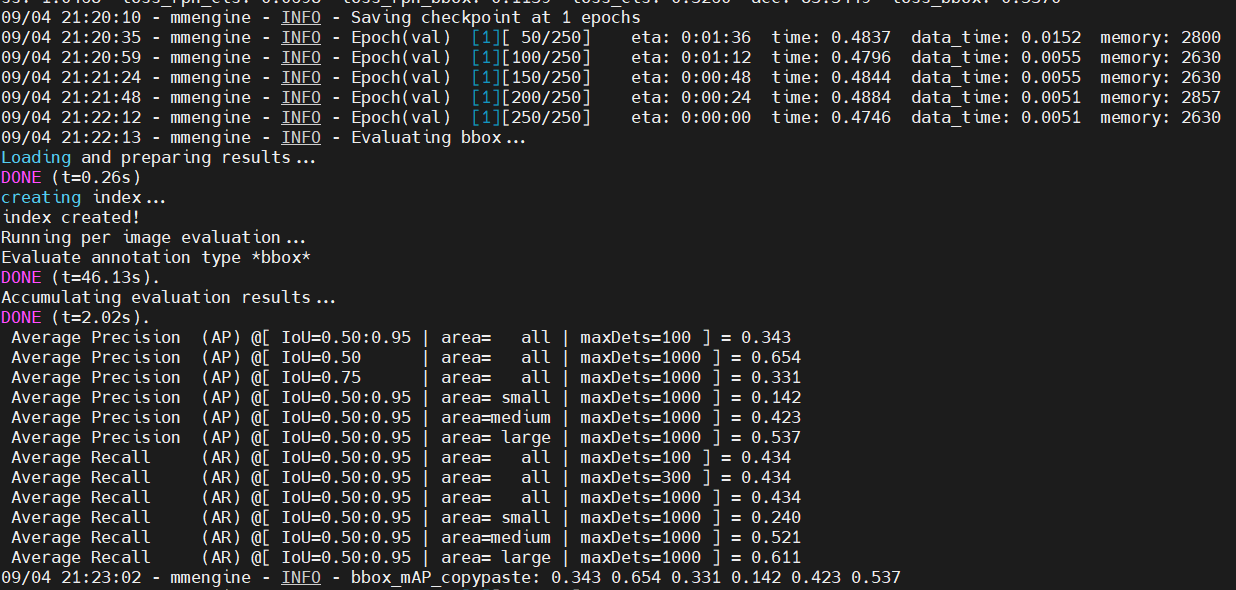
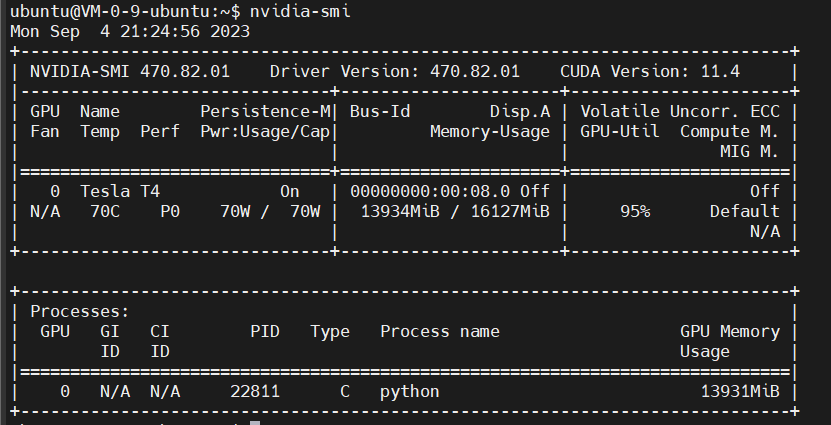
GPU占用情况:




![java八股文面试[JVM]——JVM性能优化](https://img-blog.csdnimg.cn/img_convert/944a51e6faf749f92a3778a203c66a1b.png)