索引
- 初识线程
- 1.inux下的线程
- 2.再谈进程
- 3.理解页表
- 4. 再次理解虚拟到物理的转化
- 线程的控制
- 1.线程的创建
- 2.线程异常
- 3.验证`pthread_join` 的第二个参数
- 4.线程的退出方式
- 5. 线程的公有和私有
- 6.pthread_t 与线程独立栈
- 7.线程的局部性存储
- 8.线程分离
初识线程
1.inux下的线程
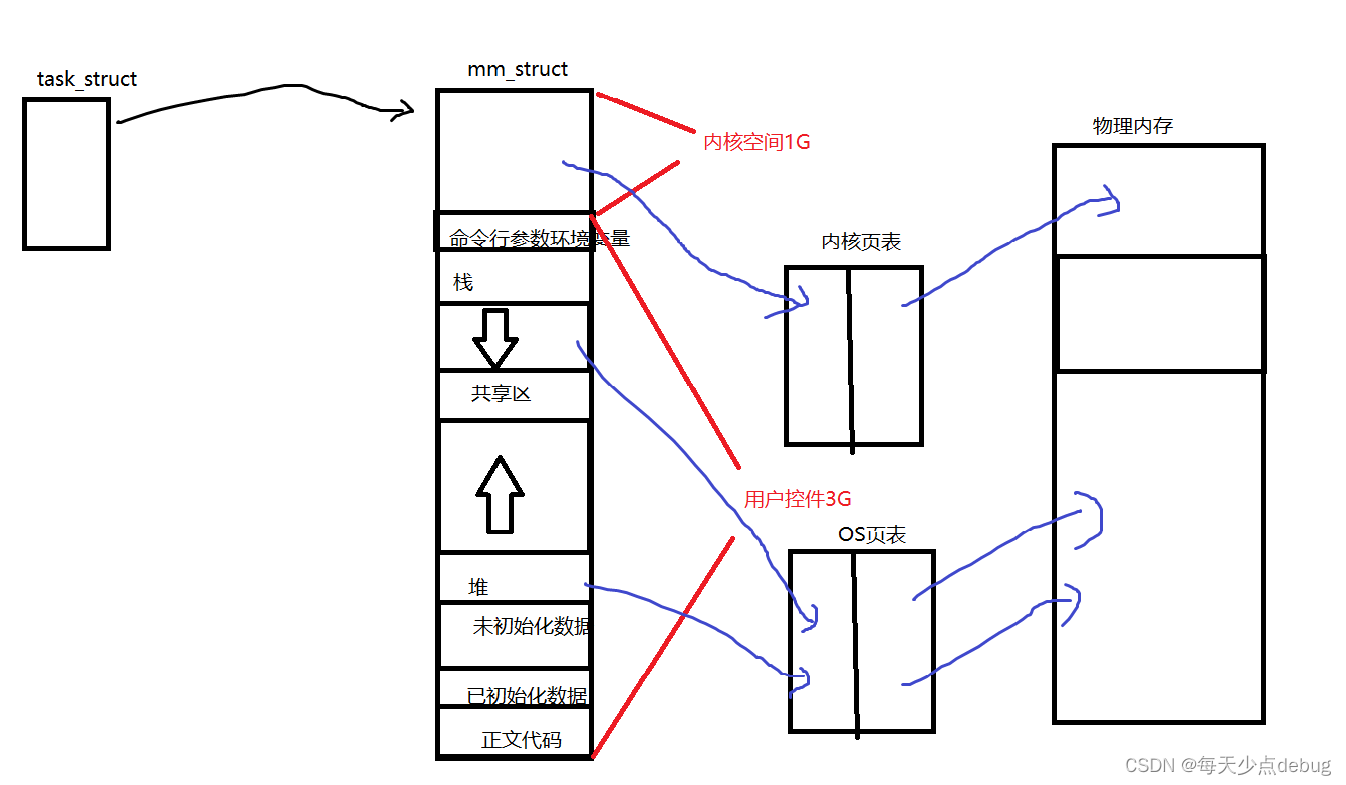
之前了解到,当一个进程被创建的时候,进程的task_struct被创建,进程的数据和代码通过页表的映射加载到物理内存。CPU选择一个进程调度就是将进程task_struct的地址load到寄存器当中,这样CPU就能很快找到这个地址,并且也可以将页表的起始地址也load到寄存器中,通过页表就能完成虚拟地址到物理地址的映射,由于task_struct和页表的上下关系都有,所以CPU内部是能快速的找到进程的所有数据的。
由于我们再创建一个进程,那么又是重复完成上述的一系列工作,成本非常高。
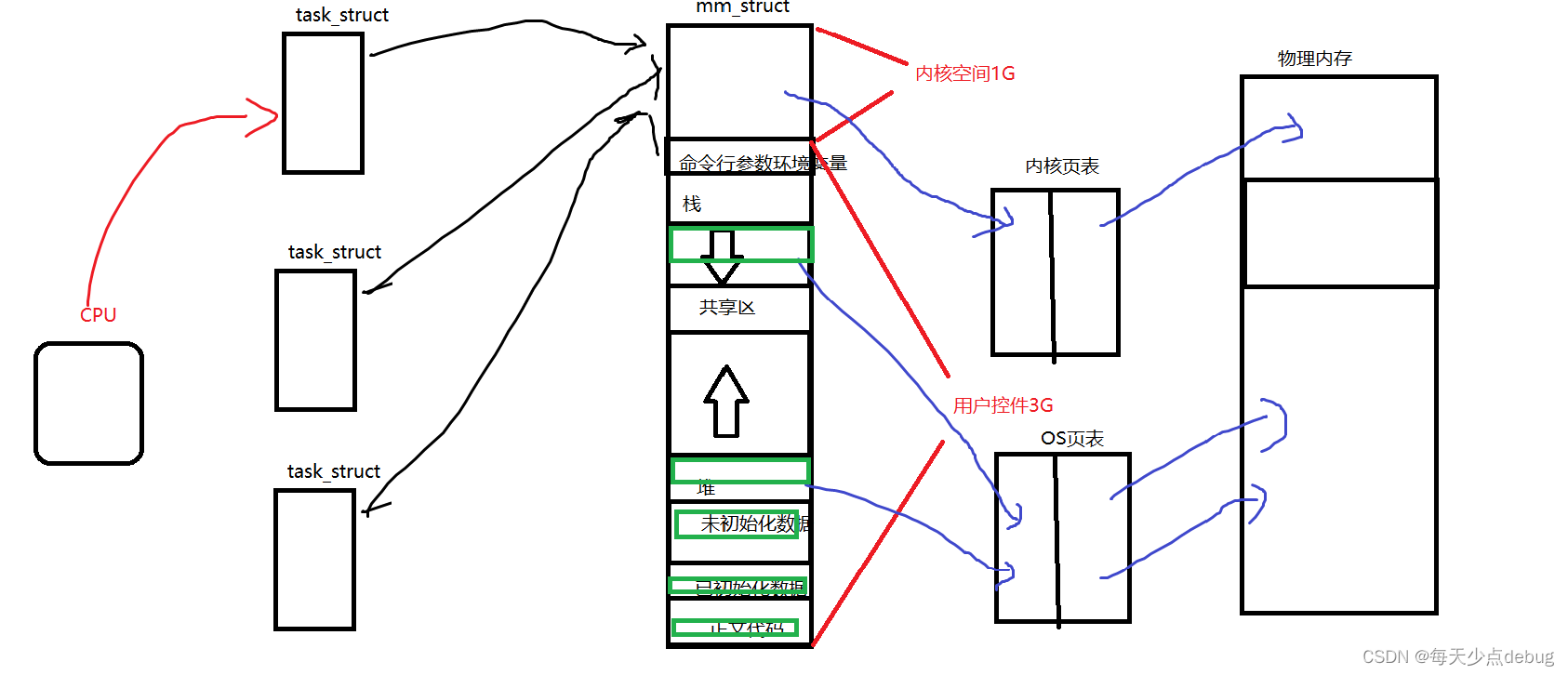
如果此时我们只创建PCB,并且是这几个PCB指向同一个地址空间,共用一张页表并且将进程的代码和数据通过函数划分成几部分,让各个PCB执行自己的部分代码和数据,各个PCB各自使用部分页表来完成映射,所以各个PCB完成的都是一部分 ——这就是Linux下粗粒度的线程。
所以就可以引出线程的几个基本概念:
1.线程是在进程的地址空间内运行的,是进程内部的一个执行流
2.线程执行粒度比进程更细,因为其执行的代码变得更小了,数据变得更少了,CPU内有一大堆寄存器,调度的时候地址空间不用切换了,页表不用切换了,要切的只是当前进程产生的临时上下文,寄存器上的一些核心数据结构不用切换了,所以调度的成本更低
3.线程是CPU内调度的基本单位。
上述说的只是在Linux的线程。
对于其他操作系统而言,由于线程的一些特性,导致线程:进程一定是 n:1的。进程需要管理,线程当然也需要管理,线程的描述是tcb,进程是pcb,但是如果单独实现线程的描述,那么其和进程之间的耦合关系就会变得很复杂。
对于Linux而言:
没有线程,没有线程在概念上的划分,只有一个叫做执行流。
Linux的线程是用进程模拟的,PCB模拟的。(这是很多教材的说法)。
因此在linux下是有TCB的,但不是单独设计的,其直接复用了PCB。
所以Linux下提供了一些接口来进行线程的相关操作,但是系统调用接口太麻烦了,而是所有的Linux必须自带的一套原生线程库,在用户层对线程进行相关动作。
这样对于CPU而言有区别吗?没有任何区别,都是调度一个task_struct,只是调度的粒度更小,调度的成本更低,这样本来串行化执行的代码,可以并发或并行的同时执行代码,同时推进,这就线程!!!
2.再谈进程
曾经: 进程 = 内核数据结构 + 进程对应的代码和数据
现在:进程 = 内核视角:承担分配系统资源的基本实体(进程的基座属性)
意义:向系统申请资源的基本单位!!
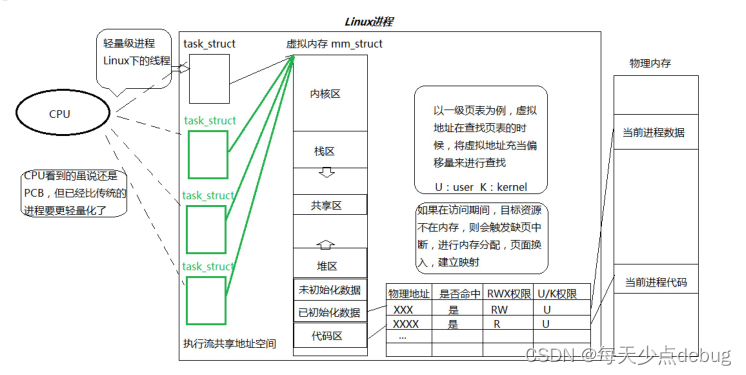
之前的进程是内部只有一个执行流的单执行流的进程,但是现在可以是内部有多个执行流的进程——多执行流的进程。
总结
CPU视角,task_struct <= 传统的进程PCB
;没有真正意义上的线程,而是用进程的task_struct模拟实现的,linux下的“进程” <= 其他操作系统的进程概念。
linux下的线程也叫做轻量级进程!线程是调度的基本单位!
下面写一段线程代码:
#include <iostream>
#include <string>#include <pthread.h>
#include <unistd.h>
using namespace std;
void *callback1(void *args)
{string name = (char *)args;while (true){cout << name << ": " << getpid() << endl;sleep(1);}
}
void *callback2(void *args)
{string name = (char *)args;while (true){cout << name << ": " << getpid() << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_create(&tid1, nullptr, callback1, (void *)"thread 1");pthread_create(&tid2, nullptr, callback2, (void *)"thread 2");while (true){cout << "我是主线程 我正在运行代码" << endl;sleep(1);}pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);return 0;
}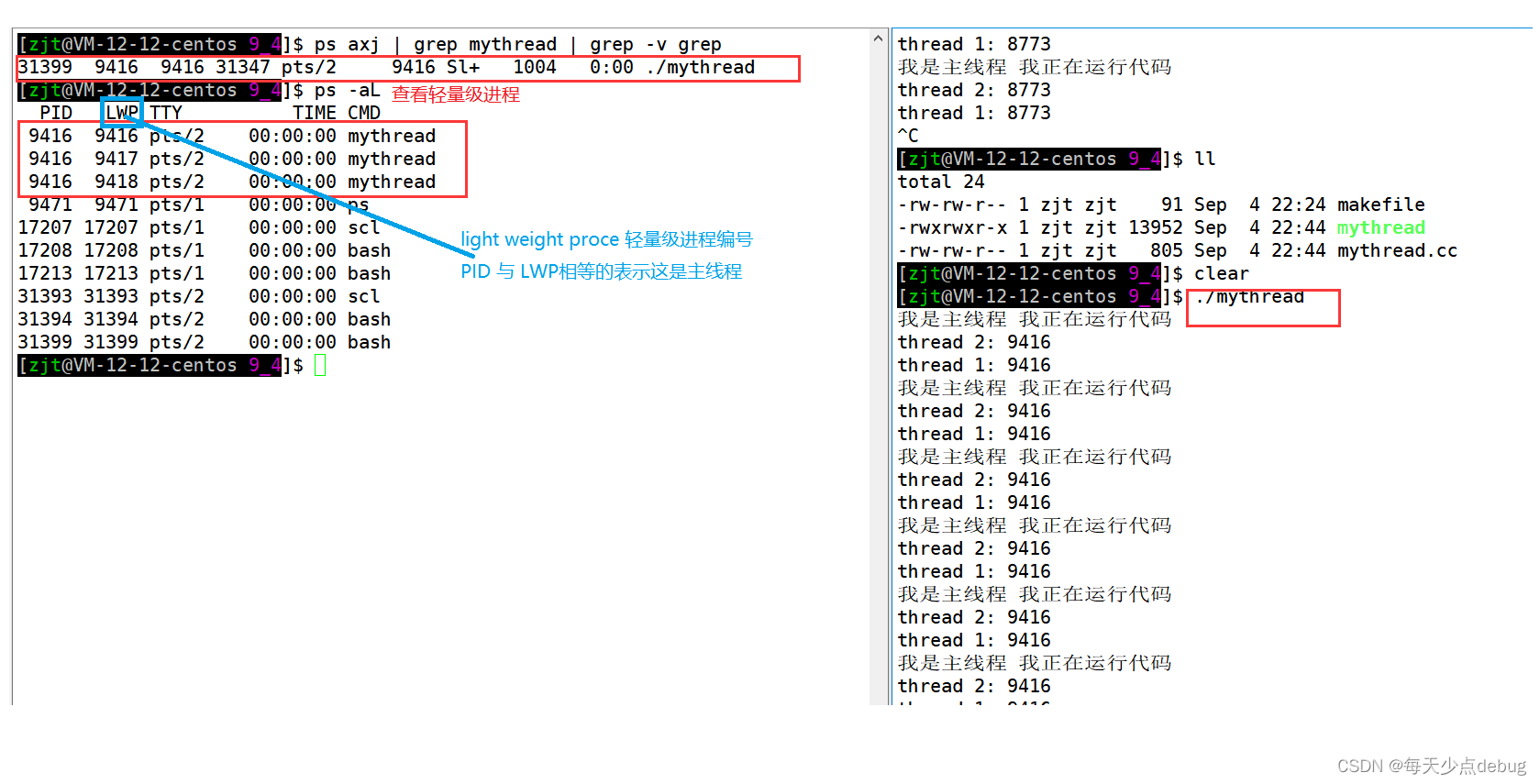
验证了linux下线程就是轻量级进程。
总结
优点:
1.创建一个线程的代价要比一个新进程的小得多
2.线程的切换不需要切换页表和地址空间,需要做的工作比进程的少
3.线程占用的资源比进程小
4.线程可以充分利用多处理器的并行数量
5.在等待慢速I/O操作时,程序可执行其他任务
6.计算密集型应用,为了能够在多处理器系统上运行,将计算分解到多个线程执行
缺点:
1.性能损失,一个很少被阻塞的计算密集型往往无法与其他线程共用一个处理器,并且一旦线程的数量比处理器的数量多,那么就可能会造成较大的性能损失,这里的损失指的是增加了额外的同步和调度开销,而可用的资源不变
2.健壮性降低,进程有独立的地址空间和页表,线程往往会和其他线程共享变量
3.缺乏访问控制,线程时调度的基本单位,在一个线程中调用某些OS会对整个进程造成影响
4.编写苦难较高,调试较难
3.理解页表
先看一个例子:
char*msg = "hello world; *msg = 'z'
上述一行代码是对的吗?
上述的代码能编译过,但是运行时会报错。
因为上述的msg指向的是字符串常量,其存在于只读常量区,是只读的,不能被修改,当发现被修改时,就会报异常。
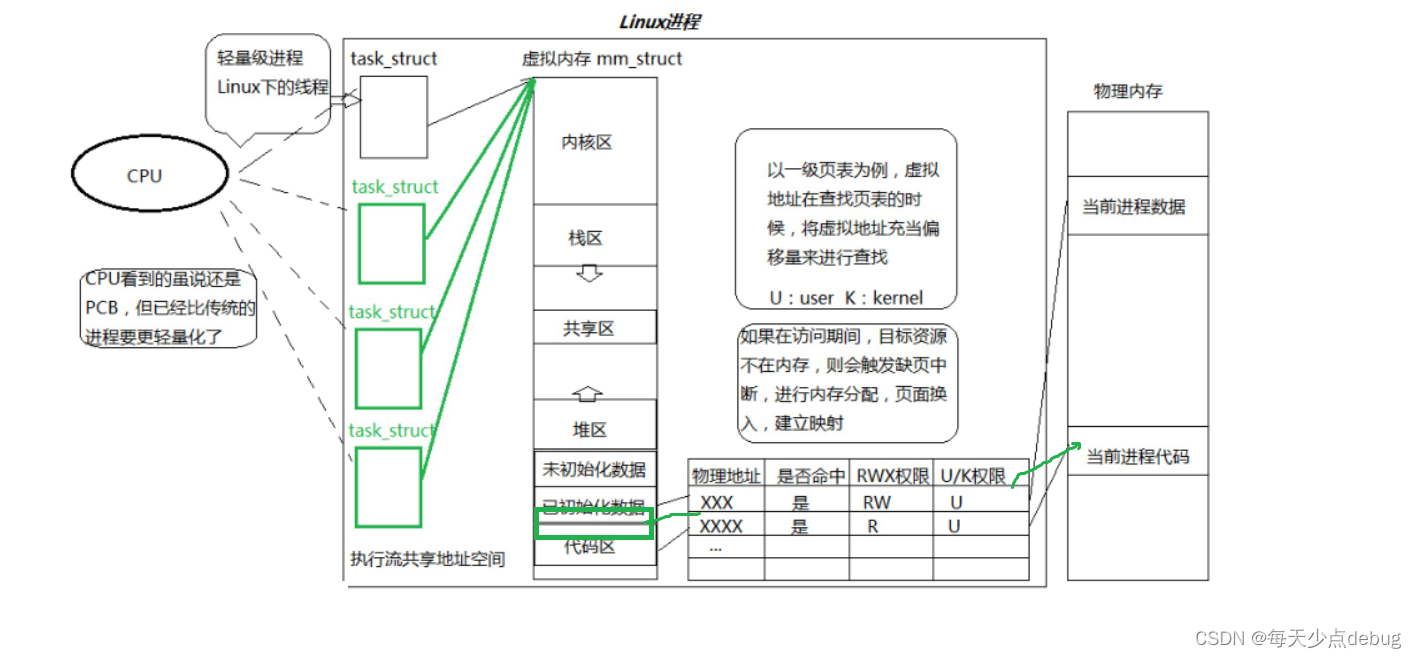
字符常量区位于代码区和已初始化数据区,该代码基于页表的映射此时在页表中的权限是只读的,当程序企图修改时,OS会通过页表检测到权限不符,就会报错,其实内存任何时候都是可以被修改的,只是有没有修改的权限罢了。
4. 再次理解虚拟到物理的转化
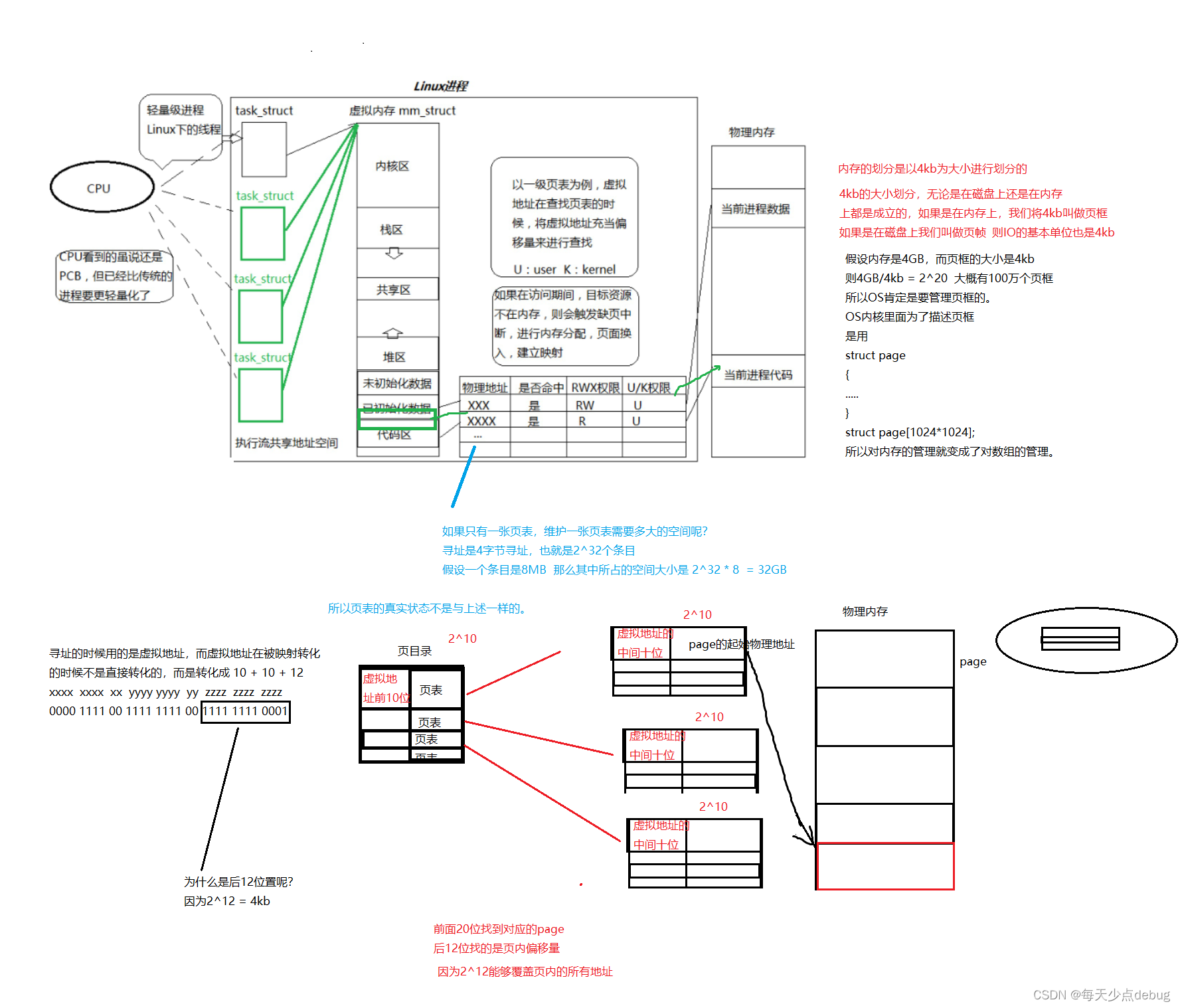
这样做有什么好处呢?
1.将进程虚拟地址管理和内存管理通过页表+page进行解耦。当我们要访问某个数据时,通过页表的映射,发现page = null,此时OS就必须从内存重新加载了。在解释一下,页表只关心page在还是不在,如果不在,就交给操作系统的内存管理,将数据重新从磁盘加载到内存。
2.因为将页表拆开了,可以实现页表的按需创建,节省空间
**解释:**页表的最终大小是2^32 / 2^12 = 1M 假设一个条目是20个字节,所以页表最大也就是20M
线程的控制
1.线程的创建
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
作用:创建线程
thread:线程id
attr:属性(不考虑)
void *(*start_routine) (void *):线程执行时所对应的回调方法
arg:传入回调方法中的参数
返回值:创建成功返回0
失败:返回错误码
#include <pthread.h>
pthread_t pthread_self(void);
作用:谁调用该函数就获取该线程的线程ID
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
作用:等待线程
因为线程本质上就是第一个轻量级进程,所以也是要等待的。否则会造成类似于进程那般的内存泄露问题。
thread:线程id
retval: 输出型参数,获取线程的返回值
#include <iostream>
#include <string>
#include <vector>
#include <pthread.h>
#include <unistd.h>
using namespace std;
static void PrintId(const char *name, const pthread_t &tid)
{printf("%s 正在运行,thread id: 0x%x\n", name, tid);
}
void *callback1(void *args)
{int cnt = 5;const char *name = static_cast<const char *>(args);while (true){cout << "线程正在运行...." << endl;PrintId(name, pthread_self());sleep(1);if (!cnt--)break;}cout << "线程退出了..." << endl;return nullptr;
}
void *callback2(void *args)
{int cnt = 5;const char *name = static_cast<const char *>(args);while (true){cout << "线程正在运行...." << endl;PrintId(name, pthread_self());sleep(1);if (!cnt--)break;}cout << "线程退出了..." << endl;return nullptr;
}
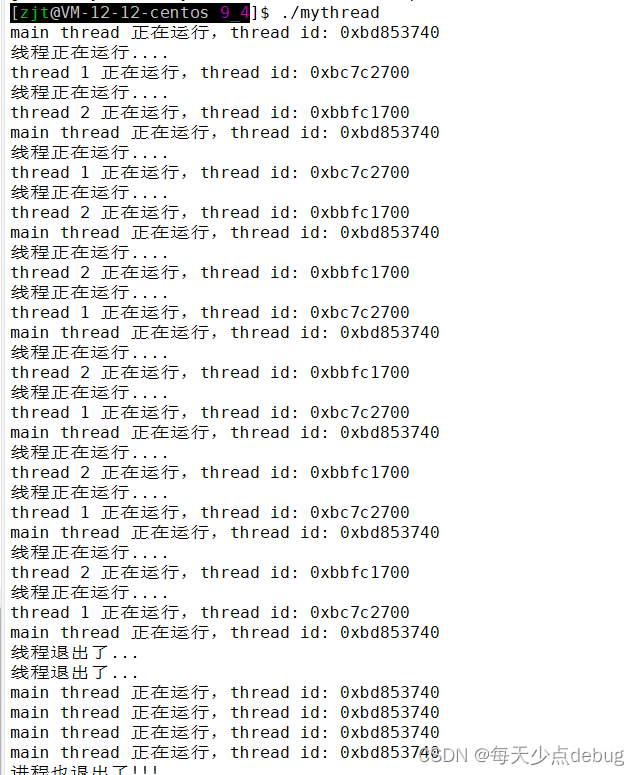
int main()
{pthread_t tid1;pthread_t tid2;pthread_create(&tid1, nullptr, callback1, (void *)"thread 1");pthread_create(&tid2, nullptr, callback2, (void *)"thread 2");int cnt = 10;while (true){PrintId("main thread", pthread_self());sleep(1);if (!cnt--)break;}cout << "进程也退出了!!!" << endl;pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);return 0;
}
2.线程异常
3.验证pthread_join 的第二个参数
参数是一个输出型参数,获取新线程的退出码
整体代码与上述相似,只写出更改的代码和运行结果的部分截图
return (void *)10;pthread_join(tid1, &retval);cout << "retval: " << ((long long)retval) << endl;
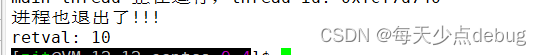
4.线程的退出方式
void *callback1(void *args)
{int *ptr = nullptr;*ptr = 4;int cnt = 3;const char *name = static_cast<const char *>(args);while (true){cout << "线程正在运行...." << endl;PrintId(name, pthread_self());sleep(1);if (!cnt--)break;}cout << "线程退出了..." << endl;return (void *)10;
}
如果此时线程一的回调函数如上所示

进程会直接退出,线程发生段错误,操作系统会发送信号给线程,而进行线程的信号是共享的,所以线程异常 = 进程异常
这也说明了线程的健壮性比较低
所以线程终止只考虑正常终止的情况。
#include <pthread.h>
void pthread_exit(void *retval);
线程终止函数,与上述代码的return 作用一样
#include <pthread.h>
void pthread_exit(void *retval);
给线程发送取消请求,如果线程是被取消的,退出结果是-1
-1实际上就是PTHREAD_CANCELED;表示线程的退出信息此时是被取消的。
int main()
{pthread_t tid1;pthread_t tid2;pthread_create(&tid1, nullptr, callback1, (void *)"thread 1");pthread_create(&tid2, nullptr, callback2, (void *)"thread 2");sleep(2);pthread_cancel(tid1);int cnt = 5;while (true){PrintId("main thread", pthread_self());sleep(1);if (!cnt--)break;}cout << "进程也退出了!!!" << endl;void *retval = nullptr;pthread_join(tid1, &retval);cout << "retval: " << ((long long)retval) << endl;pthread_join(tid2, nullptr);return 0;
}
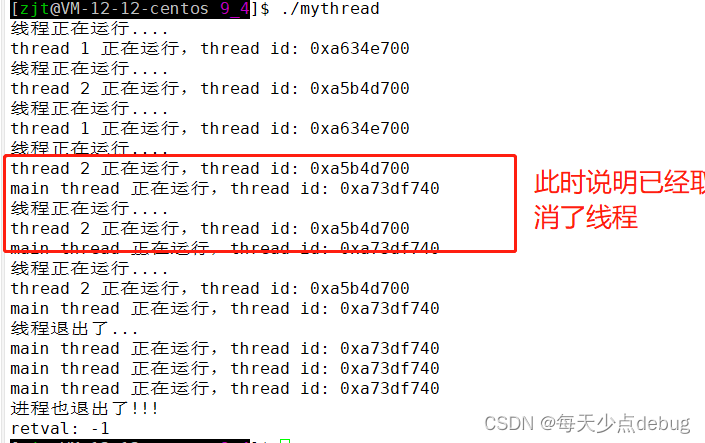
总结线程的退出方式:
1.return
value_ptr(pthread_join的第二个参数)存放的是thread线程的返回值
2.pthread_exit()
value_ptr(pthread_join的第二个参数)存放的是传给pthread_exit的参数
3.pthread_cancel();
value_ptr(pthread_join的第二个参数)存放的是常数:PTHREAD_ CANCELED
4.如果对线程的终止状态不感兴趣,可以穿nullptr给value_ptr
5. 线程的公有和私有
多线程进程,线程共享同一地址空间,同时线程还共享
文件描述符
每种信号的处理方式
当前工作目录
用户id和组id
当然,线程也有一部分自己的数据
线程ID
一组寄存器
栈
errno
信号屏蔽字
调度优先级
线程私有寄存器说明线程是可被调度的,可以进行线程切换,验证了线程是调度的基本单位。
私有栈说明线程是可以运行起来的,各自进行出栈和压栈

6.pthread_t 与线程独立栈

可以看到我们的用户级线程使用第三方线程库 libpthread.so
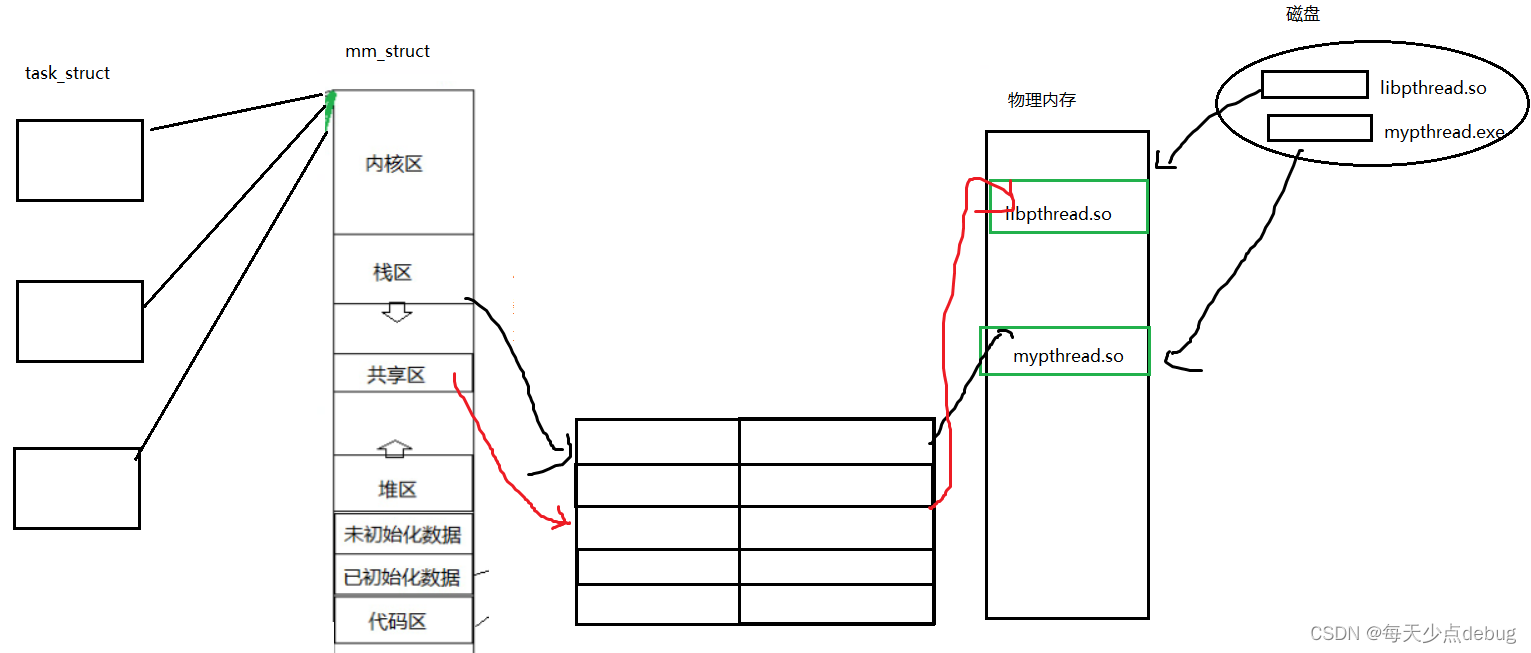
无论是第三方第三方线程库还是可执行程序,都要从磁盘加载到内存,然后通过页表建立地址空间与内存的映射。需要注意的是无论是自己的代码,还是库的代码,又或是系统的代码,都是在进程的地址空间中进行的。
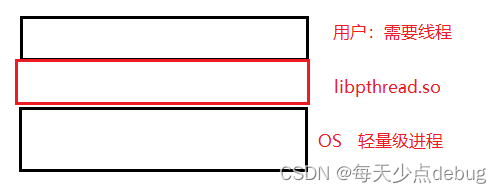
对于用户而言:其需要的是线程
但是对于LinuxOS而言,其只能提供轻量级进程。
所以libpthread.so起到了一个过渡的作用,其通过封装相关系统调用,使得用户看似拿到了线程,也正是在libpthread.so这一层开始有线程的概念。
所以线程的全部实现,并没有体现在OS中,而是OS提供执行流,具体的线程结构由库来进行管理。
库要创建多个线程,因此库要管理线程。
伪代码:
struct thread_info
{
pthread_t tid;
void *stack; //私有栈
};
大致如下
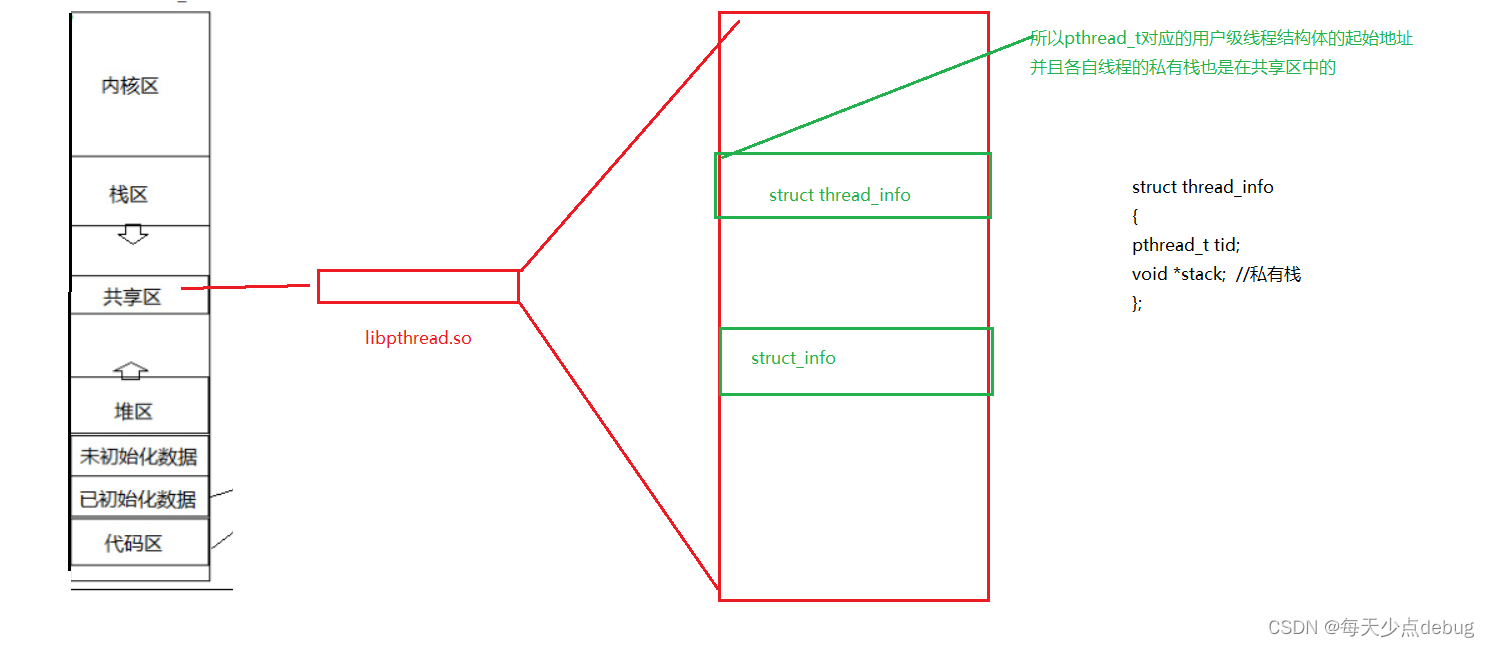
所以pthread_t对应的用户级线程结构体的起始地址
并且各自线程的私有栈也是在共享区中的,主线程用的是独立栈结构,也就是地址空间中的栈,新线程用的是库提供的栈结构。
7.线程的局部性存储
#include <iostream>
#include <string>
#include <vector>
#include <pthread.h>
#include <unistd.h>
using namespace std;
int global_val = 100;
void *startRounte(void *args)
{while (true){cout << "thread " << pthread_self() << " global_val: " << global_val<< "&global_val: " << &global_val << "Inc: " << global_val++ << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_t tid3;pthread_create(&tid1, nullptr, startRounte, (void *)"pthread 1");pthread_create(&tid2, nullptr, startRounte, (void *)"pthread 1");pthread_create(&tid3, nullptr, startRounte, (void *)"pthread 1");while (true){cout << "thread " << pthread_self() << " global_val: " << global_val<< "&global_val: " << &global_val << "Inc: " << global_val++ << endl;sleep(1);}pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);pthread_join(tid3, nullptr);return 0;
}
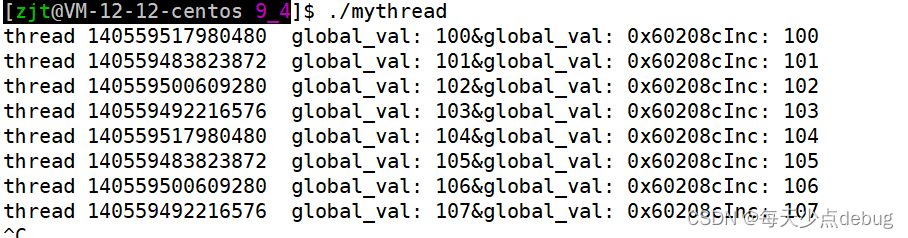
如上所示,此时的变量是全局变量,线程可以共享变量,各自打印的变量地址都是一样的
__thread int global_val = 100;
如果将变量的定义改成如上所示。
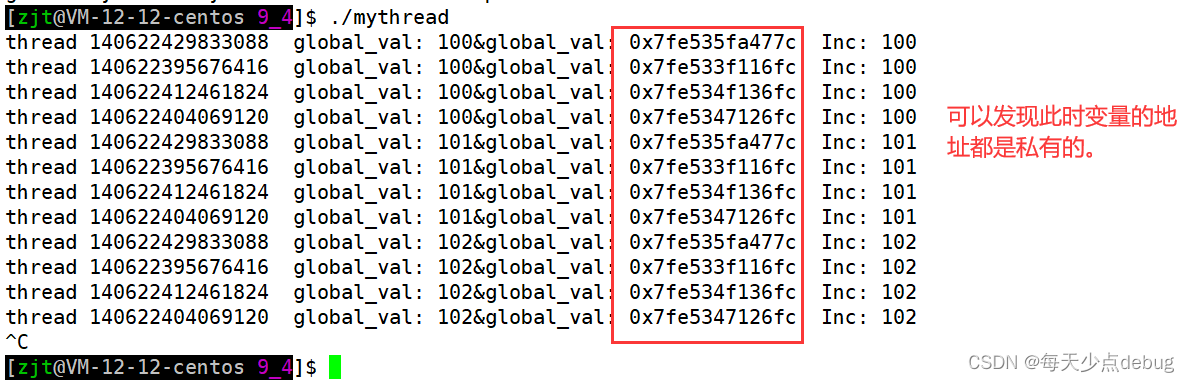
此时三个线程各自私有数据,这叫做线程的局部性存储,可以理解为一旦加了__thread,此时每个线程各自将变量拷贝了一份。
8.线程分离
默认情况下:新创建的线程都是可等待的,线程退出后,需要主线程对其pthread_join,否则无法释放资源吗,从而造成资源的泄露。
但是如果不担心线程的分离,pthread_join反而是一种负担,因为一直要阻塞式的等待线程,无法执行主线程的代码。
#include <pthread.h>
int pthread_detach(pthread_t thread);
线程既可以分离,也可以是其他线程对目标线程分离。但是建议用主线程对支线程进行分离,并且join和线程分离是冲突的,线程分离了就不能等待。
__thread int global_val = 100;
void *startRounte(void *args)
{pthread_detach(pthread_self());while (true){cout << "thread " << pthread_self() << " global_val: " << global_val<< "&global_val: " << &global_val << " Inc: " << global_val++ << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_t tid3;pthread_create(&tid1, nullptr, startRounte, (void *)"pthread 1");pthread_create(&tid2, nullptr, startRounte, (void *)"pthread 1");pthread_create(&tid3, nullptr, startRounte, (void *)"pthread 1");// sleep(1);pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);pthread_join(tid3, nullptr);return 0;
}
上述是一个错误代码,因为线程已经分离了,但是又在后面join了,此时应该会报错,但是运行之后发现

运行的结果非常好,这是因为线程是缺乏访问控制的,有可能主线程先调度,此时其直接阻塞式等待了,压根没有意识到线程分离了,为了避免这个情况,我们应该在主线程上进行线程分离。
__thread int global_val = 100;
void *startRounte(void *args)
{while (true){cout << "thread " << pthread_self() << " global_val: " << global_val<< "&global_val: " << &global_val << " Inc: " << global_val++ << endl;sleep(1);}
}
int main()
{pthread_t tid1;pthread_t tid2;pthread_t tid3;pthread_create(&tid1, nullptr, startRounte, (void *)"pthread 1");pthread_create(&tid2, nullptr, startRounte, (void *)"pthread 1");pthread_create(&tid3, nullptr, startRounte, (void *)"pthread 1");// sleep(1);pthread_detach(tid1);pthread_detach(tid2);pthread_detach(tid3);int n = pthread_join(tid1, nullptr);cout << n << " : " << strerror(n) << endl;n = pthread_join(tid2, nullptr);cout << n << " : " << strerror(n) << endl;n = pthread_join(tid3, nullptr);cout << n << " : " << strerror(n) << endl;return 0;
}

此时就可以显示出非法。








![一、了解[mysql]索引底层结构和算法](https://img-blog.csdnimg.cn/40b63e80d97b4e0caba8e68b4819bc98.png)
