文章目录
目录
文章目录
前言
一、什么是双向链表?
双向链表有什么优势?
二、双向链表的设计和实现
1.设计思想
尾增 : 在链表的末尾添加新的元素
头插 : 在链表头部插入节点
删除 : 根据val的值删除节点
查找 : 根据索引的值查找并返回节点
总结
前言
大家好,今天给大家讲解一下双向链表的设计和实现,和单向链表不同的是,双向链表中加入了指向前一个节点的指针。
一、什么是双向链表?

如上图所示,双向链表中包含了两个指针,一个指向前驱结点,一个指向后继节点,其中头结点没有前驱节点,尾结点没有后继节点
前驱 : 前驱指的是当前节点的前一个节点,即在链表中位于当前节点之前的节点。它可以通过前向指针(previous pointer)来访问。
后继 : 后继指的是当前节点的后一个节点,即在链表中位于当前节点之后的节点。它可以通过后向指针(next pointer)来访问。
双向链表有什么优势?
相对于单链表,双向链表具有以下优势:
-
可以从任意一个节点开始进行正向或反向遍历。由于每个节点都有指向前一个节点和后一个节点的指针,因此可以方便地在链表中进行前向和后向的遍历操作。
-
在插入和删除节点时,不需要遍历整个链表来找到前一个节点。在单链表中,如果要在某个节点之后插入或删除节点,需要先找到该节点的前一个节点,而双向链表可以直接通过指针找到前一个节点,从而提高了插入和删除操作的效率。
-
双向链表可以更方便地实现反向查找。在单链表中,如果要查找某个节点的前一个节点,需要从头节点开始遍历整个链表,而双向链表可以通过后向指针直接找到前一个节点,从而实现了反向查找。
总之,双向链表相对于单链表在遍历、插入和删除操作上具有更高的效率和灵活性。然而,双向链表的缺点是需要更多的内存空间来存储额外的指针。
二、双向链表的设计和实现
1.设计思想
前言 : 为了简单起见,我们在类中只定义最基本的属性
节点类: 不管是双向链表还是单向链表,都是有节点所构成,所以说节点类是必不可少的(值得一提的是,节点类不一定要定义成外部类,这么一想,好像定义成内部类更加合适,毕竟节点是链表的一部分,大家如果自己实现的话可以使用内部类的方式,由于我写博客准备的就是外部类的方式,在此就不做修改)
链表类: 类中应该需要包含什么信息? 聪明的读者肯定已经想到了吧,节点啊! 你们都是聪明人啊,除了节点之外我们还需要包含一个成员变量Head(链表的头结点),一个构造方法(链表写出来是给别人用的),还有其他的成员方法(自己设计)。
下面给出框架代码
public class List {private Node head;// 头结点public List() {}// 节点类
class Node {int val;Node prev;Node next;public Node() {}public Node(int val) {this.val = val;}@Overridepublic String toString() {return "Node{" +"no=" + val +", prev=" + prev +", next=" + next +'}';}
}
2.代码实现
前言 : 为了简单起见,我们下面只实现基本方法并且只重点针对性的解析我认为对初学者有难度的代码部分
和前面的部分代码相同,有些很简单的方法直接给出
/*
* 链表中元素的个数
* */
public int getSize(){Node cur = head;int count = 0;while(cur != null){cur = cur.next;count++;}return count;
}/*
* 判断链表是否为空
* */
public Boolean IsEmpty() {return head == null;
}
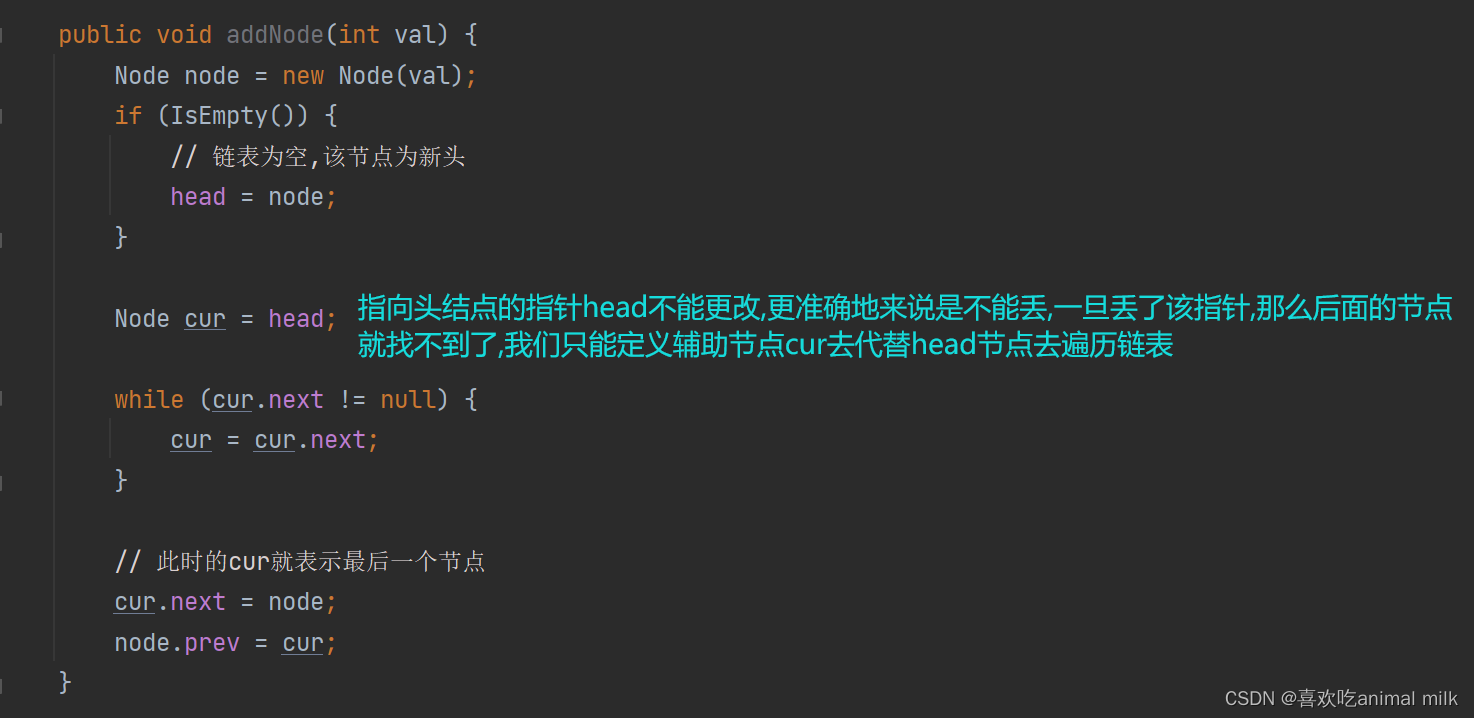
尾增 : 在链表的末尾添加新的元素
public void addNode(int val) {Node node = new Node(val);if (IsEmpty()) {// 链表为空,该节点为新头head = node;}Node cur = head;while (cur.next != null) {cur = cur.next;}// 此时的cur就表示最后一个节点cur.next = node;node.prev = cur;
}
头插 : 在链表头部插入节点
不知道初学者有没有感觉到什么难度,个人感觉这些代码都是很基础的,所以没有进行解析
如果有问题的可以在评论区提出,我再进行修改
public void addFirst(int val){Node newNode = new Node(val);if(IsEmpty()){head = newNode;}newNode.next = head;head.prev = newNode;head = newNode;
}
删除 : 根据val的值删除节点
这个和单链表比起来就简单多了,在单链表中需要找到值为val的前一个节点,还需要判断头结点为val的情况,大家搞清楚单链表中的方法,双向链表中的这个就是弟弟!
// 根据节点的no值删除节点
public void DeleteNode(int no) {int count = 0;// 记录被删除节点的个数if(IsEmpty()){System.out.println("链表为空");return;}Node cur = head;// 将head的值赋给变量cur,使其代替head进行循环遍历while(true){if(cur == null){System.out.println("共删除了"+count+"个节点");// 链表中已经没有值为no的节点,跳出循环break;}if(cur.val == no){Node prev = cur.prev;// 记录将要被删除的节点的上一个节点cur = cur.next;// 用下一个节点覆盖当前节点cur.prev = prev;count++;continue;}cur = cur.next;}
查找 : 根据索引的值查找并返回节点
// 根据索引查找节点
public Node findNode(int index) throws IndexException {// 索引是否合法,一看到和索引相关的问题就应该要想一下是否需要判断索引的合法性,此处需要判断if(index < 0 || index >= getSize()){// 自定义异常来表示索引越界这种不合法的行为throw new IndexException("索引越界");}Node cur = head;while(index > 0){index--;cur = cur.next;}return cur;
}
写到这里不得不感慨一下JAVA中的深情哥-Exception(异常)-上_喜欢吃animal milk的博客-CSDN博客的下篇到现在还没写

到这里就结束了,方法在精不在多,自行领悟吧!
总结
这篇博客大家应重点关注链表的设计,代码这个东西面试考的更多的是单链表,大家刷题更多的也是单链表,双向链表相对于就没有那么重要了。







![[.NET学习笔记] - Thread.Sleep与Task.Delay在生产中应用的性能测试](https://img-blog.csdnimg.cn/b7fcefc987cd462283171b5d3b538217.png)