ClickHouse和Hive究竟哪些区别
ClickHouse和Hive都是用于大数据处理和分析的分布式存储和计算系统,但它们之间存在一些区别:
-
架构:ClickHouse采用列式存储和向量化执行引擎,可以实现亚秒级别的数据查询。而Hive采用基于Hadoop的数据存储和MapReduce计算引擎,数据查询速度相对较慢。
-
查询语言:ClickHouse使用类似于SQL的查询语言,称为ClickHouse-SQL,易于学习和上手。Hive使用的是类似SQL的查询语言,但Hive在执行查询时需要将查询转换为MapReduce任务,查询速度较慢。
-
数据类型:ClickHouse支持多种数据类型,包括数值、字符串、日期等,可以方便地处理各种类型的数据。而Hive主要支持数值和字符串类型,对于其他数据类型需要进行转换。
-
数据导入和导出:ClickHouse支持多种数据导入方式,包括CSV、JSON、Parquet等,同时也支持多种数据导出方式,包括CSV、JSON、Parquet等。而Hive主要支持Hadoop Distributed File System(HDFS)的数据导入和导出。
-
实时处理:ClickHouse支持实时数据处理,可以实时地分析和处理数据。而Hive主要用于离线数据分析,不支持实时处理。
-
性能:ClickHouse具有较高的查询性能,可以实现亚秒级别的数据查询。而Hive查询性能相对较慢,需要进行MapReduce任务的转换和执行。
ClickHouse是什么
clickhouse是用于联机分析(OLAP)的列式数据库管理系统
(补充:OLAP 与OLTP. 联机分析处理(OLAP) 系统的主要用途是分析聚合数据,而联机事务处理(OLTP) 系统的主要用途是处理数据库事务。前者专注于构建报告,每个报告都基于大量历史数据,但这样做的频率不高。而后者通常处理连续的事务流,不断修改数据的当前状态。
OLAP 和 OLTP 系统之间的基本权衡仍然是:
• 为了有效地构建分析报告,能够单独读取列至关重要,因此大多数 OLAP 数据库都是列式的,
• 单独存储列会增加行操作的成本,例如附加或就地修改,与列的数量成比例(如果系统尝试收集事件的所有详细信息以防万一,这可能会很大)。因此,大多数 OLTP 系统存储按行排列的数据。)
传统的行式数据库系统中,数据按行存储,处于同一行的数据被物理的存在一起。
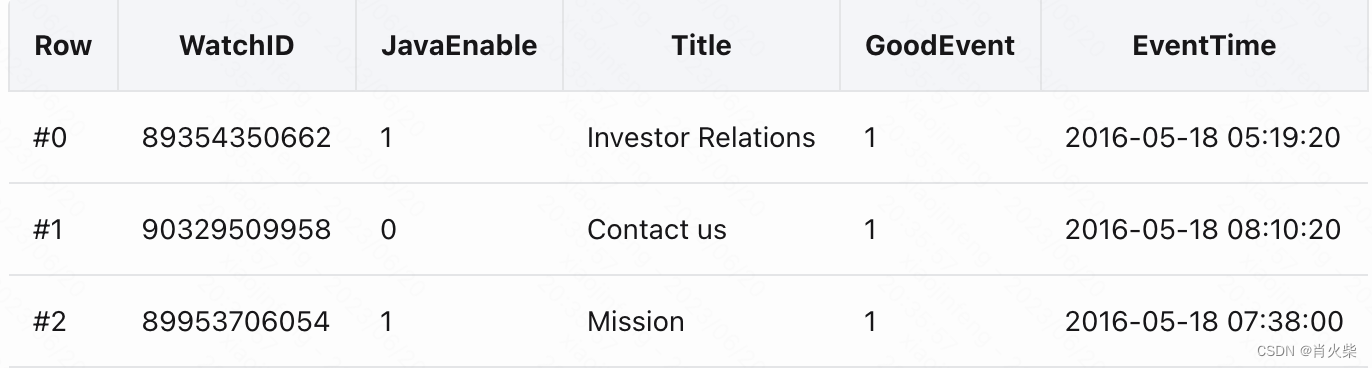
mysql、Postgres和MS SQL Server 是常见的行式数据库系统。而列式数据库是将同一个列的数据存储在一起.
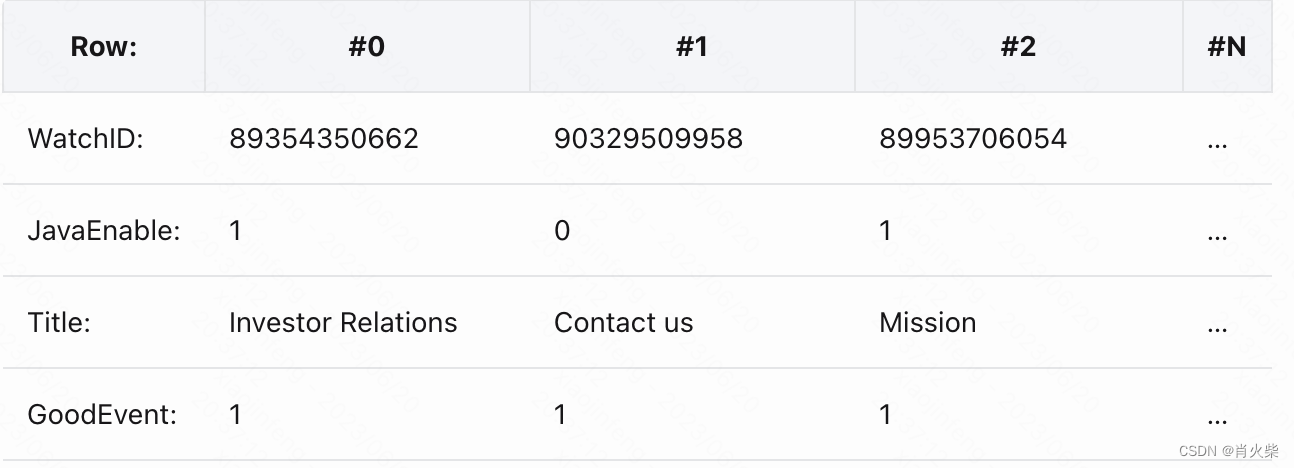
OLAP是什么
OLAP场景的关键特征
总结下来是,一但写入就不改了,主要是读操作,用于分析。有大量的列,查询结果一般远小于数据源,因为是通常是聚合操作。
• 绝大多数是读请求
• 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
• 已添加到数据库的数据不能修改。
• 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
• 宽表,即每个表包含着大量的列
• 查询相对较少(通常每台服务器每秒查询数百次或更少)
• 对于简单查询,允许延迟大约50毫秒
• 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
• 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
• 事务不是必须的
• 对数据一致性要求低
• 每个查询有一个大表。除了他以外,其他的都很小。
• 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
为何不使用 MapReduce等技术?
我们可以将MapReduce这样的系统称为分布式计算系统,其中的reduce操作是基于分布式排序的。这个领域中最常见的开源解决方案是Apache Hadoop。
这些系统不适合用于在线查询,因为它们的延迟很大。换句话说,它们不能被用作网页界面的后端。这些类型的系统对于实时数据更新并不是很有用。如果操作的结果和所有中间结果(如果有的话)都位于单个服务器的内存中,那么分布式排序就不是执行reduce操作的最佳方式,这通常是在线查询的情况。在这种情况下,哈希表是执行reduce操作的最佳方式。优化map-reduce任务的一种常见方法是使用内存中的哈希表进行预聚合(部分reduce)。用户手动执行此优化。在运行简单的map-reduce任务时,分布式排序是导致性能下降的主要原因之一。
ClickHouse特性
- 固定长度节省空间
在一个真正的列式数据库管理系统中,除了数据本身外不应该存在其他额外的数据。这意味着为了避免在值旁边存储它们的长度«number»,你必须支持固定长度数值类型。例如,10亿个UInt8类型的数据在未压缩的情况下大约消耗1GB左右的空间,如果不是这样的话,这将对CPU的使用产生强烈影响。即使是在未压缩的情况下,紧凑的存储数据也是非常重要的,因为解压缩的速度主要取决于未压缩数据的大小。 - 数据压缩高效
除了在磁盘空间和CPU消耗之间进行不同权衡的高效通用压缩编解码器之外,ClickHouse还提供针对特定类型数据的专用编解码器 - 基于磁盘存储
提供每GB更低的存储成本,比其他需要在内存中工作的列式数据库更省钱。 - 多核心并行处理
- 多服务器分布式处理
- 支持sql
使用的是基于sql的声明式查询语言。 - 实时的数据更新、适合在线查询
为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断地高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。 - 支持数据复制和数据完整性
ClickHouse使用异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。在大多数情况下ClickHouse能在故障后自动恢复,在一些少数的复杂情况下需要手动恢复。
劣势
- 没有完整是事务支持
- 缺少高频率 低延迟的修改数据的能力,仅能批量删除修改数据
- 稀疏索引导致不适合利用其键 检索单行的点查询
(注:点查询是应用访问OLTP数据库的一种常见方式,特点是返回结果前只扫描表中的少量数据,在淘宝上查看订单或者商品信息对应到数据库上的操作就是点查。)
ClickHouse解析JSON字符串和JSON数组
SELECTJSONExtractArrayRaw(cast(JSONExtractArrayRaw(cast(JSONExtractString(JSONExtractArrayRaw(cast(JSONExtractString(JSONExtractString(a.info,'logOfChain'),'11') as String) ,'logInfo')[1],'table') as String),'rows')[1] as String) ,'columnValue')[2]
FROM table_name
WHERE toDate(`timestamp` / 1000) in ( '2023-08-16')and toHour(toDateTime(`timestamp` / 1000)) in ('17')and userId = 'xxxxx'and reqId = 'xxxxx'andORDER BY `timestamp` DESC
LIMIT 10
参考
https://clickhouse.com/docs/zh
https://juejin.cn/post/7233004121682575418









![算法:移除数组中的val的所有元素---双指针[2]](https://img-blog.csdnimg.cn/00a0b6f4bc3244498610301823a21bc8.png#pic_center)