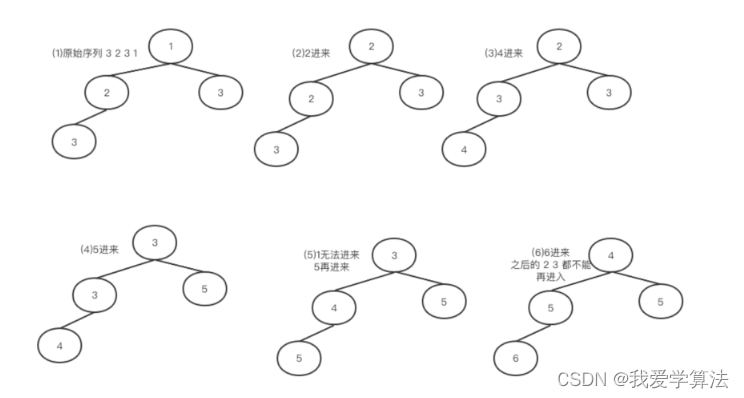
数据分片与分片算法
分库分表的第一性原理,那就是:存储容量和性能容量。只有对核心业务表才会精心进行分库分表的设计。
首先我们了解一下数据分片是什么意思?
本质上的分库分表不就是数据分片吗?定义就是:按照某个维度将存放在单个数据库中的数据进行拆分,将其分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。
数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。

未拆分前用户表和订单表放在同一个数据库中,垂直分片以后拆成了专门的用户库和订单库,形成了专库专用。垂直分片往往需要对架构和设计进行调整,它将原来一个单数据库的压力分担到不同的数据库,在一定程度上可以应对高并发场景。但是它无法真正的解决单点瓶颈。 如上所示,一个系统的用户量达到一定的规模以后增长就会放缓,但是订单库会随着时间的推移越来越大,按照垂直分库的方式还是无法解决订单库的存储压力和性能压力。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 所以说垂直拆分 可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
例如上图:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表)。假设 用户表原本有1000万的数据,进行水平分片以后,每个库(或表)只需要存放500万的数据。
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
分片策略
在做分库分表设计时,首先是需要在数据表中挑选出合适的分片键(这个我们放在后面单独讲),然后进行分布式架构设计
CREATE TABLE T_ORDER ( ORDER_IDbigint NOT NULL COMMENT '订单ID', USER_IDbigint NOT NULL COMMENT '用户ID', ADDRESS_IDbigint NOT NULL COMMENT '地址ID', ORDER_STATUSchar(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '订单状态', TOTAL_PRICEdecimal(15, 2) NOT NULL COMMENT '总价格', ORDER_DATEdate NOT NULL COMMENT '订单时间', ORDER_COMMENT varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '订单说明', PRIMARY KEY (ORDER_ID) USING BTREE )
对于上面的订单表T_ORDER,可以选择的分片键有:ORDER_ID 、USER_ID 也可以是 ORDER_DATE 。
在选出分片键后,就要选择分片的算法,比较常见的有 RANGE 和 HASH 算法。
RANGE 算法
比如,表 T_ORDER,选择分片键 ORDER_DATE,根据函数 YEAR 求出订单年份,然后根据RANGE 算法进行分片,这样就能设计出基于 RANGE 分片算法的分布式数据库架构:
从图中我们可以看到,采用 RANGE 算法进行分片后,表 T_ORDER 中,2001 年的订单数据存放在分片 1 中、2002 年的订单数据存放在分片 2 中、2003 年的订单数据存放在分片 3中,依次类推,如果要存放新年份的订单数据,追加新的分片即可。
不过,RANGE 分片算法在分布式数据库架构中,是一种非常糟糕的算法,因为对于分布式架构,通常希望能解决传统单实例数据库两个痛点:
性能可扩展,通过增加分片节点,性能可以线性提升;
存储容量可扩展,通过增加分片节点,解决单点存储容量的数据瓶颈。
那么对于订单表 T_ORDER 的 RANGE 分片算法来说,你会发现以上两点都无法实现,因为当年的数据依然存储在一个分片上(即热点还是存在于一个数据节点上)。
如果继续拆细呢?比如根据每天进行 RANGE 分片?这样的确会好一些,但是对“双 11、618”这样的大促来说,依然是单分片在工作,热点依然异常集中。
所以在分布式架构中,RANGE 分区算法是一种比较糟糕的算法。但它也有好处:可以方便数据在不同机器间进行迁移(migrate),比如要把分片 2 中 1992 年的数据迁移到分片 1,直接将表进行迁移就行。
而对于高并发的 On-Line Transaction Processing联机事务处理过程(OLTP)【面向交易处理过程】业务来说,一般推荐用 HASH 的分区算法。这样分片的每个节点都可以有实时的访问,每个节点负载都能相对平衡,从而实现性能和存储层的线性可扩展。
HASH 算法
我们来看表 T_ORDER 根据 ORDER_ID 进行 HASH 分片,分片算法如下:

在上述分片算法中,分片键是 ORDER_ID,总的分片数量是 4(即把原来 1 份数据打散到 4 张表中),具体来讲,分片算法是将 ORDER_ID 除以 4 进行取模操作。
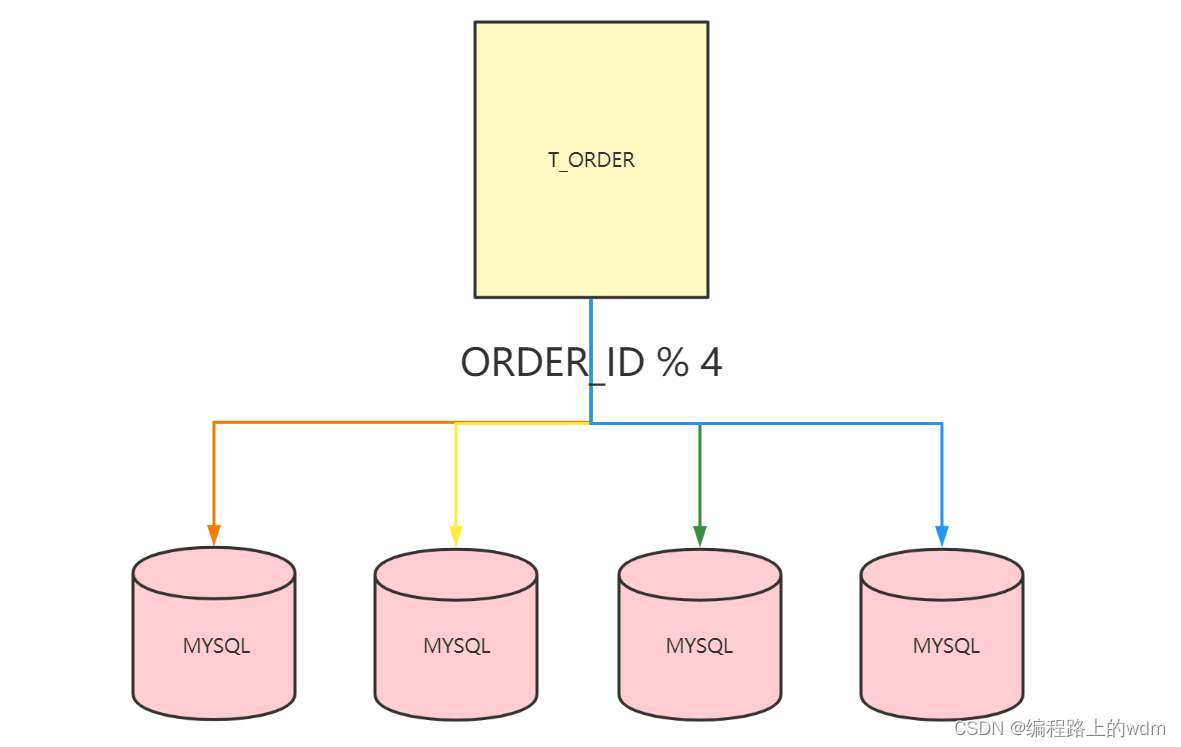
可以看到,对于订单号除以 4,余数为 0 的数据存放在分片 1 中,余数为 1 的数据存放在分片 2 中,余数为 2 的数据存放在分片 3 中,以此类推。
这种基于 HASH 算法的分片设计才能较好地应用于大型互联网业务,真正做到分布式数据库架构弹性可扩展的设计要求。
使用HASH算法可以将数据均匀的分散到多个分片中,在 上面的例子中,我们把数据分片到了 4 个节点,然而在生产环境中,推荐一开始就把分片的数量设置为一个比较大的数量。 因为使用HASH算法扩容时需要对一张表中的数据全部进行逻辑拆分,这个工作非常复杂,通常不推荐。