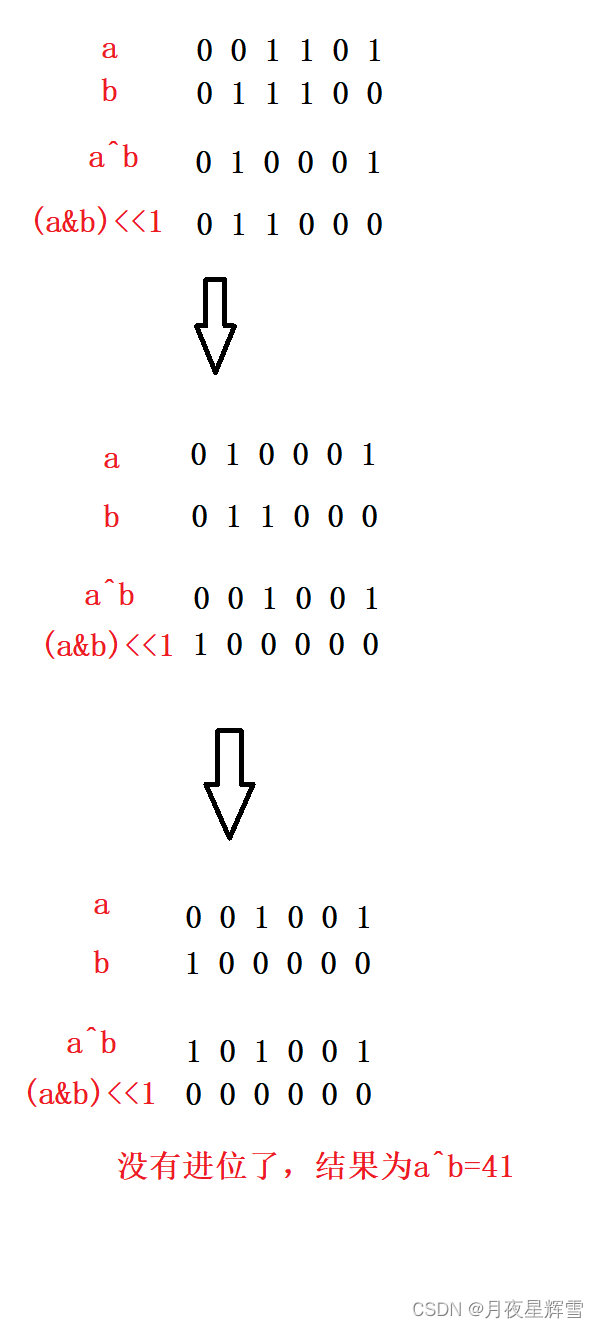
导读
蜀海供应链是集销售、研发、采购、生产、品保、仓储、运输、信息、金融为一体的餐饮供应链服务企业。2021年初,蜀海信息技术中心大数据技术研发团队开始测试用DolphinScheduler作为数据中台和各业务产品项目的任务调度系统工具。本文主要分享了蜀海供应链在海豚早期旧版本实践过程中的探索创新和在跨大版本升级部署过程中的经验,希望对大家有所启发和帮助。
作者简介

杜全,蜀海供应链大数据工程师,参与蜀海大数据平台和数据中台建设。
业务背景介绍
我们公司的主要业务如下图所示:
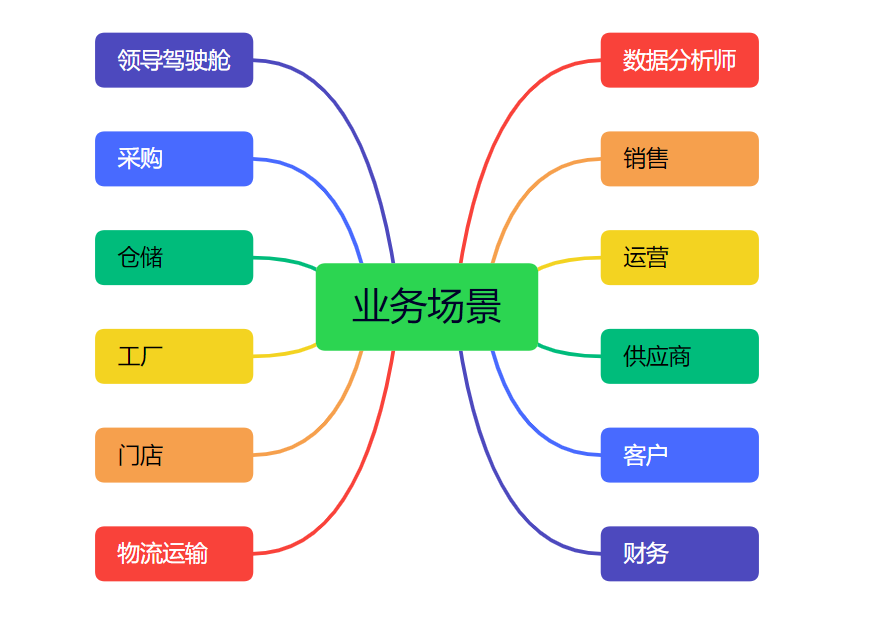
- 领导驾驶舱:提供给高层领导查看的数据准实时分析,T+1经营分析、产品毛利类、市场价格等报表
- 财务:各类日报、月报、年度报表;对账、毛利报表、指标表等
- 客户销售:客户采销类实时报表、日报、月报各个维度的数据分析及查询销售明细数据
- 供应商类:采购分析、询价报表、供应商等级、供应商工作台、供应商对账分析,采购策略优化等
- 仓储:库存周转、库位、实时库存等各种维度数据指标及报表需求
- 物流运输类:准点率、温控、运输成本,调度等分析
- 数据分析师:快速响应各种数据分析需求,及高层领导各种临时数据需求,数据挖掘及各种实时交互式分析
- 各业务运营/策略/负责人:主要查看各自业务运营的整体情况,查询数据中台的各该业务各种维度实时聚合数据
- 以及一些其他业务的数据报表及分析需求。
集成升级经验
在数据中台建设过程中,好的大数据调度组件往往能达到事半功倍的作用,我们团队也深知这一点,因此选择了海豚调度作为蜀海供应链数据中台的调度系统,并经过从v1.3.6的耦合集成部署改造到v3.1.8解耦集成部署的改造的阶段,在这个过程中也遇到了各种各样的问题并及时提供了解决方案,现就这些做一下分享,希望可以帮助到各位小伙伴。
海豚调度旧版本集成
之前团队集成的旧版本为v1.3.6,已经在生产环境稳定运行两年多了,这里主要简单介绍下当时集成到数据中台的细节及随着业务量剧增带来的痛点。
(1)API服务、UI改造对接集成到中台
- 前端UI改造
基于dolphinscheduler-ui项目二次开发(改动量大)适配中台样式,集成各海豚调度菜单(首页、项目管理、资源中心、数据源中心、监控中心、安全中心)到中台,统一走中台路由网关。

- 后端API接口服务改造
基于dolphinscheduler-api项目二次开发,融合中台用户体系改造。核心改造点如下:
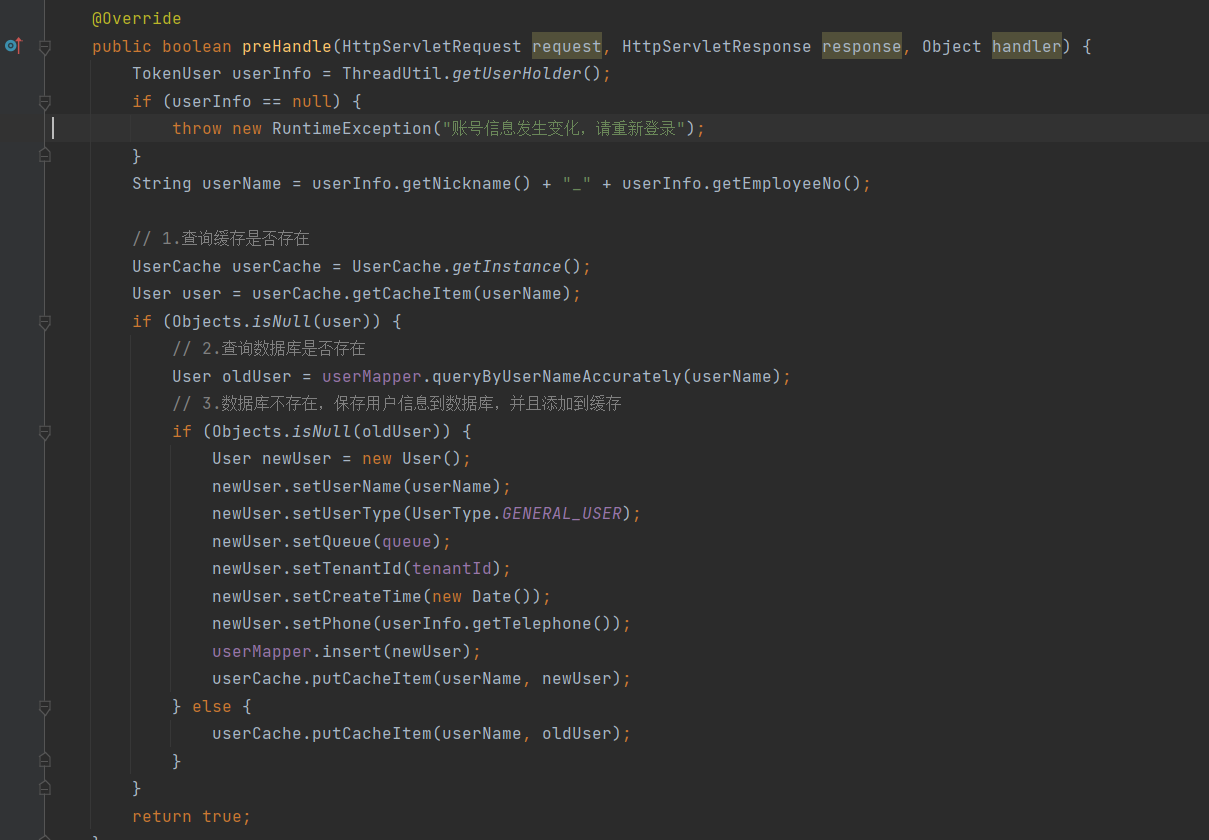
① 改造点1:LoginHandlerInterceptor拦截器类preHandle()方法重构
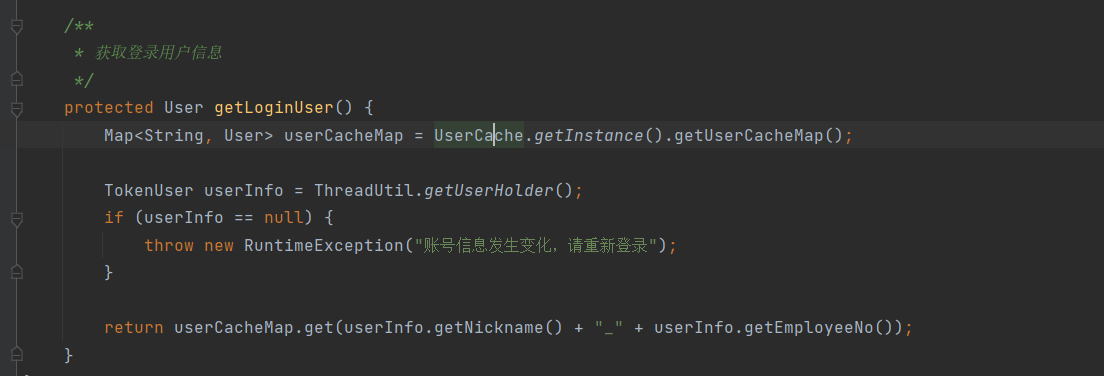
② 改造点2:每个Controller控制层类中接口方法增加获取登录用户方法getLoginUser()方法
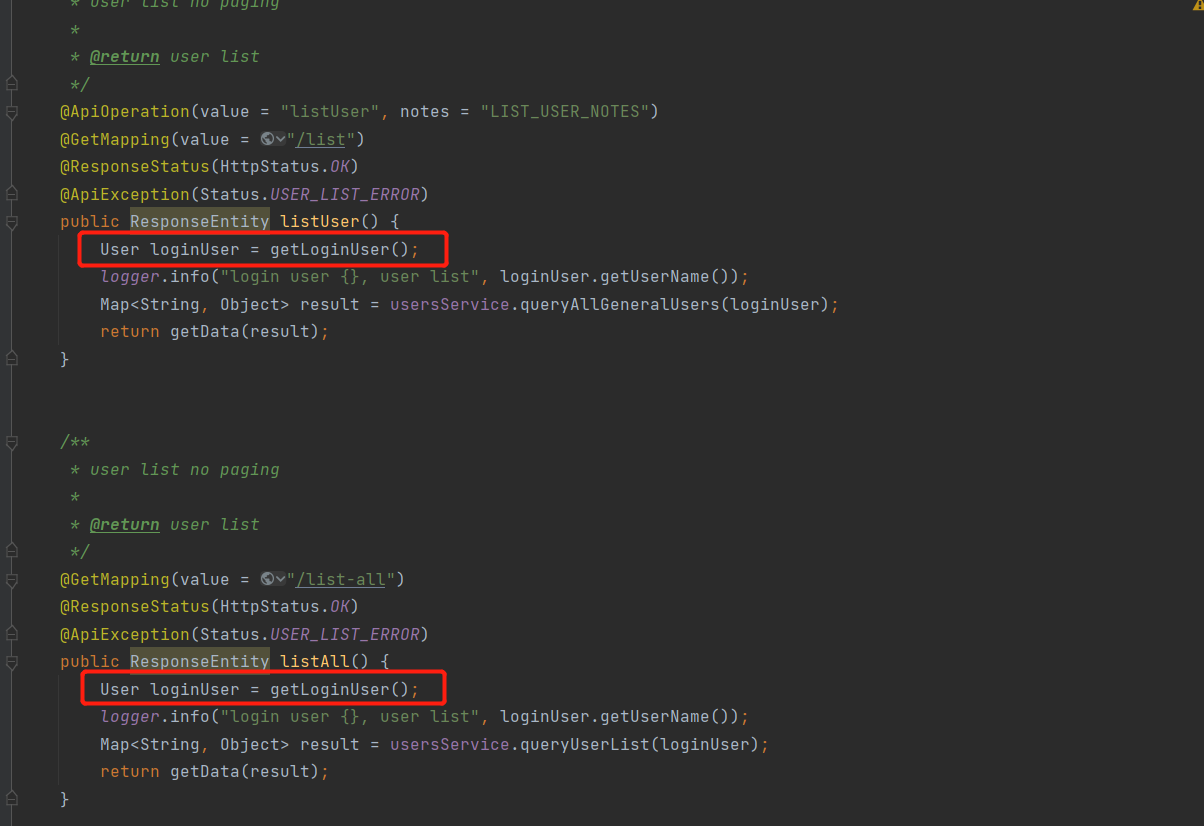
③ 改造点3:返回数据及分页数据方法改造 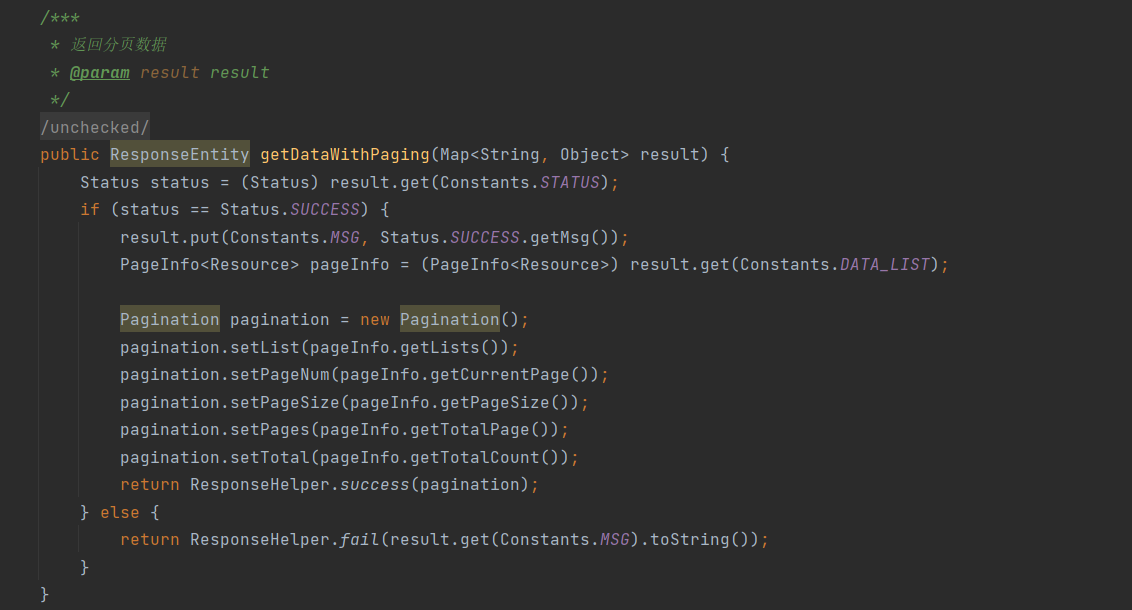
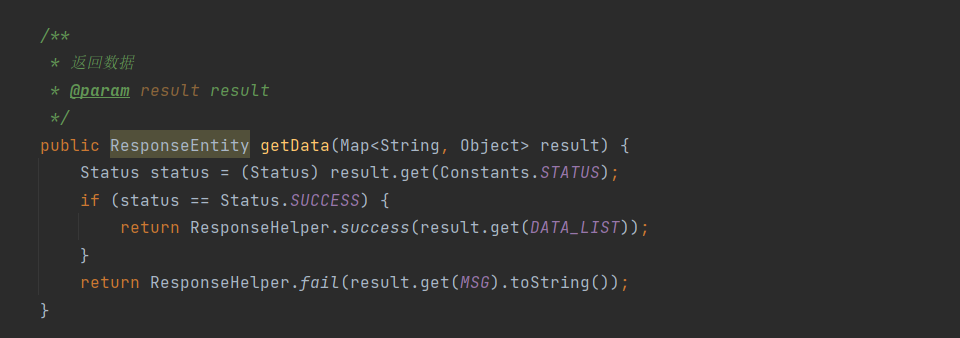
(2)告警改造增加钉钉告警
v1.3.6版本告警组组类型仅支持:邮件、短信两种。公司平时是通过钉钉接收告警信息,因此需要集成钉钉告警类型。核心改造点如下:
① 步骤1:定义DingAlertPlugin钉钉告警插件类实现AlertPlugin接口,重写getId()、getName()及process()方法 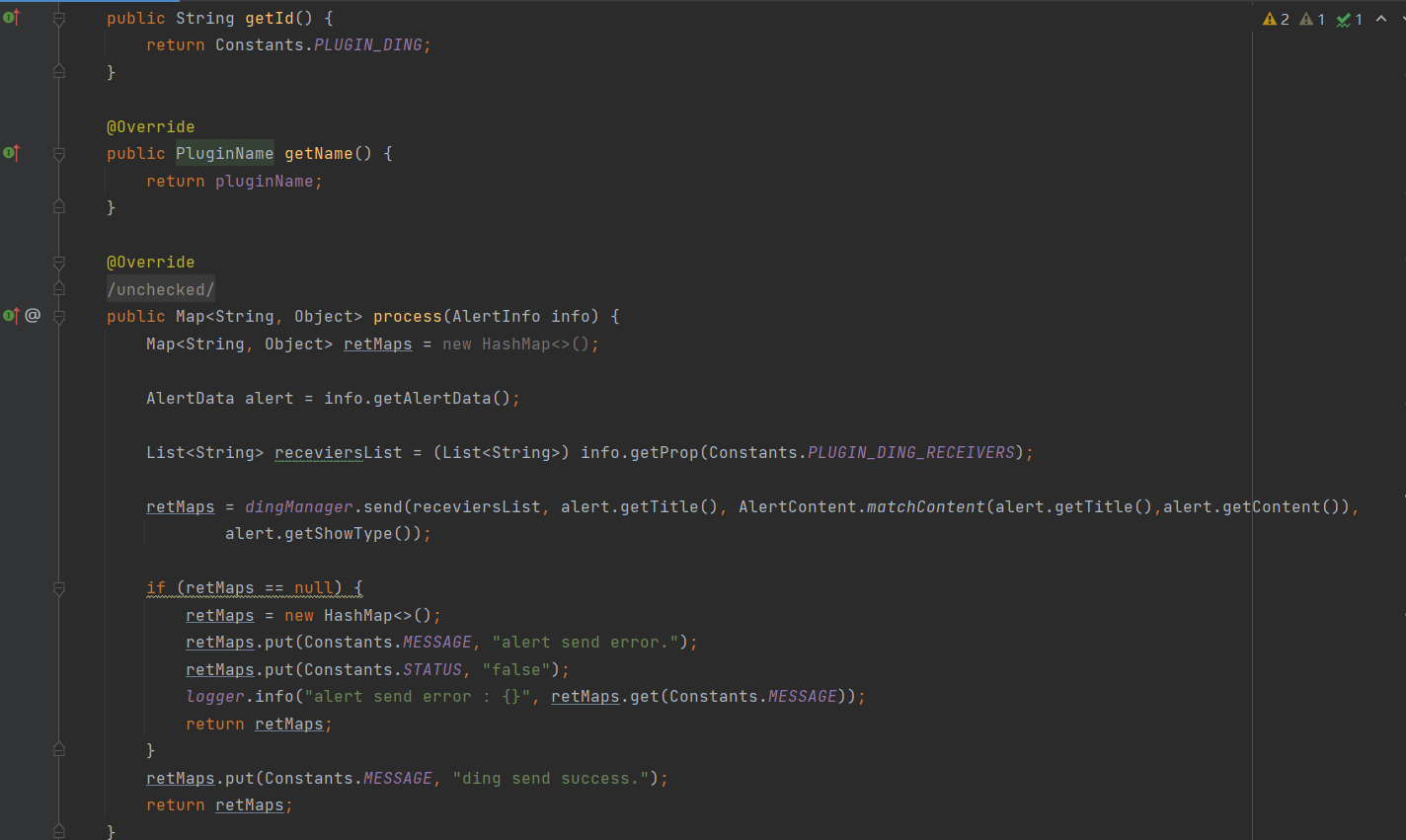
② 步骤2:定义DingManager钉钉发送管理类 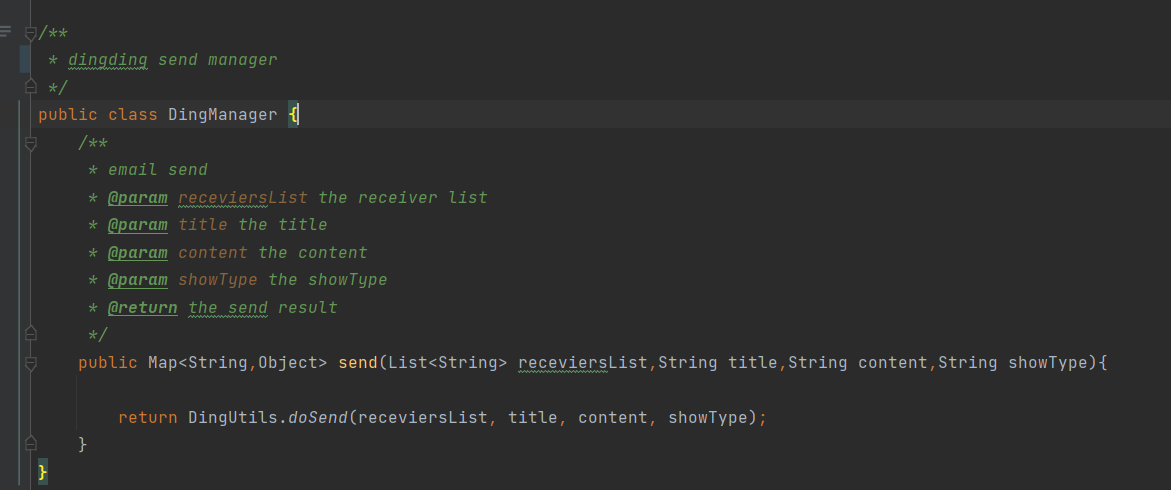 ③ 步骤3:编写DingUtils钉钉发送消息工具类
③ 步骤3:编写DingUtils钉钉发送消息工具类 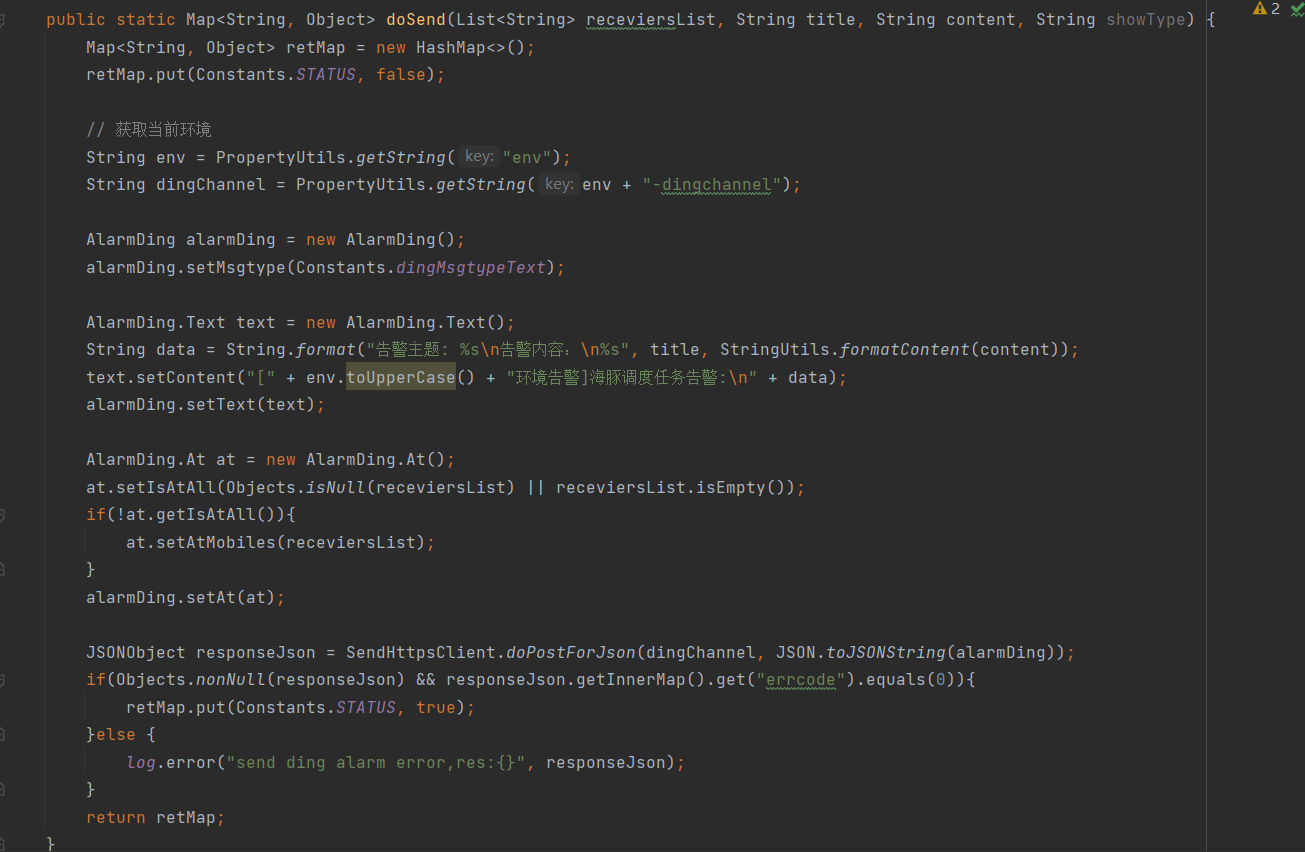 ④ 步骤4:向AlertServer注册钉钉告警插件
④ 步骤4:向AlertServer注册钉钉告警插件 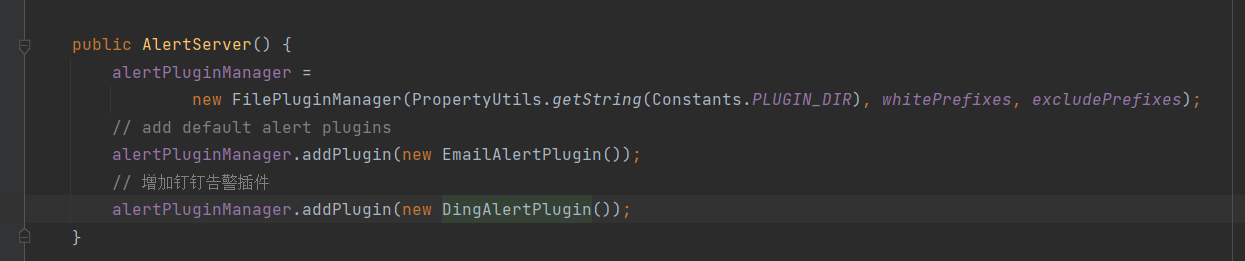 ⑤ 步骤5:打包部署并修改
⑤ 步骤5:打包部署并修改dolphinscheduler-daemon.sh 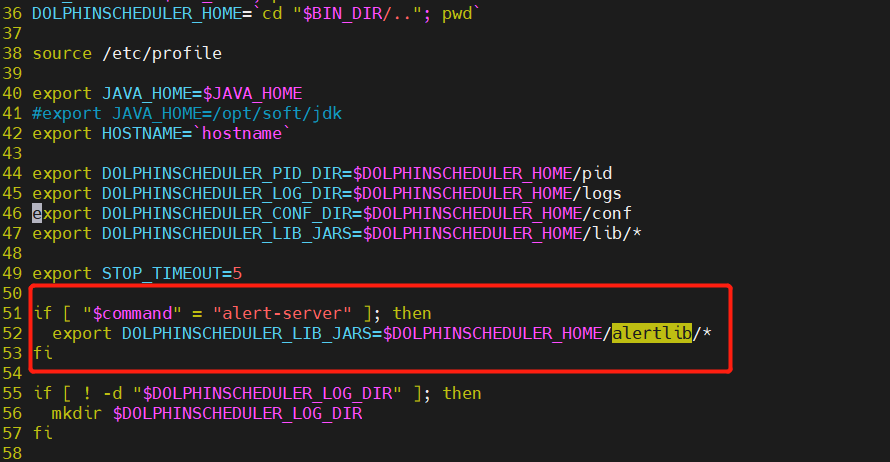
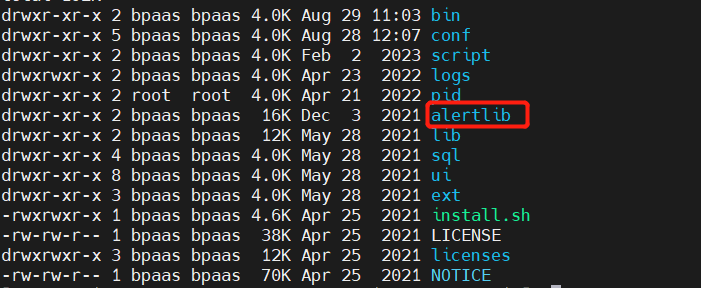
打包部署根据具体修改逻辑,这里修改了dolphinscheduler-alert-1.3.6.jar和dolphinscheduler-dao-1.3.6.jar因此打包这两个包即可。另外,安装路径下增加alertlib文件夹并在dolphinscheduler-daemon.sh中增加alter-server加载逻辑。
(3)集成成果展示
数据中台集成菜单与v1.3.6海豚调度保持一致,主要包括:首页、项目管理、资源中心、数据源中心、监控中心、安全中心,这些菜单都是集成到了我们的数据中台中,前端走平台统一的路由网关。
(4)v1.3.6旧版本业务痛点问题
工作流定义表
process_definition_json字段大JSON 任务和工作流耦合度高,解析json,非常耗费性能,且任务没法重用;否则会导致数据大量冗余,性能差,资源消耗严重升级困难,1.3.6集成到数据中台系统中,相当于二次开发了API服务,集成了中台用户体系走统一路由网关,前端UI组件每一次升级,海豚调度就会出现各种前端样式问题(SUB_PROCESS 子工作流 进入不到该子节点下)、菜单显示不全、日志全屏看不全、项目主页上下滑动不了等等一系列UI交互问题
任务间自定义参数上下不能依赖传参
工作流实例任务交叉没有任务执行策略 ,默认是并行处理的,不保证单例模式,比如调度频率高时 前一个工作流实例还未执行完,后一个又开始,造成数据错乱、不准确
自带数据质量从3.0.0开始
支持多种告警插件类型和告警组及实例管理(不限于钉钉),从3.0.0开始
前端UI大调整、优化
鉴于第一版集成的v1.3.6以上的业务痛点,升级并重构集成方式变得尤为重要。
海豚调度新版本升级
v1.3.6版本在数据分析师进行业务分析流转过程中面临的痛点,结合海豚调度新版本更优的特性,升级到更新版本迫在眉睫,以下是对我们在将海豚调度集成到数据中台以及升级过程的细节做一下介绍,希望对遇到跨大版本升级的你有所帮助。
(1)新版本(v3.1.1)集成到中台
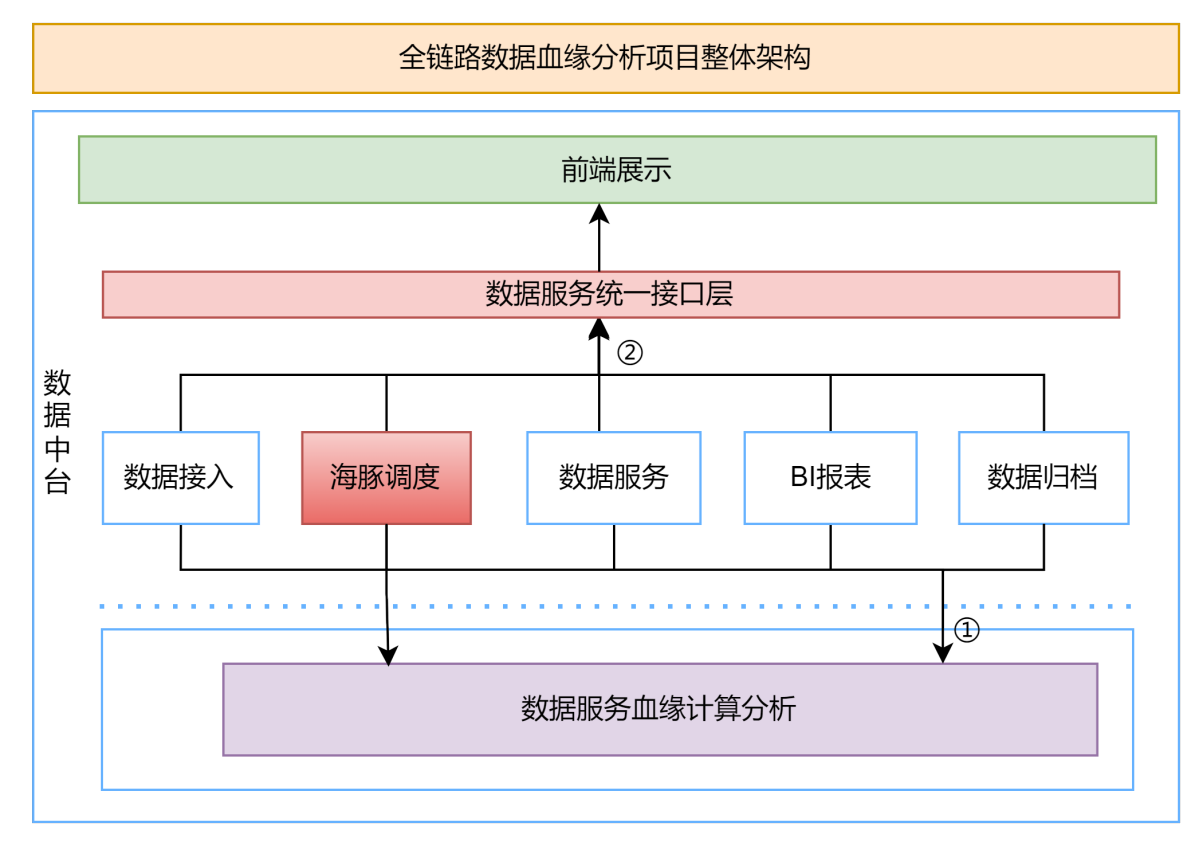
- 海豚调度集成中台项目整体架构
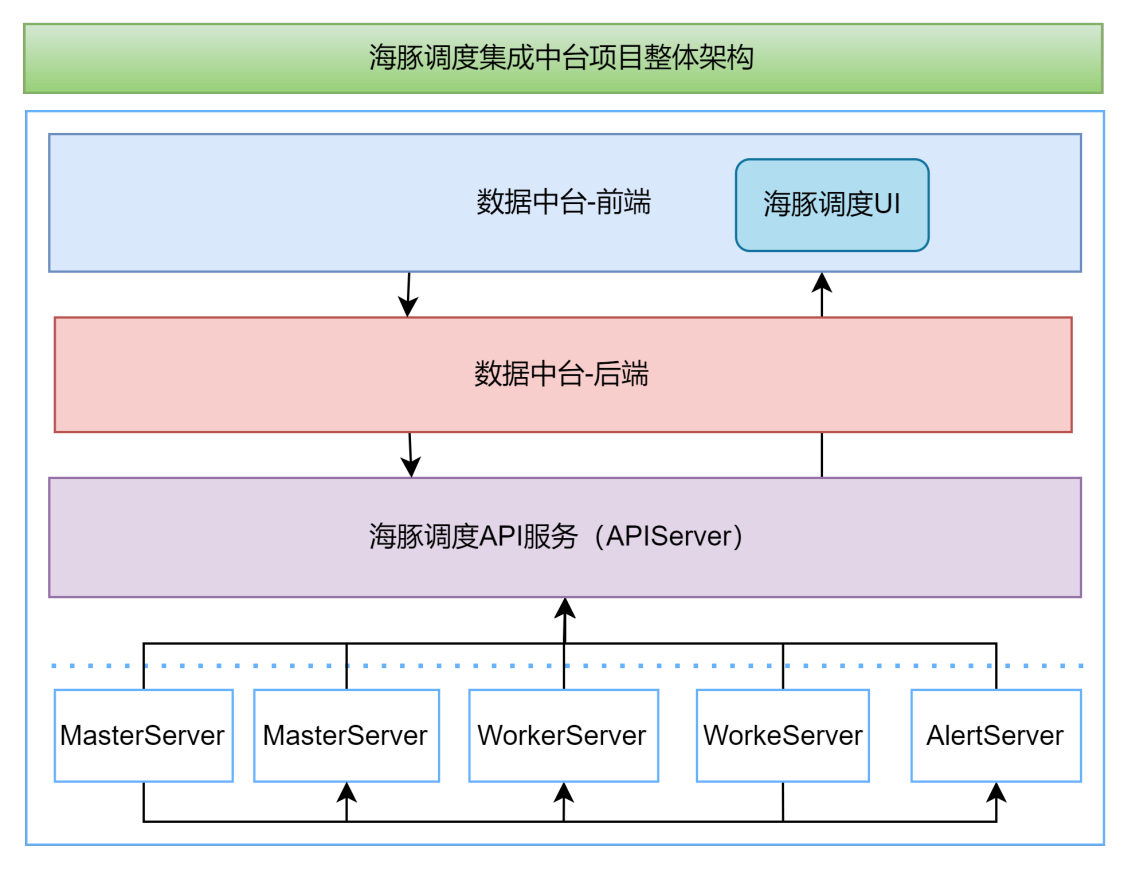
主要分为:数据中台-前端、数据中台-后端、海豚调度API服务 及集群。
- 海豚调度集成中台调用流程
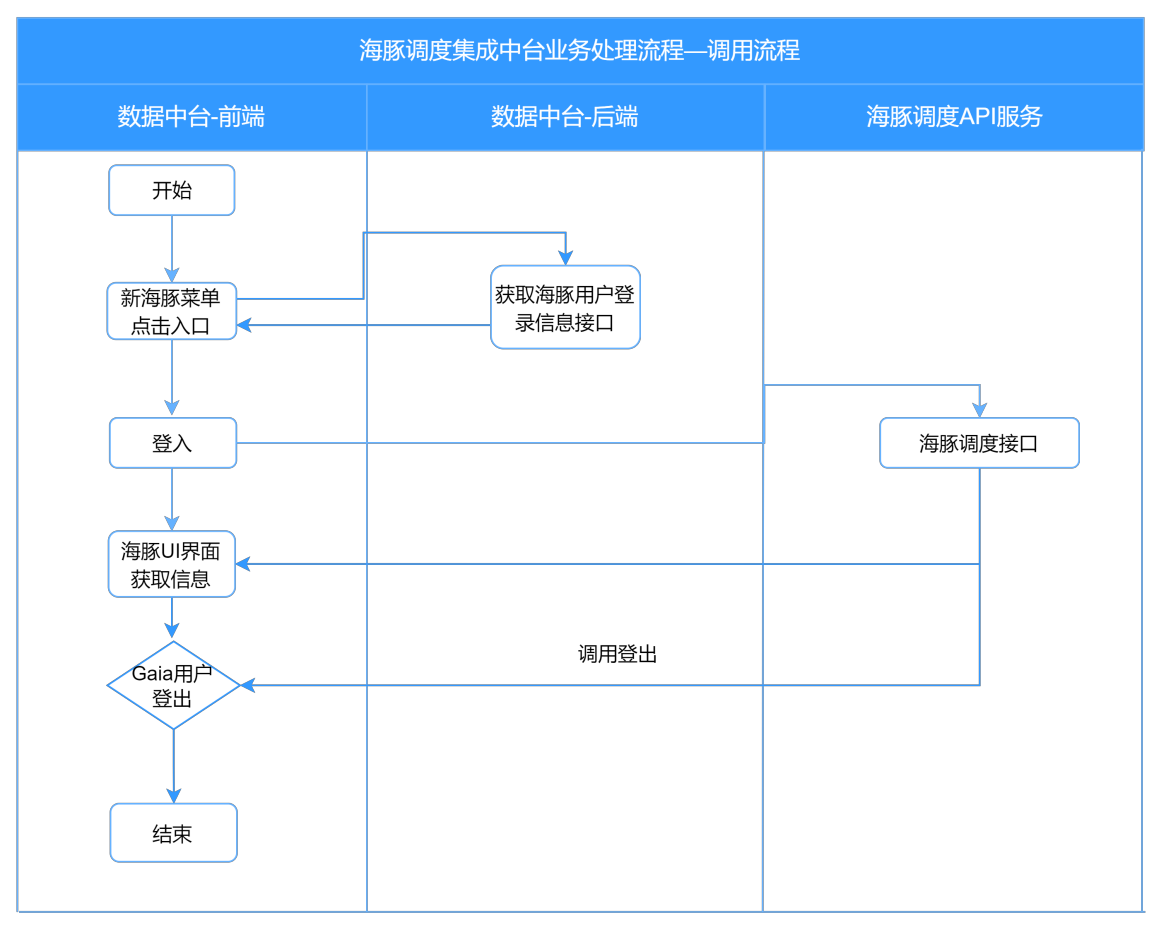
主要流程:数据中台-前端请求打开海豚调度菜单->调用数据中台后端获取海豚调度用户登录信息接口->返回用户名密码->登入海豚调度系统->数据中台-前端请求退出平台账号->海豚调度接口登出接口->退出系统
- 数据模型及设计细节
海豚调度集成数据中台项目中间用户模型设计
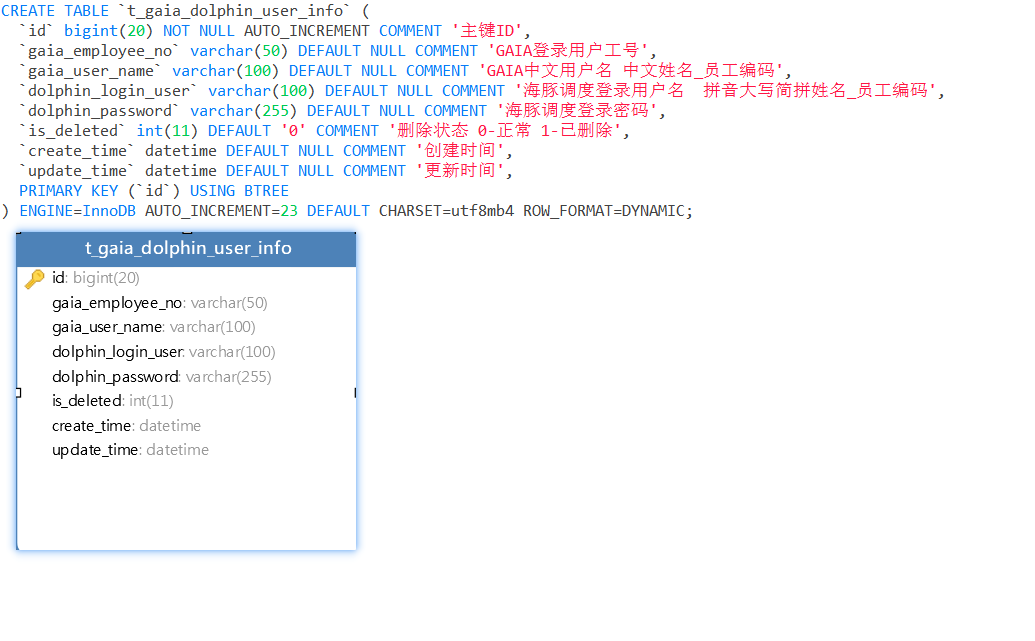
模型设计的目的主要建立数据中台和海豚调度用户的关系,便于在数据中台用户登录后,点击海豚调度菜单时获取到对应的海豚调度用户登录信息成功登录。
(2)v1.3.6滚动迁移并升级到v3.1.8+
这里我以我们生产环境升级版本v1.3.6为起点,经过v2.0.0->2.0.9>3.0.0>3.1.0->3.18这些版本迭代升级<当然可以跨度步伐迈的再小一点,出现的问题可能就更少了,因为毕竟官网提供的update_schema.sh脚本是适用于小版本的,对于大版本兼容性支持不完善。
在升级过程中主要在v2.0.0需要修改部分源码兼容升级,其他版本基本都是需要修改schema对应的ddl脚本兼容升级,主要升级流程总结如下:
- 下载目标升级安装包(需要滚动升级的源码包和二进制包下载)
下载新稳定版本(待升级版本)的所有二进制安装包,并将二进制包放到与当前 DolphinScheduler 旧服务不一样的路径中,升级步骤需在新版本的目录进行。

注意:如果存在跨大版本升级需求,尤其是跨v2.0.0版本,需要下载2.0.0源码包,修改详见(3)
- Dolphin Scheduler元数据备份(获取生产旧版本SQL脚本)
从生产环境转储或用dump命令备份数据库脚本文件,一些非必要的日志表数据可以不要,但需要备份表结构。
- 修改升级版本的配置文件
这里按版本分为≤v2.0.9和≥v3.0.0,在v2.0.9版本之前,目录结构大致如下:
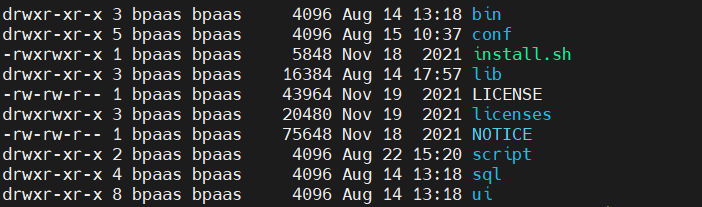
在v3.0.0版本之后,目录结构大致如下:
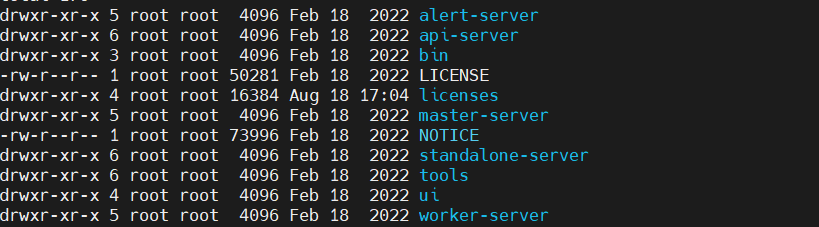
一般修改遵循先配置升级schema,再配置基础部署文件的原则。
对于≤v2.0.9而言,配置升级schema需要修改conf/datasource.properties文件并将数据库驱动包放在lib目录下即可;而配置基础部署文件需要修改conf/common.properties、conf/config/install_config.conf、conf/env/dolphinscheduler_env.sh。
对于≥v3.0.0而言,配置升级schema则需要修改bin/env/dolphinscheduler_env.sh并将数据库驱动包放在tools/libs目录下即可;而配置基础部署文件则需要修改bin/env/install_env.sh、alert/master/worker/api-server/conf下的common.properties、application.yaml。
- 更新数据库、执行数据库升级脚本
这里说明一下,如果刚好是v2.0.0之前的旧版本,那就会遇到一个棘手问题:工作流定义表大JSON未拆分。首先需要通过官方提供的update-schema.sh拆分大JSON并且在执行过程中会出现很多问题,除非你们公司的旧版本的工作流定义ID未经过删减一直保持自增并且不间断,因为官方对于工作流定义中tasks的拆分逻辑是自增的,找不到就会报错,因此需要修改v2.0.0源码兼容。
- 安装部署、启用最新版本的服务
这里会遇到一个问题,当执行bin/install.sh后,应该在3.1.x版本后都会遇到, 在install.sh的第四步<即:4.delete zk node>中会出现如下报错:
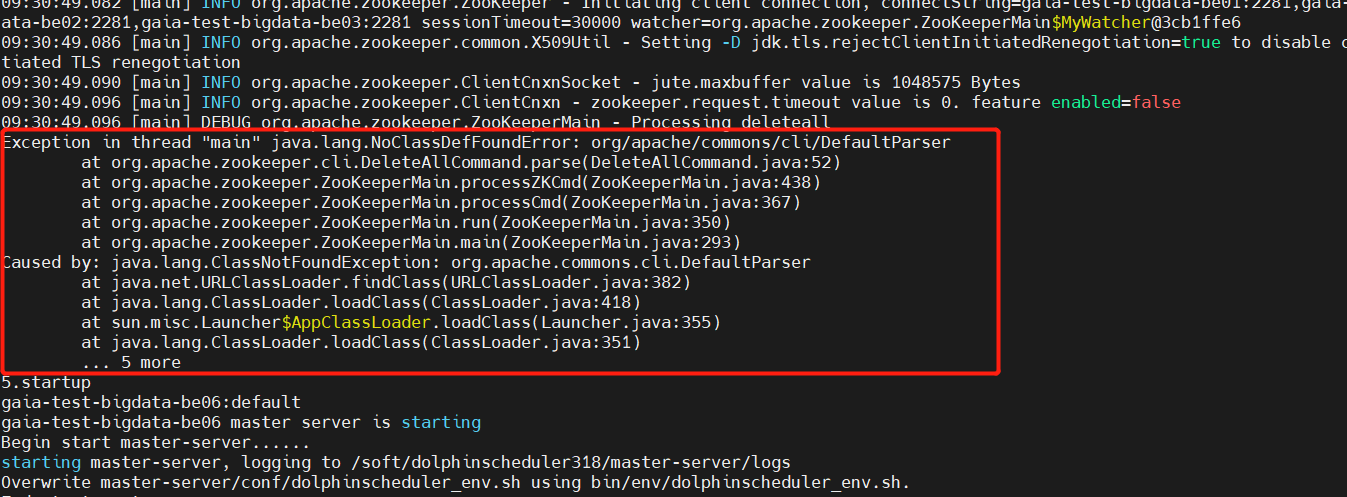
大概分析了下,经过排查定位确定是缺jar包,我用的Zookeeper版本为v3.8.0。而worker-server/master-server/api-server的libs下commons-cli-1.2.jar源包中也确实没有DefaultParser类,是因为1.2的版本过低。
解决办法:下载≥1.4的common-cli包分别放到各服务对应的libs下,再次安装部署就没问题了,https://mvnrepository.com/artifact/commons-cli/commons-cli/1.4,效果如下:
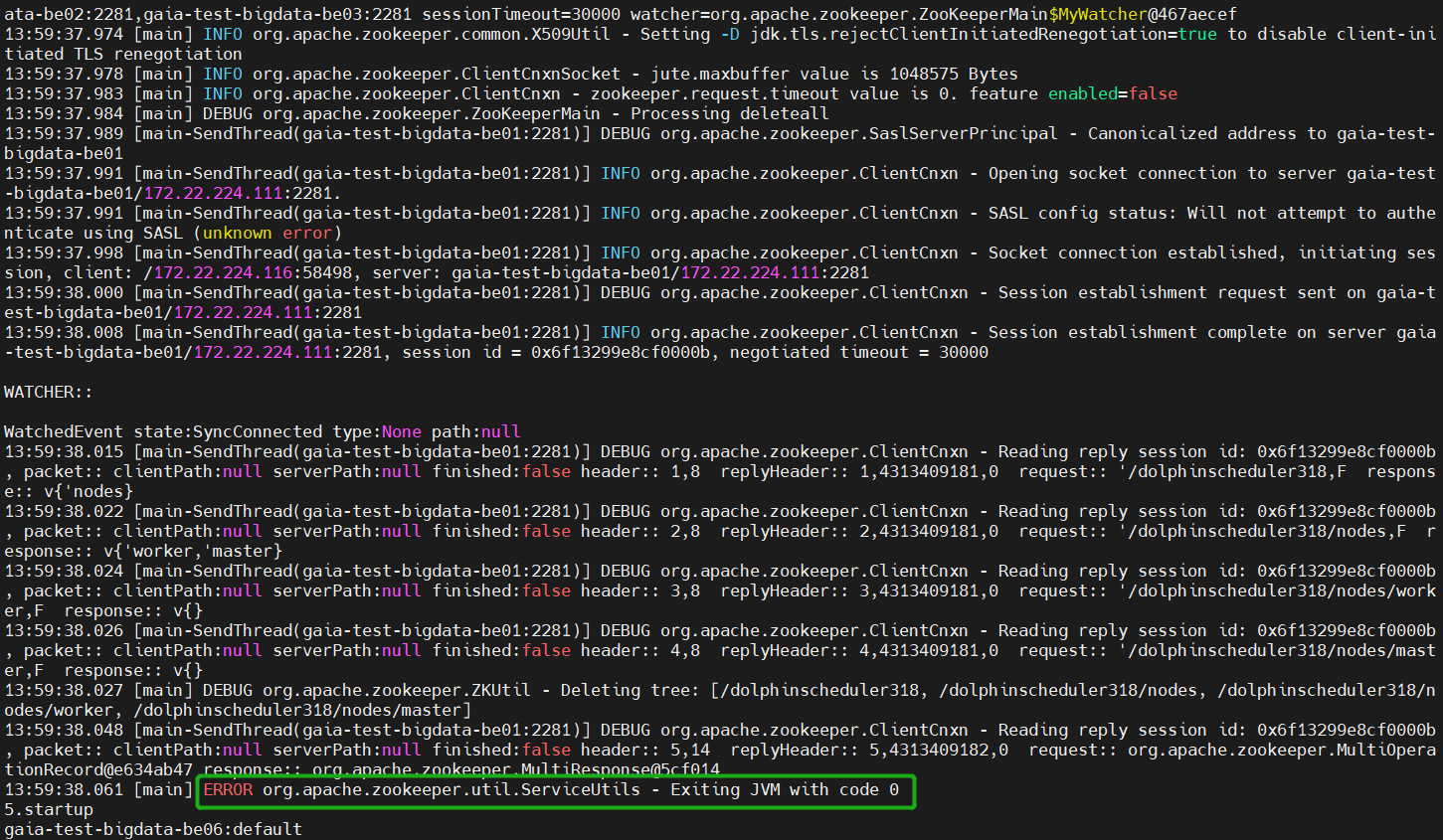
这里会出现一个显眼的ERROR信息:ERROR org.apache.zookeeper.util.ServiceUtils - Exiting JVM with code 0,虽然看着不舒服,但请忽略这个是Zookeeper正常执行完命令的退出码,0表示程序正常终止,如果仍存在疑惑可以打开一个Zookeeper客户端(bin/zkCli.sh)Ctrl+D试一下退出。

- 初始化数据、验证新版本功能
初始化数据主要包括:租户、用户、告警组及实例、资源中心、数据源中心、环境管理等数据信息维护,这些需要根据公司具体业务场景自行维护,功能验证这里不再赘述。
(3)滚动升级过程中遇到的问题总结
- OutOfMemoryError:Java heap space (v1.3.6->v2.0.0)
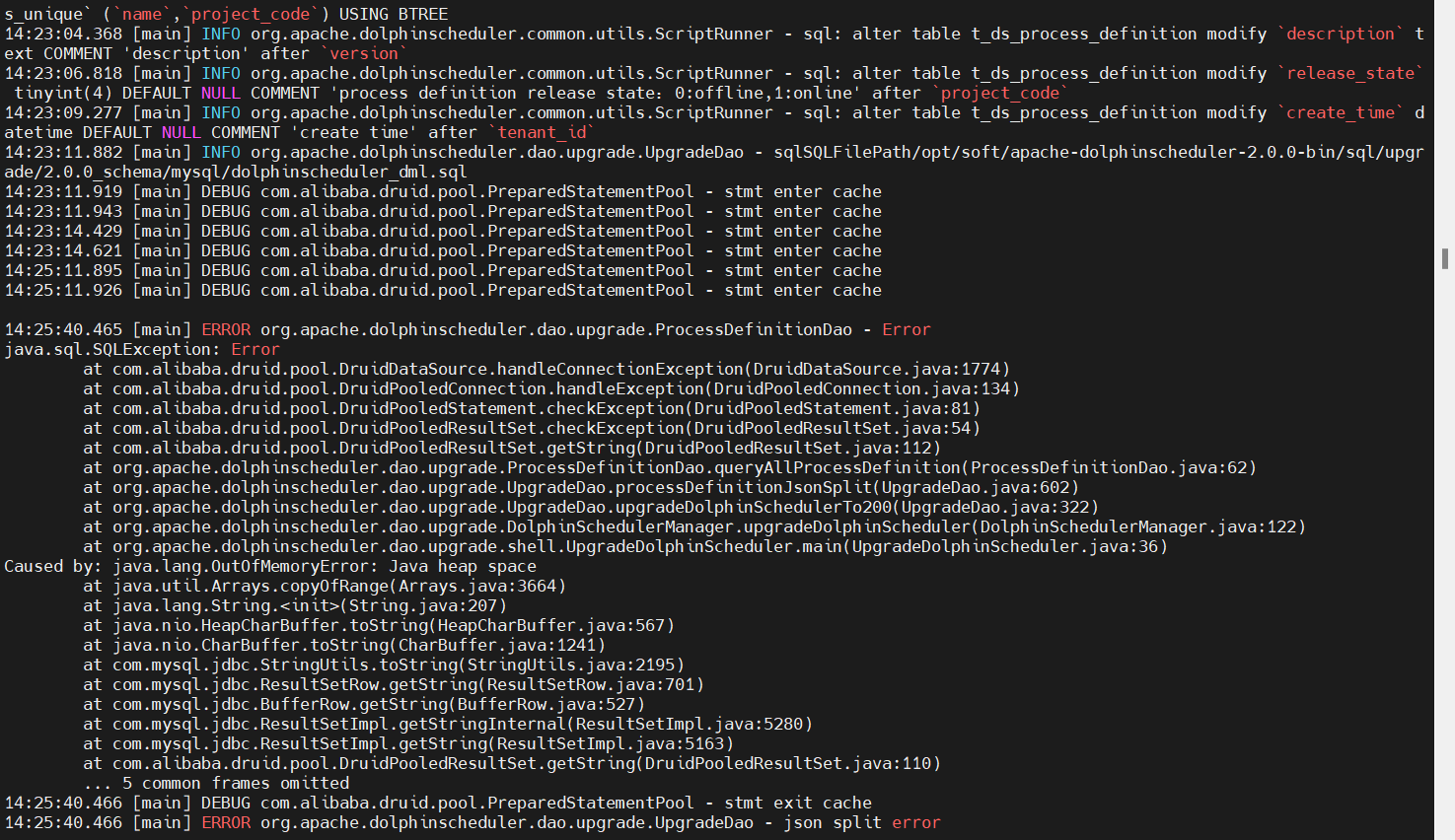
出现这种问题的原因是:在升级到v2.0.0过程中需要拆分工作流定义表process_definition_json字段,而我们的工作流定义数为6463个(随着业务量还在增长中),拆分需要大量耗费内存,Java堆空间不足,导致无法分配更多的内存,这个需要根据服务器配置适当调大-Xmx参数,这里我调整到了-Xmx4g,然后升级就没问题了。

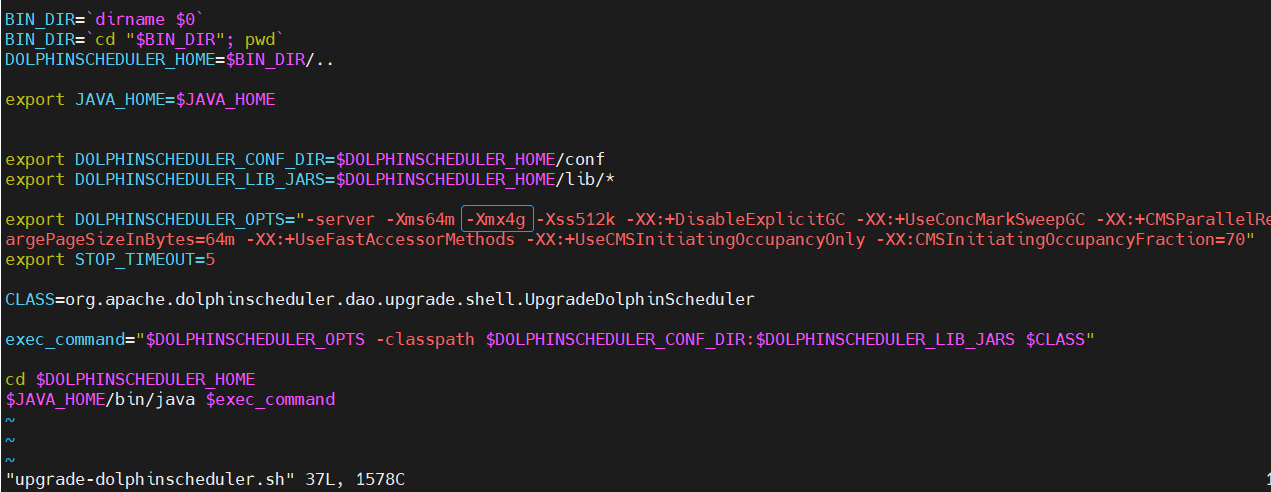
- json split error && NullPointException:null (v1.3.6->v2.0.0)
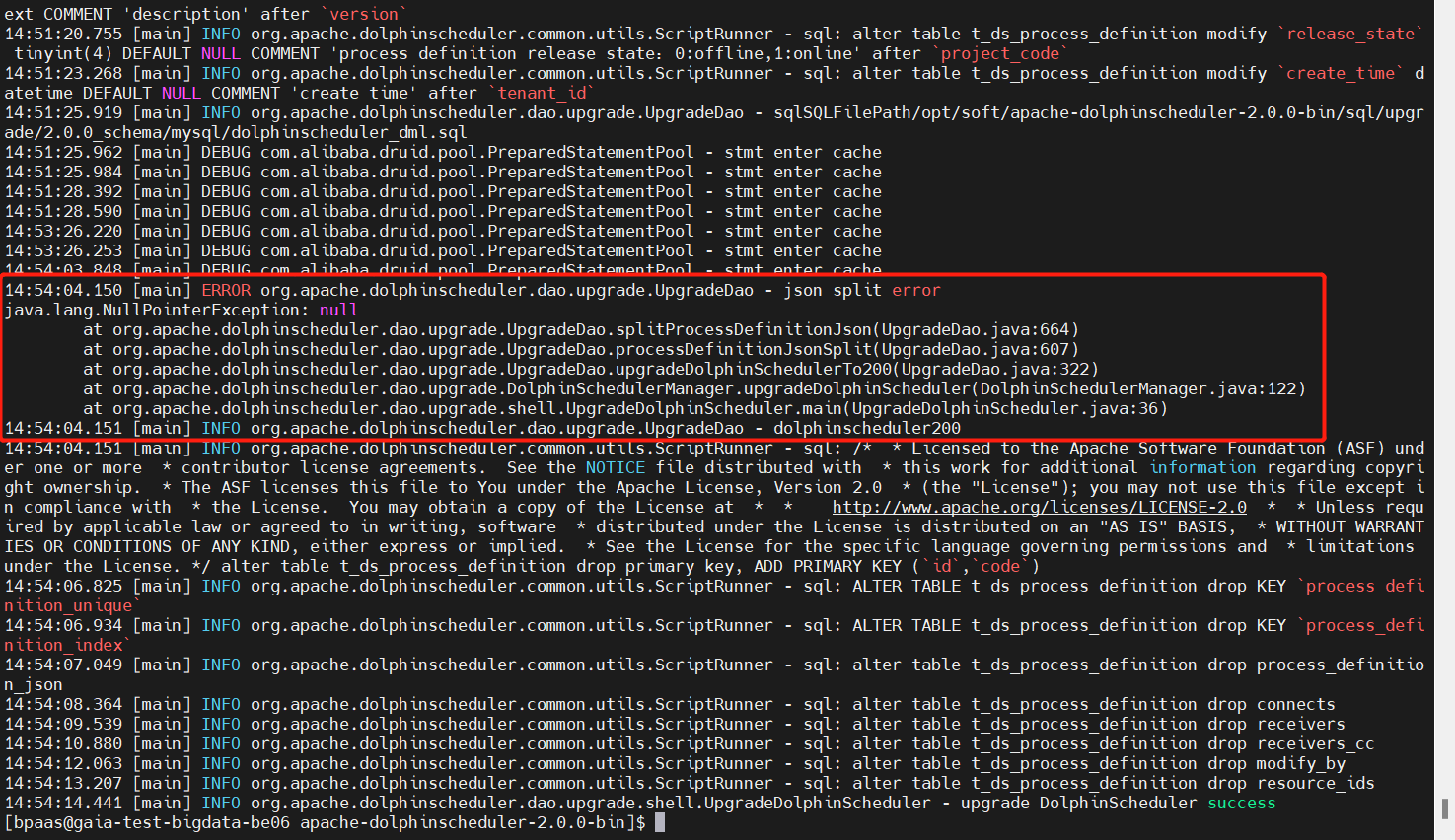
这个问题说实在的,刚开始是一脸懵逼啊,差点让我放弃了跨大版本的升级之路,然后直觉告诉我遇到问题不要慌,要淡定,于是果断下载v2.0.0源码,定位到了源代码位置,分析后对其进行了修改并打印记录错误日志,以便后续分析,先让程序正常运行起来,这里我在调试过程中主要修改了以下几处:
源码修改第1处主要是规避processDefinitionMap为空,导致的空指针异常,如下图所示:
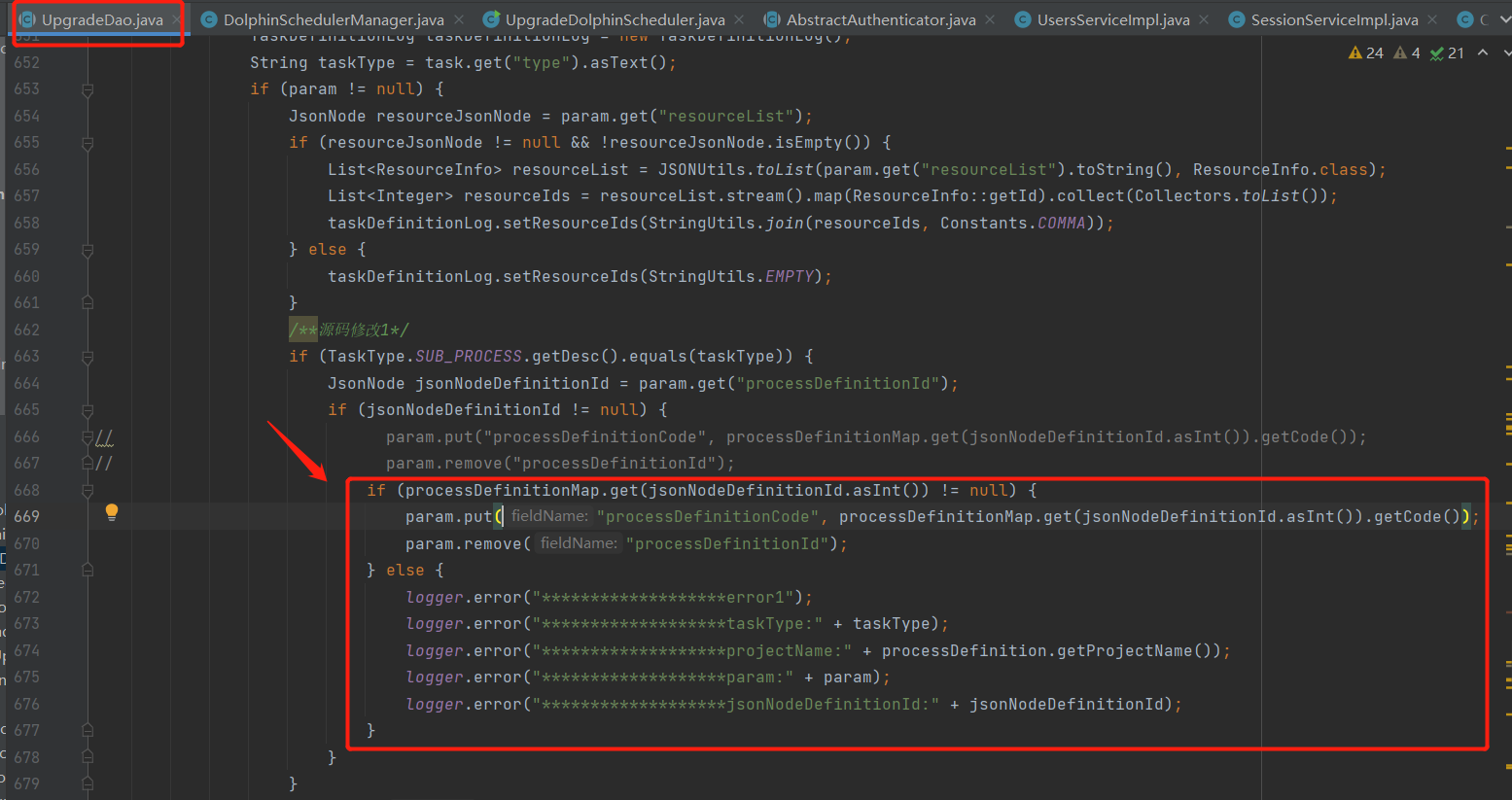
源码修改第2处主要是规避task对象节点获取description描述信息为空,导致的空指针异常,如下图所示:

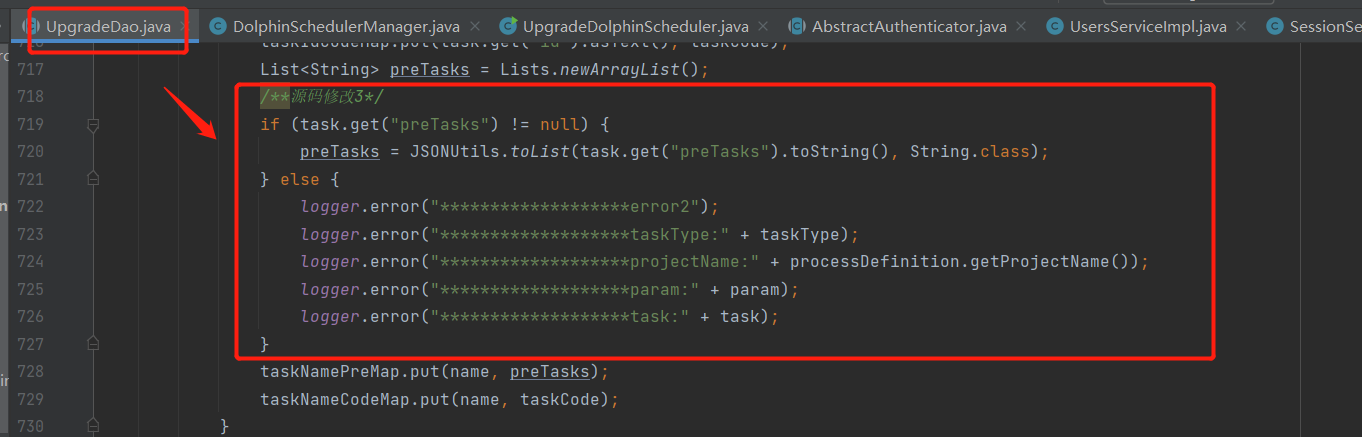
源码修改第3处主要是规避task对象节点获取preTasks前置任务为空,导致的空指针异常,如下图所示:
- Data too long for column 'task_params' (v1.3.6->v2.0.0)
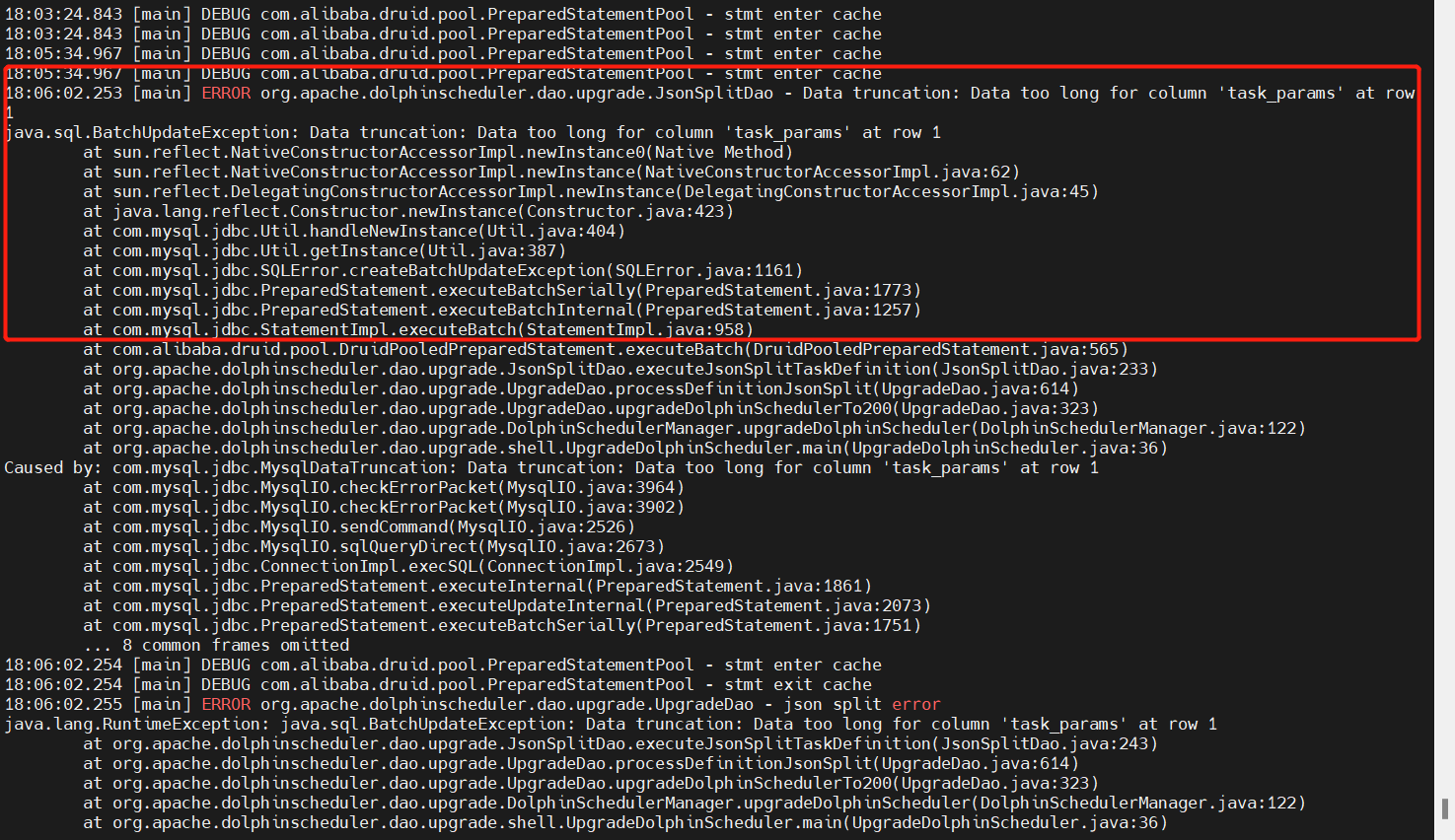
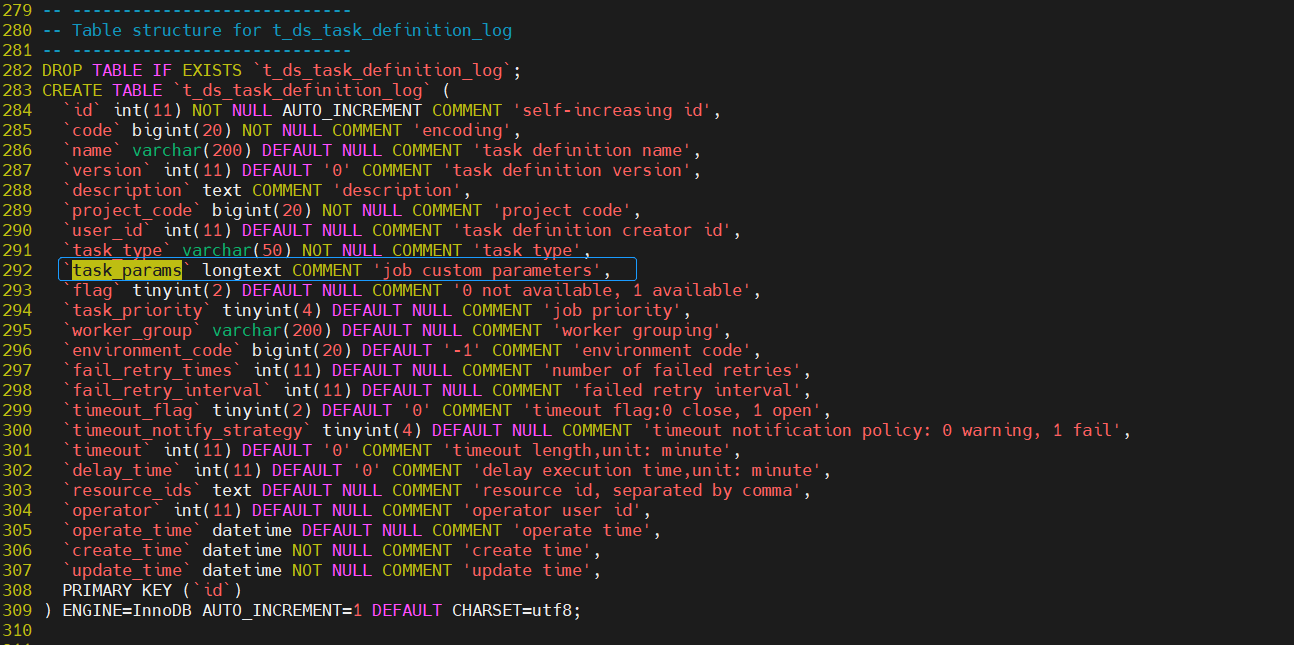
这个问题需要修改官方提供的DDL脚本,具体需要修改dolphinscheduler_ddl.sql中t_ds_task_definition_log 的task_params字段长度text->longtext以及t_ds_task_instance的task_params字段长度text->longtext,text已经满足不了任务参数的存储大小要求了,如下图所示:

- Duplicate column name 'alter_type' (v2.0.9->v3.0.0)

这个问题是因为在v2.0.9及之前某个版本已经添加过,官方脚本未注释掉。
- class path resource [sql/upgrade/2.0.0_schema/mysql/dolphinscheduler_dml.sql] cannot be opened because it does not exist (v2.0.0->v3.1.7 这个是前提调研尝试的)
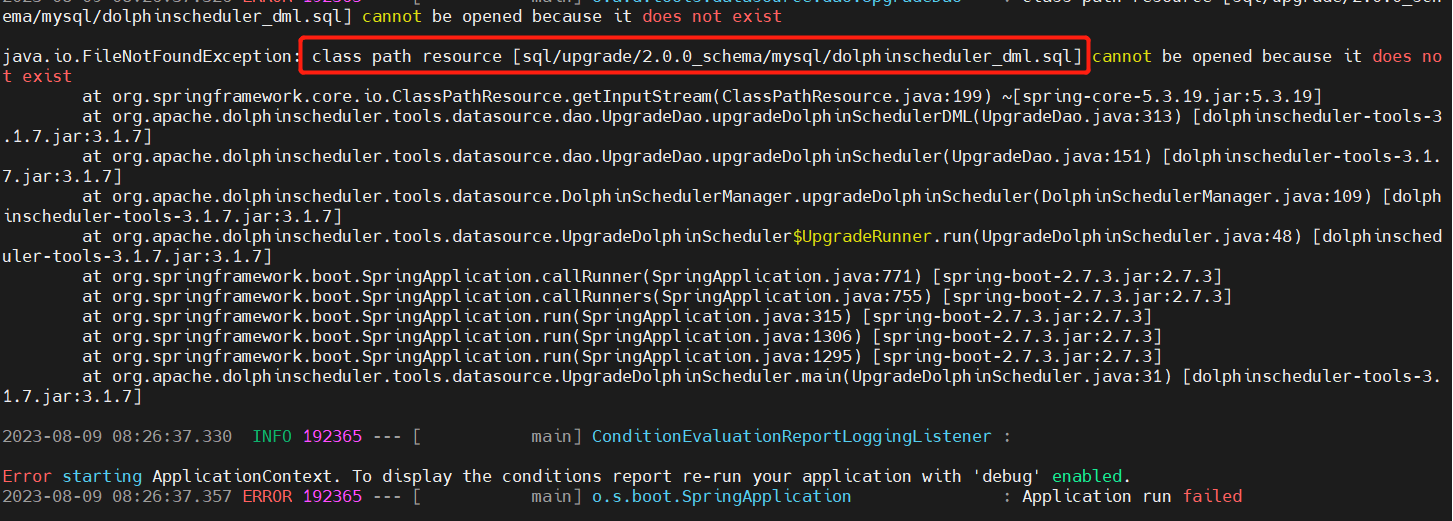
这个问题个人总结是版本跨度太大导致的,也印证了升级脚本只能小碎步,不能大跨步升级,如果你也遇到跨大版本升级,可以参考我的滚动升级版本,少走弯路。
- Unknown column 'other_params_json' in 't_ds_worker_group' (v3.0.0->v3.1.0)
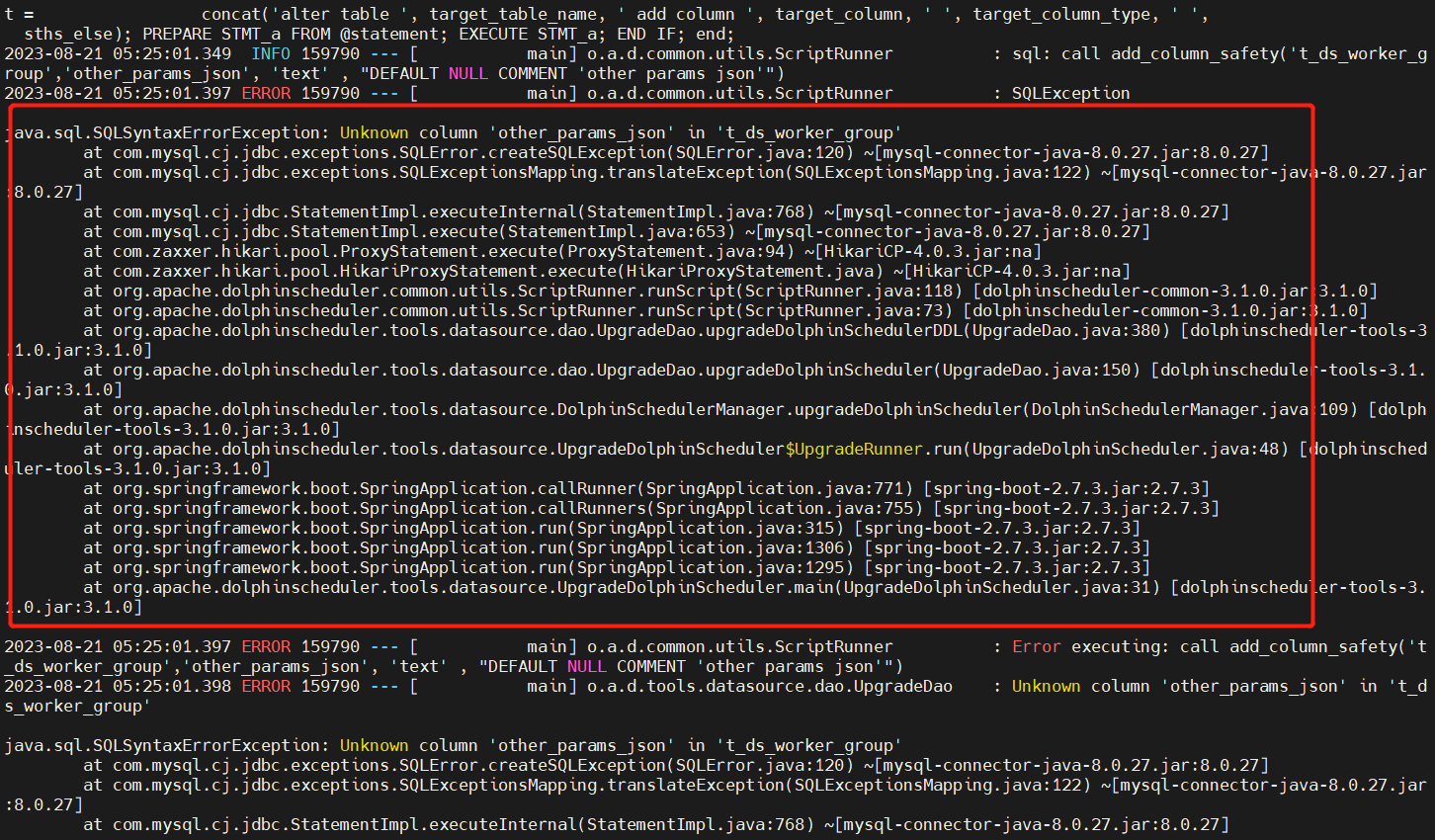
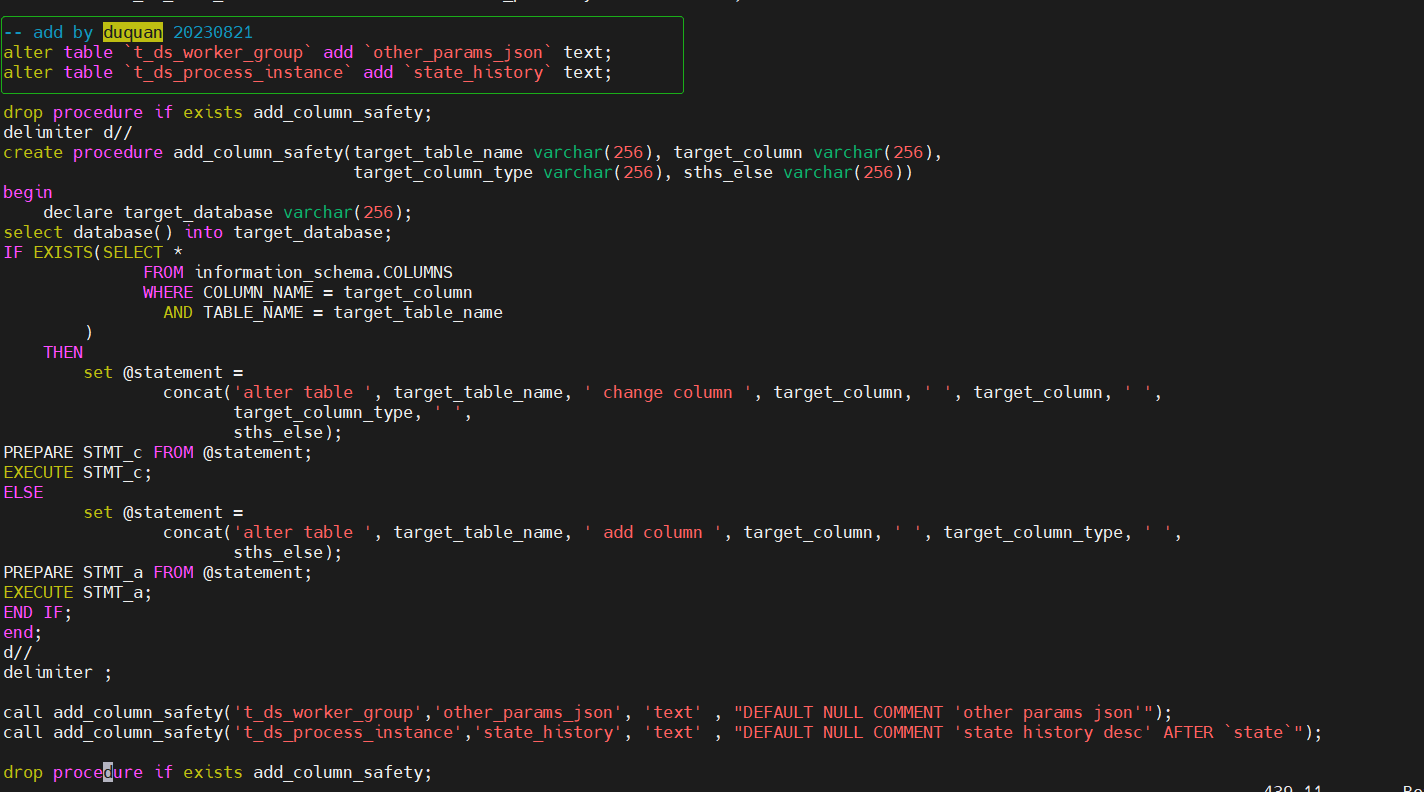
修改官方提供的DDL脚本,需要调整dolphinscheduler_ddl.sql,t_ds_worker_group表增加other_params_json字段,t_ds_process_instance表增加state_history字段,如下图所示:
- Unknown column 'description' in 't_ds_worker_group' (v3.1.0->v3.1.8)

修改官方提供的DDL脚本(在v3.1.8中3.1.1_schema下),需要调整dolphinscheduler_ddl.sql,t_ds_worker_group表增加description字段,如下图所示:

- 不向前兼容性的更新
这个兼容性主要涉及v3.0.0和v3.1.1版本,对于v3.0.0一个是复制和导入工作流时去掉了copy前缀;使用分号;作为SQL默认分隔符。对于v3.1.1就是改变了unix执行shell的方式由sh改为bash,这些影响基本可以忽略。
(4)集成成果展示
数据中台集成菜单是平台定义的,只有一个入口菜单,即:海豚调度,这里嵌入中台的截图的是v3.1.1的版本,v3.1.8随后会快速集成进去,除了状态和定时状态样式基本大差不差。
技术创新之数据表血缘
基于海豚调度工作流定义,我们也做了创新性的数据表血缘实践,总体逻辑通过解析工作流定义,在数据流转过程中基本都是以Insert...Select这种语法,以输入表(Select语句)、输出表(Insert语句)作为流转过程构建数据血缘DAG流图来赋能我们的业务,相当于为数据中台插了一双眼,真正做到数据表流转过程的可视化,这些都是以海豚调度作为核心点展开的。
数据血缘解析及全量查询
(1)数据血缘解析
- 整体架构
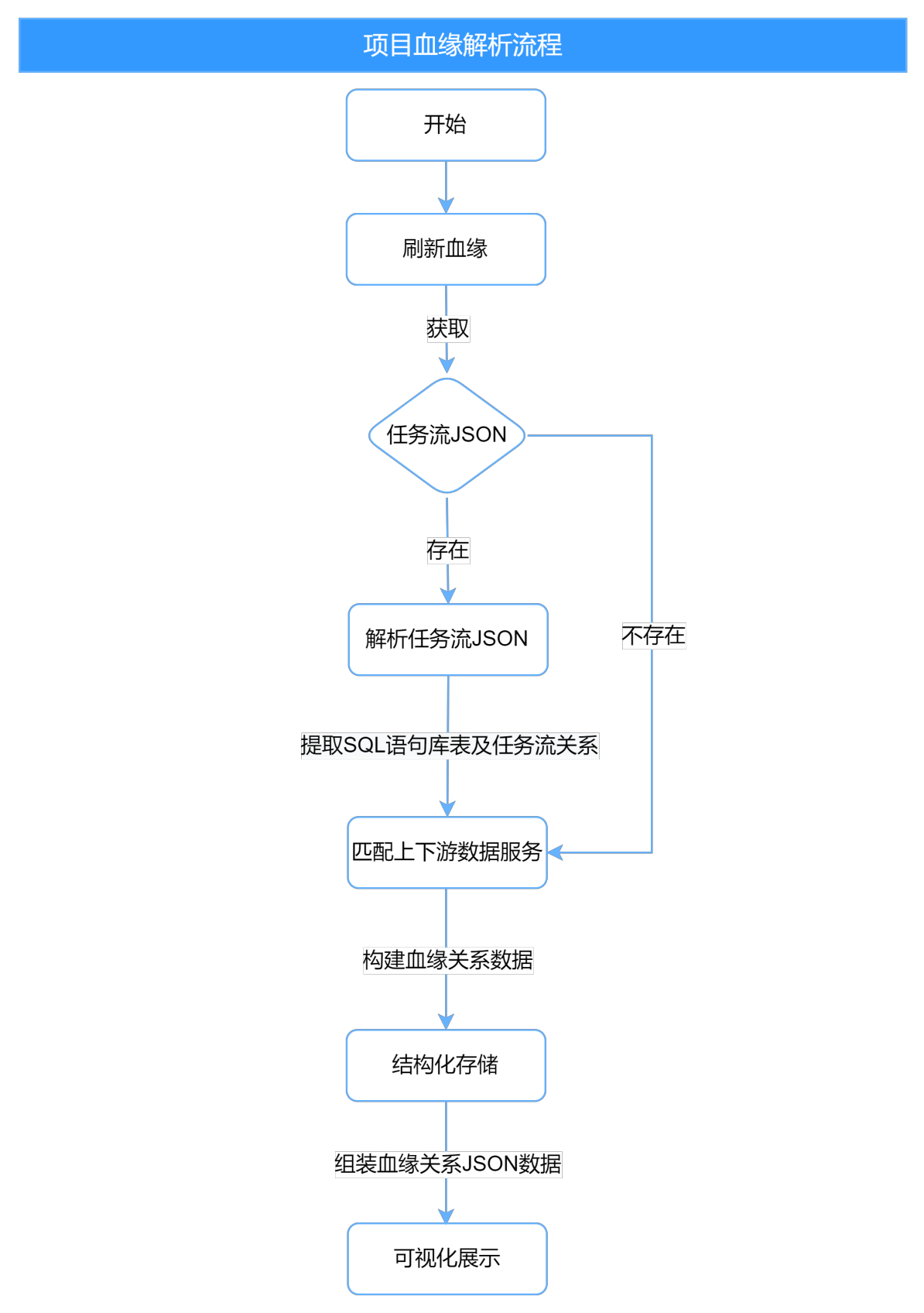
- 解析流程及展示
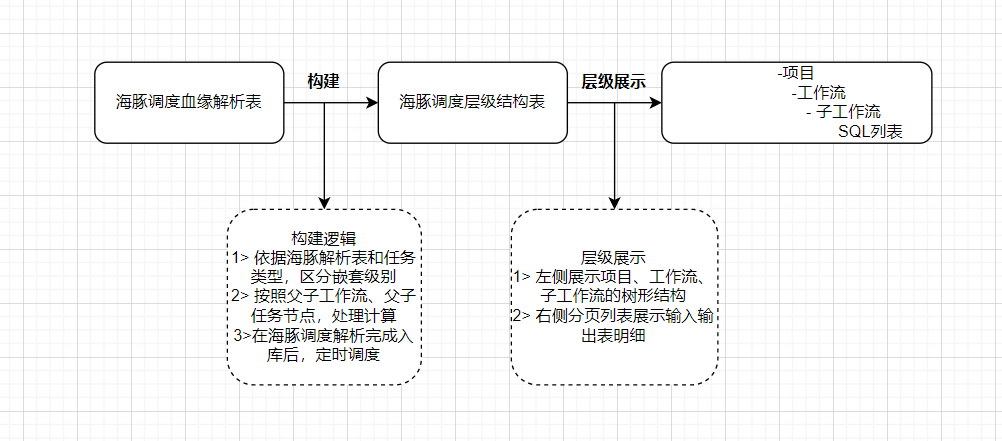
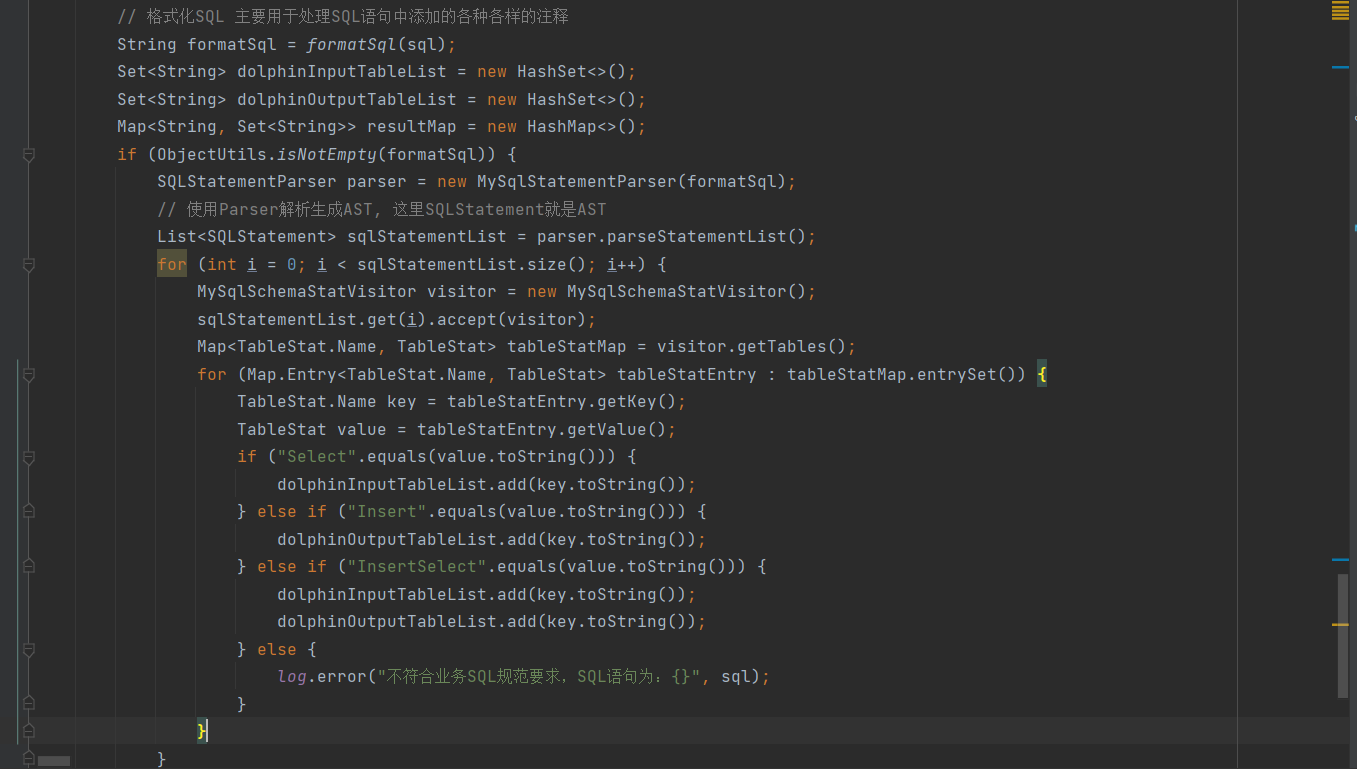
- 解析SQL的核心代码
解析SQL表血缘,我们采用的是阿里的Druid,建议版本(≥V1.2.6),Druid解析SQL还是很强大的,它的TableStat支持Merge、Insert、Update、Select、Delete、Drop、Create、Alter、CreateIndex、DropIndex这些类型并且可以按照语法组合,比如:InsertSelect,我们的血缘解析执行多个insert...select语句解析,多个用分号;分割
(2)数据血缘查询
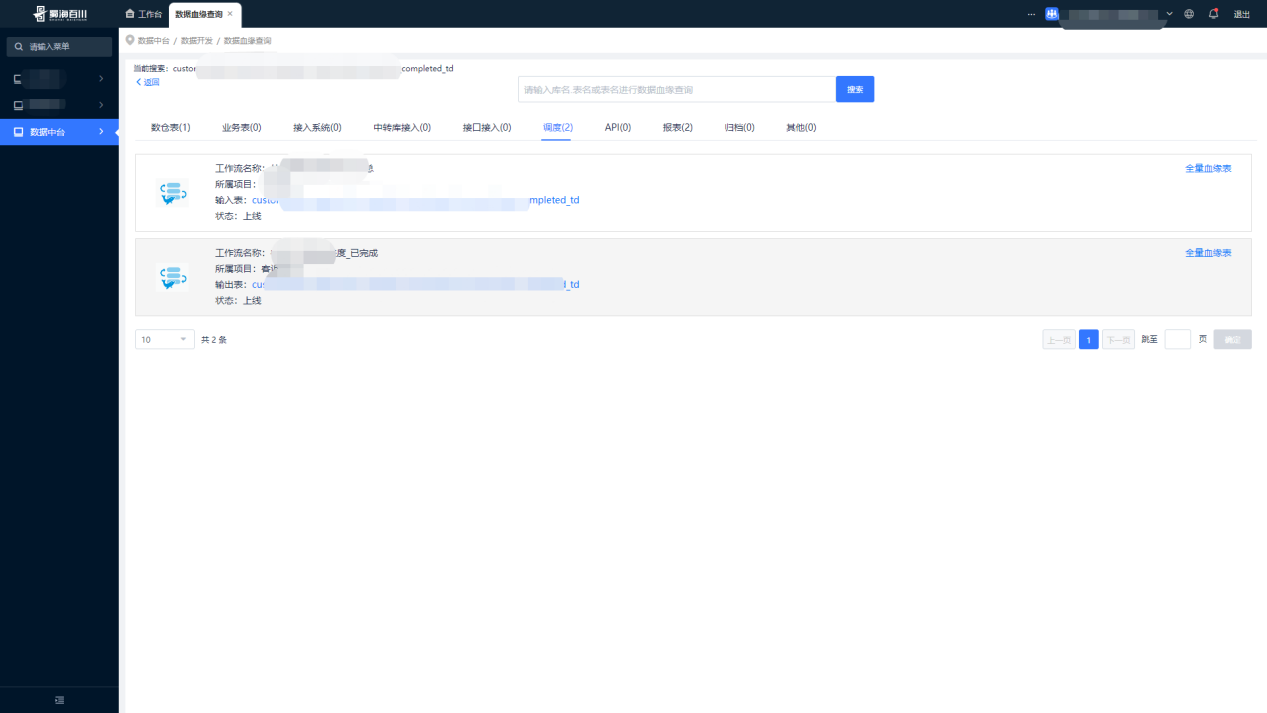
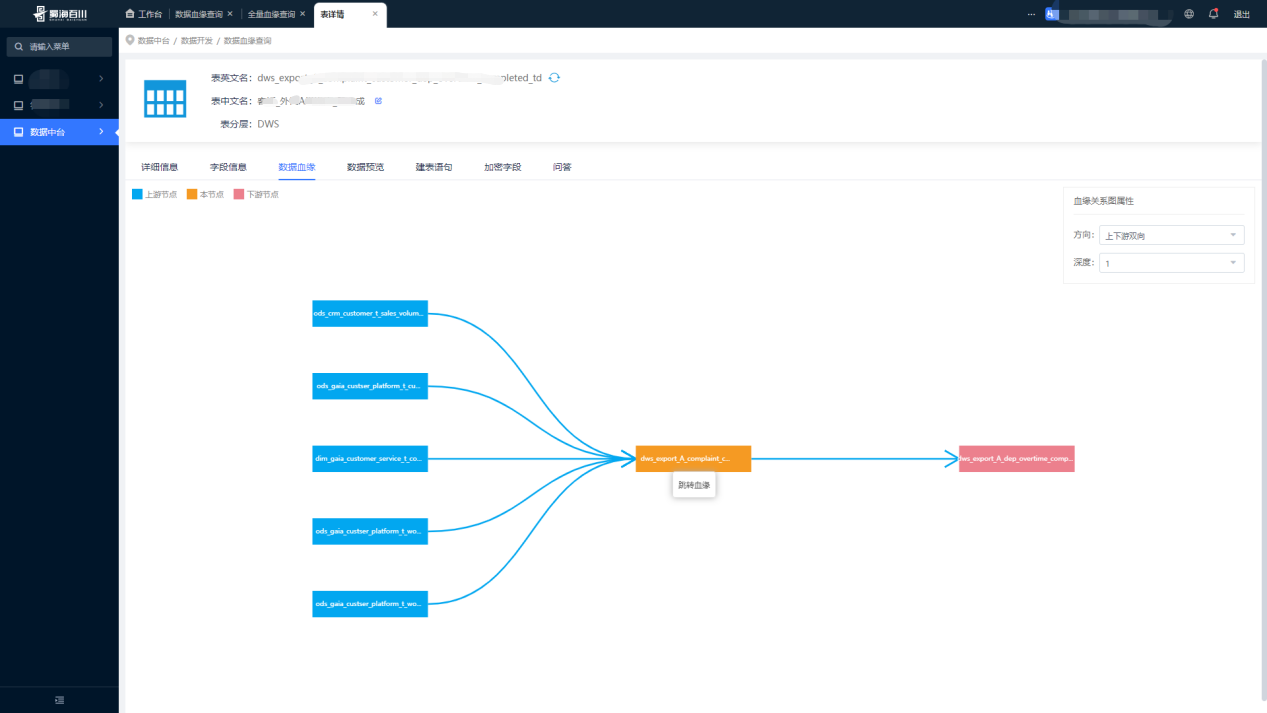
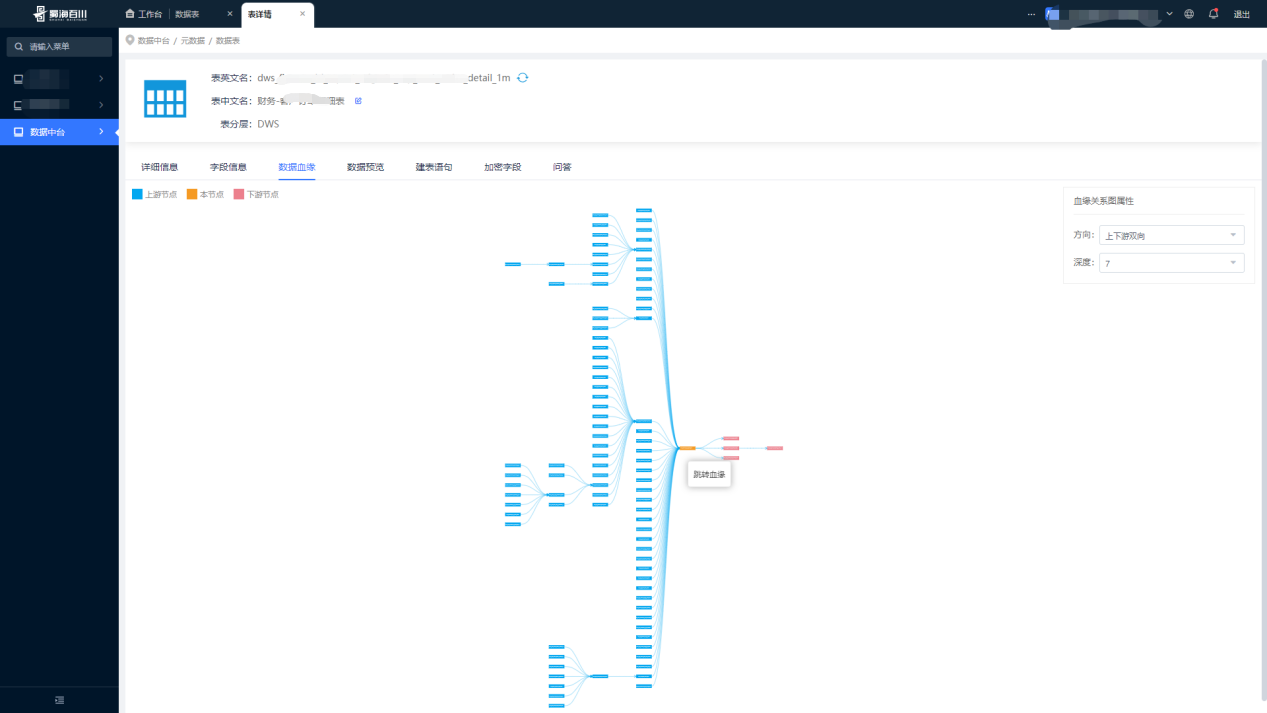
(3)全量血缘查询
全量血缘查询可以以输入、输出表的形式直观的展示海豚调度项目工作流定义,快速查询定位到某个任务,给我们数据分析师带来了极大的便利。
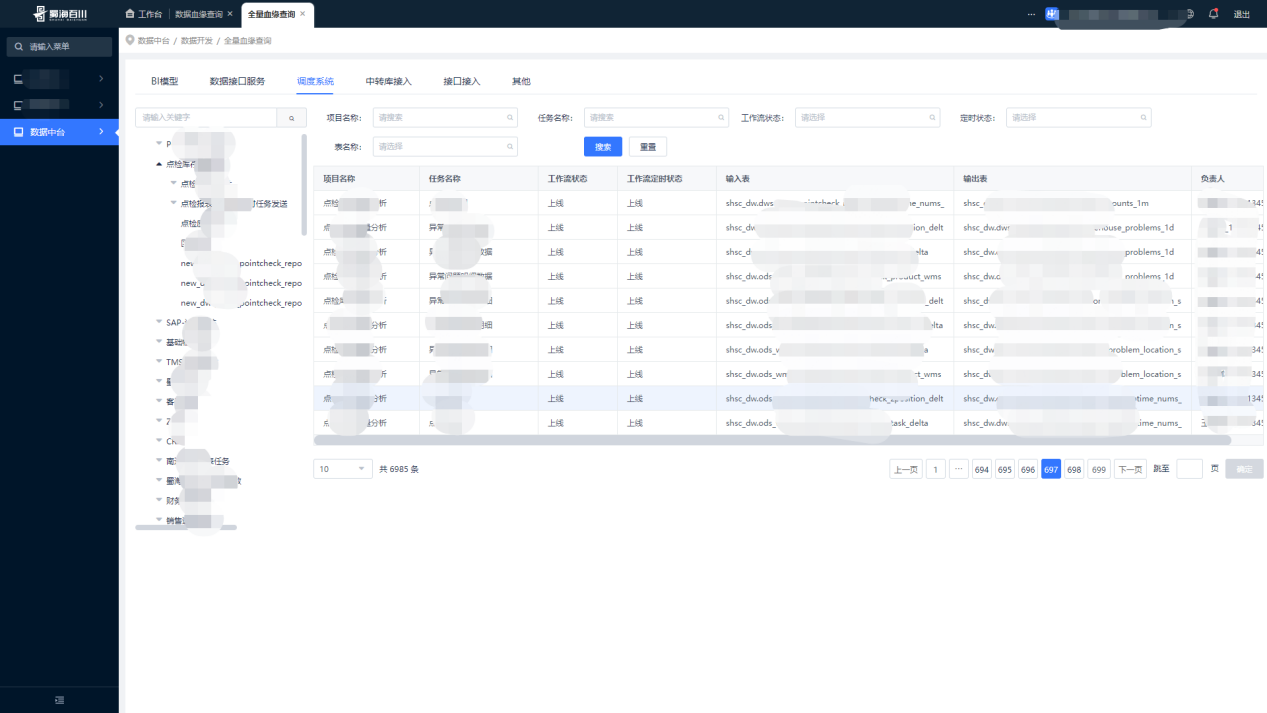
(4)血缘异常处理
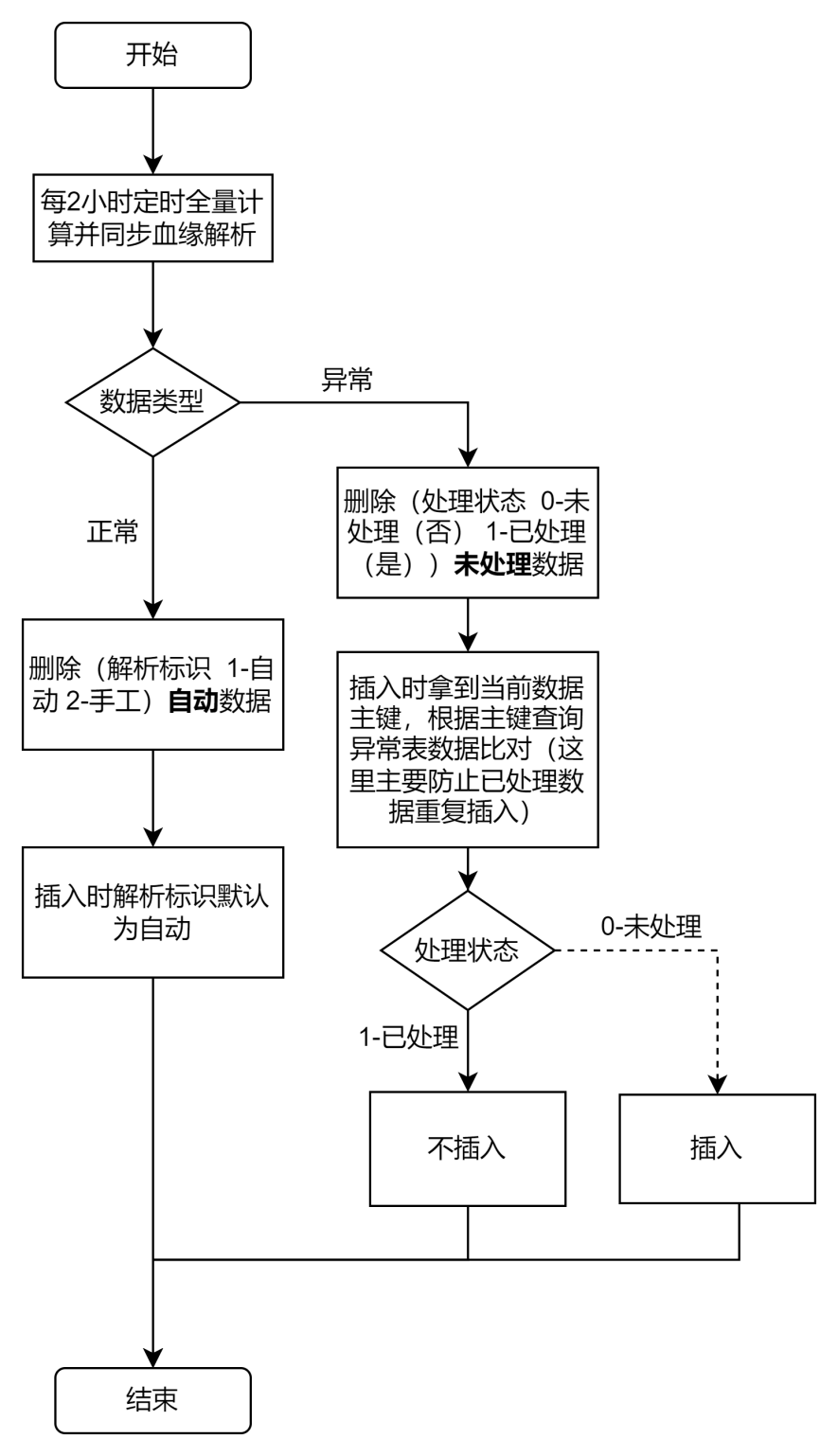
在数据血缘解析过程中,难免会出现SQL语句解析异常的情况,我们也考虑到了这一点,总体异常处理流程如下:
用户收益
- 支撑公司数据中台每日累计近7000的工作流定义任务个数,78个项目基本涵盖数据中台的所有业务模块;
- 基于工作流和任务定义构建的表级上下游血缘解析及查询,真正做到了表血缘关系的统一化检索和可视化管理,极大提升了数据中台开发人员和数据分析师的日常检索表的效率;
- 提供了设置任务执行策略模式,在同一工作流实例下任务交叉执行时,保证了数据的准确性;解决了任务间自定义参数上下游依赖传参问题;
- 后续迭代升级可以做到快速高效地响应数据中台生产需求。
总结与致谢
不得不说基于Apache DolphinScheduler提供的强大集成扩展插件能力大幅提升了企业数据加工、集成、开发的效率,真正做到了为企业业务数据分析高效流转赋能。
我们第一版数据中台集成部署时使用的是v1.3.6 版本。目前社区已经发布了v3.1.8,并且这次我们也是滚动升级到了最新版本v3.1.8,也是紧跟社区步伐,官方社区v3.2.0也在预热中,迭代速度之快,也侧面反映了用户群体在日益倍增。如果你们公司正在为选择大数据调度组件而苦恼,我们真心强烈建议使用海豚调度。
加入社区、进DS Group群,DS也会有每周的FAQ环节及时为你答疑解惑,贴心服务,你值得拥有。
强烈值得推荐Apache DolphinScheduler,调度选的好,下班回家早;调度选的对,半夜安心睡!希望大家都能从中受益,告别996。
最后,衷心祝愿Apache DolphinScheduler生态圈越来越好!
用户简介
蜀海(北京)供应链管理有限责任公司
所属行业:整体食材供应链
蜀海供应链成立于2014年6月,是集销售、研发、采购、生产、品保、仓储、运输、信息、金融为一体的餐饮供应链服务企业,现为广大餐饮连锁企业及零售客户提供整体食材供应链解决方案服务。
蜀海拥有遍布全国的现代化冷链物流中心、食品工厂、蔬果加工中心、底料加工等基地。以安全透明的供应链体系为餐饮客户提供品质服务,解决餐饮行业难标准化的痛点。在净菜生产、菜品研发、餐饮标准工业化等项目领域做持续不断的研究升级下,蜀海获得了业内权威机构和广大客户的认可,已成为供应链领域的标杆企业。
本文由 白鲸开源科技 提供发布支持!