Excel周报制作
文章目录
- Excel周报制作
- 一、理解数据
- 二、数据透视表
- 三、常用函数
- 1.sum-求和
- 2.sumif-单条件求和
- 3.sumifs-多条件求和
- 4.sum和subtotal的区别
- 5.if函数
- 6.if嵌套
- 7.vlookup函数和数据透视表聚合
- 8.index和match函数
- 四、周报开发
- 五、报表总览
一、理解数据
这是一个线上外卖门店的数据。
通过全选一行和全选一列得知,数据有561行(去掉表头),24列。
使用CTR L+SHIFT+L快捷键对所有列进行快速筛选。
品牌名称:一共有2个值,分别是蛙小辣火锅杯(总账号)和拌客(武宁路店)
门店ID:每个门店有一个固定的ID
平台:拼音格式,一共有eleme和meituan两个值
平台i:文本格式,一共有饿了么和美团两个值
平台门店名称:
蛙小辣火锅杯(五角场店)和蛙小辣火锅杯(五角场店)的括号格式不同(中英文),这两个店是一个店吗?拌客干拌麻辣烫(武宁路店)、拌客·干拌麻辣烫(武宁路店)和拌客干拌麻辣烫(武宁路店)这几个店是同一个店吗?
在筛选中,只选择蛙小辣火锅杯(五角场店)和蛙小辣火锅杯(五角场店),查看它们的门店ID,发现蛙小辣火锅杯(五角场店)的门店ID为2000507076,蛙小辣火锅杯(五角场店)的门店ID为8184590,所以它们是不同的两个店。
在筛选中,只选择拌客干拌麻辣烫(武宁路店)、拌客·干拌麻辣烫(武宁路店)和拌客干拌麻辣烫(武宁路店),查看它们的门店ID,拌客干拌麻辣烫(武宁路店)和拌客·干拌麻辣烫(武宁路店)的门店ID均为337460136,说明它们两个是同一个店,拌客干拌麻辣烫(武宁路店)的门店ID是9428110,说明它是不同的一个店。
造成这个情况的原因可能是同一家店在平台上进行过关店重开,以享受平台的新店流量补贴,重开时的平台门店名称和之前的有所不同。
GMV:GMV(全称Gross Merchandise Volume),即商品交易总额,是成交总额(一定时间段内)的意思。多用于电商行业,一般包含拍下未支付订单金额
这里只是表面金额——外卖的原价,真正入账还需要减去各种平台的满减、红包、补贴等。
商家实收:去除掉平台满减、红包、补贴、抽成后的实际入账金额
门店曝光量:这家门店在外卖平台被多少个用户看到过
门店访问量:有多少用户在外卖平台中点进了这家门店
门店下单量:有多少用户在这家门店下单。无效订单+有效订单=门店下单量
无效订单:下单后中途取消或退款等等
进店人数:这是线上外卖门店的数据,进店人数指的是在外卖平台上进入门店的人数,和门店访问量相对应,而不是线下进入门店的人数
一般来说,曝光人数、进店人数、下单人数都是要比门店曝光量、门店访问量、门店下单量要少的,因为存在一个人多次进店的情况。但是有些时候(比如第一行)会出现进店人数比门店访问量要多的情况,这种数据是有问题的。
它们之间的区别类似于UV和PV的区别。

CPC:Cost Per Click,每产生一次点击所花费的成本
二、数据透视表
选择源数据中任意一个单元格,点击插入选项卡下的数据透视表。
三、常用函数
1.sum-求和
| 1-8月GMV | 1月和8月GMV | |
|---|---|---|
| 总计 | =SUM(‘拌客源数据1-8月’!J2:J562) | =SUM(‘拌客源数据1-8月’!J2:J25,‘拌客源数据1-8月’!J496:J562) |
1-8月GMV在工作表拌客源数据1-8月中,是一个跨工作表求和的问题。
方法1:输入=SUM(),点击上方fx按钮,点击拌客源数据1-8月工作表,CTRL+SHIFT+↓选中GMV列,点击确定。
方法2:点击视图选项卡下的新建窗口,在xxxx.xlsx:2下选择GMV列,省去了来回切换工作表的麻烦。
新建的窗口和原来的工作簿是同样一个工作簿。
win+→实现左右分屏。
1月和8月GMV:SUM函数可以用逗号分隔多个区域,对多个区域进行求和。
使用视图选项卡下的冻结窗格—冻结首列,将首列(日期)冻结,方便操作。
1月的GMV:J2:J25
8月的GMV:J496:J562
筛选并没有剔除数据,所以筛选1月和8月后对整列求和,得到的还是1-8月GMV。
2.sumif-单条件求和
语法
SUMIF(range,criteria,sum_range)
(1) Range 为用于条件判断的单元格区域。
(2) Criteria 为确定哪些单元格将被相加求和的条件,其形式可以为数字、表达式或文本。例如,条件可以表示为 32、“32”、“>32” 或 “apples”。(使用方法同COUNTIF)
(3) Sum_range 是需要求和的实际单元格。(可只写该区域的第一个单元格)
| GMV | |
|---|---|
| 2020/07/01 | =SUMIF(‘拌客源数据1-8月’!$A:$A,B15,‘拌客源数据1-8月’!$J:$J) |
| 2020/07/07 | |
| 2020/07/16 | |
| 2020/07/17 | |
| 2020/08/08 | |
| 2020/08/19 | |
| 2020/08/21 |
我们以第一行的问题为例。第一行要求我们求出日期为2020/07/01的GMV总和。
我们在SUMIF函数的第一个参数中选中日期这一整列,第二个参数选择2020/07/01所在的单元格,第三个参数选择GMV这一整列。
再使用快捷键F4将第一个参数和第三个参数全部锁定,将鼠标移至第一行GMV单元格的右下角时双击,即可快速求出所有答案。
第一个参数告诉Excel判断的依据在哪个区域,第二个参数告诉Excel具体的判断条件,第三个参数告诉Excel按照判断条件对哪个区域求和。
3.sumifs-多条件求和
(1)以求2020/07/01的美团平台GMV为例

Sum_range:需要求和的区域
Criteria_range1:用于条件判断的单元格区域1
Criteria1:判断条件1
Criteria_range2:用于条件判断的单元格区域2
Criteria2:判断条件2
(2)同比和环比

GPT:
当我们分析数据时,“同比”(Year-over-Year,YoY)和"环比"(Quarter-over-Quarter,QoQ)是两个常用的比较方式,用于衡量数据在不同时间段之间的变化。以下是它们的概念解释:
同比(Year-over-Year,YoY):同比指的是将当前时间段的数据与同一时间段的前一年相比较。它用于比较相同时间段的不同年份的数据变化情况。例如,我们可以将今年第三季度的销售额与去年同一季度的销售额进行同比比较,以评估销售业绩的增长或下降。
环比(Quarter-over-Quarter,QoQ):环比指的是将当前时间段的数据与上一个时间段相比较。它用于比较相邻时间段的数据变化情况。例如,在季度数据中,我们可以将本季度的销售额与上一季度的销售额进行环比比较,以了解业绩的季度波动情况。
这两种比较方式用于帮助我们观察和分析数据的增长趋势、周期性变化以及季节性影响。通过同比和环比分析,我们可以更好地了解数据的变化情况,并作出相应的决策或判断。
年
2020年环比
=(2020年数据-2019年数据)/2019年数据
=2020年数据/2019年数据-2019年数据/2019年数据
=2020年数据/2019年数据-1
月
2020年7月环比=2020年7月数据/2020年6月数据-1
2020年7月同比=2020年7月数据/2019年7月数据-1
日
2020年7月1日的日环比=2020年7月1日数据/2020年6月30日数据-1
2020年7月1日的月环比=2020年7月1日数据/2020年6月1日数据-1
2020年7月1日的周环比=2020年7月1日数据/2020年6月24日数据-1
同比:上年同期相比 环比:同年上一期相比
2020/07/01的日环比:2020-07-01的GMV/2020-06-30的GMV-1
=SUMIFS('拌客源数据1-8月'!$J:$J,'拌客源数据1-8月'!$H:$H,"美团",'拌客源数据1-8月'!$A:$A,B30)/SUMIFS('拌客源数据1-8月'!$J:$J,'拌客源数据1-8月'!$H:$H,"美团",'拌客源数据1-8月'!$A:$A,B30-1)-1
日同比:当天GMV/前一个月的那天的GMV
2020年7月1日的日同比 = 2020年7月1日数据 / 2020年6月1日数据 - 1
使用YEAR、MONTH、DAY、DATE函数求出2020年6月1日的日期。
2020年6月1日数据:
=SUMIFS('拌客源数据1-8月'!$J:$J,'拌客源数据1-8月'!$H:$H,"美团",'拌客源数据1-8月'!$A:$A,DATE(YEAR(B30),MONTH(B30)-1,DAY(B30)))
(3)求2020年1月的GMV
| 美团GMV | 月环比 | |
|---|---|---|
| 2020/01 | =SUMIFS(‘拌客源数据1-8月’!J:J,‘拌客源数据1-8月’!H:H,“美团”,‘拌客源数据1-8月’!A:A,“>=”&E39,‘拌客源数据1-8月’!A:A,“<=”&G39) | =C39/SUMIFS(‘拌客源数据1-8月’!J:J,‘拌客源数据1-8月’!H:H,“美团”,‘拌客源数据1-8月’!A:A,“>=”&DATE(YEAR(B39),MONTH(B39)-1,1),‘拌客源数据1-8月’!A:A,“<=”&DATE(YEAR(B39),MONTH(B39),1)-1)-1 |
| 2020/02 | ||
| 2020/03 | ||
| 2020/04 | ||
| 2020/05 | ||
| 2020/06 | ||
| 2020/07 | ||
| 2020/08 |
问题解析:求2020年1月的GMV即求2020年1月1日到2020年1月31日的GMV,即使用SUMIFS函数,条件设置为>=这个月的第一天,<=这个月的最后一天。
每个月的第一天:
=DATE(YEAR(B39),MONTH(B39),1)
每个月的最后一天:下个月的第一天减去一天
=DATE(YEAR(B39),MONTH(B39)+1,1)-1
在SUMIFS中使用条件表达式时,>=这种比较符需要加上双引号,并且将比较符用&和后边的表达式连接。
">="&表达式

2020-01的月环比:2020年1月的数据/2019年12月的数据-1
4.sum和subtotal的区别
语法
SUBTOTAL(function_num,ref1,[ref2],…)
SUBTOTAL 函数语法具有以下参数:
-
Function_num 必需。 数字 1-11 或 101-111,用于指定要为分类汇总使用的函数。 如果使用 1-11,将包括手动隐藏的行,如果使用 101-111,则排除手动隐藏的行;始终排除已筛选掉的单元格。
-
Ref1 必需。 要对其进行分类汇总计算的第一个命名区域或引用。
-
Ref2,… 可选。 要对其进行分类汇总计算的第 2 个至第 254 个命名区域或引用。
| sum函数 | subtotal函数 | |
|---|---|---|
| GMV | =SUM(‘拌客源数据1-8月’!J:J) | =SUBTOTAL(9,‘拌客源数据1-8月’!J:J) |
| 不使用筛选 | 1071473.25 | 1071473.25 |
| 筛选出美团的数据 | 1071473.25 | 305135.17 |
SUBTOTAL可以根据源数据的筛选进行求和。
5.if函数
| 月份 | GMV | 判断是否大于月目标10万 |
|---|---|---|
| 1月 | 64233.37 | =IF(C64>100000,“达标”,“不达标”) |
6.if嵌套
| A | B | 判断 |
|---|---|---|
| 0 | 0 | =IF(I80=0,IF(J80=0,“A=0 B=0”,“A=0 B≠0”),IF(J80=0,“A≠0 B=0”,“A≠0 B≠0”)) |
| 1 | 0 | A≠0 B=0 |
| 1 | 1 | A≠0 B≠0 |
| 0 | 1 | A=0 B≠0 |
| 月份 | GMV | cpc总费用 | 大于月目标10万且花费少于5千的为达标 |
|---|---|---|---|
| 1月 | 64233.37 | 3344.24 | =IF(C80>100000,IF(D80<5000,“达标”,“不达标”),“不达标”) |
| 2月 | 32755.71 | 902.87 | 不达标 |
| 3月 | 78895.69 | 2645.32 | 不达标 |
| 4月 | 108307.07 | 4513.12 | 达标 |
| 5月 | 194276.97 | 11804.4 | 不达标 |
| 6月 | 255727.79 | 8302.53 | 不达标 |
| 7月 | 255891.73 | 13616.33 | 不达标 |
| 8月 | 81384.92 | 3680.31 | 不达标 |
7.vlookup函数和数据透视表聚合
视频教程:【EXCEL教程 | 拜托三连了!全B站最用心(没有之一)的EXCEL免费课程!OFFICE/WPS/表格/EXCEL函数/EXCEL技巧/数据分析/办公软件】
语法
VLOOKUP(lookup_value,table_array,col_index_num,[range_lookup])
(1)lookup_value 需要在数据表首列进行搜索的值,可以是数值,引用或字符串
(2) table_array 要在其中搜索数据的文字、数字或逻辑值表,可以是对区域或区域名称的引用
(3) col_index_num 返回匹配的序列号,表中首个值列的序号为1
(4) range_lookup 逻辑值:大致匹配用True或省略,精确匹配用False
举例说明
- 精确查找
| C | D | E | |
|---|---|---|---|
| 20 | 姓名 | 基本工资 | 奖金 |
| 21 | 员工1 | 1797 | 604 |
| 22 | 员工2 | 1979 | 522 |
| 23 | 员工3 | 1903 | 994 |
| 24 | 员工4 | 1754 | 745 |
| 25 | 员工5 | 1572 | 776 |
| 26 | 员工6 | 1521 | 673 |
| 27 | 员工7 | 1777 | 974 |
| 28 | 员工8 | 1544 | 985 |
| 29 | 员工9 | 1640 | 653 |
我们想查找姓名为员工5的基本工资,方法如下:
| 姓名 | 基本工资 |
|---|---|
| 员工5 | =VLOOKUP(“员工5”,C20:E29,2,0) |
第一个参数代表要查找员工5,第二个参数代表在C20:E29这个区域内查找,第三个参数代表要返回的是找到的那行序列中的第2个数据,第四个参数代表精确查找。
col_index_num 返回匹配的序列号,表中首个值列的序号为1,这点与大部分编程语言中从0开始计数不同。
- 模糊查找
| G | H | I | |
|---|---|---|---|
| 33 | 成绩大于等于 | 成绩小于 | 成绩级别 |
| 34 | 0 | 60 | 不及格 |
| 35 | 60 | 80 | 及格 |
| 36 | 80 | 90 | 良好 |
| 37 | 90 | 100 | 优秀 |
我们需要从上表中查询成绩级别,填入下面的表中
| C | D | |
|---|---|---|
| 33 | 成绩 | 成绩级别 |
| 34 | 82 | =VLOOKUP(C34,$G$33:$I$37,3,1) |
| 35 | 95 | |
| 36 | 88 | |
| 37 | 68 | |
| 38 | 86 | |
| 39 | 75 | |
| 40 | 82 | |
| 41 | 76 | |
| 42 | 59 | |
| 43 | 55 | |
| 44 | 63 | |
| 45 | 66 | |
| 46 | 84 | |
| 47 | 69 | |
| 48 | 82 | |
| 49 | 72 |
练习
| 门店ID | 门店名称 |
|---|---|
| 2001104355 | =VLOOKUP(B96,‘拌客源数据1-8月’!$D$1:$E$562,2,0) |
| 8184590 | 五角场店 |
| 305225345 | 龙阳广场店 |
| 2000507076 | 五角场店 |
| 8106681 | 怒江路店 |
| 8491999 | 宝山店 |
| 337460136 | 拌客干拌麻辣烫(武宁路店) |
| 9428110 | 拌客干拌麻辣烫(武宁路店) |
| F | G | |
|---|---|---|
| 95 | 全名 | 值 |
| 96 | a | 1 |
| 97 | abc | 2 |
| 98 | abcd | 3 |
| 99 | acd | 4 |
| 100 | cb | 5 |
| 101 | bc | 6 |
| 102 | bcc | 7 |
| 103 | bdd1 | 8 |
注意:第一行第一列的a后边有一个空格
查找a对应的值
| 查找项 | 返回值 |
|---|---|
| a | =VLOOKUP(I96&“*”,F95:G103,2,1) |
这时候就需要使用通配符。
查找b开头并且是三个字符所对应的数值
| b | =VLOOKUP(I99&“??”,F95:G103,2,0) |
vlookup引用数据透视表
我们首先选中源数据的任意单元格,点击插入选项卡下的表格–数据透视表。
在选中放置数据透视表的位置选项下,选中现有工作表,选取一个空白位置(我这里选择的是O105)
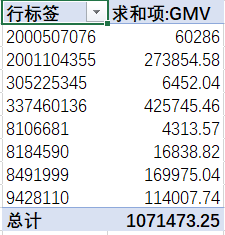
数据透视表的范围是O105:P114
接下来我们需要用vlookup引用数据透视表。
| 门店ID | GMV |
|---|---|
| 2001104355 | =VLOOKUP(O96,$O$106:$P$113,2,0) |
| 8184590 | |
| 305225345 | |
| 2000507076 | |
| 8106681 | |
| 8491999 | |
| 337460136 | |
| 9428110 |
这里要注意对数据透视表的范围进行绝对引用(固定)。
8.index和match函数
让excel自动根据列名去源数据里找对应的数值,完成聚合运算。
MATCH函数语法
MATCH(lookup_value, lookup_array, [match_type])
MATCH 函数语法具有下列参数:
-
lookup_value 必需。 要在 *lookup_array* 中匹配的值。 例如,如果要在电话簿中查找某人的电话号码,则应该将姓名作为查找值,但实际上需要的是电话号码。
*lookup_value* 参数可以为值(数字、文本或逻辑值)或对数字、文本或逻辑值的单元格引用。
-
lookup_array 必需。 要搜索的单元格区域。
-
match_type 可选。 数字 -1、0 或 1。 *match_type* 参数指定 Excel 如何将 *lookup_value* 与 *lookup_array* 中的值匹配。 此参数的默认值为 1。
MATCH函数是查找一个值在一个序列(一行或者一列)中的第几个位置。
从编程的角度可以理解为,有一个数组array=[a,b,c,d,e,f,g],查找一个值a在数组array中的索引(第几个位置),match会返回1;查找e,返回5。
举例:
| B | |
|---|---|
| 111 | 平台门店名称 |
| 112 | 蛙小辣·美蛙火锅杯(宝山店) |
| 113 | 蛙小辣火锅杯(合生汇店) |
| 114 | 蛙小辣火锅杯(龙阳广场店) |
| 115 | 蛙小辣火锅杯(五角场店) |
| 116 | 蛙小辣·美蛙火锅杯(长风大悦城店) |
| 117 | 蛙小辣火锅杯(宝山店) |
| 118 | 蛙小辣火锅杯(五角场店) |
| 119 | 蛙小辣火锅杯麻辣烫(五角场店) |
| 120 | 蛙小辣·美蛙火锅杯(五角场店) |
| 121 | 蛙小辣·美蛙火锅杯麻辣烫(宝山店) |
| 122 | 蛙小辣·美蛙火锅杯麻辣烫(五角场店) |
| 123 | 蛙小辣·美蛙火锅杯麻辣烫(五角场店) |
| 124 | 拌客干拌麻辣烫(武宁路店) |
| 125 | 拌客·干拌麻辣烫(武宁路店) |
| 126 | 拌客干拌麻辣烫(武宁路店) |
查询B115 蛙小辣火锅杯(五角场店)在B列中(不包含平台门店名称)的索引(第几个位置)
=MATCH(B115,B112:B126,0)
结果为4
| 平台门店名称 | 门店ID | 品牌名称 | 品牌ID | GMV | 进店人数 | 下单人数 |
|---|
查询品牌ID在这一行中是第几个
=MATCH("品牌ID",B111:I111,0)
结果是5
INDEX函数语法
INDEX(array,row_num,col_num)
INDEX(区域,行号,列号)
INDEX函数返回的是在一片区域内第几行第几列的值。
举例:
| 门店ID | 门店名称 |
|---|---|
| 2001104355 | 宝山店 |
| 8184590 | 五角场店 |
| 305225345 | 龙阳广场店 |
| 2000507076 | 五角场店 |
| 8106681 | 怒江路店 |
| 8491999 | 宝山店 |
| 337460136 | 拌客干拌麻辣烫(武宁路店) |
| 9428110 | 拌客干拌麻辣烫(武宁路店) |
我们希望查找上表中第4行第1列的值
=INDEX(B95:C103,4,1)
结果是305225345
我们可以将INDEX和MATCH嵌套使用。
举例:
| B | C | D | E | |
|---|---|---|---|---|
| 111 | 平台门店名称 | 门店ID | 品牌名称 | |
| 112 | 蛙小辣·美蛙火锅杯(宝山店) | |||
| 113 | 蛙小辣火锅杯(合生汇店) | |||
| 114 | 蛙小辣火锅杯(龙阳广场店) | |||
| 115 | 蛙小辣火锅杯(五角场店) | |||
| 116 | 蛙小辣·美蛙火锅杯(长风大悦城店) | |||
| 117 | 蛙小辣火锅杯(宝山店) | |||
| 118 | 蛙小辣火锅杯(五角场店) | |||
| 119 | 蛙小辣火锅杯麻辣烫(五角场店) | |||
| 120 | 蛙小辣·美蛙火锅杯(五角场店) | |||
| 121 | 蛙小辣·美蛙火锅杯麻辣烫(宝山店) | |||
| 122 | 蛙小辣·美蛙火锅杯麻辣烫(五角场店) | |||
| 123 | 蛙小辣·美蛙火锅杯麻辣烫(五角场店) | |||
| 124 | 拌客干拌麻辣烫(武宁路店) | |||
| 125 | 拌客·干拌麻辣烫(武宁路店) | |||
| 126 | 拌客干拌麻辣烫(武宁路店) |
=INDEX(B111:E126,MATCH(D111,D111:D126,0),MATCH(D111,B111:E111,0))
上面的函数查询结果是 门店ID
将存有结果的单元格向右拖拽,查询结果是 品牌名称
练习案例
我们希望根据左侧的平台门店名称,从源数据中求出门店ID等列。
| 平台门店名称 | 门店ID | 品牌名称 | 品牌ID | GMV | 进店人数 | 下单人数 | |
|---|---|---|---|---|---|---|---|
| 蛙小辣·美蛙火锅杯(宝山店) | |||||||
| 蛙小辣火锅杯(合生汇店) | |||||||
| 蛙小辣火锅杯(龙阳广场店) | |||||||
| 蛙小辣火锅杯(五角场店) | |||||||
| 蛙小辣·美蛙火锅杯(长风大悦城店) | |||||||
| 蛙小辣火锅杯(宝山店) | |||||||
| 蛙小辣火锅杯(五角场店) | |||||||
| 蛙小辣火锅杯麻辣烫(五角场店) | |||||||
| 蛙小辣·美蛙火锅杯(五角场店) | |||||||
| 蛙小辣·美蛙火锅杯麻辣烫(宝山店) | |||||||
| 蛙小辣·美蛙火锅杯麻辣烫(五角场店) | |||||||
| 蛙小辣·美蛙火锅杯麻辣烫(五角场店) | |||||||
| 拌客干拌麻辣烫(武宁路店) | |||||||
| 拌客·干拌麻辣烫(武宁路店) | |||||||
| 拌客干拌麻辣烫(武宁路店) |
我们使用INDEX函数,区域选中全部源数据(A:X)
=INDEX('拌客源数据1-8月'!$A:$X,row_num,col_num)
INDEX函数的第二个参数是row_num,即行数。**左侧的平台门店名称(蛙小辣·美蛙火锅杯(宝山店))和上方的列名称(门店ID)是处于同一行的。**所以我们想找到名为蛙小辣·美蛙火锅杯(宝山店)的门店ID在源数据中处于第几行,只需要找到蛙小辣·美蛙火锅杯(宝山店)在源数据中处于第几行。
这里我们使用MATCH函数。
MATCH($B112,'拌客源数据1-8月'!$I:$I,0)
INDEX函数的第三个参数是col_num,即列数。我们想找到列名(门店ID)在源数据中处于第几列,即我们需要找到门店ID在源数据首行中处于第几个位置。
MATCH(D$111,'拌客源数据1-8月'!$A$1:$X$1,0)
通过嵌套的MATCH函数,我们锁定了行和列,再通过INDEX函数返回我们需要的值。
=INDEX('拌客源数据1-8月'!$A:$X,MATCH($B112,'拌客源数据1-8月'!$I:$I,0),MATCH(D$111,'拌客源数据1-8月'!$A$1:$X$1,0))
有一点我们需要注意!
-
我们对源数据区域的选择,都需要使用快捷键F4进行行和列的锁定。
-
我们希望在下拉的时候,上方列名不会改变,而在右拉的时候,上方列名进行改变(由门店ID变为品牌名称)所以我们需要对列名进行列锁定,即$B112
-
我们希望在右拉的时候,左侧平台门店名称不会改变,而在下拉的时候,左侧平台门店名称进行改变(由宝山店变为合生汇店)
所以我们需要对平台门店名称进行行锁定,即D$111
综上:
=INDEX('拌客源数据1-8月'!$A:$X,MATCH($B112,'拌客源数据1-8月'!$I:$I,0),MATCH(D$111,'拌客源数据1-8月'!$A$1:$X$1,0))
我们向下拖拽和向右拖拽后,自动填充门店ID、品牌名称和品牌ID列。
还剩下三列GMV、进店人数、下单人数
我们通过SUMIF和INDEX+MATCH联用。
INDEX函数如果行位置是0的话,会返回整列;如果列位置是0的话,会返回整行。
我们使用SUMIF函数来聚合数据。
- SUMIF的第一个参数:判断的区域,这里是平台门店名称这一整列
INDEX('拌客源数据1-8月'!$A:$X,0,MATCH("平台门店名称",'拌客源数据1-8月'!$1:$1,0))
INDEX函数第一个参数代表整个源数据,第二个参数为0代表选中一整列,第三个参数是MATCH函数,返回的是平台门店名称在源数据首行的第几个位置。
整个INDEX函数的结果是返回了平台门店名称这一整列。
需要注意源数据的位置都应该锁住。
-
SUMIF的第二个参数:判断条件,这里是$B112,即左侧的平台门店名称。
-
SUMIF的第三个参数:求和区域,这里是上方列名(GMV)。
INDEX('拌客源数据1-8月'!$A:$X,0,MATCH(G$111,'拌客源数据1-8月'!$1:$1,0)
INDEX函数第一个参数代表整个源数据,第二个参数为0代表选中一整列,第三个参数是MATCH函数,返回的是上方列名G$111在源数据首行中的第几个位置。
整个INDEX函数的结果是返回了上方列名(GMV)在源数据中的一整列。
综上:
=SUMIF(INDEX('拌客源数据1-8月'!$A:$X,0,MATCH("平台门店名称",'拌客源数据1-8月'!$1:$1,0)),$B112,INDEX('拌客源数据1-8月'!$A:$X,0,MATCH(G$111,'拌客源数据1-8月'!$1:$1,0)))
需要注意行列的锁定。
向下向右拖拽,填充其他单元格。
函数部分总结:

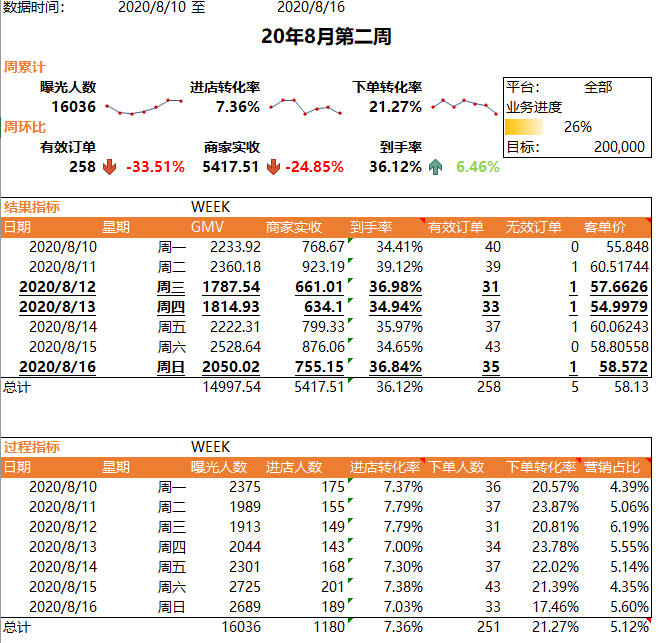
四、周报开发
一切美化工作都放到最后去做。
我们在日期列的第一行输入2020-08-10,然后第二行引用第一行的单元格+1,从第二行开始向下拖拽。
这时候如果我们改变第一个单元格的值,其他日期也会随之改变。
平台部分点击数据选项卡下的数据验证,将验证条件改为允许序列,数据来源输入 全部,美团,饿了么
GMV列的函数逻辑:如果平台是全部,则直接求GMV;如果平台是美团或饿了么,则需要使用SUMIF/SUMIFS
if(平台=全部,sumif(日期列,日期,GMV),sumifs(GMV,日期列,日期,平台列,平台))
第一版GMV列:
=IF($H$5="全部",SUMIF('拌客源数据1-8月'!$A:$A,$A13,'拌客源数据1-8月'!$J:$J),SUMIFS('拌客源数据1-8月'!$J:$J,'拌客源数据1-8月'!$A:$A,$A13,'拌客源数据1-8月'!$H:$H,$H$5))
我们再使用INDEX+MATCH函数对第一版进行改进。
=IF($H$5="全部",SUMIF('拌客源数据1-8月'!$A:$A,$A13,INDEX('拌客源数据1-8月'!$A:$X,0,MATCH(C$12,'拌客源数据1-8月'!$1:$1,0))),SUMIFS(INDEX('拌客源数据1-8月'!$A:$X,0,MATCH(C$12,'拌客源数据1-8月'!$1:$1,0)),'拌客源数据1-8月'!$A:$A,$A13,'拌客源数据1-8月'!$H:$H,$H$5))
我们对日期列不需要进行修改,只需要使用INDEX+MATCH修改上方列名。
向下、向右拖拽,得到部分结果。
到手率、客单价、进店转化率、下单转化率这四列只需要引用已经计算出来的单元格做除法即可。
我们还剩下一列营销占比需要计算。
营销占比=cpc总费用/GMV
我们的源数据中是有cpc总费用这一列的,所以我们把所有GMV(C$12)的位置直接改为"cpc总费用",再除以GMV单元格的引用即可。
=IF($H$5="全部",SUMIF('拌客源数据1-8月'!$A:$A,$A13,INDEX('拌客源数据1-8月'!$A:$X,0,MATCH("cpc总费用",'拌客源数据1-8月'!$1:$1,0))),SUMIFS(INDEX('拌客源数据1-8月'!$A:$X,0,MATCH("cpc总费用",'拌客源数据1-8月'!$1:$1,0)),'拌客源数据1-8月'!$A:$A,$A13,'拌客源数据1-8月'!$H:$H,$H$5))/C13
点击总计行的单元格,使用Alt+=快捷键快速求和。
现在只剩营销占比列的总计待求解。
营销占比总计=8-10至8-16的cpc总费用/8-10至8-16的GMV
=IF($H$5="全部",SUMIFS('拌客源数据1-8月'!T:T,'拌客源数据1-8月'!A:A,">="&A25,'拌客源数据1-8月'!A:A,"<="&B31),SUMIFS('拌客源数据1-8月'!T:T,'拌客源数据1-8月'!A:A,">="&A25,'拌客源数据1-8月'!A:A,"<="&B31,'拌客源数据1-8月'!H:H,H5))/C20
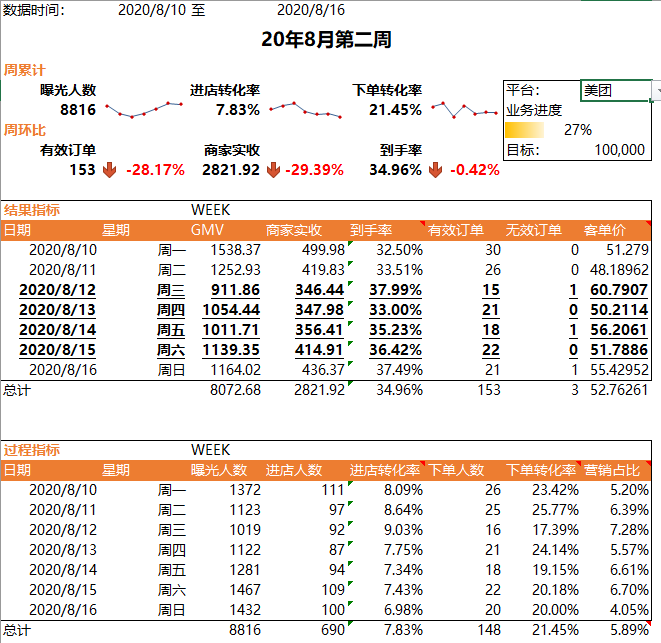
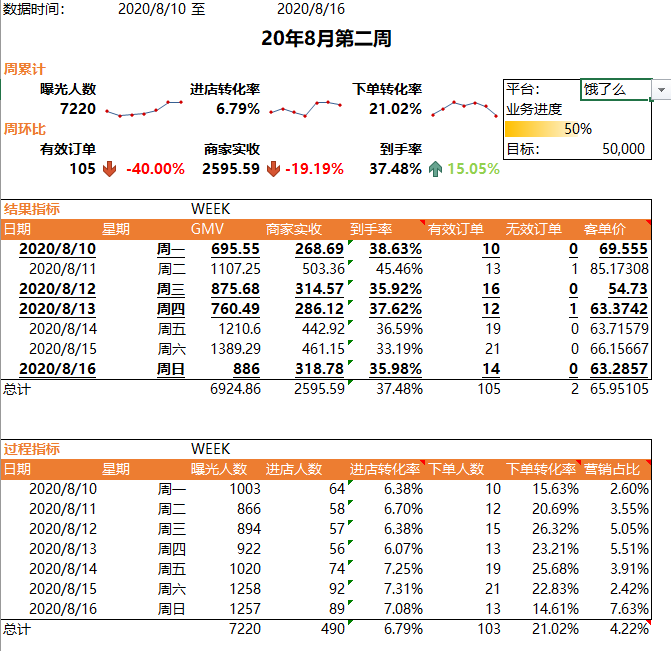
五、报表总览
全部
美团
饿了么










![[SpringBoot3]博客管理系统(源码放评论区了)](https://img-blog.csdnimg.cn/d27e6193a7954c6cac0034017445080c.png)

![[国产MCU]-W801开发实例-MQTT客户端通信](https://img-blog.csdnimg.cn/f6159728c6d74fc8bb888e440eddc698.png#pic_center)