1. 数据库服务器的优化步骤
当我们遇到数据库调优问题的时候,该如何思考呢?这里把思考的流程整理成下面这张图。
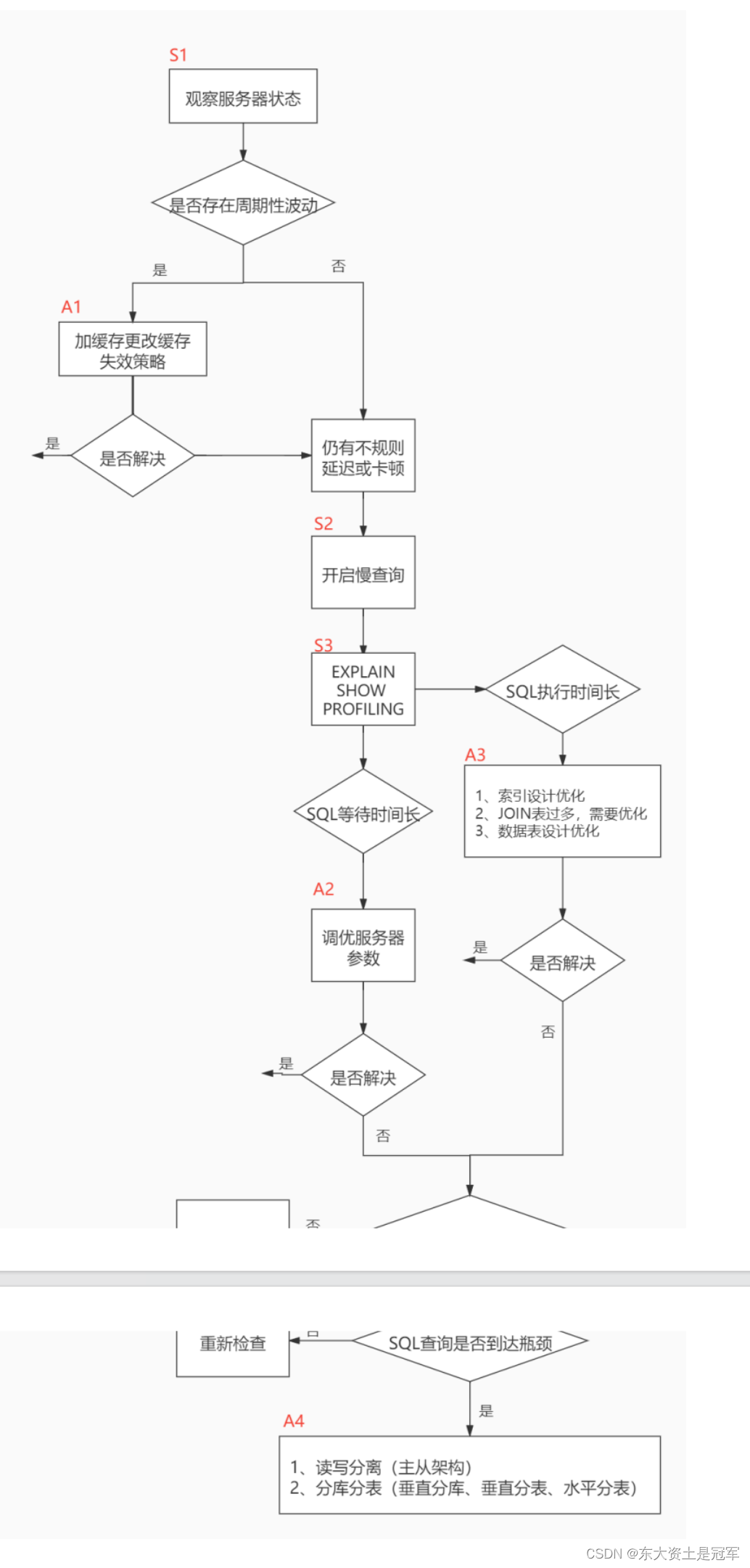
我们可以通过观察了解数据库整体的运行状态,通过性能分析工具可以让我们了解执行慢的SQL都有哪些,查看具体的SQL执行计划,甚至是SQL执行中的每一步的成本代价,这样才能定位问题所在,找到了问题,再采取相应的行动。
详细解释一下这张图:
首先在S1部分,我们需要观察服务器的状态是否存在周期性的波动。如果存在周期性波动,有可能是周期性节点的原因,比如双十一、促销活动等。这样的话,我们可以通过A1这一步骤解决,也就是加缓存,或者更改缓存失效策略。
如果缓存策略没有解决,或者不是周期性波动的原因,我们就需要进一步分析查询延迟和卡顿的原因。接下来进入S2这一步,我们需要开启慢查询。慢查询可以帮我们定位执行慢的sQL语句。我们可以通过设置long_query_time参数定义“慢”的阈值,如果SQL执行时间超过了long_query_time,则会认为是慢查询。当收集上来这些慢查询之后,我们就可以通过分析工具对慢查询日志进行分析。
在S3这一步骤中,我们就知道了执行慢的sQL,这样就可以针对性地用EXPLAIN查看对应SQL语句的执行计划,或者使用show profile查看SQL中每一个步骤的时间成本。这样我们就可以了解SQL查询慢是因为执行时间长,还是等待时间长。
如果是sQL等待时间长,我们进入A2步骤。在这一步骤中,我们可以调优服务器的参数,比如适当增加数据库缓冲池等。如果是SQL执行时间长,就进入A3 步骤,这一步中我们需要考虑是索引设计的问题?还是查询关联的数据表过多?还是因为数据表的字段设计问题导致了这一现象。然后在这些维度上进行对应的调整。
如果A和A3都不能解决问题,我们需要考虑数据库自身的sQL查询性能是否已经达到了瓶颈,如果确认没有达到性能瓶颈,就需要重新检查,重复以上的步骤。如果已经达到了性能瓶颈,进入A4阶段,需要考虑增加服务器,采用读写分离的架构,或者考虑对数据库进行分库分表,比如垂直分库、垂直分表和水平分表等。
以上就是数据库调优的流程思路。如果我们发现执行sQL时存在不规则延迟或卡顿的时候,就可以采用分析工具帮我们定位有问题的sQL,这三种分析工具你可以理解是SQL调优的三个步骤:慢查询、EXPLAIN和 SHOWPROFILING。
小结:
2. 查看系统性能参数
SHOW [GLOBAL|SESSION] STATUS LIKE '参数';全局|当前会话级别一些常用的性能参数如下:
• Connections:连接MySQL服务器的次数。
• Uptime:MySQL服务器的上线时间。
• Slow_queries:慢查询的次数。
慢查询次数参数可以结合慢查询日志找出慢查询语句, 然后针对慢查询语句进行表结构优化或者查询语句优化
• Innodb_rows_read:Select查询返回的行数
• Innodb_rows_inserted:执行INSERT操作插入的行数
• Innodb_rows_updated:执行UPDATE操作更新的行数
• Innodb_rows_deleted:执行DELETE操作删除的行数
• Com_select:查询操作的次数。
• Com_insert:插入操作的次数。对于批量插入的 INSERT 操作,只累加一次。
• Com_update:更新操作的次数。
• Com_delete:删除操作的次数。
3. 统计SQL的查询成本:last_query_cost
一条SQL查询语句在执行前需要确定查询执行计划,如果存在多种执行计划的话,MySQL会计算每个执行计划所需要的成本,从中选择成本最小的一个作为最终执行的执行计划。
如果我们想要查看某条SQL语句的查询成本,可以在执行完这条SQL语句之后,通过查看当前会话中的last_query_cost变量值来得到当前查询的成本。它通常也是我们评价一个查询的执行效率的一个常用指标。这个查询成本对应的是SOL语句所需要读取的页的数量
我们依然使用第8章的 student_info 表为例:
CREATE TABLE `student_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`student_id` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`course_id` INT NOT NULL ,
`class_id` INT(11) DEFAULT NULL,
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;如果我们想要查询 id=900001 的记录,然后看下查询成本,我们可以直接在聚簇索引上进行查找:
SELECT student_id, class_id, NAME, create_time FROM student_info
WHERE id = 900001;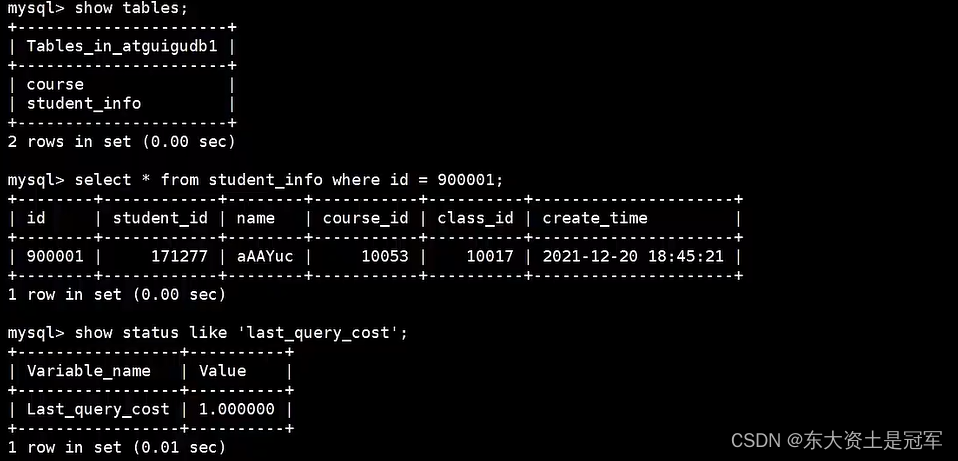 如果我们想要查询 id 在 900001 到 9000100 之间的学生记录呢?
如果我们想要查询 id 在 900001 到 9000100 之间的学生记录呢?
SELECT student_id, class_id, NAME, create_time FROM student_info
WHERE id BETWEEN 900001 AND 900100;运行结果(100 条记录,运行时间为 0.046s ):
mysql> SHOW STATUS LIKE 'last_query_cost';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| Last_query_cost | 21.134453 |
+-----------------+-----------+你能看到页的数量是刚才的 20 倍,但是查询的效率并没有明显的变化,实际上这两个 SQL 查询的时间 基本上一样,就是因为采用了顺序读取的方式将页面一次性加载到缓冲池中,然后再进行查找。虽然 页数量(last_query_cost)增加了不少 ,但是通过缓冲池的机制,并 没有增加多少查询时间 。
SQL"查询是一个动态的过程,从页加载的角度来看,我们可以得到以下两点结论:
1. 位置决定效率 。如果页就在数据库 缓冲池 中,那么效率是最高的,否则还需要从 内存 或者 磁盘 中进行读取,当然针对单个页的读取来说,如果页存在于内存中,会比在磁盘中读取效率高很多。
2. 批量决定效率 。如果我们从磁盘中对单一页进行随机读,那么效率是很低的(差不多10ms),而采用顺序读取的方式,批量对页进行读取,平均一页的读取效率就会提升很多,甚至要快于单个页面在内存中的随机读取。
所以说,遇到I/O并不用担心,方法找对了,效率还是很高的。我们首先要考虑数据存放的位置,如果是经常使用的数据就要尽量放到 缓冲池 中,其次我们可以充分利用磁盘的吞吐能力,一次性批量读取数据,这样单个页的读取效率也就得到了提升。
4. 定位执行慢的 SQL:慢查询日志
MySQL的慢查询日志,用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10秒以上(不含10秒)的语句,认为是超出了我们的最大忍耐时间值。
它的主要作用是,帮助我们发现那些执行时间特别长的SQL查询,并且有针对性地进行优化,从而提高系统的整体效率。当我们的数据库服务器发生阻塞、运行变慢的时候,检查一下慢查询日志,找到那些慢查询,对解决问题很有帮助。比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合explain进行全面分析。
默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。
慢查询日志支持将日志记录写入文件。
4.1 开启慢查询日志参数
1. 开启slow_query_log
mysql > set global slow_query_log='ON';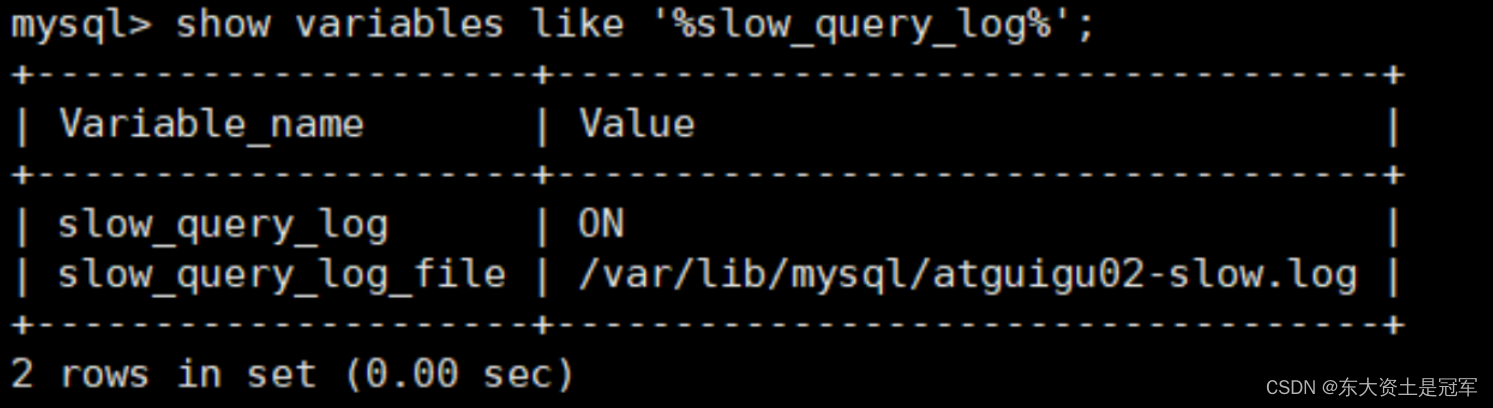
2. 修改long_query_time阈值
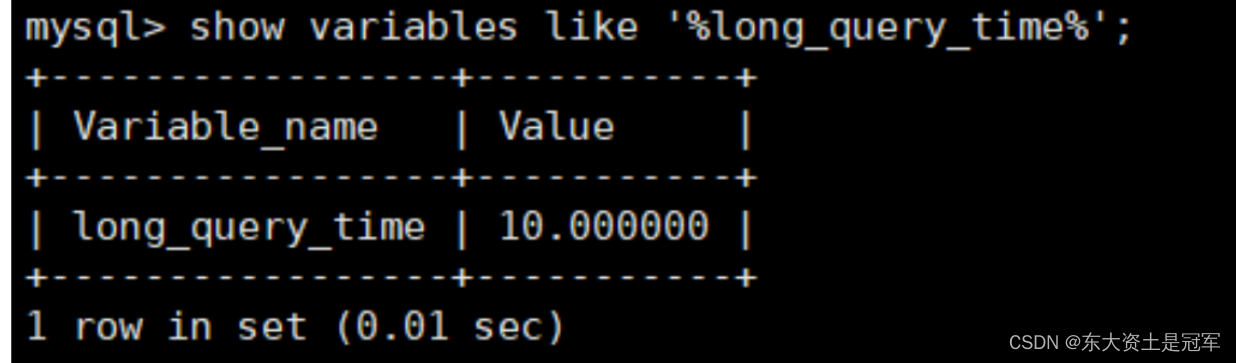
mysql > show variables like '%long_query_time%';
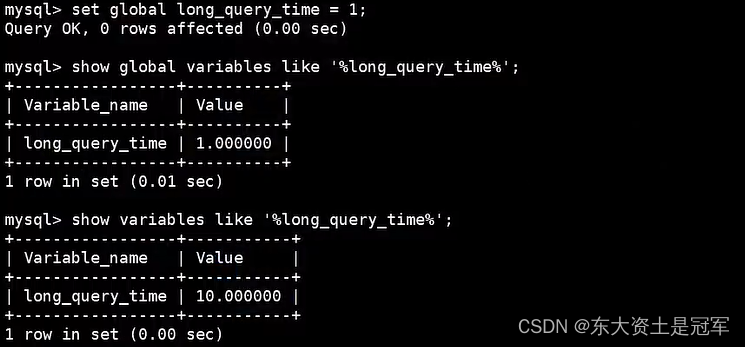
mysql > set global long_query_time = 1;
mysql> show global variables like '%long_query_time%';mysql> set long_query_time=1;
mysql> show variables like '%long_query_time%';4.2 查看慢查询数目
查询当前系统中有多少条慢查询记录
SHOW GLOBAL STATUS LIKE '%Slow_queries%';4.3 案例演示
步骤1. 建表
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;步骤2:设置参数 log_bin_trust_function_creators
This function has none of DETERMINISTIC......则命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。步骤3:创建函数
随机产生字符串:(同上一章)
DELIMITER //
CREATE FUNCTION rand_string(n INT)RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGINDECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';DECLARE return_str VARCHAR(255) DEFAULT '';DECLARE i INT DEFAULT 0;WHILE i < n DOSET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));SET i = i + 1;END WHILE;RETURN return_str;
END //
DELIMITER ;#测试
SELECT rand_string(10);产生随机数值:(同上一章)
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGINDECLARE i INT DEFAULT 0;SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;RETURN i;
END //
DELIMITER ;
#测试:
SELECT rand_num(10,100);步骤4:创建存储过程
DELIMITER //
CREATE PROCEDURE insert_stu1( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, NAME ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(10,100),rand_num(10,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;#调用刚刚写好的函数, 4000000条记录,从100001号开始
CALL insert_stu1(100001,4000000);4.4 测试及分析
1. 测试

2. 分析
show status like 'slow_queries';
除了上述变量,控制慢查询日志的还有一个系统变量: min_examined_row_limit。这个变量的意思是,查询扫描过的最少记录数。这个变量和查询执行时间,共同组成了判别一个查询是否是慢查询的条件。如果查询扫描过的记录数大于等于这个变量的值,并且查询执行时间超过long_query_time的值,那么,这个查询就被记录到慢查询日志中;反之,则不被记录到慢查询日志中。
mysql> show variables like 'min%' ;
十-—------ --- ---- ------------+---------+l Variable_name | Value l
l min_examined_row_limit | 0 l十--------------------------------+-------+
1 row in set, 1 warning (0.00 sec)
这个值默认是0。与long_query_time=10合在一起,表示只要查询的执行时间超过10秒钟,哪怕一个记录也没有扫描过,都要被记录到慢查询日志中。你也可以根据需要,通过修改“my.inil文件,来修改查询时长,或者通过SET指令,用SQL语句修改“min_examined_row_limit”的值。
4.5 慢查询日志分析工具:mysqldumpslow
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具 mysqldumpslow 。
mysqldumpslow --help注意这个是一个脚本文件, 因此不要在MySQL中执行, 而是在根目录下执行

c: 访问次数l: 锁定时间r: 返回记录t: 查询时间al: 平均锁定时间ar: 平均返回记录数at: 平均查询时间 (默认方式)ac: 平均查询次数

 工作常用参考:
工作常用参考:
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more4.6 关闭慢查询日志
MySQL服务器停止慢查询日志功能:

此时查看变量发现还没有变回10秒

(2)重启MySQL服务,使用SHOW语句查询慢查询日志功能信息,再次执行查询慢日志功能。成功变回10秒
4.7 删除慢查询日志
手动删除慢查询日志文件即可
5. 查看 SQL 执行成本:SHOW PROFILE
Show profile 是MySQL提供的可以用来分析当前会话中SQL都做了什么, 执行的资源情况的工具, 可用于sql调优的测量. 默认情况下处于关闭状态, 并保存最近15次的运行结果.
我们可以再会话级别开启这功能
mysql > show variables like 'profiling';
通过设置 profiling='ON’ 来开启 show profile:

mysql > show profiles;我们先执行两个查询语句
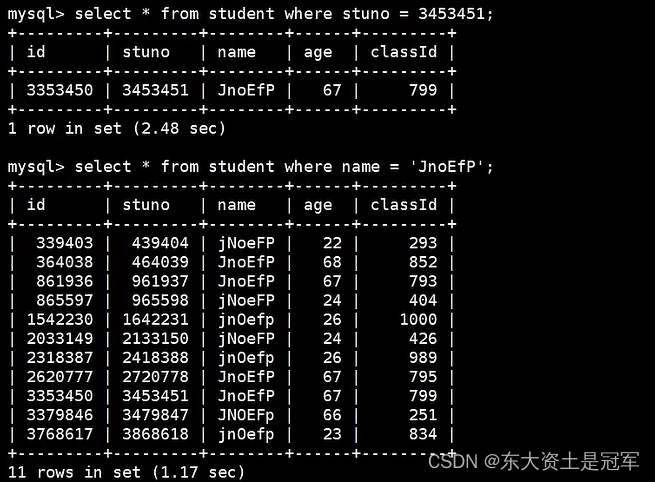
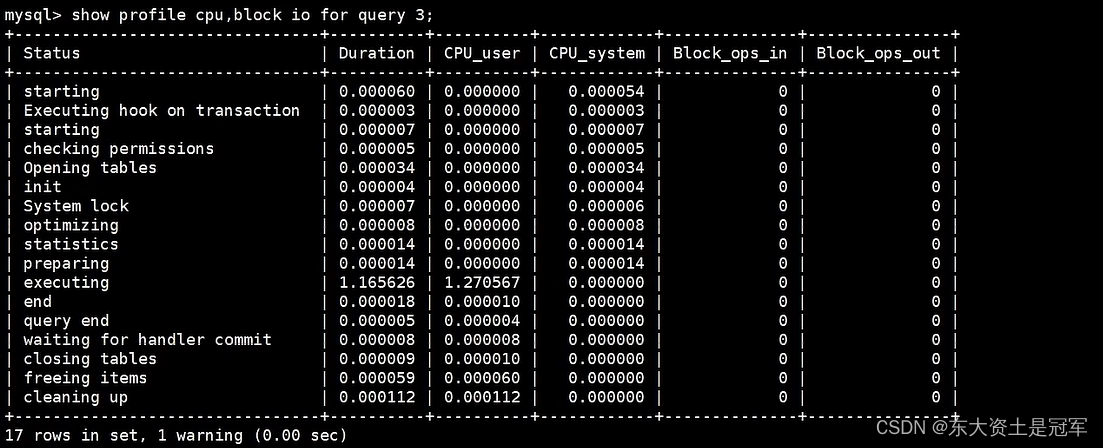
之后你能看到当前会话一共有 3 个查询。如果我们想要查看最近一次查询的开销,可以使用:
mysql > show profile;
想查看第三条记录开销