本篇内容来自小米集团数据科学部负责人刘汉武老师的数据特训营笔记。不涉及深入的知识,仅在扫盲。
首先一个问题:大模型和大语言模型的区别是什么?
有人说大模型像是连接数据的星辰,能给我们提供前所未有的见解和洞察。现有的大模型很多,随便一搜,就能看到很多,除却最近大火的GPT,还有专注于常识推理、形式逻辑的PaLM、专门服务于企业的Cohere、目前仅能用于研究的LLaMA…在大语言模型和大模型中,大语言模型的大体现在模型规模和数据量上;而由NLP发展起来的语言模型专注于文字语言的处理。可能在未来会有图像的分支(好像已经有了)
文章目录
- 发展历史
- 大模型一般用途
- 使用大模型
- 使用prompt让下游任务适配大模型
- 模型部署
发展历史
大语言模型基于transform分支发展起来,整体大概可以分为3个大分支。
- 蓝色的部分依赖于transform的解码器,以GPT为代表。GPT是闭源的,该分支下还有开源的LLaMA供研究学习
- 粉色的部分依赖于transform的编码器,以BERT为代表,GPT君临天下之前,BERT横扫江湖
- 绿色的部分既依赖于编码器,又依赖于解码器。其中最强健的两个模型,一个是谷歌T5,另一个是清华大学的GLM
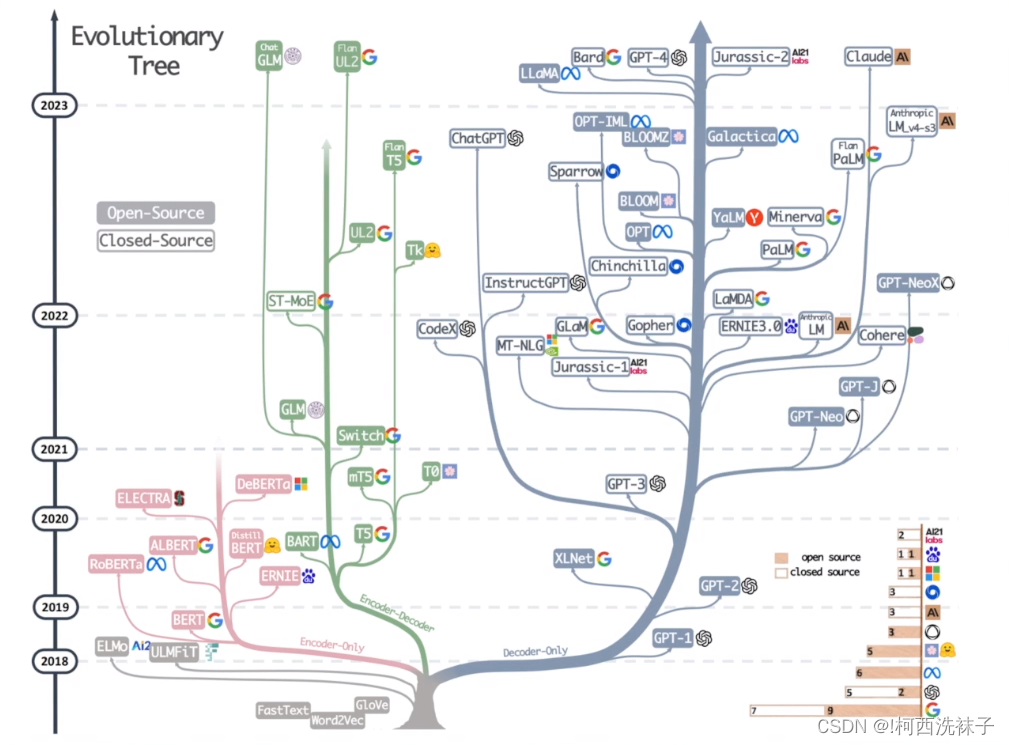
扫盲小知识:BERT和GPT有什么区别
大模型一般用途
大模型发展很快,日常生活中,像我这样的程序员有时候会让他帮忙写代码(bushi),有人用它作为生活管家,有人依赖它对数据进行分析(譬如,生成一些简单的sql语句:我要查询2023年8月某商品的销售量和用户类型)。我们可以简单分为4类:
- 使用者(非研发):譬如用AI写某红书,画画,写作业(不行!作业还是要自己写!)
- 大模型工具开发者(研发):他们需要了解大模型原理,依靠模型进行分布式训练,同时需要处理数据,进行一些模型的开发。典型的成果包括通过预训练大模型数据能捕捉语义规律,产生更自然的文本和图像内容的Monica
- 领域大模型开发者(研发):典型的成果由医疗大模型、交通大模型等等,这类人群利用底层大模型做微调,构建领域的大模型。他们重点关注模型微调的技术,譬如P_Tuning、LoRa、Instruct。需要了解大模型原理
- 基座大模型开发者(研发):典型的基座大模型有OpenAI的ChatGpt、Meta的LLaMA、阿里的通义千问、百度文心一言、小米的MiLM。开发基座大模型,需要精通大模型原理,熟练掌握大规模分布式训练、大规模数据处理的技术。
使用大模型
大模型那么香,那么,我们如何使用大模型呢?
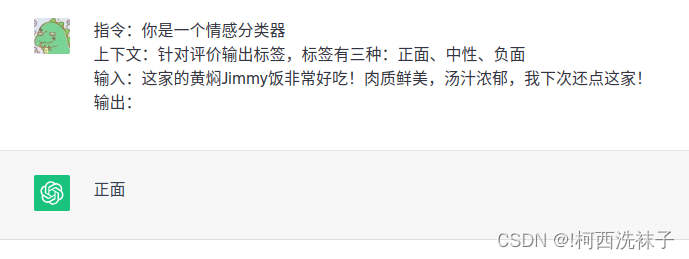
我们做一个场景假设,你开了一家餐厅,并迎来了第一批顾客。他们用餐之后,纷纷在小程序上留下了评论。你想要统计一下有多少顾客满意、多少顾客觉得差点儿意思。
传统的方式不外乎自己或者雇个小弟一条一条看。更科技一些,可以雇个程序员给你写一个分类器。但是如果有了大模型,你只需要对大模型进行调教,就能完成情感分类这个任务。

使用prompt让下游任务适配大模型
从前,针对不同类型的需求,需要训练不同类型的模型。譬如机翻需要训练机翻的模型,情感分析需要训练情感分析的模型。每一次训练需要标注数据、预训练、获取尽可能收益大的特征、调参,才能得到一个对需求有效的模型。而prompt就像一个适配接口,只需要一个大模型,就可以适配不同的任务。
模型部署
我们知道,模型越大,消耗的算力越多,选模型需要选最合适的。因此我们需要通过部署模型进行对比测试,找到最合适的基座大模型。模型部署分5步:
- 搭建开发环境
- 到官网下载模型
- 下载源码
- 安装依赖
- 测试模型的基本能力
–没写完,放个凳子。