《异常检测——从经典算法到深度学习》
- 0 概论
- 1 基于隔离森林的异常检测算法
- 2 基于LOF的异常检测算法
- 3 基于One-Class SVM的异常检测算法
- 4 基于高斯概率密度异常检测算法
- 5 Opprentice——异常检测经典算法最终篇
- 6 基于重构概率的 VAE 异常检测
- 7 基于条件VAE异常检测
- 8 Donut: 基于 VAE 的 Web 应用周期性 KPI 无监督异常检测
- 9 异常检测资料汇总(持续更新&抛砖引玉)
- 10 Bagel: 基于条件 VAE 的鲁棒无监督KPI异常检测
- 11 ADS: 针对大量出现的KPI流快速部署异常检测模型
- 12 Buzz: 对复杂 KPI 基于VAE对抗训练的非监督异常检测
- 13 MAD: 基于GANs的时间序列数据多元异常检测
- 14 对于流数据基于 RRCF 的异常检测
- 15 通过无监督和主动学习进行实用的白盒异常检测
- 16 基于VAE和LOF的无监督KPI异常检测算法
- 17 基于 VAE-LSTM 混合模型的时间异常检测
- 18 USAD:多元时间序列的无监督异常检测
- 19 OmniAnomaly:基于随机循环网络的多元时间序列鲁棒异常检测
- 20 HotSpot:多维特征 Additive KPI 的异常定位
- 21 Anomaly Transformer: 基于关联差异的时间序列异常检测
- 22 Kontrast: 通过自监督对比学习识别软件变更中的错误
相关:
- VAE 模型基本原理简单介绍
- GAN 数学原理简单介绍以及代码实践
- 单指标时间序列异常检测——基于重构概率的变分自编码(VAE)代码实现(详细解释)
22. Kontrast: 通过自监督对比学习识别软件变更中的错误
论文名称:Identifying Erroneous Software Changes through Self-Supervised Contrastive Learning on Time Series Data
论文发表于 ISSRE 2022
论文下载:netman
会议 PPT 下载:netman
源码地址:https://github.com/NetManAIOps/kontrast
22.1 论文概述
这里首先介绍一下论文中每个章节的大体内容:

22.2 相关技术介绍
kontrast 用到的核心技术包括以下几方面,我们逐个介绍,下一个章节介绍它们是如何组合、如何工作的。
22.2.1 自监督学习(Self-supervised learning)
自监督学习 是一种通过自动生成任务或标签来训练模型的方法,允许模型从无标签数据中学习有用的特征和模式。与传统的监督学习方法不同,自监督学习不需要手动标注大量的数据,而是利用数据本身的内在结构或信息来指导模型的学习过程。
在自监督学习中,模型会根据数据中的某种自动生成的信号进行预测。这些信号可以是数据中的部分信息,例如在图像中遮挡住的部分、文本中被遮挡的词语、视频中被剪辑的片段等。通过使模型预测这些自动生成的任务,它会逐渐学习到数据中的有用特征和模式,从而可以在后续任务中更好地泛化。
自监督学习在计算机视觉、自然语言处理和语音处理等领域都得到了广泛的应用。一些自监督学习的应用包括图像中的无监督特征学习、语言模型的预训练、视频理解等。通过自监督学习,研究人员可以减少对人工标注数据的依赖,从而在资源有限的情况下训练出更好的模型。
22.2.2 对比学习(Contrastive learning)
**对比学习(Contrastive Learning)**是一种自监督学习的方法,旨在通过将数据样本与其他样本进行比较,以学习数据中的有用特征。在对比学习中,模型会被要求区分出来自同一类别的样本和来自不同类别的样本,从而学习到数据中的模式和相似性。
对比学习的基本思想 是将数据样本投影到一个特征空间,使得同一类别的样本在特征空间中更加接近,而不同类别的样本则更远离。为了实现这一点,通常会引入一个对比损失函数,该损失函数在同类样本之间施加吸引力,而在不同类样本之间施加排斥力。通过最小化这个损失函数,模型会学习到如何在特征空间中有效地区分不同类别的样本。
对比学习可以应用于各种领域,例如计算机视觉、自然语言处理和语音处理等。在计算机视觉中,对比学习可以用于图像特征学习,使得模型能够学习到图像中的纹理、形状等信息。在自然语言处理中,对比学习可以用于学习词嵌入或句子表示,以捕捉词语和句子之间的语义关系。
22.2.3 长短期记忆网络 (LSTM, Long Short-Term Memory)
长短期记忆网络(Long Short-Term Memory,简称LSTM)是一种特殊的循环神经网络(Recurrent Neural Network,RNN),用于处理序列数据,并且在解决传统RNN中存在的梯度消失和梯度爆炸等问题方面表现出色。
LSTM最初于1997年由Hochreiter和Schmidhuber提出,旨在克服传统RNN的缺陷,特别是在处理长序列时产生的问题。LSTM通过引入三个关键的门控机制,即遗忘门、输入门和输出门,来有效地控制信息的流动,从而更好地捕捉和记忆长期的依赖关系。
以下是LSTM中的三个关键门控机制的简要解释:
- 遗忘门(Forget Gate):决定了在当前时间步中哪些信息应该被遗忘,以便更好地适应新的输入。遗忘门的输出范围在0到1之间,0表示完全忘记,1表示完全保留。
- 输入门(Input Gate):决定了在当前时间步中哪些新的信息应该被添加到细胞状态(cell state)中。输入门通过使用一个sigmoid函数来决定哪些信息应该更新。
- 输出门(Output Gate):决定了当前时间步中细胞状态的哪些部分应该作为输出。输出门的输出是经过一个sigmoid函数的细胞状态乘以一个tanh激活函数的结果。
这些门控机制使得LSTM能够在序列数据中更好地捕捉长期依赖关系,而不受传统RNN中梯度消失和梯度爆炸问题的困扰。LSTM在许多序列相关的任务中表现出色,如自然语言处理、语音识别、机器翻译等。
22.2.4 伪标记(Pseudo-labeling)
“伪标记”(Pseudo-labeling) 是一种半监督学习的技术,用于训练模型,尤其在标注数据有限的情况下。在半监督学习中,我们通常有一小部分有标签的数据和大量无标签的数据。伪标记的主要思想是,使用模型对无标签数据进行预测,并将这些预测作为“伪标签”来扩充训练数据,从而提供额外的监督信号。
伪标记的步骤通常如下:
使用已有的有标签数据训练一个模型。
使用训练好的模型对无标签数据进行预测,得到伪标签。
将带有伪标签的无标签数据与有标签数据合并,形成一个更大的训练数据集。
使用这个扩充后的数据集重新训练模型。
重复上述步骤多次,逐渐提升模型性能。
伪标记的核心观点是,尽管伪标签可能存在一些误差,但通过将无标签数据与伪标签纳入训练,模型可以从更多的数据中学习,并在某些情况下提高性能。这种方法特别适用于那些标注数据稀缺的任务,因为它允许模型从未标注的数据中汲取信息。
伪标记并不总是适用于所有场景。在使用伪标记时,需要小心控制伪标签引入的误差,并监控模型在验证集或测试集上的性能,以确保性能提升而不是退步。
22.2.5 数据增强(Data augmentation)
**数据增强(Data Augmentation)**是一种用于扩充训练数据集的技术,特别在机器学习和深度学习中广泛应用。数据增强通过对原始训练数据进行一系列变换或扰动,生成新的样本,从而增加训练数据的多样性和丰富性。这有助于提升模型的泛化能力,减少过拟合,并提高模型在真实世界中的性能。
数据增强可以应用于各种类型的数据,包括图像、文本、音频等。以下是一些常见的数据增强技术:
图像数据增强: 在图像处理中,数据增强技术可以包括随机裁剪、旋转、翻转、缩放、亮度调整、色彩变换等。这些变换可以模拟不同的视角、光照条件和噪声,增加模型对各种情况的适应能力。
文本数据增强: 在自然语言处理中,数据增强可以包括词汇替换、句子重排、插入或删除词语、同义词替换等。这些变换可以帮助模型更好地处理词汇多样性和语法结构的变化。
音频数据增强: 在音频处理中,数据增强技术可以包括音频变速、变调、添加噪声、截断等。这些变换可以提高模型对于不同录制条件和环境噪声的适应性。
数据增强的目标 是在不改变数据的本质特征的情况下,引入一些变化,使得模型能够更好地捕捉数据中的模式和结构。通过引入更多的变化,模型将学会更加鲁棒地处理新的、未见过的数据。然而,需要注意的是,数据增强不能无限制地应用,因为过度的增强可能导致生成不真实的样本,从而影响模型的训练效果。
22.3 经验研究(EMPIRICAL STUDY)
我们对真实世界的数据进行了实证研究,以了解工业环境中的软件变更实践。本节显示了我们对软件变更的观察结果以及错误软件变更识别的当前实践。由于安全和隐私问题,本研究中报告的确切数字被掩盖。
22.3.1 数据收集
我们手动分析了全球数据中心在两年期间的更改单和事件报告。每个变更单记录软件变更的部署周期、变更目标、变更的系统等。
为了识别错误的软件变更,操作员需要在软件变更后密切监测大量KPI。软件变更频繁,尤其是对于那些关键应用程序。软件变更的每日计数如图1(a)所示,其峰值约为一千。由于数据中心的稳定性至关重要,因此软件更改的频率为每两周一次。可能有超过两百个应用程序同时部署软件变更。对于一个应用程序来说,有数百个实例来保持高可用性。一旦部署了特定应用上的软件改变,运营商就使用数百个系统级(例如,CPU使用率)和服务级别(例如事务计数)KPI来监视其实例并了解其运行状态。考虑到所有因素,对于软件变更,操作员应检查一万多个KPI。因此,在峰值期间需要同时检查多达200万个KPI。运营商希望在出现重大损失之前识别错误的软件更改;即识别错误软件改变的算法的时间仅限于几分钟。
软件更改部署过程。软件变更部署过程如图 2 所示。由于应用程序的规模巨大,因此完成所有部署操作需要一些时间。这个时间在我们的论文中被称为进行期,其分布如图所示。第 1 (b) 段。在进行期间,我们注意到一些KPI时间序列不规则地受到软件更改的影响,这可能是由服务重启、流量转移等引起的。我们将 t 0 t_0 t0 表示为软件更改的开始时间点, t 1 t_1 t1 表示为完成时间点,进行期间是 t 0 t_0 t0 和 t 1 t_1 t1 之间的时间段。 t 1 t_1 t1 表示所有相关 KPI 已经达到由输入给出的稳定性的时间。我们称 t 0 t_0 t0 之前的时段为变化前时段, t 1 t_1 t1 之后的时段为变后时段。
22.3.2 在线服务系统中的软件变更 (Software Changes in the Online Service System)
软件变更 是在线服务系统的重要组成部分。在线服务系统由数千个应用程序组成,每个应用程序支持一组特定的在线服务。软件变更的典型类型包括错误修复、新功能增强、配置更新等。
为了识别错误的软件变更,操作员需要在软件变更后密切监测大量KPI。软件变更频繁,尤其是对于那些关键应用程序。软件变更的每日计数如图所示。1(a),其峰值约为一千。由于数据中心的稳定性至关重要,因此软件更改的频率为每两周一次。可能有超过两百个应用程序同时部署软件更改。对于一个应用程序来说,有数百个实例来保持高可用性。一旦部署了特定应用上的软件改变,运营商就使用数百个系统级(例如,CPU使用率)和服务级别(例如事务计数)KPI来监视其实例并了解其运行状态。考虑到所有因素,对于软件变更,操作员应检查一万多个KPI。因此,在峰值期间需要同时检查多达200万个KPI。运营商希望在出现重大损失之前识别错误的软件更改;即识别错误软件改变的算法的时间仅限于几分钟。
软件更改部署过程。软件变更部署过程如图2所示。由于应用程序的规模巨大,因此完成所有部署操作需要一些时间。这个时间在我们的论文中被称为进行期,其分布如图所示。第1(b)段。在进行期间,我们注意到一些KPI时间序列不规则地受到软件更改的影响,这可能是由服务重启、流量转移等引起的。我们将t0表示为软件更改的开始时间点, t 1 t_1 t1 表示为完成时间点,进行期间是 t 0 t_0 t0 和 t 1 t_1 t1 之间的时间段。 t 1 t_1 t1 表示所有相关 KPI 已经达到由输入给出的稳定性的时间。我们称 t 0 t_0 t0 之前的时段为变化前时段, t 1 t_1 t1 之后的时段为变后时段。
22.3.3 当前实践中错误的软件变更识别方法 (Erroneous Software Change Identification Approaches inCurrent Practice)
由于在线服务系统通常具有其自己的服务水平目标(SLO),因此操作员密切监视KPI时间序列中的异常。在数据中心中,若干监视系统(例如,Prometheus [15])从相关服务实例收集KPI时间序列数据。一旦几个与变更相关的KPI时间序列被视为异常,则将发出事件通知单,将软件变更标记为错误,需要操作员立即注意。错误软件更改的根本原因包括代码逻辑错误、配置错误、SQL查询速度慢等。其中每一个具有关于其相关KPI的一组特定模式。由于权限问题,我们无法在此处显示详细的根本原因分析结果。
运营商目前识别异常KPI的方法相对简单:将变更后的KPI时间序列段(通常是部署后的短时间段)与变更前的KPI时间序列段(变更后的时间序列段的同期历史数据或部署前的短时间段)进行比较,检查KPI时间序列段是否接近。一些轻量级比较算法,如t检验,k-sigma [13]和核密度估计(KDE)[16],用于满足效率要求。然而,这些算法的准确性是不令人满意的,因为这些基于统计的算法忽略了KPI时间序列的顺序信息。因此,作为识别过程的关键补充,需要对当前算法的输出进行手动验证以实现合理的准确性。操作员基于他们的领域知识来判断KPI时间序列,这主要受KPI的物理含义的影响。例如,他们对待成功率比对待内存使用更严格;成功率下降10%被认为是异常的,而内存使用率下降10%则不是。然而,由于当前方法错误警报的KPI时间序列数量过大,人力远远不够。
此外,识别错误软件更改的常见方法[8],[10]无法处理跨数据集适应情况。在新应用程序上运行时,很少有历史数据。因此,难以确定这些方法的参数。在这种情况下,操作员很少有适当的工具来识别错误的软件更改。然而,自适应模型可以从其他系统的软件更改数据中学习一般的异常模式,从而在这个新的应用中做出准确的决策。
总之,所需的错误软件变更识别模型应满足以下所有要求。1) 效率很高该模型应该能够在短时间内以低延迟处理大量KPI。2) 准确。稳定性是在线服务系统的首要考虑因素。因此,准确地识别错误的软件变更是至关重要的。3) 适应性。基于一个应用程序训练并可用于另一个应用程序的模型是优选的。由于目前的方法无法满足所有的要求,我们提出了 Kontrast,旨在提供一个解决方案,满足所有的需求。
22.4 核心方法 APPROACH
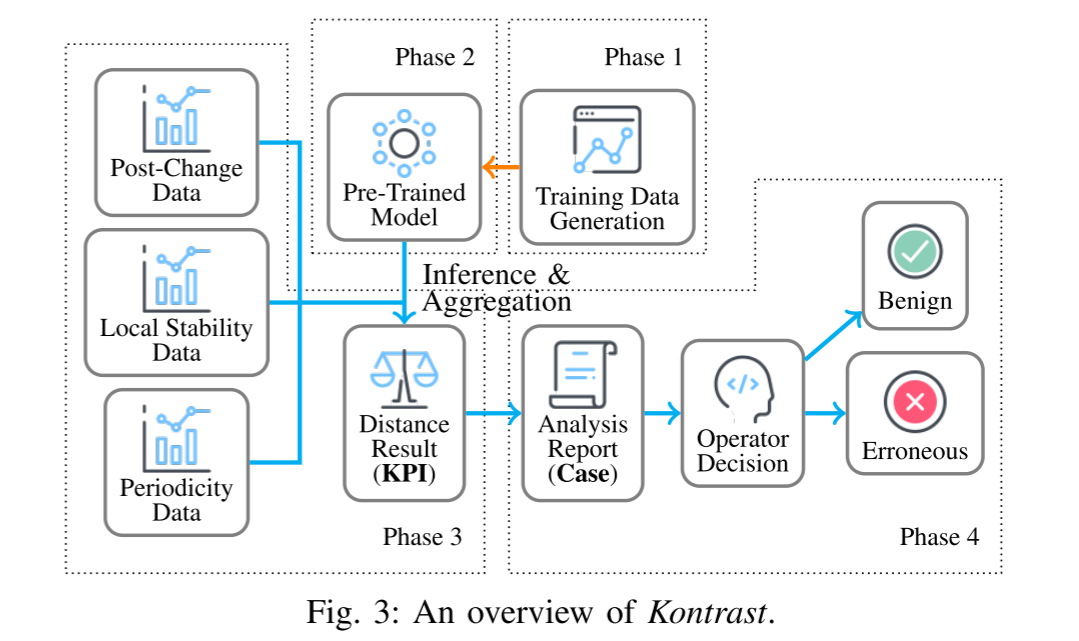
我们提出了一种新的方法称为 Kontrast。在 Kontrast 中,我们首先判断每个与变更相关的KPI时间序列在变更部署后是否正常。然后根据软件变更相关KPI的结果,判断软件变更是否引入缺陷。图3 示出了 Kontrast 的概览。
Kontrast由四个阶段组成。1) 为了处理标记数据的缺乏,我们应用噪声模式注入来生成用于模型训练的伪标记KPI时间序列段对(第III-B节)。2) 在第1阶段生成的数据的基础上,我们训练了一组通用的基于比较的模型(第III-C节)。3) 当部署软件变更时,我们提取特定的变更后KPI时间序列段(KPI时间序列的连续片段),并使用阶段2中的模型将其与变更前KPI时间序列段进行比较(第III-D节)。4) 我们汇总结果以判断软件变更是否错误,并将报告发送给操作员(第III-D节)。
在介绍这四个阶段之前,我们首先展示了KPI时间序列段的数据提取规范。
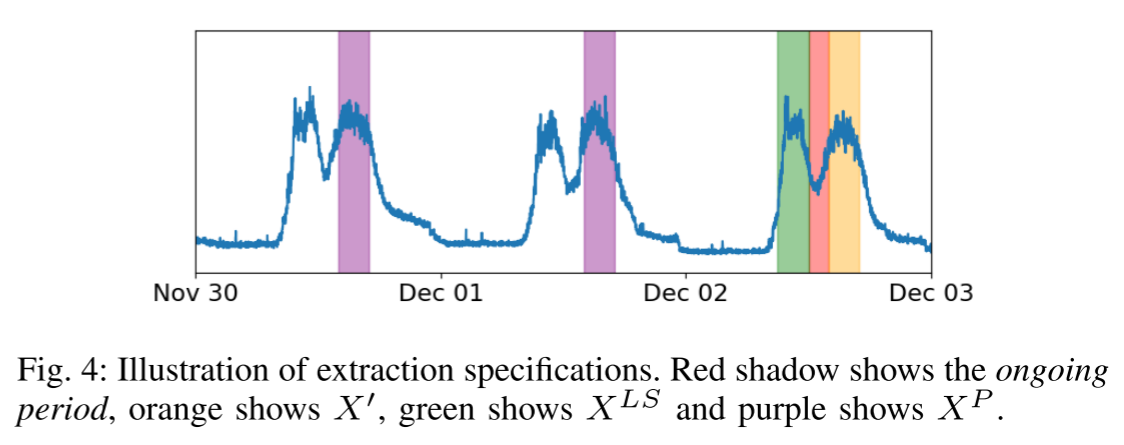
22.4.1 数据提取规范 Data Extraction Specifications
我们发现,一个正常的KPI时间序列大致表现出两个属性:周期性[17],[18]和局部稳定性[19]通过经验观察。在现实世界的生产环境中,大部分KPI遵循一定的周期性,在许多其他作品中也称为季节性KPI [20]-[22]。这些KPI与用户行为和人们的作息规律密切相关。为了确保KPI时间序列在软件变更后是预期的,检查它是否保持其周期性是必不可少的。如果不是,则KPI时间序列福尔斯异常状态,指示从软件变更过程引入的潜在缺陷。
另一个观察是KPI时间序列在典型情况下很少突然改变。每当一个突然的变化发生,异常很可能揭示[9],[20]。在我们的论文中,这个属性被称为局部稳定性。基于此观察,如果软件变更是良性的且相对较短,则在软件变更之前和之后应保持局部稳定性。此外,根据我们对运营商的采访,季节性和非季节性KPI都具有局部稳定性。
然后,我们从KPI时间序列中提取以下三个部分来验证属性:
-
X ′ X^{'} X′: 假设软件变更从 t 0 t_0 t0 开始,到 t 1 t_1 t1 结束,我们可以根据 { x t 1 + 1 , x t 1 + 2 , ⋯ , x t 1 + ω − 1 , x t 1 + ω } ) \left.\left\{x_{t_1+1}, x_{t_1+2}, \cdots, x_{t_1+\omega-1}, x_{t_1+\omega}\right\}\right) {xt1+1,xt1+2,⋯,xt1+ω−1,xt1+ω}) 得到变更后的 KPI 时间序列数据,记作 X ′ X^{'} X′ ,这里 X X X 是 KPI 时间序列, ω \omega ω 是检查窗口大小。
-
X P X^{P} XP:标记 T T T 是给定 KPI 时间序列的周期,即 T T T 是一般模式的重现的最小间隔。我们的模型将 T T T 作为一个给定的输入值,这个值可以很容易地推断专家知识或自相关算法,这是我们的研究领域。通常在业务场景中,包括我们的场景, T T T 的长度是一天时间。我们使用 { X [ t 1 + 1 − δ , t 1 + ω − δ ] ∣ δ ∈ Δ } \left\{X\left[t_1+1-\delta, t_1+\omega-\delta\right] \mid \delta \in \Delta\right\} {X[t1+1−δ,t1+ω−δ]∣δ∈Δ},其中 Δ \Delta Δ 包含一组时间间隔,通常包括 1 T 1T 1T、 2 T 2T 2T、 3 T 3T 3T、 7 T 7T 7T、 14 T 14T 14T、 21 T 21T 21T 等。例如,如果软件变更在星期一部署,则来自上周五 3 T 3T 3T 的同期数据反映工作日的最新模式,并且来自周末 1 T 1T 1T, 2 T 2T 2T )的同期数据显示最新模式,来自过去的星期一( 7 T 7T 7T, 14 T 14T 14T, 21 T 21T 21T)的同期数据反映可能由于每周调度的任务而导致的每周模式。对于每个方面,三个样本足以反映各自的模式,因为 Kontrast 使用最小距离作为聚合策略(第III-D节)。因此,反映正常模块的任何一个样本都是足够的。
我们收集这些 KPI 时间序列片段并将其表示为 X P X^P XP ,这里 . P .^P .P 是周期性的缩写。 -
X L S X^{LS} XLS:我们提取 X [ t 0 − ω , t 0 − 1 ] X[t_0 − \omega,t_0 − 1] X[t0−ω,t0−1] 作为 X L S X^{LS} XLS,它显示软件变更部署之前的数据模式。将 X L S X^{LS} XLS 与 X P X^{P} XP 进行比较,证明了 X L S X^{LS} XLS 的局部稳定性。这里 ⋅ L S ·^{LS} ⋅LS 是局部稳定性的缩写。
到目前为止,我们得到了 X P X^P XP, X L S X^{LS} XLS 和 X ′ X' X′。检查 X ′ X' X′ 是否遵循由 X P XP XP 和 X L S X^{LS} XLS 推断的模式,我们可以确定KPI时间序列是否异常。提取阶段的简要说明见 图 4。
22.4.2 训练数据生成 Training Data Generation
为了在Kontrast中训练对比学习模型,我们首先需要收集包含相似和不相似KPI时间序列片段对的标记训练数据。然而,手动标记大规模训练数据是昂贵且耗时的,因此不现实。自监督学习是通过创建自定义伪标签作为监督并学习数据的表示来解决这个问题的合适工具。受此启发,我们提出了一种新的数据增强方法,其架构如图 5 所示,它使用变更前的KPI时间序列数据,并生成足够的伪标签数据,正(不相似)和负(相似),用于模型训练。这一办法包括两个主要组成部分,介绍如下。
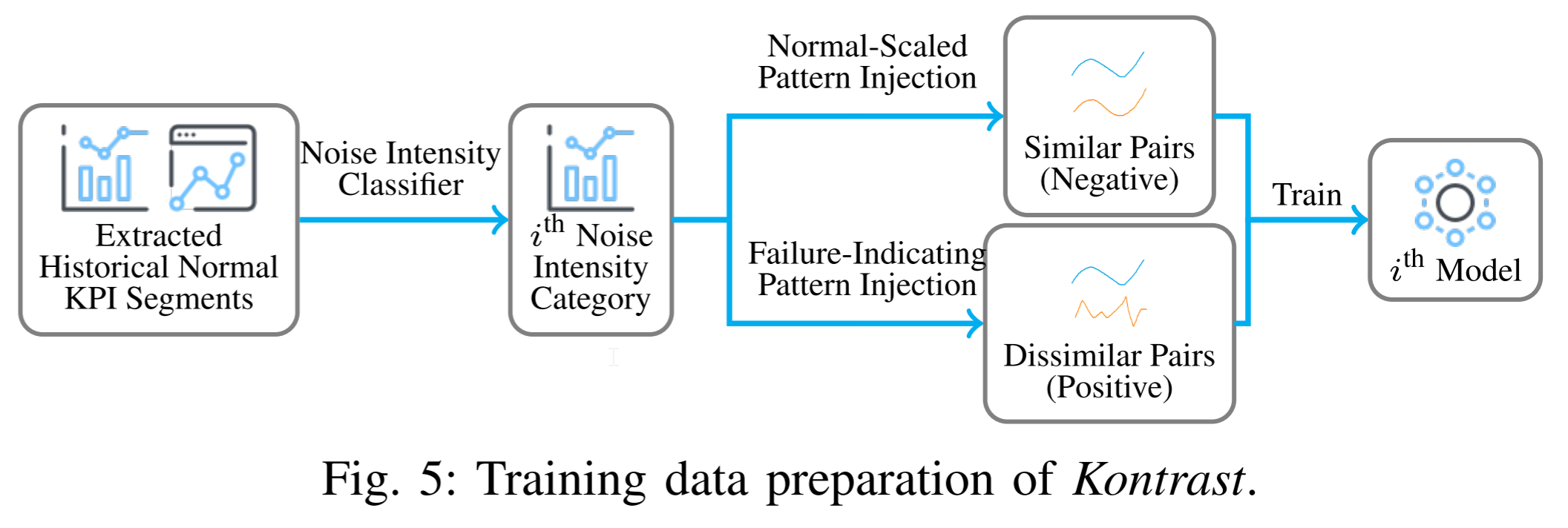
- 噪声强度分类器(Noise Intensity Classifier):具有不同物理意义的 KPI 时间序列可能具有不同的异常标准。即使对于从不同服务实例收集的共享相似物理含义的 KPI,异常模式也可能是不同的。因此,使用单个模型来处理所有 KPI 是不现实的。因此,我们需要首先进行一个简单而有效的分类,将KPI时间序列按其历史特征分为几类,并使用不同的标准进行检查。
为此,需要噪声强度分类器。将噪声强度N表示为特定时间点的数据与其他时段的相同时间点的数据之间的偏差。时间序列的总体噪声强度是每个特定时间点的平均噪声强度,如式子(1)所示:
在公式(1)中, std ( ⋅ ) \operatorname{std}(\cdot) std(⋅) 表示标准偏差函数, N X N_X NX 表示 KPI 时间序列 X X X 的噪声强度。 X X X 中的每一个等级强度衍生出一个 N X N_X NX,我们将所有的KPI时间序列根据它们的 N N N 分为 K K K 类。KPI 时间序列的噪声强度隐含着其异常判断阈值。我们构建了一个数据集,并为每个噪声强度类别训练了一个专用模型。
N X , i = std ( X i , X i + T , X i + 2 T , ⋯ ) N X = 1 T ∑ i = 0 T − 1 N X , i (1) \begin{aligned} N_{X, i} & =\operatorname{std}\left(X_i, X_{i+T}, X_{i+2 T}, \cdots\right) \\\tag{1} N_X & =\frac{1}{T} \sum_{i=0}^{T-1} N_{X, i} \end{aligned} NX,iNX=std(Xi,Xi+T,Xi+2T,⋯)=T1i=0∑T−1NX,i(1)
-
对选择和噪声模式注入:每种噪声强度类别的数据生成过程是相似的,因此我们以一个类别为例。
我们的目标是建立一个数据集包含相似和不相似的时间序列段对。我们的解决方案是从未标记的KPI时间序列构建伪标记对。由于 X P X^P XP 和 X L S X^{LS} XLS 的模式不一样,我们应该建立一个模型来比较 X ′ X' X′和 X P X^{P} XP,另一个模型来比较 X ′ X' X′ 和 X L S X^{LS} XLS,分别称为 P P P 模型和 L S LS LS 模型。
首先,我们介绍了P模型的数据生成方法。基于时间序列的周期性,我们从一个KPI时间序列中随机选取这些同期对来模拟 X P X^P XP 和 X ′ X' X′ ,旨在覆盖KPI时间序列中所有可能的时间跨度,提高数据集的全面性。对于异常案例,方法是双重的。第一种方法是随机选择配对,忽略时间信息。第二种方法是选择一个随机片段并注入强烈的噪声,使其与原始模式不同。还需要简单的欧几里德距离滤波来确保对确实不相似。此外,为了提高对比模型的鲁棒性,温和的和特定于噪声类别的噪声应该被注入到所选择的数据对中,无论是在阳性情况下还是阴性情况下。
-
对于 L S LS LS 模型,方法类似。唯一的区别是负情况生成方法中的配对选择方法。这里,选择从任意时间点开始的随机长度的持续时段。将其正面和背面提取为负对,模拟 X L S X^{LS} XLS 和 X ′ X' X′。
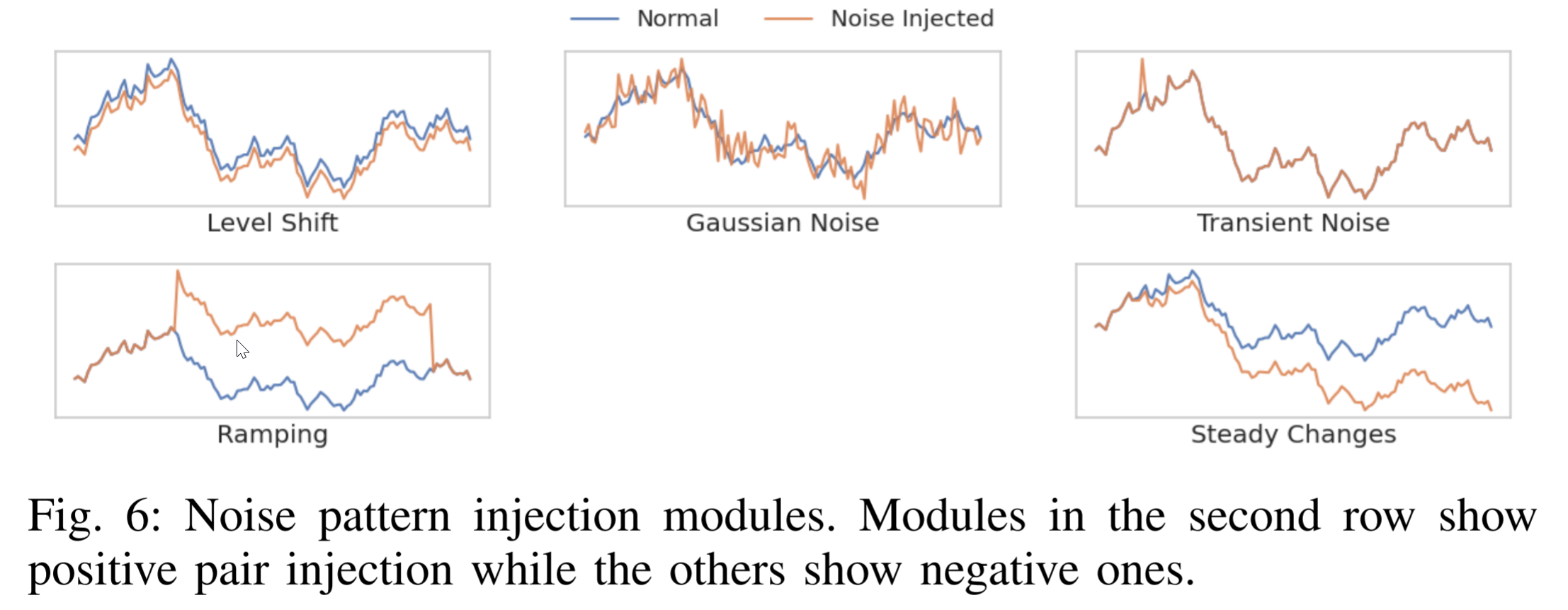
噪声模式注入方法由几个模块组成,每个模块注入一种故障模式。我们参考 [24] 并使用其中的故障模式,并总结了我们的噪声模式注入的五个模块,即电平偏移,高斯噪声,瞬态噪声,斜坡和稳态变化。它们的模式示范可以在图6 中找到这些模块并不相互排斥,我们在一个KPI时间序列上使用了多个模块。随机生成噪声模式注入的强度,旨在覆盖从最轻微到最强的噪声强度。
22.4.3 模型设计 Model Design
为了确定KPI时间序列变化后是否异常,我们提出了一种新的对比学习模型进行比较。如前所述,给定处理后的KPI时间序列,接下来分别检查 X ′ X' X′ 与 X P X^P XP、 X ′ X' X′ 与 X L S X^{LS} XLS 之间的相似性。如果 X ′ X' X′ 不遵循由 X P X^P XP 和 X L S X^{LS} XLS 推断的模式,则 KPI 时间序列被判断为异常。神经网络架构应用于比较时间序列段。这是因为神经网络可以拟合任意复杂度的分布,包括对时间序列模式的复杂特征进行编码。此外,神经网络支持批量测试,大大提高了并行度。我们模型的核心思想是使用长短期记忆(LSTM)[25] 作为特征提取器,Siamese 网络架构作为比较器,以伪标记时间序列对为基础,学习时间序列的相似度计算原理,如图 7 所示。
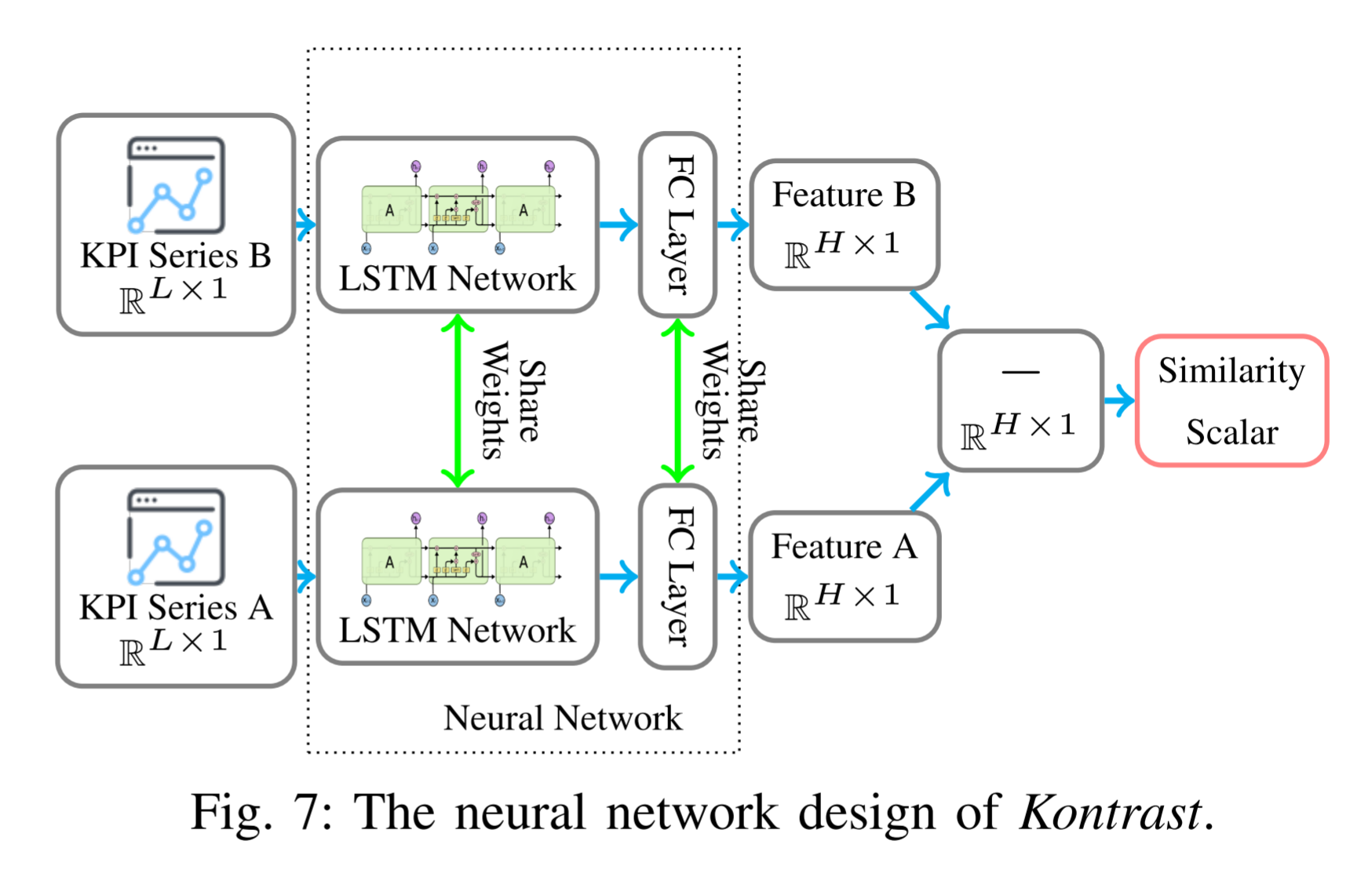
Siamese 网络[26] 使用协变量共享特征提取器同时解析两个输入序列,产生两个特征。这是一个用于比较两个对象的经典模型。在 [27] 中引入的对比损失函数(式子 2)影响暹罗网络的输出沿着提供的标签。它强制特征提取器学习标签 Y Y Y 为0(负情况)时的时间序列数据的相似性和标签为1(正情况)时的差异。这里 M M M 表示避免过拟合的 m a r g i n margin margin 。 x 1 → \overrightarrow{x_1} x1, x 2 → \overrightarrow{x_2} x2 是输入样本, L ( F , ⋅ , ⋅ , ⋅ ) \mathcal{L (F, \cdot, \cdot,\cdot)} L(F,⋅,⋅,⋅) 是使用神经网络设置 F \mathcal{F} F 的编码的对比损失函数。
L ( F , Y , x 1 → , x 2 → ) = ( 1 − Y ) 1 2 ( ∥ F ( x 1 → ) − F ( x 2 → ) ∥ 2 2 ) + ( Y ) 1 2 ( max { 0 , M − ∥ F ( x 1 → ) − F ( x 2 → ) ∥ 2 } ) 2 (2) \begin{aligned} \mathcal{L}\left(\mathcal{F}, Y, \overrightarrow{x_1}, \overrightarrow{x_2}\right)= & (1-Y) \frac{1}{2}\left(\left\|\mathcal{F}\left(\overrightarrow{x_1}\right)-\mathcal{F}\left(\overrightarrow{x_2}\right)\right\|_2^2\right)+ \\ & (Y) \frac{1}{2}\left(\max \left\{0, M-\left\|\mathcal{F}\left(\overrightarrow{x_1}\right)-\mathcal{F}\left(\overrightarrow{x_2}\right)\right\|_2\right\}\right)^2 \end{aligned} \tag{2} L(F,Y,x1,x2)=(1−Y)21( F(x1)−F(x2) 22)+(Y)21(max{0,M− F(x1)−F(x2) 2})2(2)
LSTM处理复杂时间序列数据的能力已经被许多新兴的方法所证明[8],[28]。受LSTM有效性的启发,我们将其应用于并行地从两个输入时间序列中提取关于形状和模式的丰富信息。来自Siamese网络的双塔架构需要在训练和测试期间共享来自两个特征提取器的参数。从而统一了KPI时间序列中提取有用信息的标准。然后,特征提取器的输出被发送到完全连接的模块,编码,并转换为距离可比较的表达式。在训练阶段,将全连接层的输出发送到(2);而在测试阶段,两个输入样本之间的距离通过简单的减法获得,即:
D ( F , x 1 → , x 2 → ) = ∥ F ( x 1 → ) − F ( x 2 → ) ∥ 2 2 (3) \mathcal{D}\left(\mathcal{F}, \overrightarrow{x_1}, \overrightarrow{x_2}\right)=\left\|\mathcal{F}\left(\overrightarrow{x_1}\right)-\mathcal{F}\left(\overrightarrow{x_2}\right)\right\|_2^2 \tag{3} D(F,x1,x2)= F(x1)−F(x2) 22(3)
其中 D ( F , ⋅ , ⋅ ) \mathcal{D(F, \cdot,\cdot)} D(F,⋅,⋅) 是神经网络设置 F \mathcal{F} F 的距离函数。
在获得KPI时间序列段对的距离函数结果之后,接下来,我们应该将结果聚合为异常KPI的判决。
22.4.4 错误软件变更 Erroneous Software Change Identification
部署软件变更后,将向 Kontrast 发送多个相关 KPI,请求检查。这里被监视的 KPI 包括更新的服务和受影响的服务中的 KPI,即上游和下游服务。每个输入 KPI 时间序列根据其历史特征划分为特定的噪声强度类别 c c c,然后进行数据提取,得到其 X P X^P XP、 X L S X^{LS} XLS 和 X ′ X' X′。
然后,我们使用噪声强度类别 c c c 的预训练的 P P P 模型和 L S LS LS 模型(即, F c P \mathcal{F_c^P} FcP 和 F c L S \mathcal{F_c^{LS}} FcLS)来获得它们的距离预测。由于存在多个 X P X^P XP ,我们有一系列 D ( F c P , X i P , X ′ ) \mathcal{D(F^P_c,X^P_i,X')} D(FcP,XiP,X′) 。我们使用式子(4)来得到距离函数的最终结果:
pred = min i { D ( F c P , X i P , X ′ ) } + α D ( F c L S , X L S , X ′ ) (4) \text { pred }=\min _i\left\{\mathcal{D}\left(\mathcal{F}_c^P, X_i^P, X^{\prime}\right)\right\}+\alpha \mathcal{D}\left(\mathcal{F}_c^{L S}, X^{L S}, X^{\prime}\right) \tag{4} pred =imin{D(FcP,XiP,X′)}+αD(FcLS,XLS,X′)(4)
其中 α \alpha α 是超参数,将来自两个模型的结果融合为统一的最终距离结果 p r e d pred pred。我们使用基于观察的最小函数:一些历史数据可能包含异常;因此,如果 X ′ X' X′ 与其同期时间序列段之一相似,则认为它是正常的。如果 p r e d pred pred 大于预设阈值,则 KPI 时间序列异常。最后,如果一定数量的 KPI 系列被认为是异常的,则该改变将被认为是错误的。在这种情况下,将发出警报并立即报告给操作员。
22.5 论文实验
为了证明 Kontrast 的上级性能和适应性,我们进行了实验来回答以下研究问题 ( R Q s RQ_s RQs)。
- RQ1:Kontrast 的性能如何?
- RQ2:Kontrast 的时间效率是多少?
- RQ3:Kontrast如何适应不同的数据集?
- RQ4:主要组件对Kontrast的性能有何贡献?
- RQ5:相关超参数的影响是什么?
22.5.1 实验设置
-
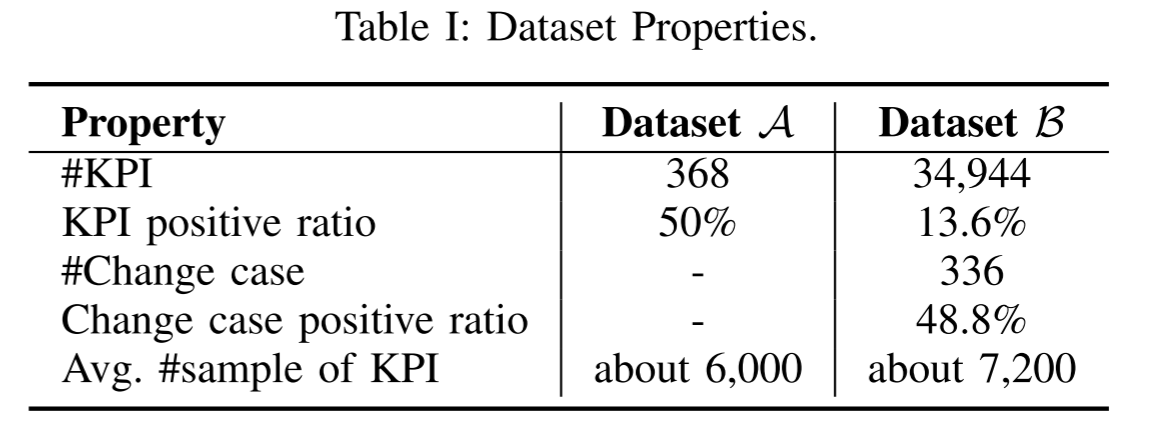
Dataset:为了评估 Kontrast 的性能,我们准备了两个不同的数据集 A \mathcal{A} A 和 B \mathcal{B} B。数据集 A \mathcal{A} A 包含 368 个 KPI 时间序列,而数据集 B \mathcal{B} B 包含 336 个软件变更案例和 34,944 个相关 KPI 时间序列。
数据集 A \mathcal{A} A 基于AIOps 2018 Challenge [29],这是一个用于异常检测的公共数据集,已被广泛用于分析时间序列[30]-[32]。由于原始数据集只有每个时间点的异常标签(正常/异常),而没有软件变更信息,因此需要预处理步骤将其应用于我们的任务。为了生成阳性情况,我们首先提取连续的正常段,然后是异常段。然后,我们在正常段的尾部随机选择一个点作为“软件变更时间点”。该点之前的正常段为变更前阶段,该点之后的正常段和异常段均为变更后阶段,模拟软件变更结束后某个时间发生的故障。这是基于观察到数据集 A \mathcal{A} A 中的异常模式与第 V-A 节中错误软件变更案例中的异常模式相似。对于阴性情况,我们在正常节段内安排软件变更时间点,并确保在随机长度的变更后期间没有失败。注意,数据集 A \mathcal{A} A 中的KPI时间序列段对是单独的;因此,在每种情况下不存在软件变更情况信息,并且其仅用于KPI级实验。数据集生成过程重复3次,无需人工干预。对数据集 A \mathcal{A} A 的结果进行平均以减少随机性的影响。
数据集 B \mathcal{B} B 是从一个流行的 [33]-[35] 微服务基准测试系统上的数百个变更部署实验中收集的:[36] 第三十六话基于微服务的架构允许我们将错误的软件更改注入各种微服务。关于在我们的实证研究中分析的错误软件更改的根本原因,我们实现了32个不同的有问题的微服务版本,例如,在服务源代码中添加死循环、修改服务的网络配置、在SQL查询函数中附加额外的随机延迟等。对于每个软件变更案例,基于 Kubernetes [37] 执行特定微服务的版本切换。Prometheus [15] 持续收集与变更相关的KPI时间序列数据。对于每个软件变更案例,一个随机长度的持续时间遵循图1中的分布。1(B) 存在。收集的 KPI 包括CPU使用率、内存使用率、网络流量率、服务成功率、事务计数和事务应答时间成本。两个作者独立标记的KPI段异常或不评估的性能 Kontrast 在异常的 KPI 识别。通过讨论解决了贴标过程中的分歧。
数据集的详细信息见表 I。
-
指标:我们的实验包含两个任务。一个是分类KPI是否异常,另一个是预测软件更改是否错误,这两个都是二元分类任务。前者是后者的基础,因此单独进行了实验。我们将异常 KPI 或错误的软件变更案例视为积极样本,使用精确度、召回率和 F1-score 来报告绩效。此外,我们测量了Kontrast和其他比较方法的训练时间和测试时间,以评估效率。注意,由于数据集 A \mathcal{A} A 中没有变更案例信息,因此我们不会对数据集 A \mathcal{A} A 执行错误的软件变更识别。
2.5.2 对比算法
比较的方法可以分为三类:
- 端到端(end-to-end)错误软件变更识别方法取软件改变信息(即,软件变更部署时间、相关KPI)作为输入,并识别软件变更是否错误。
- SCWarn [8] :基于多变量LSTM的最新错误软件变更识别算法;
- Gandalf [10]:使用Holt-Winters [38] 的端到端安全部署框架。
- 直接比较时间序列的比较方法(即,DTW(Dynamic Time Warping)[39]、Pearson 相关系数、Lumos [40]、 TS-CP 2 \textbf{TS-CP}^2 TS-CP2 [41]);他们的核心思想是计算两个时间序列的相似性(在软件更改之前和之后),这与 Kontrast 相似。我们使用它们作为我们在第 III-C 节中介绍的 Siamese 网络模块的替代品,分别为这些算法构建了一个 P 模型和一个 LS 模型。
- 根据 [8] 的转换,适应我们的任务的异常检测方法;变点检测方法 Funnel [9]、单变量时间序列异常检测方法 Donut [20]和多变量时间序列异常检测 USAD [28]。我们之所以选择它们,是因为它们具有代表性,并在相应的任务中得到广泛应用。他们使用整个KPI时间序列作为输入,并为每个时间点输出一个值,指示异常分数。我们称这些转换后的方法为 Funnel*、Donut* 和 USAD*。
2.5.3 实现和参数
我们建立了一组 Kontrast 的 P 和 LS 模型,最后对模型的结果进行了汇总。根据我们的实验,我们将 #noise 噪声强度类别 K K K 设置为 5,并且噪声强度分类的阈值为 0.005、0.03、0.1、0.3 和 1。实验结果表明,阈值的选择不敏感。因此,由于页数限制,我们不提供实验结果。对于每个噪声强度类别,我们生成了40,000个正KPI时间序列片段对和40,000个负KPI时间序列片段对。对于LSTM模块,我们使用双向LSTM(BiLSTM)[42],其隐藏大小为30。全连接(FC)模块包含两层,用于将LSTM的输出转换为固定长度的向量。它们的隐藏大小设置为30。数据提取过程中的时间间隔设置为1T、2T、3T、7T、14T、21T。在训练期间使用Adam优化器,具有0.001的恒定学习率。批大小为10,000,epoch的数量为100。对于包括基线在内的所有模型,如果损失值收敛或每个KPI的总计算时间超过10秒,则中止训练或测试。在结果聚合中,我们根据实验结果设置 α \alpha α = 2.5。
我们使用[8],[9],[20],[28],[41]中的参数及其开源代码进行比较。为了提高可重复性,我们在GitHub上开源了我们的代码[14]。
实验是在Ubuntu 18.04.5 LTS上进行的,该系统配备Intel(R)Xeon(R)CPU(2.60GHz)、64位操作系统和 NVIDIA RTX 2080Ti GPU。
2.5.4 实验结果
为了评估我们的模型的性能,我们在两个任务上测试了这些方法:异常KPI识别和错误的软件变更识别。进行以下实验以回答研究问题:
-
RQ1: Kontrast 的性能如何?
异常KPI识别 如表 II 所示,在第一个任务中,Kontrast的表现明显优于基线(分别为0.013、0.084),在两个数据集上达到0.932和0.648的 F1-scpre 。由于数据集 A \mathcal{A} A 的数据特性和 Holt-Winters 算法的性质,Gandalf算法在数据集 A \mathcal{A} A 上不能在时间限制内收敛。SCWarn和USAD* 是多变量方法,使用多个KPI时间序列。因此,他们在这项任务上没有结果。
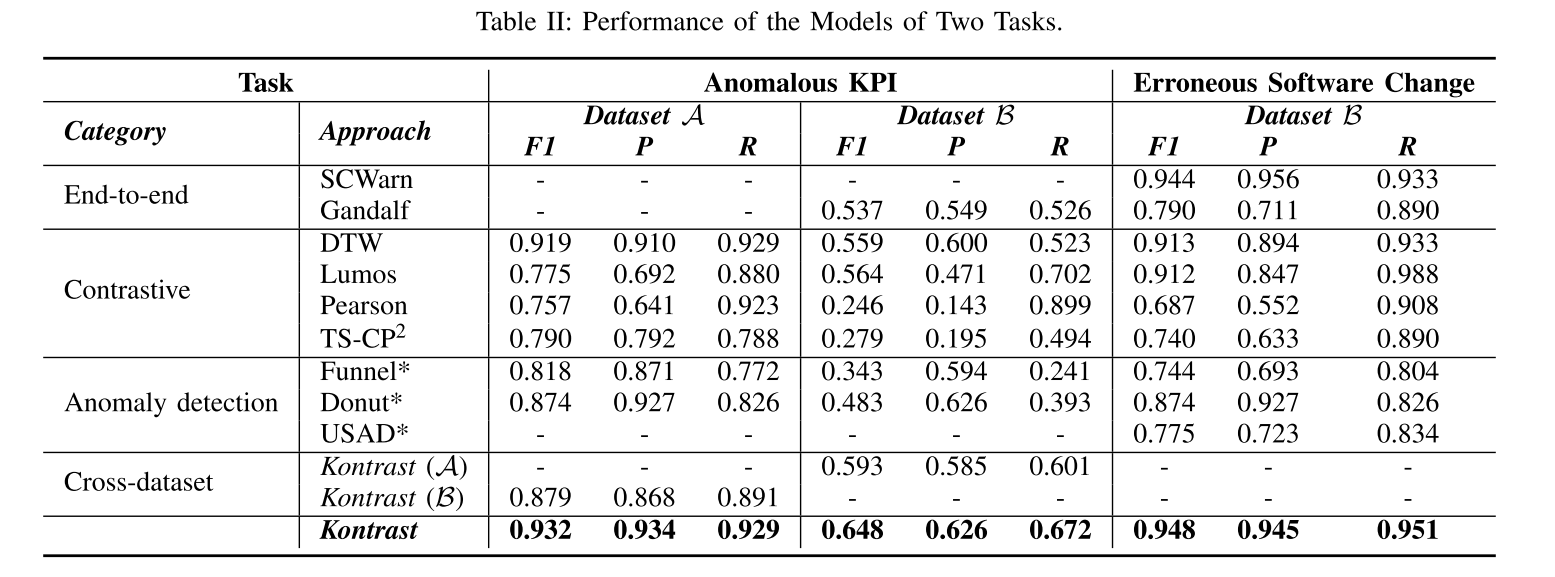
错误软件变更识别 由于我们没有数据集 A \mathcal{A} A 的 异常信息,我们仅对数据集 B \mathcal{B} B 执行了错误软件变更识别任务。基于我们的实证研究和所提出的方法的观察,我们判断软件的变化,其相关的 KPI 时间序列的预测。我们使用 KPI 距离预测的第 95 百分位数来区分错误的软件更改。我们看到Kontrast优于所有其他方法。SCWarn 融合了多个KPI的丰富信息,实现了合理的结果。但它是基于预测的;因此,它受到当前期间波动的影响。Lumos基于比较,但它忽略了数据的顺序,因此性能较差。DTW 无法识别具有不同异常模式的KPI之间的差异。 TS-CP 2 \textbf{TS-CP}^2 TS-CP2 的数据增强模块不是为我们的任务而设计的,因此它们在我们的数据集上表现不佳。上述实验表明,Kontrast比所比较的方法表现得更好。
-
RQ2:Kontrast 的时间效率是多少?
测试时间 在实际部署中,时间效率是识别错误软件更改的一个关键考虑因素。由于Kontrast是一个通用模型,它可以使用一个单一的模型批处理不同的KPI时间序列。该属性极大地提高了算法的并行性,使其能够以相对大的批量处理数据,从而减少每个KPI的时间成本,如表III所示。由于TSCP2利用对比学习,因此它在此任务上也是有效的。对于以多变量KPI时间序列作为输入的模型(USAD* 和SCWarn),我们计算了一个KPI时间序列的平均时间成本。结果显示,Kontrast在某个KPI的测试阶段拥有毫秒级的速度,为100(例如SCWarn、Lumos)至1,000(例如,Donut*,DTW)比排除基于对比学习的方法的最新方法快一倍。
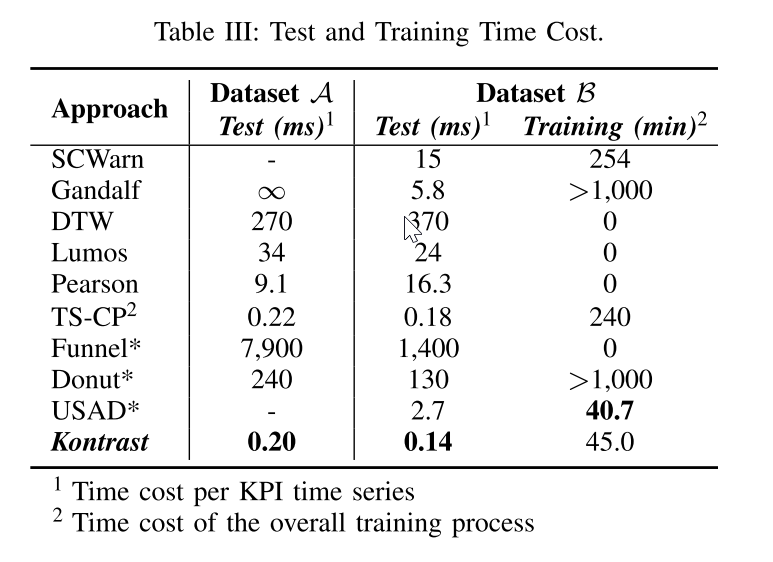
训练时间 训练时间成本也是方法的关键评估指标,因为它决定了需要在线训练的方法的检测延迟。由于Kontrast的训练时间高度依赖于超参数,因此我们在特定上下文中比较结果(当在数据集B上运行时)。对于不需要训练的模型,我们将其训练时间视为0。对于每个KPI时间序列需要训练的模型,我们总结了训练时间。对于Kontrast,我们总结了K训练数据生成时间成本和K模型训练时间成本。通过表 III 的最后一列,我们发现在相当数量的情况下(即,如果要处理大约35, 000)KPI时间序列,KPI特定算法的训练时间变得不可接受。相反,Kontrast的训练时间只与一些超参数(生成的数据集的大小,K,ω和训练时期)有关,这意味着Kontrast的训练时间成本对输入大小不敏感。TS-CP 2具有相当复杂的模型结构,从KPI时间序列中提取细节信息,这导致训练效率低。
-
RQ3:Kontrast如何适应不同的数据集?
适应性 为了证明Kontrast的适应性,我们使用不同的数据集对其进行了训练和测试。使用[43]的方法,我们证明了两个数据集的不相似性:基于DTW的算法测得数据集 A \mathcal{A} A 与 A \mathcal{A} A 的数据集间相似度为0.289, B \mathcal{B} B 与 B \mathcal{B} B 的数据集间相似度为0.274,而 A \mathcal{A} A 与 B \mathcal{B} B 的数据集间相似度为1.357,这表明数据集 A \mathcal{A} A 与 B \mathcal{B} B 在时间序列形状上存在较大差异。结果可见于 表II 的“交叉数据集” 类别中。
结果表明,虽然Kontrast可能没有学习到数据集中的确切数据模式,但它比大多数比较模型取得了更好的效果。Gandalf 中的Holt-Winters不收敛于数据集 A \mathcal{A} A ,因此被省略。此外,我们还对数据集 B \mathcal{B} B 进行了五重交叉验证。实验结果接近于表 II 中的那些。由于页面限制,我们不在此列出。这些结果证明了Kontrast的适应性,使其有可能部署在不熟悉的平台上,即使不知道他们的正常数据模式。 -
RQ4:主要组件对Kontrast的性能有何贡献?
噪声注入模型 如图 8 示出了没有每个噪声模式注入模块的Kontrast的 F1-score。具有所有组件的原始模型在两个数据集上的所有实验中表现最好,而噪声模式注入模块的任何删除降低了整体性能。结果表明,我们的数据增强模块是有益的,我们的对比学习为基础的模型。
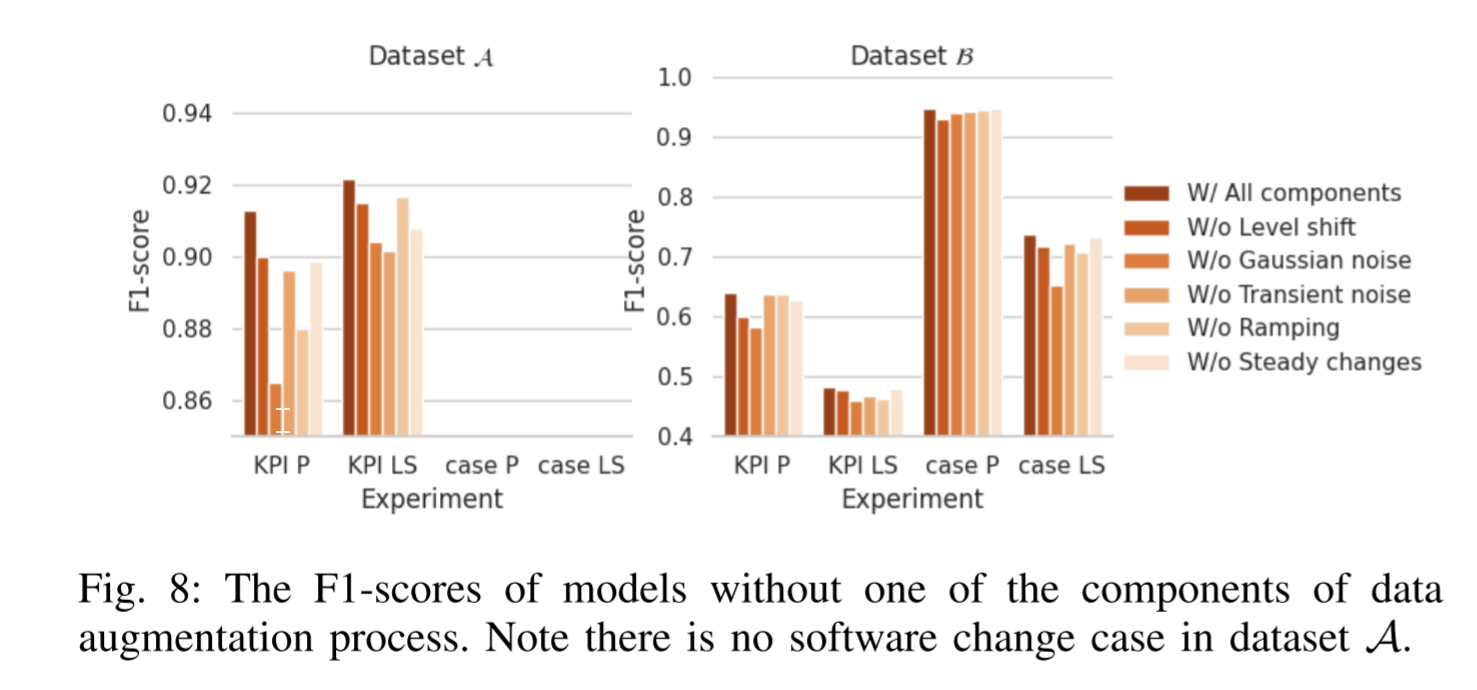
关于我们的数据增强模块的竞争力,我们还发现我们的数据增强比数据增强的自我监督损失的最新工作[44]。事实上,根据我们的实验结果,如果我们用[44]中的数据增强模块替换Kontrast中的数据增强模块,异常KPI识别的 F1-score 在数据集 A \mathcal{A} A 和 B \mathcal{B} B 上分别降低0.12和0.17和0.14,错误软件变更识别的 F1-score 降低0.14。我们推测这是因为我们的数据增强更接近现实的软件变更情况,因此比其他方法表现得更好。
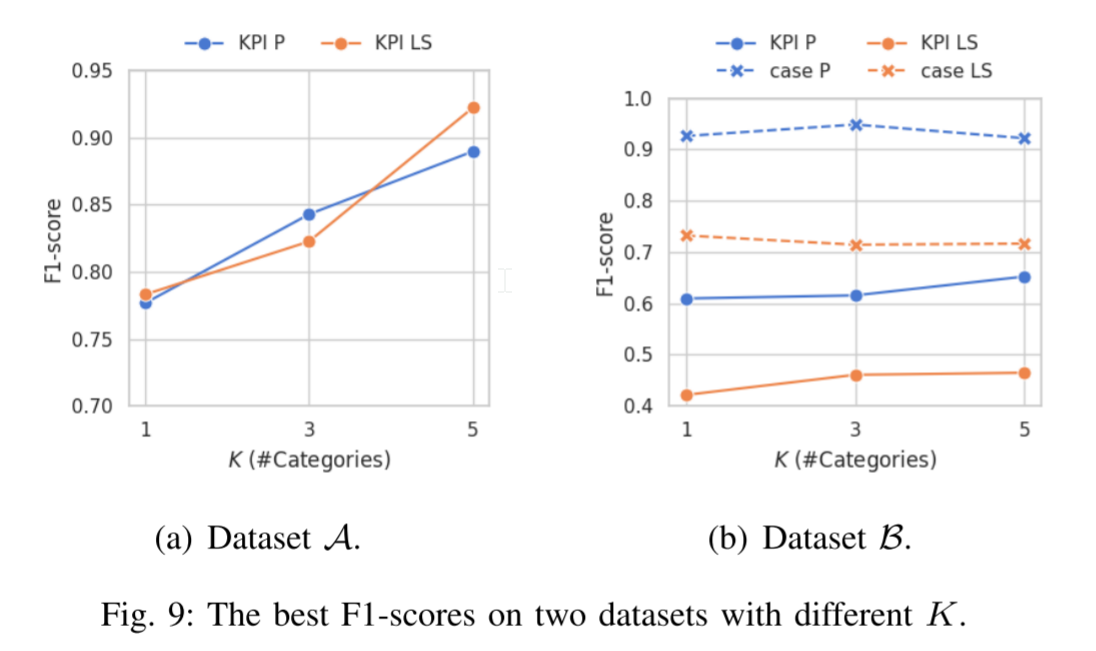
K - #噪声强度分类器的类别。为了验证噪声强度分类器的有效性,我们探索了K与模型性能之间的关系。为了探索参数对P模型和LS模型的影响,我们在本实验和第IV-D5节中使用了聚集之前模型的原始预测结果(4)。我们发现,更大的 K 导致更好的性能与更多的数据生成和训练成本的权衡,根据图 9 中的结果。因此,我们应该通过在不同的数据集上尝试多个Ks来达到准确性和时间效率之间的经验平衡。我们还可以确保当K = 1时(使用一个P模型和一个LS模型处理所有KPI时间序列),两个数据集上的性能都是最差的。这一观察结果证明了Kontrast噪声强度分类的必要性。
5. RQ5:相关超参数的影响是什么?
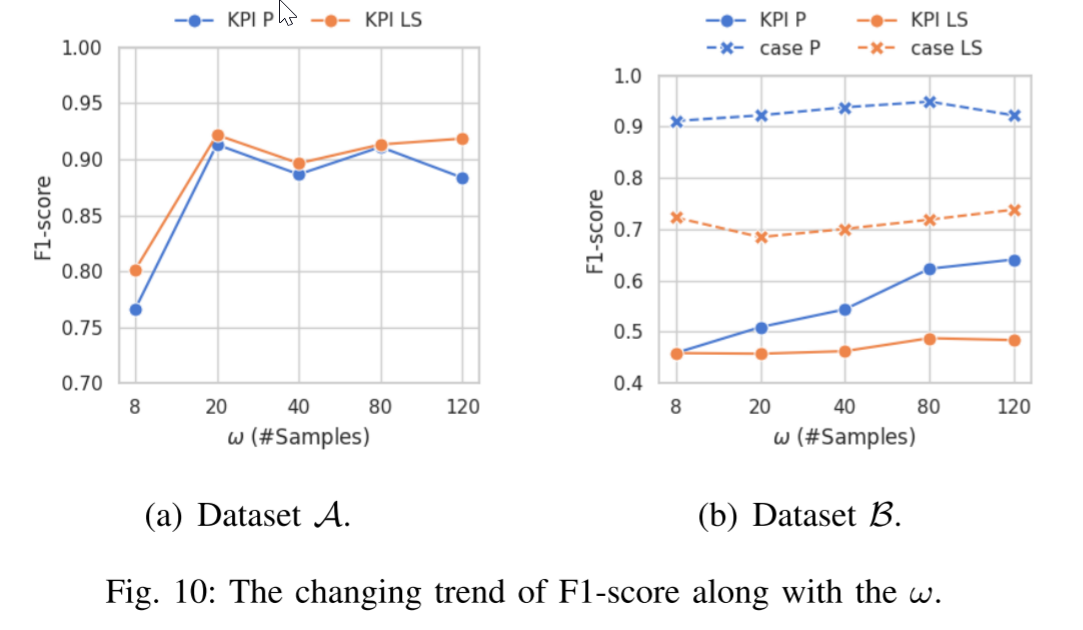
ω \omega ω - 检查窗口中的样本数 图10展示了相对于 ω 的变化的F1-score,其中 ω 越大,大致上模型执行得越好。然而,大的 ω 引入显著的检测时间延迟,因为我们需要等待直到已经获得第 ω 个时间点的数据。在数据集 A \mathcal{A} A 中,当 ω 足够大时,结果对 ω 不敏感,这表明数据集 A \mathcal{A} A 的正例生成对于Kontrast足够鲁棒。
2.6 实际应用和局限性
为了评估我们的方法在实践条件下,我们应用Kontrast在实际的软件变更的情况下。我们展示了几个成功的故事和一些局限性。
2.6.1 成功案例
为了评估和强调Kontrast在现实设置中的有效性,我们从数据中心收集了几个真实的软件变更案例。运营商对Kontrast有三方面的赞赏。1)Kontrast在识别错误的软件更改方面非常高效。所选择的案例是用于手动分析的小规模(在一个案例中的#KPI约为1,000)案例。Kontrast在一秒钟内成功识别了所有错误的软件更改,这比目前的做法快得多。高效率帮助操作员快速地找到错误的软件改变以立即采取行动(例如,回滚)。2)由于具有自适应性,即使只有少量的历史数据,识别结果也是准确的。由于数据中心的特权问题,训练数据不容易获得。因此,模型训练难以在数据中心之外进行,降低了参数微调的效率。在处理以下软件更改案例时,我们发现即使我们在数据集B上训练Kontrast,整体性能也没有下降太多,仍然可以识别异常KPI和错误的软件更改。这种适应性主要提高了数据安全性,使其可以在没有大量敏感数据的情况下对模型进行微调。3)准确性令人满意,减少了误报率和漏报率。Kontrast进行的分析结果比当前实践进行的分析结果更接近人类标签,包括FluxRank [12],k-sigma [13]和固定阈值异常检测方法。使用Kontrast,虚警率和漏报率较低,减少了运营商不必要的工作量,提高了业务的稳定性。
以下列举了一些典型案例,相应的KPI 如图11 所示。
Case 1: 在一个特定的应用程序上,在一次常规的函数更新之后,除了一些KPI时间序列中的一些短暂的峰值之外,没有异常。峰值可能是由网络服务重启引起的,网络服务重启可以自我修复,不应被视为异常。比较的方法错误地警告这种模式,造成浪费操作员的时间,而Kontrast成功地识别出它作为一个错误的异常由于瞬态噪声模块(第III-B2节)。该模块将这种尖峰注入到负面情况中,使模型能够容忍这种模式。
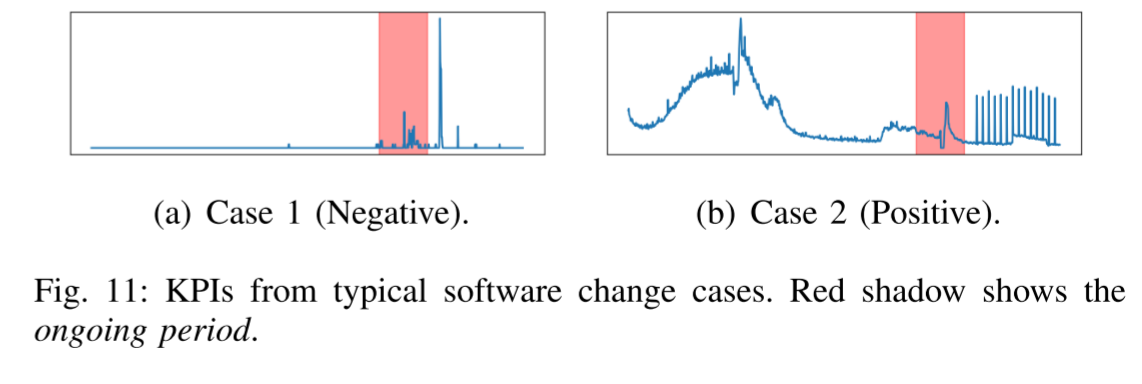
Case 2:新部署的软件更改修改了日志文件保存功能,导致输出文件大小大幅增加。直到磁盘系统几乎满了,平均事务时间才显著增加。Kontrast在软件更改后通过事务时间使用检测到此事件。它发现,在部署之后,该KPI中存在更频繁的峰值,而比较的方法未能检测到它。
2.6.2 局限性
使用Kontrast有一些限制。首先,很难检测到由错误的软件更改引起的静默事件。另一个限制是Kontrast目前单独处理每个KPI时间序列,忽略了多变量数据中的相互依赖性[45]。由于我们的模型的架构,多元和适应性是排他性的。我们将这些问题留给我们未来的改进来解决。
22.7 论文源码运行与分析
本部分我们根据原作者源码内容进行实验,但由于作者并没有提供论文中用到的所有数据集,所以想完全复现论文实验是比较困难的。因此,我们只能使用论文源码提供的数据集进行实验。
此外,由于版本不同,小伙伴们运行时可能遇到很多乱七八糟的问题,希望各位查查资料,或者描述清楚在下方评论,一定回复。
22.7.1 本地执行(CPU)
首先从 github 上 clone 到本地,即
$ git clone https://github.com/NetManAIOps/kontrast
使用 pycharm 等软件打开项目,选择 Python 环境。
接着我们修改一下 requirements.txt 文件,主要是因为作者对依赖的要求过于苛刻。
numpy
pandas
tqdm
torch
PyYAML
pynvml
sklearn
matplotlib
接着安装依赖:
$ pip install -r requirements.txt
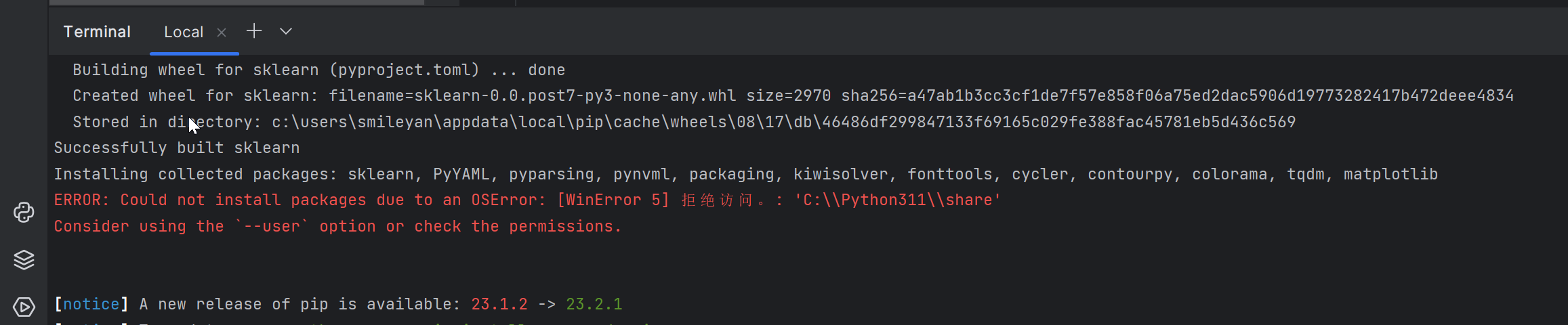
如果遇到这个问题,则添加参数 --user
$ pip install --user -r requirements.txt
此步骤无误后,继续执行作者提供的脚本:
$ python run.py
如下图所示:
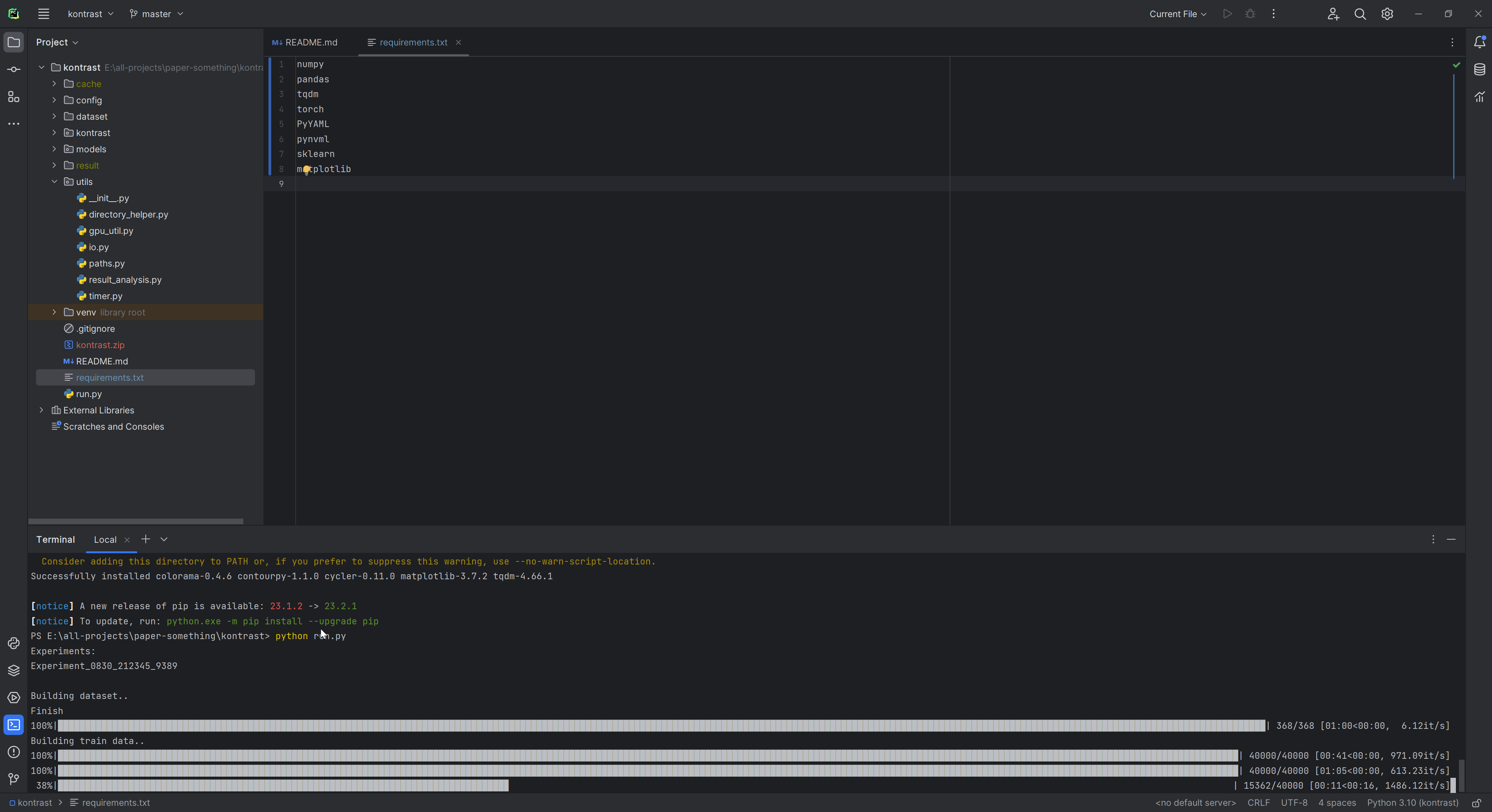
接着需要等待一些时间,包括数据集的处理以及训练过程等。

22.7.2 基于 GPU 运行
过程与前面一样,只是在训练过程中基于GPU运行,速度更加快。
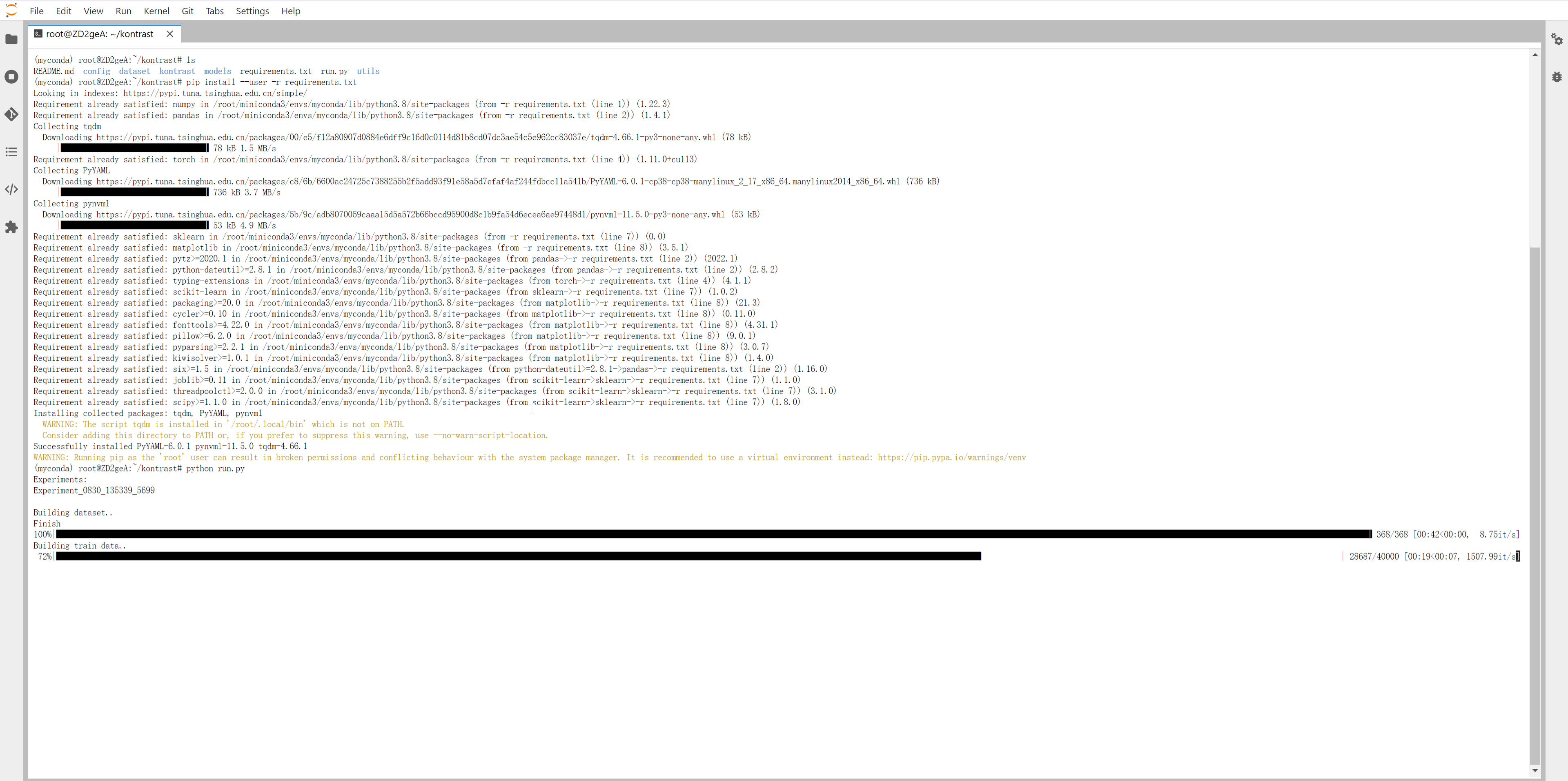

运行过程中可以看到CPU与GPU使用率大致为:



运行完成以后,结果写入到 result/analysis/report.csv 。
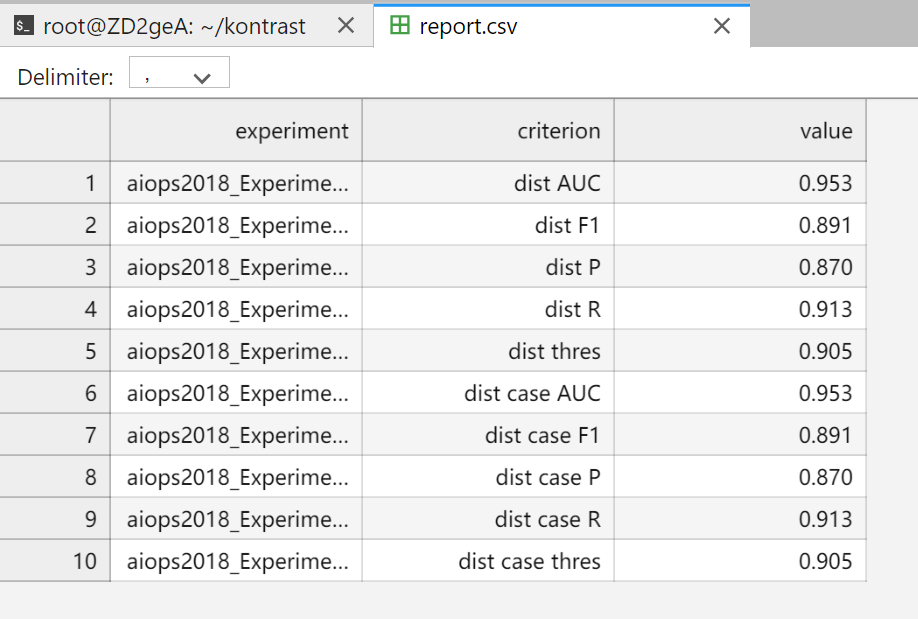
result/analysis_fig/aiops2018_Experiment_0830_135339_5699.jpg
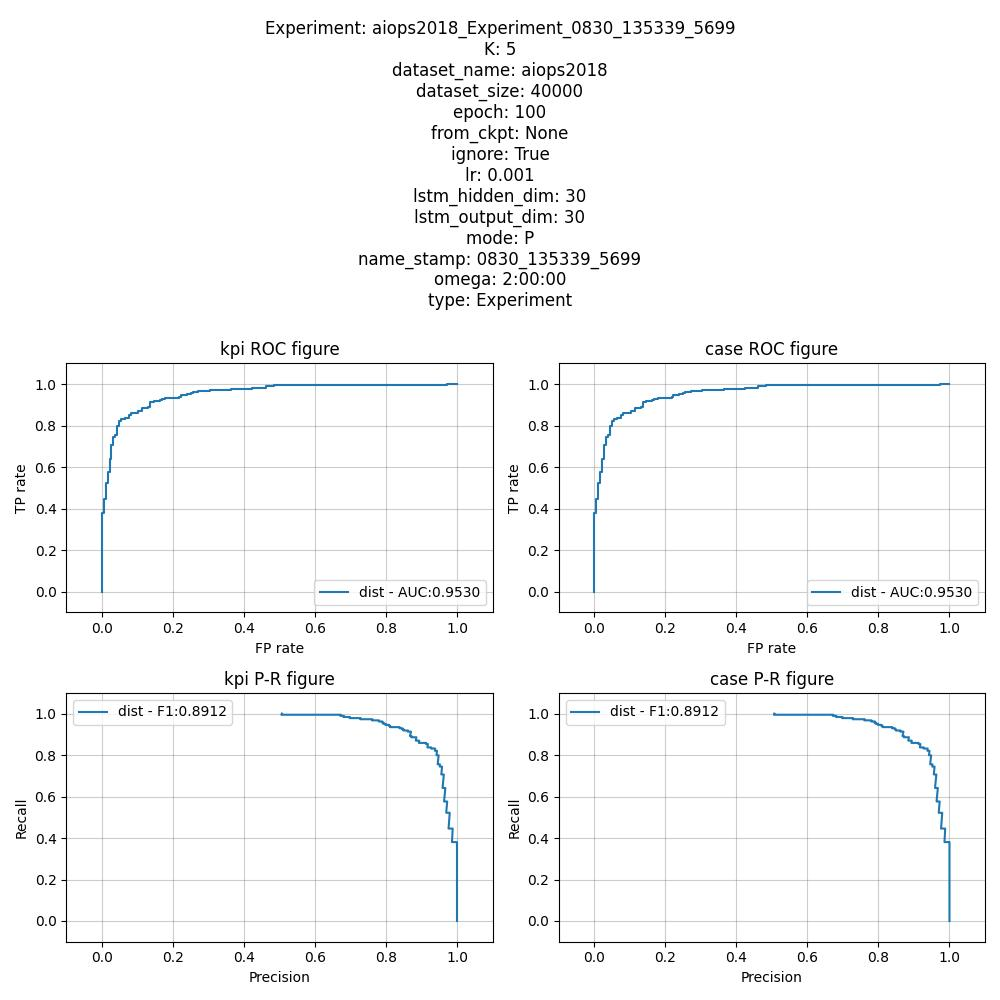
22.7.3 源码分析
首先查看 run.py 主要内容如以下注释
if __name__ == '__main__':torch.multiprocessing.set_start_method('spawn')configs = read_config()dataset_name = configs['common_args']['dataset_name']experiments = build_experiments(configs)print('Experiments: ')for exp in experiments:print(exp)print()# 对于每类数据集,或者每一个实验,执行run_experiment方法while len(experiments) > 0:exp = experiments[0]run_experiment(dataset_name, exp)experiments.pop(0)# 生成结果generate_analysis()
其次,查看 run_experiments 方法,核心代码如下:
# 训练过程
experiment.train()
t0 = time()# 测试过程
result_df = experiment.test()
t1 = time()
total_time_cost = t1 - t0
total_kpi_count = len(get_dataset(dataset_name))# 将结果保存下来
os.makedirs(csv_save_path, exist_ok=True)
result_df.sort_values(by='id', inplace=True)
result_df['id'] = result_df['id'].astype(int)
result_df['label'] = result_df['label'].astype(int)
result_df['case_id'] = result_df['case_id'].astype(int)
result_df['case_label'] = result_df['case_label'].astype(int)
result_df.to_csv(os.path.join(csv_save_path, f'{dataset_name}_{experiment}.csv'), index=False)
所以现在的关键在于 experiment.train() 方法
def train(self) -> None:"""Train the model."""# 数据集准备self.dataset = Dataset(dataset_name=self.dataset_name,omega=self.omega,period=self.period,config=DatasetConfig(K=self.K, mode=self.mode, ignore=self.ignore,batch_size=self.batch_size, dataset_size=self.dataset_size))if self.from_ckpt is None:print('Start training..')for i, m in enumerate(self.models):# 逐个模型开始训练m.train(self.dataset.get_train_data_loader(i), f'{self.name_stamp}_{i}')print('Training complete.')else:# 如果运行到一半被终止,或者其他原因,已经训练好模型,再次运行时无需训练,直接加载print('Start loading..')for i, m in enumerate(self.models):m.load(f'{self.from_ckpt}_{i}')print('Loading complete.')
上面直接遍历了 self.models,并直接训练,我们查看一下它初始化的过程,即
def __init__(self,omega: td,period: td,dataset_name: str,mode: str,K: int,epoch: int,lstm_hidden_dim: int,lstm_output_dim: int,lr: float,from_ckpt: str=None,batch_size: int=5000,dataset_size: int=10000,rate: int=60,**kwargs):"""Configs of an experiment.Args:omega: Inspection window size. omega in our paper. NOTE here we use TimeDelta.period: The period of KPI time series in the dataset. T in our paper. NOTE here we use TimeDelta.dataset_name: Filename of the dataset file under "dataset/config/" (ext name excluded).mode: "LS" or "P", indicating this is an LS model or a P model.K: Number of noise intensity levels. K in our paper.epoch: Epochs to train.lstm_hidden_dim: The hidden dimension of LSTM.lstm_output_dim: The output dimension of LSTM.lr: Learning rate.from_ckpt: Whether to start from a checkpoint (name_stamp of another experiment). If so, we only test the model.batch_size: Batch size of the dataset.dataset_size: Number of KPI time series segment pairs in the dataset to generate per label (positive/negative).rate: Sampling interval of the dataset (unit: second). For example, if the monitor service collects data once per minute, rate=60.ignore: Whether to ignore the ongoing period in LS model, default True.device: Which device should this experiment be conducted on."""# The list of distance names.self.name_stamp = io.exp_name_stamp()self.omega = omegaself.period = periodassert mode in ['LS', 'P']self.mode = modeself.dataset_name = dataset_nameself.K = Kself.lstm_hidden_dim = lstm_hidden_dimself.lstm_output_dim = lstm_output_dimself.epoch = epochself.lr = lrself.ignore = kwargs['ignore'] if mode == 'LS' else Truedevice = kwargs['device'] if 'device' in kwargs else 'cuda:0'self.dataset_size = dataset_sizeself.from_ckpt = from_ckptself.save_yaml()self.batch_size = batch_sizeself.dataset = None # imported later when train() is calledself.models = []# 初始化不同噪声等级的模型for i in range(self.K):self.models.append(Model(config=ModelConfig(input_dim=1,epoch=self.epoch,lstm_hidden_dim=self.lstm_hidden_dim,lstm_output_dim=self.lstm_output_dim,lr=self.lr,device=torch.device(device),input_len=int(self.omega.total_seconds() // rate))))
不同噪声等级对应不同的模型,现在查看训练过程,即
@timerdef train(self, dataloader: DataLoader, filename: str):"""Train the model with a given dataloader.Args:dataloader: Dataset dataloader.filename: The dataset filename, used for save checkpoint."""n_epoch = self.config.epochdevice = self.config.devicemodel = self.modelloss_fn = self.loss_fnoptimizer = self.optimizer# 循环所有的 epochfor epoch in range(n_epoch):loss_sum = 0# 小批量训练for batch_x1, batch_x2, batch_y in tqdm.tqdm(dataloader):batch_x1 = batch_x1.to(device)batch_x2 = batch_x2.to(device)batch_y = batch_y.to(device)optimizer.zero_grad()out_1, out_2 = model(batch_x1, batch_x2)# 计算损失loss = loss_fn.forward(out_1, out_2, batch_y)loss_sum += loss * batch_x1.shape[0]# backwardloss.backward()optimizer.step()print(f'epoch {epoch:3d}: loss = {loss_sum / (1e-5 + dataloader.sample_count()):.4f}')self.model = modelself.dump(os.path.join(ckpt_save_path, f'{filename}.ckpt'))
测试过程
def test(self, dataloader: DataLoader):"""Test the model with a given dataloader.Note for each kpi id, there are multiple X^Ps (for P model).We need an minimum aggregation, shown in the code.Args:dataloader: Dataset dataloader.Returns:DataFrame"""device = self.config.deviceresult = []with torch.no_grad():for batch_x1, batch_x2, batch_y, batch_id, batch_case_id, batch_case_label in tqdm.tqdm(dataloader):batch_x1 = batch_x1.to(device)batch_x2 = batch_x2.to(device)# 测试结果out_1, out_2 = self.model(batch_x1, batch_x2)# 计算损失loss = F.pairwise_distance(out_1, out_2, keepdim=True).cpu().numpy()batch_id = batch_id.numpy()batch_y = batch_y.numpy()batch_case_id = batch_case_id.numpy()batch_case_label = batch_case_label.numpy()batch_result = np.concatenate([batch_id, batch_y, batch_case_id, batch_case_label, loss], axis=-1)# 批次的结果result.append(batch_result)if len(result) > 0:result = np.concatenate(result, axis=0)result_df = pd.DataFrame(result, columns=['id', 'label', 'case_id', 'case_label', 'dist'])# Minimum aggregation group = result_df.groupby('id').agg({'label': 'mean','case_id': 'mean','case_label': 'mean','dist': 'min'})group.reset_index(inplace=True)return groupelse:return None
22.7 总结
kontrast 主要是介绍如何通过自监督对比学习的方法来识别错误的软件变更。论文首先介绍了错误的软件变更对系统稳定性和用户体验的影响,然后提出了一种名为Kontrast的新方法,该方法可以同时处理不同的关键绩效指标(KPI)时间序列数据,以快速准确地识别错误的软件变更。论文还介绍了Kontrast的四个阶段,包括噪声模式注入、通用比较模型训练、软件变更后的KPI时间序列数据提取和聚合结果判断。最后,论文通过实验证明了Kontrast的有效性和效率,并指出该方法具有跨数据集适应性。
论文提供方便可用的源码,推荐感兴趣的小伙伴在新的数据集上测试一下。
感谢各位小伙伴的支持 ~
Smileyan
2023.08.30 22:48





![[杂谈]-快速了解直接内存访问 (DMA)](https://img-blog.csdnimg.cn/c35f0532cc6942a0b3a4b48e2338633f.webp#pic_center)