文章目录
- 基本概念
- N与NP
- 泛化能力
- 性能度量
- 比较检验
- 线性回归
- 逻辑回归
- 神经网络
基本概念
N与NP

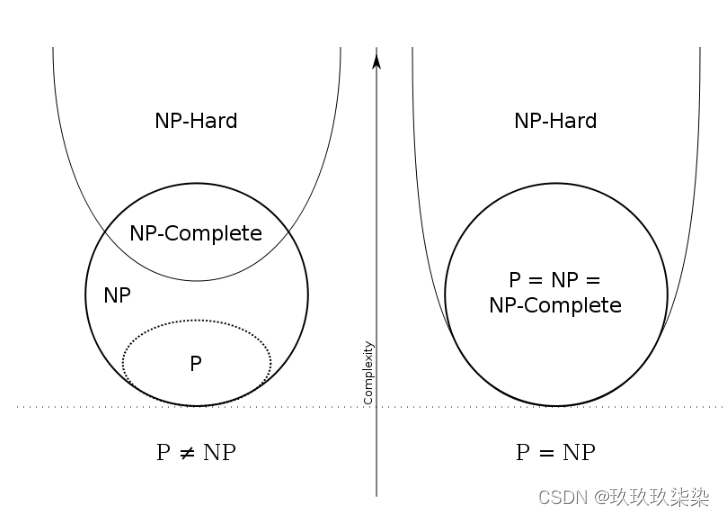
P问题:一个问题可以在多项式(O(n^k) 的时间复杂度内解决
例如:n个数的排序(不超过O(n^2))
NP问题:一个问题的解可以在多项式的时间内被证实或证伪
例如:典型的子集求和问题,给定一个整数集合求是否存在一个非空子集它的和为零。如给定集合s={-1,3,2,-5,6},很明显子集{3,2,-5}能满足问题,并且验证该解只需要线性时间复杂度就能被证实。
NP-hard问题:任意np问题都可以在多项式时间内归约为该问题。归约的意思是为了解决问题A,先将问题A归约为另一个问题B,解决问题B同时也间接解决了问题A。
例如,停机问题。
NPC问题:既是NP问题,也是NP-hard问题。
例如,SAT问题(第一个NPC问题)。该问题的基本意思是,给定一系列布尔变量以及它的约束集,是否存在一个解使得它的输出为真。
相互关系:显然,所有P问题都是NP问题,反之则不一定。npc问题是np问题的子集,也是p问题和np问题的差异所在。如果找到一个多项式内能被解决的npc问题的解决方法,那么P=NP。
泛化能力
是指机器学习算法对新鲜样本的适应能力。 学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
提取几个关键词:新鲜样本、适应能力、规律、合适输出。由此可见,经训练样本训练的模型需要对新样本做出合适的预测,这是泛化能力的体现。
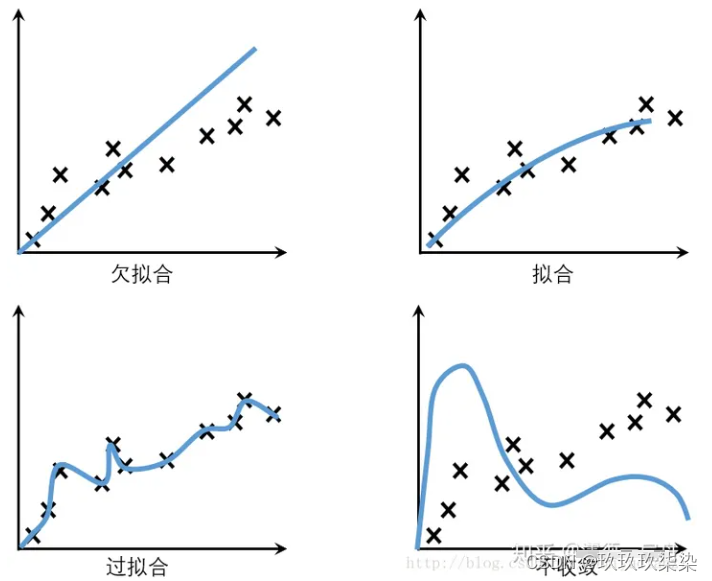
考试成绩差的同学,有这三种可能:一、泛化能力弱,做了很多题,始终掌握不了规律,不管遇到老题新题都不会做;二、泛化能力弱,做了很多题,只会死记硬背,一到考试看到新题就蒙了;三、完全不做题,考试全靠瞎蒙。机器学习中,第一类情况称作欠拟合,第二类情况称作过拟合,第三类情况称作不收敛。
性能度量
错误率与精度
查准率、查全率与F1
ROC与AUC
代价敏感错误率与代价曲线
比较检验
对学习器的性能进行评估比较,比较泛化性能。
(西瓜书)
线性回归

Sigmod绘图
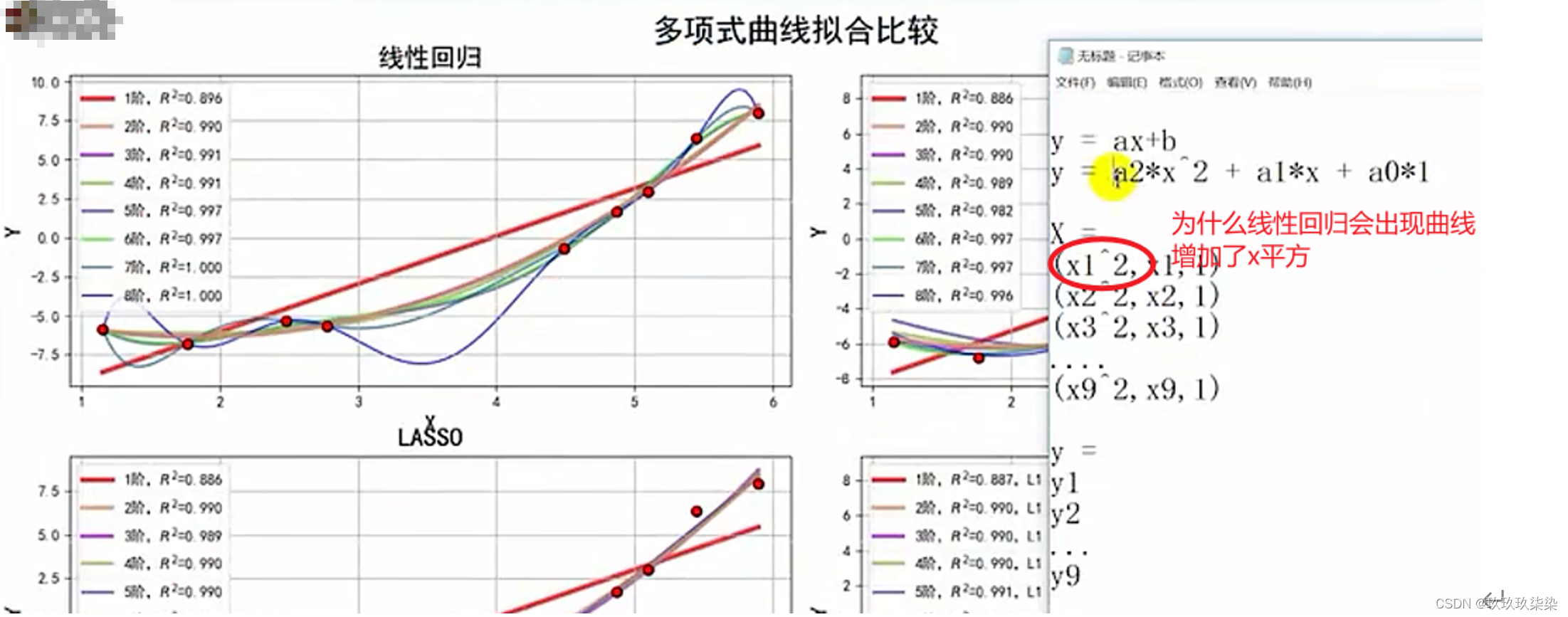
#
逻辑回归
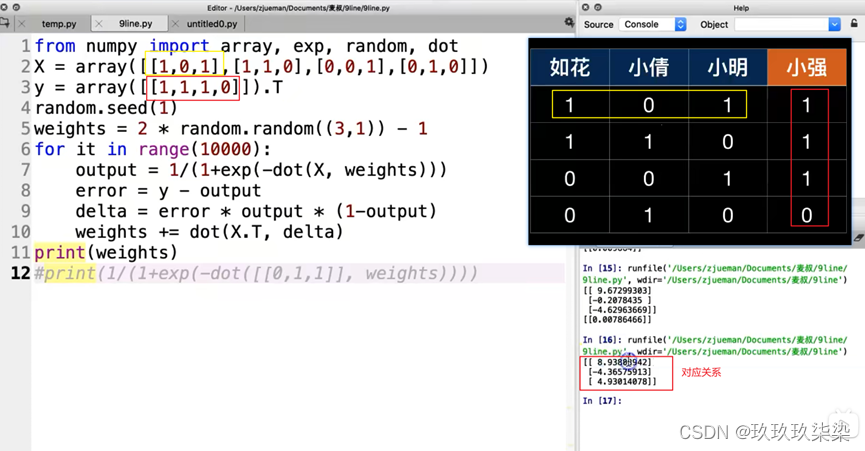
1 简介 逻辑回归也被称为广义线性回归模型,它与线性回归模型的形式基本上相同,最大的区别就在于它们的因变量不同,如果是连续的,就是多重线性回归;如果是二项分布,就是Logistic回归。
Logistic回归虽然名字里带“回归”,但它实际上是一种分类方法,主要用于二分类问题(即输出只有两种,分别代表两个类别),也可以处理多分类问题。
线性回归是用来预测连续变量的,其取值范围(-∞,+∞),而逻辑回归模型是用于预测类别的,例如,用逻辑回归模型预测某物品是属于A类还是B类,在本质上预测的是该物品属于A类或B类的概率,而概率的取值范围是0~1,因此不能直接用线性回归方程来预测概率,此时就涉及到Sigmoid函数,可将取值范围为(-∞,+∞)的数转换到(0,1)之间。如下图所示。
在这里插入图片描述
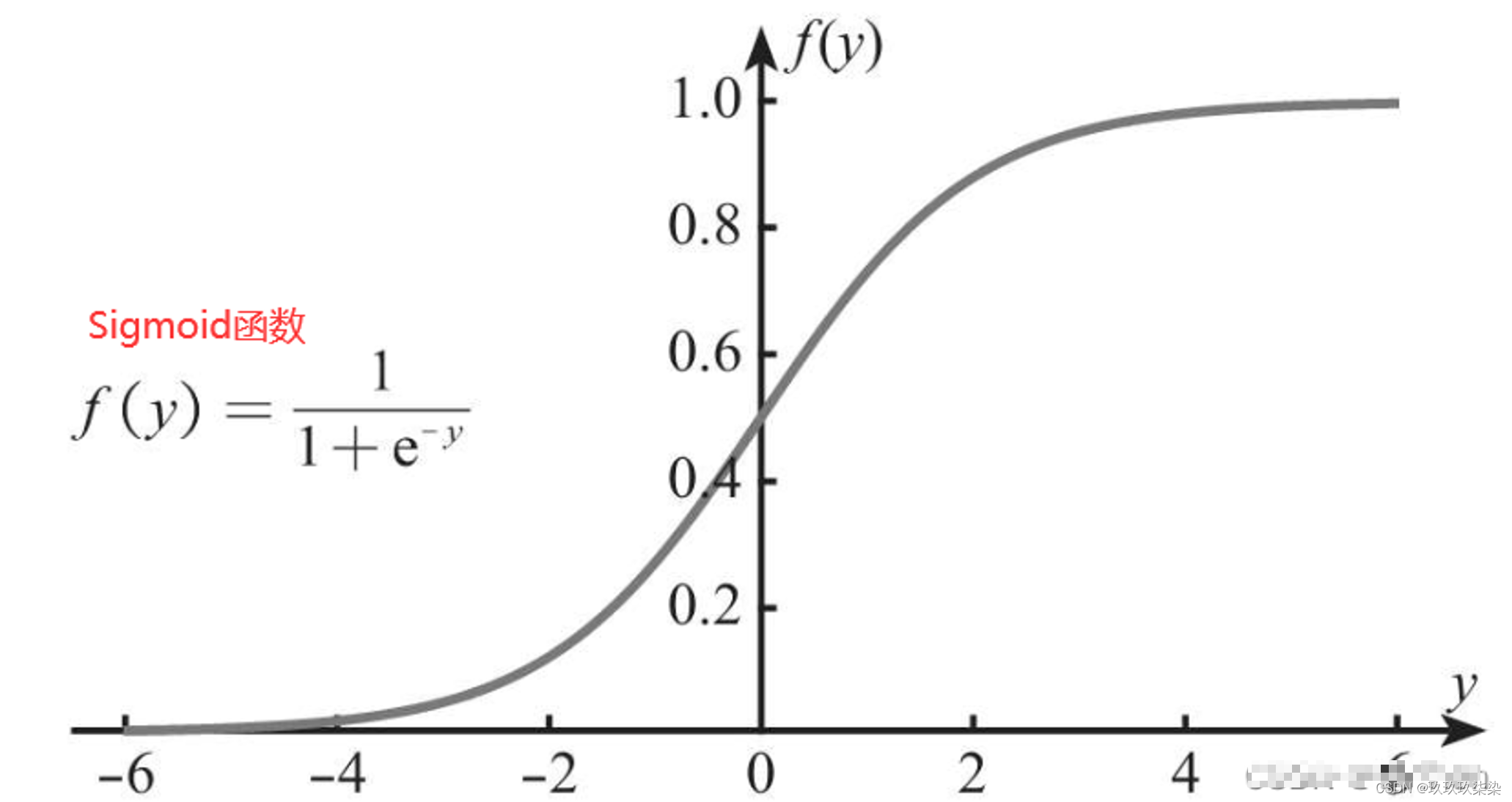
总结来说,逻辑回归模型本质就是将线性回归模型通过Sigmoid函数进行了一个非线性转换,得到一个介于0~1之间的概率值,对于二分类问题(分类0和1)而言,其预测分类为1(或者说二分类中数值较大的分类)的概率可以用如下所示的公式计算。因为概率和为1,则分类为0(或者说二分类中数值较小的分类)的概率为1-P。逻辑回归模型的本质就是预测属于各个分类的概率,有了概率之后,就可以进行分类了。2 优缺点 优点:速度快,适合二分类问题;简单、易于理解,可以直接看到各个特征的权重;能容易地更新模型吸收新的数据。缺点:对数据和场景的适应能力有局限性,不如决策树算法适应性强。3 适用场景 ·寻找危险因素:寻找某一疾病的危险因素等;·预测:根据模型,预测在不同的自变量情况下,发生某种疾病或某种情况的概率有多大;·判别:实际上跟预测有些类似,也是根据模型,判断某人属于某种疾病或属于某种情况的概率有多大。
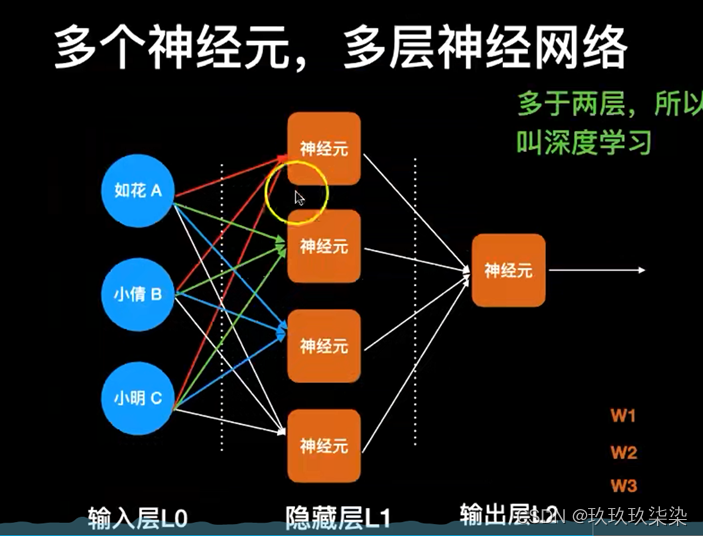
神经网络
一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
神经元模型的使用可以这样理解:我们有一个数据,称之为样本。样本有四个属性,其中三个属性已知,一个属性未知。我们需要做的就是通过三个已知属性预测未知属性。
具体办法就是使用神经元的公式进行计算。三个已知属性的值是a1,a2,a3,未知属性的值是z。z可以通过公式计算出来。
这里,已知的属性称之为特征,未知的属性称之为目标。假设特征与目标之间确实是线性关系,并且我们已经得到表示这个关系的权值w1,w2,w3。那么,我们就可以通过神经元模型预测新样本的目标。
事实上,神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。初学者可能认为画神经网络的结构图是为了在程序中实现这些圆圈与线,但在一个神经网络的程序中,既没有“线”这个对象,也没有“单元”这个对象。实现一个神经网络最需要的是线性代数库。
两层神经网络通过两层的线性模型模拟了数据内真实的非线性函数。因此,多层的神经网络的本质就是复杂函数拟合。
在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术 。
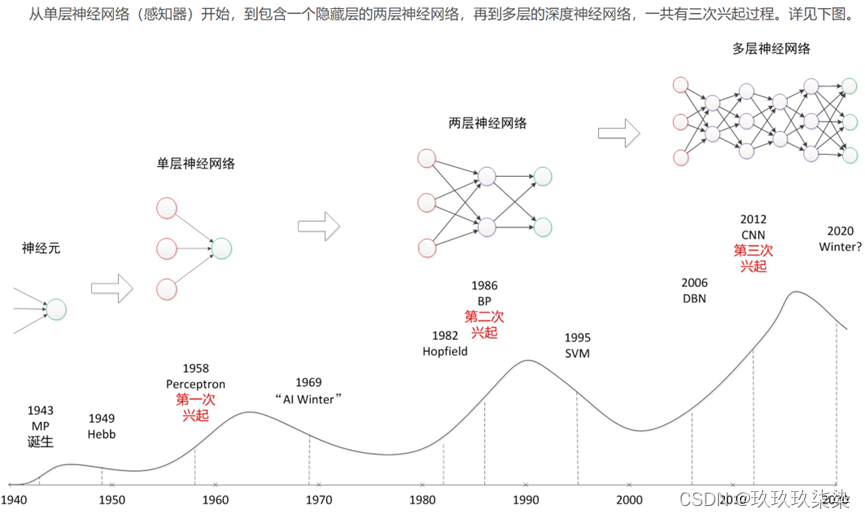
多层神经网络






![解决C++ 遇笔试题输入[[1,2,3,...,],[5,6,...,],...,[3,1,2,...,]]问题](https://img-blog.csdnimg.cn/cf5ef861771746f1997b82e7b856e2f3.png)
![串行协议——USB驱动[基础]](https://img-blog.csdnimg.cn/1ad1a35a30a0484d95e3a624dd3da9c5.png)