分类任务评价指标
分类任务中,有以下几个常用指标:
- 混淆矩阵
- 准确率(Accuracy)
- 精确率(查准率,Precision)
- 召回率(查全率,Recall)
- F-score
- PR曲线
- ROC曲线
1. 混淆矩阵
| 真实1 | 真实0 | |
|---|---|---|
| 预测1 | TP | FP |
| 预测0 | FN | TN |
从预测的角度看:
- TP: True Positive。预测为1,实际为1,预测正确。
- FP: False Positive。预测为1,实际为0,预测错误。
- FN: False Negative。预测为0,实际为1,预测错误。
- TN: True Negative。预测为0,实际为0,预测正确。
2.准确率(Accuracy)
在所有预测结果中,正确预测的占比:
$Accuracy = \frac{TP+TN}{TP+FP+FN+TN} $
准确率衡量整体(包括正样本和负样本)的预测准确度,但不适用与样本不均衡的情况。比如有100个样本,其中正样本90个,负样本10个,此时模型将所有样本都预测为正样本就可以取得 90% 的准确率,但实际上这个模型根本就没有分类的能力。
3. 精确率(查准率,Precision)
在所有预测为1的样本中,正确预测的占比:
$ Precision = \frac{TP}{TP+FP}$
衡量正样本的预测准确度。
4. 召回率(查全率,Recall)
在所有真实标签为1的样本中,正确预测的占比:
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
衡量模型预测正样本的能力。
5. F-score
综合考虑精确率和召回率:
$ F_{score}=(1+\beta2)\frac{PR}{\beta2*P+R} $
- β=1,表示Precision与Recall一样重要(此时也叫F1-score)
- β<1,表示Precision比Recall重要
- β>1,表示Recall比Precision重要
精确率和召回率相互“制约”:精确率高,则召回率就低;召回率高,则精确率就低。因此就需要综合考虑它们,最常见的方法就是 F-score 。F-score越大模型性能越好。
6. PR曲线
6.1 绘制方法
PR曲线以召回率R为横坐标、以精确率P为纵坐标,以下面的数据为例说明一下绘制方法:
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 预测为正类的概率 score | 0.9 | 0.8 | 0.7 | 0.5 | 0.3 |
| 实际类别 class | 1 | 0 | 1 | 1 | 0 |
-
将每个样本的预测结果按照预测为正类的概率排序(上面已排序)
-
依次看每个样本
a) 对于样本1,将它的 score 0.9 作为阈值,即 score >= 0.9时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 0 预测0 2 2 b) 对于样本2,将它的 score 0.8 作为阈值,即 score >= 0.8时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 1 预测0 2 1 c) ……
d) ……
e) 对于样本5,将它的 score 0.3 作为阈值,即 score >= 0.3时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 3 2 预测0 0 0 -
根据上面的混淆矩阵,依次算出 5 对(R, R),以召回率R为横坐标、以精确率P为纵坐标,将这些点连接起来即得到 PR 曲线。
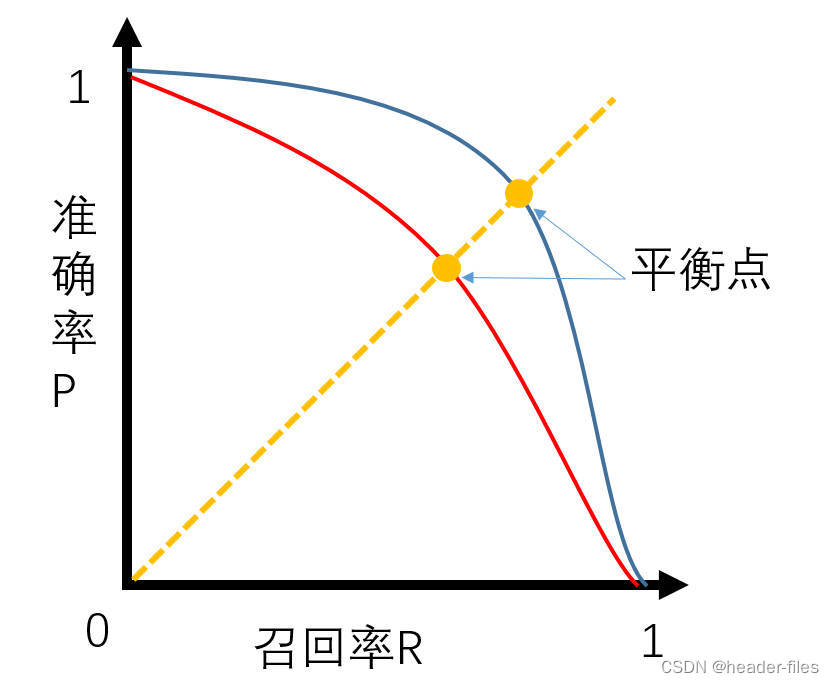
6.2 模型性能衡量方法
-
如果曲线A完全“包住”曲线B,则A的性能优于B(P和R越高,代表算法分类能力越强);
-
曲线AB发生交叉时:以PR曲线下的面积作为衡量指标(这个指标通常难以计算);
-
使用 “平衡点”(P=R时的取值),值越大代表效果越优(这个点过于简化,更常用的是F1-score)。
7. ROC曲线
真阳性率(真实1里面正确预测为1的概率): T P R = T P T P + F N TPR = \frac{TP}{TP+FN} TPR=TP+FNTP
假阳性率(真实0里面错误预测为1的概率): F P R = F P F P + T N FPR = \frac{FP}{FP+TN} FPR=FP+TNFP
7.1 绘制方法
ROC曲线以假阳性率FPR为横坐标、以真阳性率TPR为纵坐标,以下面的数据为例说明一下绘制方法:
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 预测为正类的概率 score | 0.9 | 0.8 | 0.7 | 0.5 | 0.3 |
| 实际类别 class | 1 | 0 | 1 | 1 | 0 |
-
将每个样本的预测结果按照预测为正类的概率排序(上面已排序)
-
依次看每个样本
a) 对于样本1,将它的 score 0.9 作为阈值,即 score >= 0.9时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 0 预测0 2 2 b) 对于样本2,将它的 score 0.8 作为阈值,即 score >= 0.8时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 1 预测0 2 1 c) ……
d) ……
e) 对于样本5,将它的 score 0.3 作为阈值,即 score >= 0.3时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 3 2 预测0 0 0 -
根据上面的混淆矩阵,依次算出 5 对(FPR, TPR),以假阳性率FPR为横坐标、以真阳性率TPR为纵坐标,将这些点连接起来即得到 ROC 曲线。
7.2 模型性能衡量方法
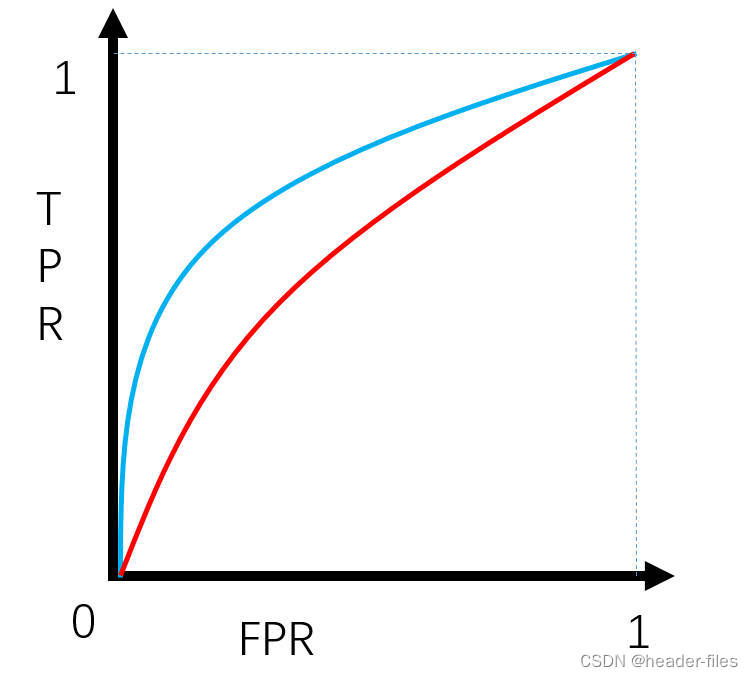
ROC曲线下的面积(AUC)作为衡量指标,面积越大,性能越好。
7.3 AUC的计算
在有M个正样本,N个负样本的数据集里。一共有MN对样本(一对样本即一个正样本与一个负样本)。统计这MN对样本里,正样本的预测概率大于负样本的预测概率的个数:
A U C = ∑ I ( P 正样本 , P 负样本 ) M ∗ N AUC = \frac{\sum I(P_\text{正样本},P_\text{负样本})}{M^*N} AUC=M∗N∑I(P正样本,P负样本)
其中:
I ( P 正样本 , P 负样本 ) = { 1 , P 正样本 > P 正样本 0.5 , P 正样本 = P 负样本 0 , P 正样本 < P 负样本 I(P_\text{正样本},P_\text{负样本})=\begin{cases}1,P_\text{正样本}>P_\text{正样本}\\0.5,P_\text{正样本}=P_\text{负样本}\\0,P_\text{正样本}<P_\text{负样本}\end{cases} I(P正样本,P负样本)=⎩ ⎨ ⎧1,P正样本>P正样本0.5,P正样本=P负样本0,P正样本<P负样本