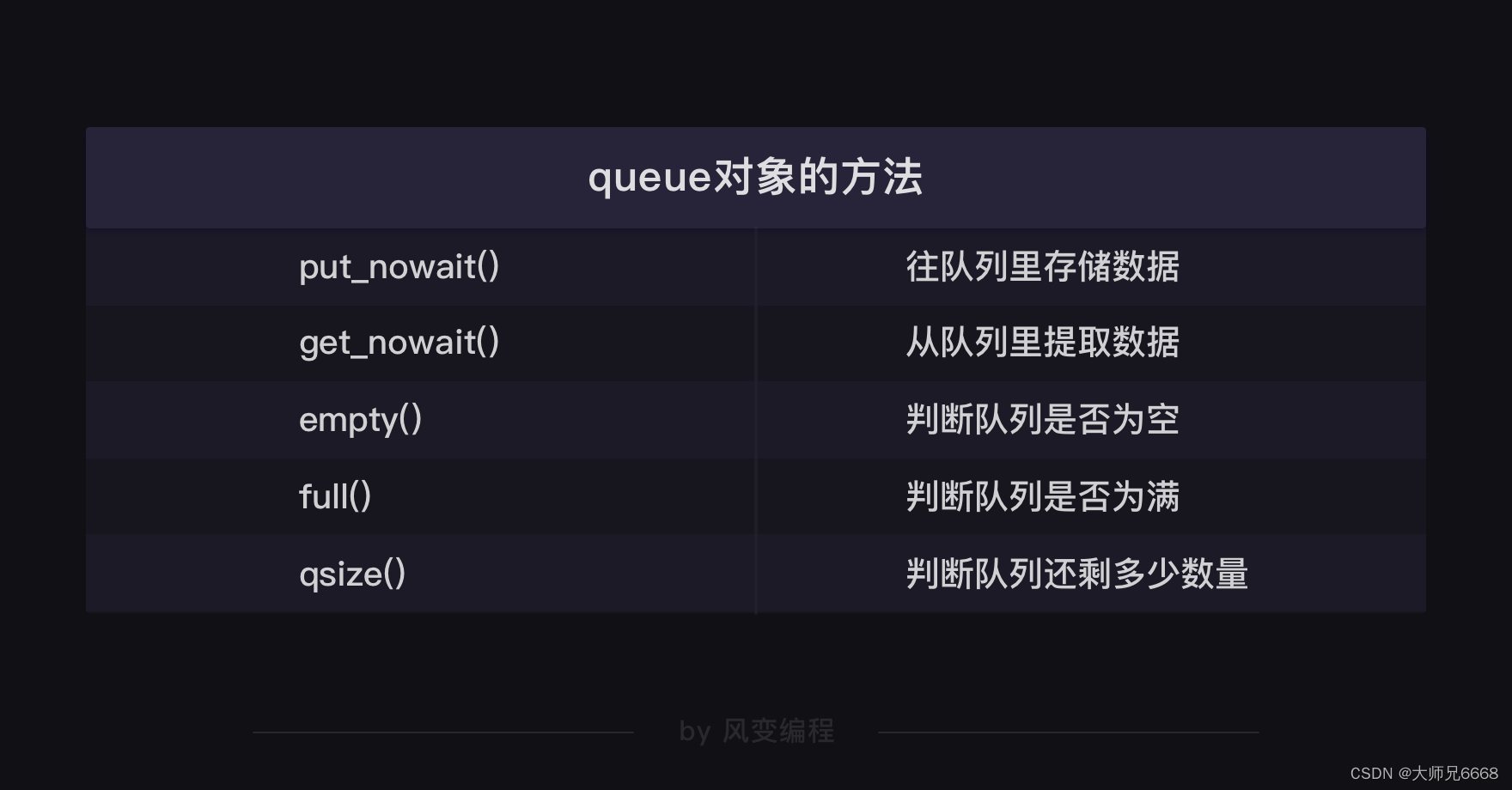
实现功能
依次遍历每一行,在某列包含某个元素时新增一列进行标记
实现代码
def province_distribution_of_colleges(self, file):df = pd.read_excel(os.path.join(self.datapath, file))df1 = dfhua_bei = ['北京市','天津市','河北省','山西省','内蒙古自治区']dong_bei = ['辽宁省','吉林省','黑龙江省']hua_dong = ['上海市','江苏省','浙江省','安徽省','福建省','江西省','山东省']hua_nan = ['广东省','广西壮族自治区','海南省']zhong_nan = ['湖南省','湖北省','河南省','江西省']xi_nan = ['重庆市','四川省','贵州省','云南省','西藏自治区']xi_bei = ['陕西省','甘肃省','青海省','宁夏回族自治区','新疆维吾尔自治区']gang_ao = ['香港特别行政区','澳门特别行政区']df1['区域'] = Nonefor index, row in df1.iterrows():if row['省份'] in hua_bei:df1.at[index, '区域'] = '华北'elif row['省份'] in dong_bei:df1.at[index, '区域'] = '东北'elif row['省份'] in hua_dong:df1.at[index, '区域'] = '华东'elif row['省份'] in hua_nan:df1.at[index, '区域'] = '华南'elif row['省份'] in zhong_nan:df1.at[index, '区域'] = '中南'elif row['省份'] in xi_nan:df1.at[index, '区域'] = '西南'elif row['省份'] in xi_bei:df1.at[index, '区域'] = '西北'elif row['省份'] in gang_ao:df1.at[index, '区域'] = '港澳'else:df1.at[index, '区域'] = '未知'print(df1)province_distribution_of_colleges('schools_with_coordinates.xlsx')实现效果
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据挖掘相关科研工作,对数据挖掘有一定认知和理解,会结合自身科研实践经历不定期分享关于python机器学习、深度学习、数据挖掘基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
邀请三个朋友关注V订阅号:数据杂坛,即可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。