目标
为期30天的用户数据,但是不是所有的用户都有30天的信息数据,比如用户A第7天注册的,则其前6天没有数据。
预测未来用户活跃度的可能性。 预测7天后的,基于第7天,预测第14天,基于第8天,预测第15天用户活跃度的可能性(0/1)
活跃用户定义为:在未来七天使用过APP
数据集分析
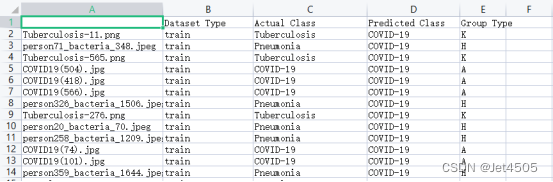
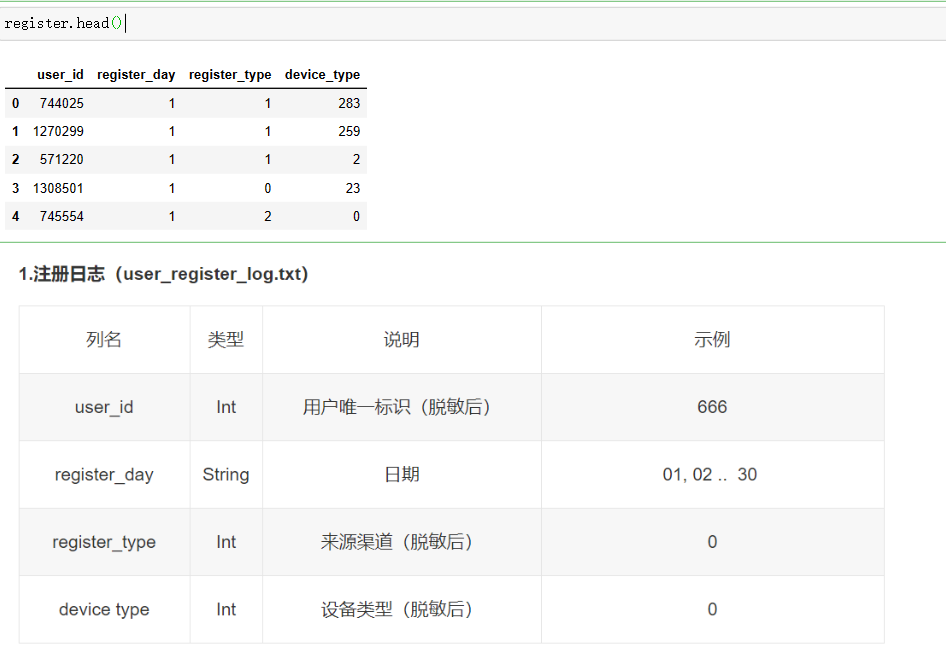
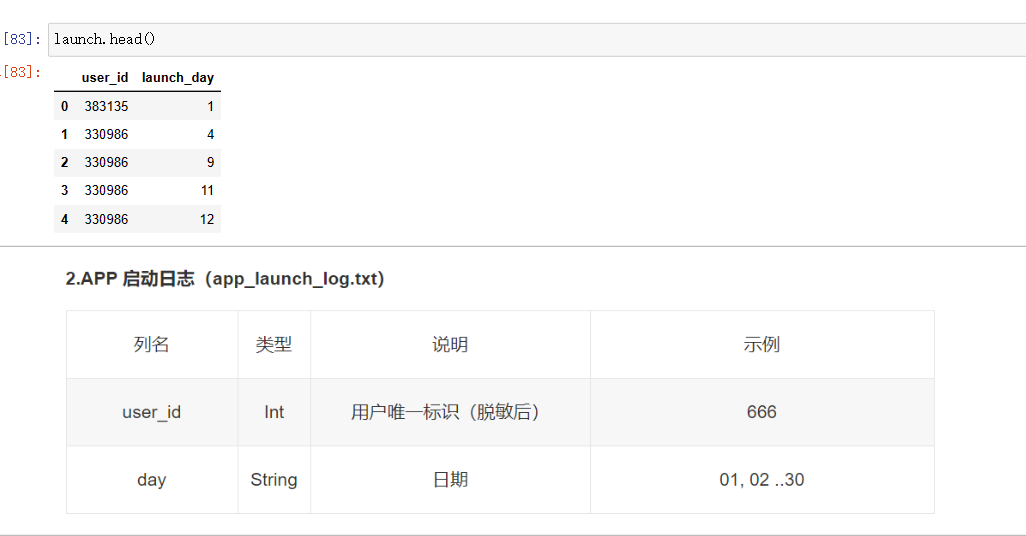
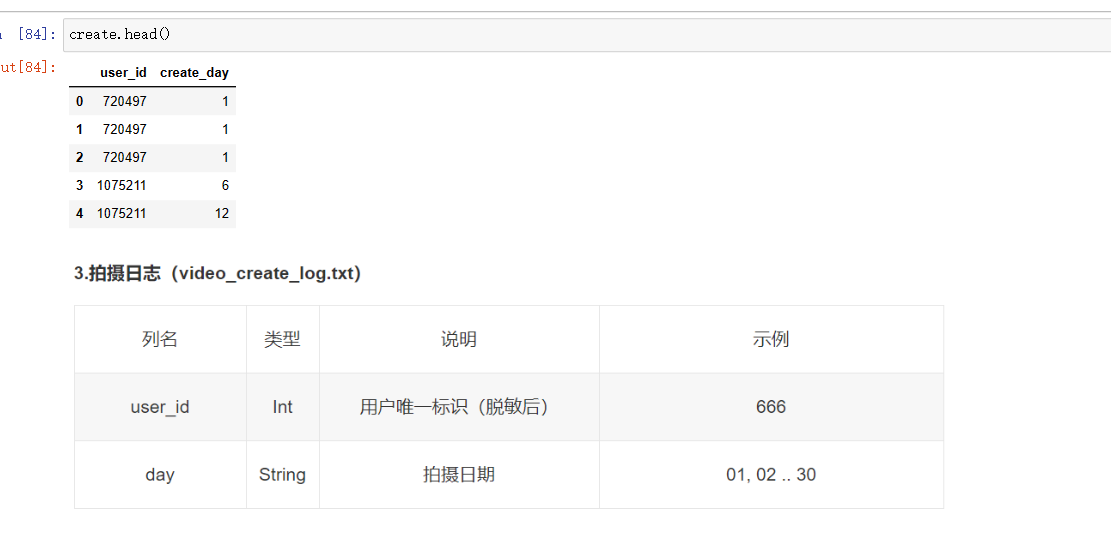
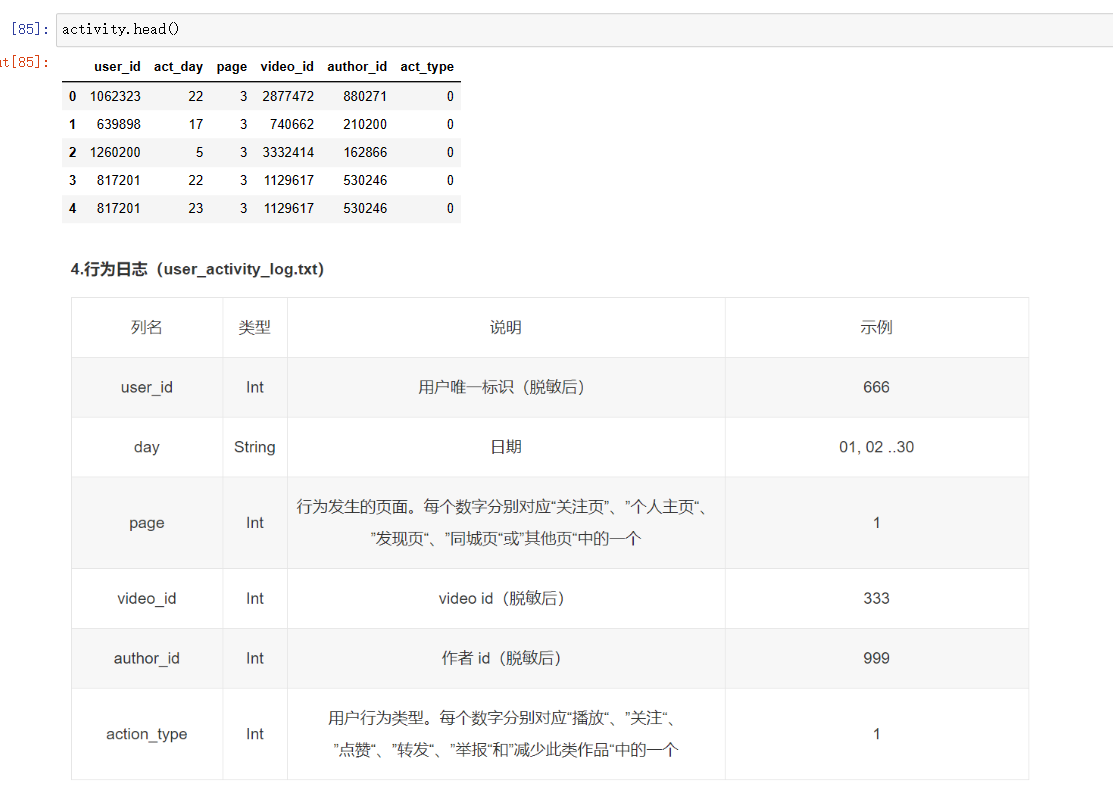
一共4份数据集,登陆日志、活跃日志、注册日志、视频创建日志
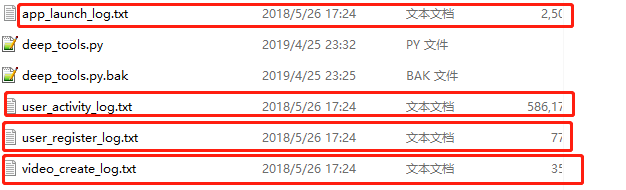
各数据集的内容
import pandas as pd
import numpy as np
import tensorflow as tf
import datetime
from deep_tools import f
from deep_tools import DataGenerator
register=pd.read_csv('user_register_log.txt',sep='\t',names=['user_id','register_day','register_type','device_type'])
launch=pd.read_csv('app_launch_log.txt',sep='\t',names=['user_id','launch_day'])
create=pd.read_csv('video_create_log.txt',sep='\t',names=['user_id','create_day'])
activity=pd.read_csv('user_activity_log.txt',sep='\t',names=['user_id','act_day','page','video_id','author_id','act_type'])
整体模型架构
预测未来7天的活跃度 tn+7
使用RNN(GRU 或者LSTM)
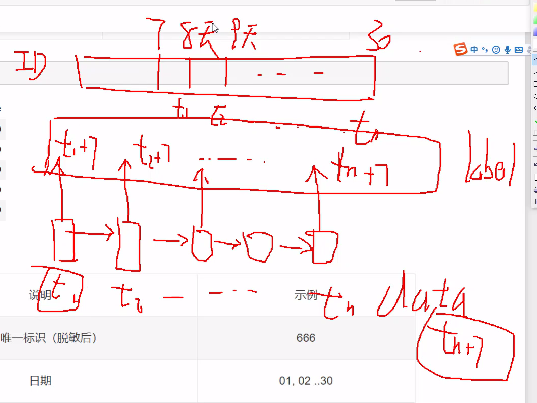
预测第8天的活跃度,只要有登陆或其他都动作,说明是活跃的。
构建label 序列 标签
基于数据是否有登陆,来进行序列打标
构建用户特征序列
每个用户id的序列长度
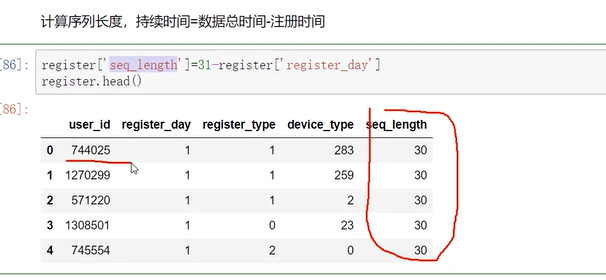
构建字典存储用户在持续时间内,不同日期的数据
取到用户长度,并将相应的用户id 放进去

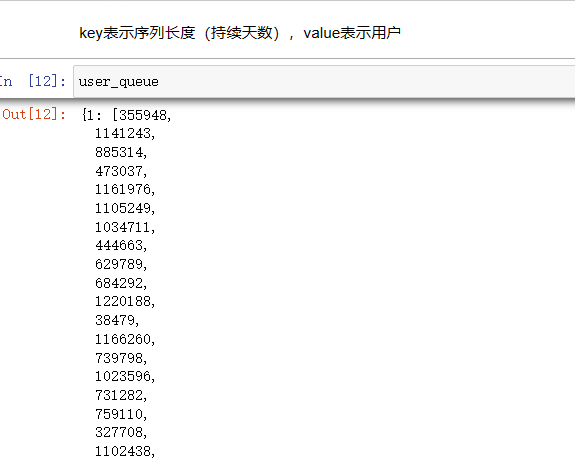
每个ID有一个长为30的序列,每个序列有12个特征,没有用0填充。
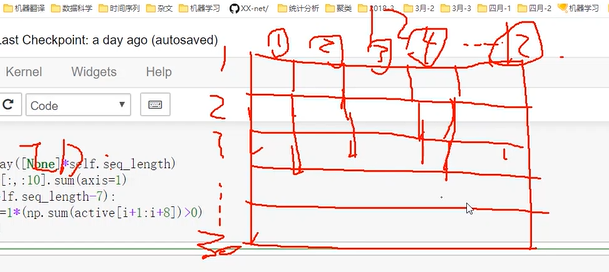
class user_seq:def __init__(self,register_day,seq_length,n_features):self.register_day=register_dayself.seq_length=seq_lengthself.array=np.zeros([self.seq_length,n_features]) #构建矩阵:持续天数*特征个数,后续新创建的特征来往里面填充self.array[0,0]=1self.page_rank=np.zeros([self.seq_length])self.pointer=1def put_feature(self,feature_number,string):for i in string.split(','):pos,value=i.split(':') #注册后第几天进行了登录,1为指示符self.array[int(pos)-self.register_day,feature_number]=1def put_PR(self,string):for i in string.split(','):pos,value=i.split(':')self.page_rank[int(pos)-self.register_day]=valuedef get_array(self):return self.arraydef get_label(self):self.label=np.array([None]*self.seq_length)active=self.array[:,:10].sum(axis=1)for i in range(self.seq_length-7):self.label[i]=1*(np.sum(active[i+1:i+8])>0)return self.label
n_features=12
data={row[0]:user_seq(register_day=row[1],seq_length=row[-1],n_features=n_features) for index,row in register.iterrows()}
Tips
- batch 内每个的序列长度都必须相同
- batch 与 batch 之间可以不一样
- 每个样本, 每个ID用户对应 sep_length*n_features
- 如果是使用随机森林、xgboost 等方法的话,还可以加入统计特性如 平均值、最值、等信息
- 本项目构建特征序列矩阵是为了使用RNN 方法
- 构建时序特征矩阵,然后基于RNN建立模型