文章目录
- 背景
- 什么是ElasticSearch
- 使用场景
- ElasticSearch的在linux环境下的安装部署
- 前期准备
- 分配权限(正式实操)
- 启动ElasticSearch
- 创建用户组
- 创建用户,并设置密码
- 用户添加到elasticsearch用户组
- 指定用户操作目录的一个操作权限
- 切换用户
- 解压elasticsearch
- 修改es的配置文件
- 修改jvm.option,调整jvm堆内存大小
- 可能出现的问题
- 启动
- 验证是否启动成功
- 总结提升
背景
最近项目中要做一个根据某关键字查询商家名称或查询聊天记录的一个功能。这里需要考虑到一个性能的问题,如果聊天的内容很多,怎么才能快速检索的要查询的信息。这里查阅了相关的资料,发现使用ElastSearch比较合适。下面展开关于ElasticSearch的相关内容介绍。
什么是ElasticSearch
Elasticsearch 被设计用于处理大规模数据集并实时查询。它可以快速地索引和搜索各种类型的数据,包括结构化、非结构化和地理空间数据。
是一个高度可扩展的分布式搜索和分析引擎,它能够处理海量数据的索引和检索,并提供实时查询和分析功能。它基于Apache Lucene库构建,使用倒排索引来高效地存储和搜索数据。
在Elasticsearch中,数据被划分为多个分片(shard),每个分片可以在不同的节点上进行复制和分布。这种分布式架构使得Elasticsearch具有高可用性和容错性,即使某个节点或分片发生故障,系统仍然可以继续工作。
Elasticsearch支持各种类型的数据,包括结构化数据、半结构化数据和非结构化数据。它不仅可以用于全文搜索,还可以进行复杂的查询、聚合分析和地理空间分析。您可以通过使用JSON格式来索引和查询数据,而无需预先定义数据模式。
通过使用Elasticsearch的RESTful API,您可以轻松地与其进行交互。您可以使用HTTP请求来执行各种操作,如索引文档、搜索、删除和更新数据。同时,Elasticsearch还提供了强大的查询DSL(Domain Specific Language),以便更灵活地构建查询语句。
除了核心功能之外,Elasticsearch还提供了插件生态系统,可以方便地扩展其功能。这些插件可以用于数据可视化、安全认证、监控和集成到其他工具和系统中。
它具有以下特点:
1、分布式架构:Elasticsearch 使用分片和复制机制来将数据分布在多个节点上,实现数据的水平扩展和高可用性。
2、实时搜索:Elasticsearch 提供了近乎实时的搜索性能,能够在毫秒级别内返回结果。
3、多种查询方式:Elasticsearch 支持全文搜索、精确匹配、模糊搜索、范围搜索等多种查询方式,以满足不同的搜索需求。
4、多样化的数据分析功能:Elasticsearch 提供了丰富的聚合(aggregation)和数据分析功能,如统计、分组、排序、过滤等,可以进行数据探索和可视化。
5、开放性和可扩展性:Elasticsearch 提供了丰富的 RESTful API,易于集成和扩展,同时还支持插件和扩展来满足各种定制化需求。
6、Elasticsearch 被广泛应用于各种场景,如搜索引擎、日志和事件数据分析、实时监控、产品推荐、安全分析等。它的使用范围涵盖了互联网公司、企业组织、科研机构和个人开发者等不同领域。
使用场景
Elasticsearch 在许多不同的场景中都有广泛的应用。以下是一些常见的使用场景:
1、搜索引擎和文档检索:Elasticsearch 能够快速地索引大量的文档数据,并提供高效的全文搜索功能。它被广泛用于构建搜索引擎、内容管理系统(CMS)和知识库等应用。
2、实时日志和事件数据分析:Elasticsearch 可以接收和索引实时产生的日志和事件数据,并提供强大的搜索和分析能力。它被广泛用于系统日志、应用日志、安全日志和运营监控等领域。
3、电子商务和产品推荐:Elasticsearch 可以用于构建电子商务网站的商品搜索和过滤功能。它还可以与机器学习算法结合,实现个性化的推荐系统。
4、数据分析和聚合:Elasticsearch 提供了丰富的聚合功能,可以对索引的数据进行统计、分组、排序和过滤等操作。它可以用于从大规模数据集中提取有价值的信息和洞察。
5、地理空间数据分析:Elasticsearch 内置了地理空间功能,可以索引和查询地理位置数据。它适用于地理信息系统(GIS)、位置搜索和地理可视化等应用。
6、全文搜索和自动补全:Elasticsearch 提供了强大的全文搜索功能,支持各种类型的查询,如模糊搜索、关键词匹配和范围搜索。它还可以通过自动补全功能提供即时的搜索建议。
7、实时监控和报警:Elasticsearch 可以接收和处理实时产生的指标数据,并提供实时的仪表板和报警功能。它被广泛用于应用性能监控、系统运维和大规模分布式系统的监控。
8、智能搜索和语义分析:Elasticsearch 可以与自然语言处理(NLP)技术结合,实现智能搜索和语义分析功能。它可以理解查询意图,提供更准确的搜索结果。
此外,由于 Elasticsearch 具有高可扩展性和开放性,它还可以应用于更多的场景,如推荐系统、社交媒体分析、网络爬虫、数据挖掘和机器学习等。
ElasticSearch的在linux环境下的安装部署
前期准备
确保系统满足要求:检查您的 Linux 系统是否满足 Elasticsearch 的最低系统要求。例如,
1、确保您的系统具有足够的内存和磁盘空间,并且已经安装了 Java 运行时环境(JRE)。
2、安装 Java:Elasticsearch 是用 Java 编写的,因此您需要在系统上安装适当版本的 Java。可以使用以下命令验证 Java 是否已安装:
java -version
3、创建一个非特权用户:为了安全起见,建议使用专用的非特权用户来运行 Elasticsearch。您可以使用以下命令创建新用户并切换到该用户:
sudo adduser elasticsearch
sudo su - elasticsearch
下载 Elasticsearch:访问 Elasticsearch 官方网站https://www.elastic.co/cn/elasticsearch/下载合适的版本。您可以选择稳定版或预览版,根据自己的需求选择正确的版本。
分配权限(正式实操)
ES不能使用root来启动,必须使用普通用户才能安装启动。
启动ElasticSearch
创建用户组
创建了一个名字为elasticsearch的用户组
groupadd elasticsearch
创建用户,并设置密码
useradd gys
passwd xxx
用户添加到elasticsearch用户组
usermod -G elasticsearch gys
指定用户操作目录的一个操作权限
这里的前提是已经把elasticsearch压缩包解压,然后把gys用户的操作权限加到该文件下
chown -R gys /usr/local/elasticsearch/elasticsearch-7.6.1
使用
visudo
编辑权限,在root ALL=(ALL) ALL的下面加一段话,
gys ALL=(ALL) ALL
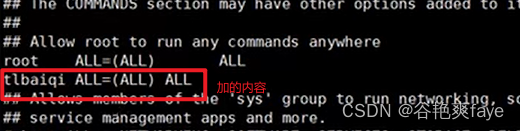
添加成功之后保存退出(esc,:wq)
切换用户
su gys
解压elasticsearch
在解压的过程中,可能会有人使用tar -zxvf+压缩文件,这里可能会遇到错误是:gzip: stdin: unexpected end of file,这样的错误信息。
那么可以把解压命令中的z去掉,也就是 tar-xvf。
或者可能有人会使用finalshell直接把文件进去,可能也会遇到类似的问题,这里建议使用上传文件,如果直接拖进去可能会造成压缩包的文件缺失。
修改es的配置文件
进入到es的config目录
cd /usr/local/elasticsearch/elasticsearch-7.6.1/config
修改相关信息
vim elasticsearch.yml
把cluster.name…解开注释

node.name解开注释
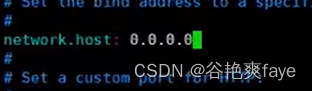
network.host解开注释,并设置为0.0.0.0,任意主机都能访问到
http.port解开注释
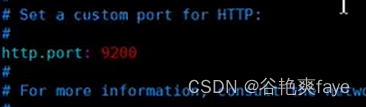
cluster.initial_master_nodes解开注释,这里和节点的名称是一致的

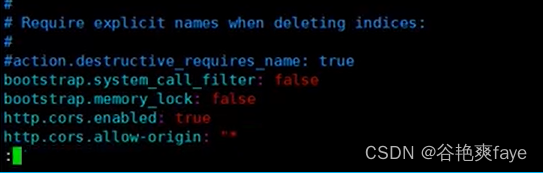
把这些信息加到配置文件的最后
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true //设置跨域
http.cors.allow-origin: "*"
具体含义:
bootstrap.system_call_filter: false:该配置用于禁用 Elasticsearch 在启动时检查系统调用过滤器。系统调用过滤器是一种安全机制,用于限制 Elasticsearch 进程能够执行的系统调用。通过将此配置设置为 false,Elasticsearch 将跳过系统调用过滤器的检查。
bootstrap.memory_lock: false:Elasticsearch 使用内存锁定(mlock)来确保其分配的堆内存不会被交换到磁盘或页面文件中。将该配置设置为 false 表示禁用内存锁定。禁用内存锁定可能会导致 Elasticsearch 在高负载情况下出现性能问题,因为操作系统可能会将内存页交换到磁盘上。
http.cors.enabled: true:该配置用于启用跨源资源共享(CORS)。CORS 是一种浏览器安全机制,用于控制不同源网站之间的资源访问权限。通过将此配置设置为 true,Elasticsearch 将允许来自任何源的跨域 HTTP 请求。
http.cors.allow-origin: “*”:该配置指定允许的跨域请求的来源。通配符 * 表示允许来自任何源的跨域请求。您也可以指定特定的域名或 IP 地址。
然后保存并退出
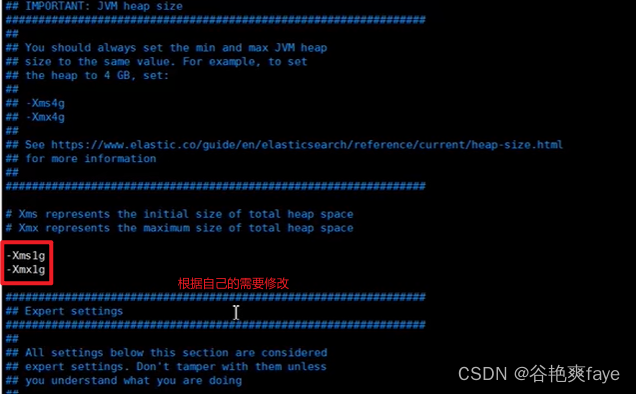
修改jvm.option,调整jvm堆内存大小
cd /usr/local/elasticsearch/elasticsearch-7.6.1/configvi jvm.options
可能出现的问题
1、普通用户打开文案金的最大数限制
问题错误信息描述:
max file descriptors [4096]for elasticsearch process likely too low.increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除Iiux系统当中打开文件最大数目的限制,不然ES启动就会抛错
三台机器使用baiqil用户执行以下命令解除打开文件数据的限制
进入文件:
sudo vi /etc/security/limits.conf
加入以下内容:
* soft nofile 65535
* hard nofile 65535
保存退出
启动
进入到elassearch的bin目录下:
执行:
./elasticsearch -d
上面这种是后台运行,也就是服务器退出之后该程序还在运行状态中
或者使用该命令也是后台运行
nohup ./bin/elasticsearch > nohup.out 2>&1 &
验证是否启动成功
使用ip+9200在浏览器运行,如果出现下面这些说明是已经运行成功了。

总结提升
Elasticsearch 是一个开源的分布式搜索和分析引擎,具有强大的全文搜索能力和实时数据分析功能。下面是关于 Elasticsearch 的总结提升:
高性能的全文搜索:Elasticsearch 使用倒排索引和分布式搜索算法,能够快速地对海量数据进行全文搜索。它支持复杂的查询语法,并且能够智能地处理词干、拼写错误纠正和近义词等搜索相关性问题。
水平扩展和高可用性:Elasticsearch 可以轻松地水平扩展到多个节点,以应对高并发和大规模数据存储的需求。它使用分片和复制机制来保证数据的可靠性和高可用性,即使有节点故障也能确保系统的正常运行。
实时数据分析:Elasticsearch 不仅可以用于搜索,还可以用于实时数据分析和聚合。它支持聚合操作、多维度分析和可视化。通过与 Kibana 等工具的集成,可以方便地创建仪表盘和报表,帮助用户深入理解数据。
强大的插件生态系统:Elasticsearch 拥有丰富的插件生态系统,可以满足各种不同的业务需求。例如,通过插件可以实现与其他数据源的集成、自定义分析器和搜索过滤器、数据监控和警报等功能扩展。
多种语言支持:Elasticsearch 提供了多种语言的客户端库,方便开发者在各种编程语言中使用 Elasticsearch。无论是 Java、Python、JavaScript 还是其他主流语言,都可以轻松地与 Elasticsearch 进行交互。
易于安装和部署:Elasticsearch 的安装和部署相对简单,官方提供了各个操作系统的安装包和文档教程。它也适合在云环境中部署,如 AWS、Azure 和 Google Cloud 等。
总的来说,Elasticsearch 是一个功能强大、性能卓越的搜索和分析引擎,适用于各种场景,如电子商务网站的商品搜索、日志分析、实时监控等。通过合理的配置和优化,可以将其性能发挥到极致,提供快速、可靠的数据搜索和分析服务。