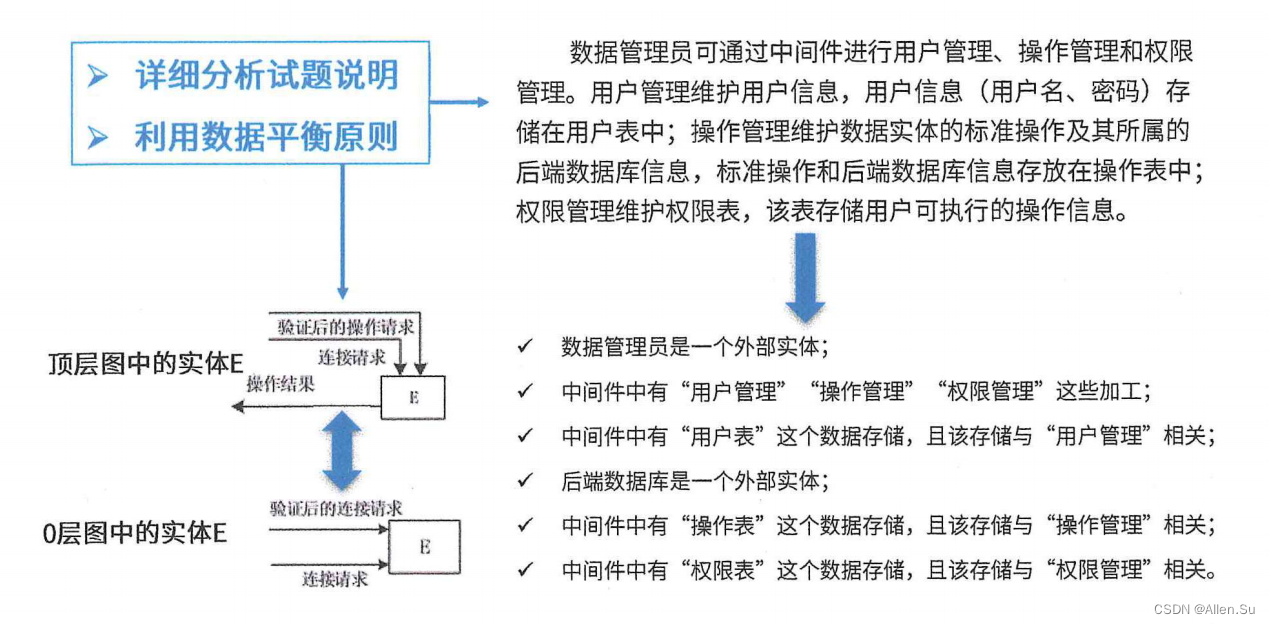
selenium本身是一个自动化测试工具。
它可以让python代码调用浏览器。并获取到浏览器中加们可以利用selenium提供的各项功能。帮助我们完成数据的抓取。它容易被网站识别到,所以有些网站爬不到。
它没有逻辑,只有相应的函数,直接搜索即可
提纲:
1.掌握 selenium发送请求,加载网页的方法
2.掌握 selenium简单的元素定位的方法
3.掌握 selenium的基础属性和方法
4.掌握 selenium退出的方法
安装
pip install selenium
用chrome浏览器
chrome驱动地址:http://chromedriver.storage.googleapis.com/index.html
需要下载对应版本的驱动,版本前三位一致即可,不用版本完全一致
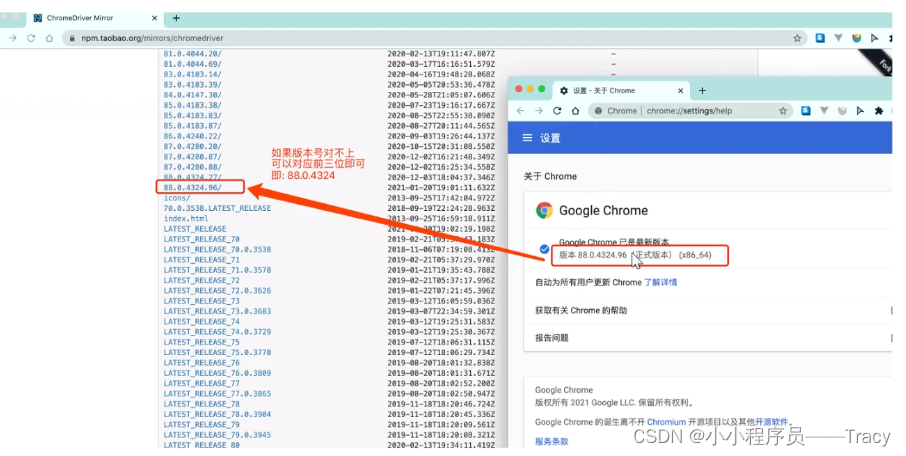
得到 chromdriver.exe 文件之后放在当前代码的文件夹下或者放在python解释器的文件夹内
Tips:Windwos: py-0p 查看Python路径
当谷歌浏览器自动更新之后 chromdriver.exe 就需要重新下载成对应的谷歌版本
版本不对的时候运行代码会报错
Selenium 使用过程:
1.加载网页
from selenium import webdriver //selenium的导包
from selenium.webdriver.common.by import By // 老版本就不需要写 By , 新版本就需要写 By
driver = webdriver.Chrome() // selenium创建driver对象,如果你的浏览器驱动放在了解释器文件夹,那么就不用写这个括号里的配置
driver = webdriver.Chrome(executable_path="chromedriver”) // 如果你的浏览器驱动放在了项目里这个配置就是为了告诉浏览器 chromedriver.exe 的位置在哪里#访问百度,根据 url 请求数据
driver.get("http://www.baidu.com/")
# 截图 只截取一屏
driver.save_screenshot("baidu.png")截取长图可以搜索 selenium 截长图2.定位和操作:
# 搜索关键字 杜卡迪
driver.find_element(By.ID,"kw").send keys("杜卡迪")
# 点击id为su的搜索按钮
driver.find_element(By.ID,"su").click()3、查看请求信息:
driver.page_source // 获取页面所有数据,如果之前还执行了滚动啊 点击啊 都会展示这些操作执行之后 这个页面所有的数据
# 获取页面内容
driver.get_cookies() // 获取 cookies 模拟登录
driver.current_url
4、退出
driver.close() # 退出当前页面
driver.quit ()# 退出浏览器time.sleep(3) //延迟3秒 需要 import time
元素定位的两种方式:
精确定位一个元素,返回结果为一个element对象,定位不到则报错
driver.find_element(By.xx, value) # 建议使用,新版本的写法
driver.find_element_by_xxx(value) // 老版本的写法By 之前需要引入
from selenium.webdriver.common.by import By定位一组元素,返回结果为element对象列表,定位不到返回空列表
driver.find_elements(By.xx,value) # 建议使用
driver.find_elements_by_xxx(value)元素定位的八种方法
以下方法在element之后添加“s”就变成能够获取一组元素的方法
定位后找到的原色都是节点(标签), 如果想要获取相关属性的值,需要调用相关的方法
By.ID 使用id值定位
el = driver.find element(By.ID,'') // 新版本写法
el = driver.find element by_id() //老版本写法
By.XPATH 使用xpath定位
el = driver.find element(By.XPATH,)
el = driver.find_element_by_xpath()driver.find_elements(By.XPATH,"//*[@id='s']/h1/a")
// 任意一个网页元素,都可以 f12 选中 右键 copy -> copy xpath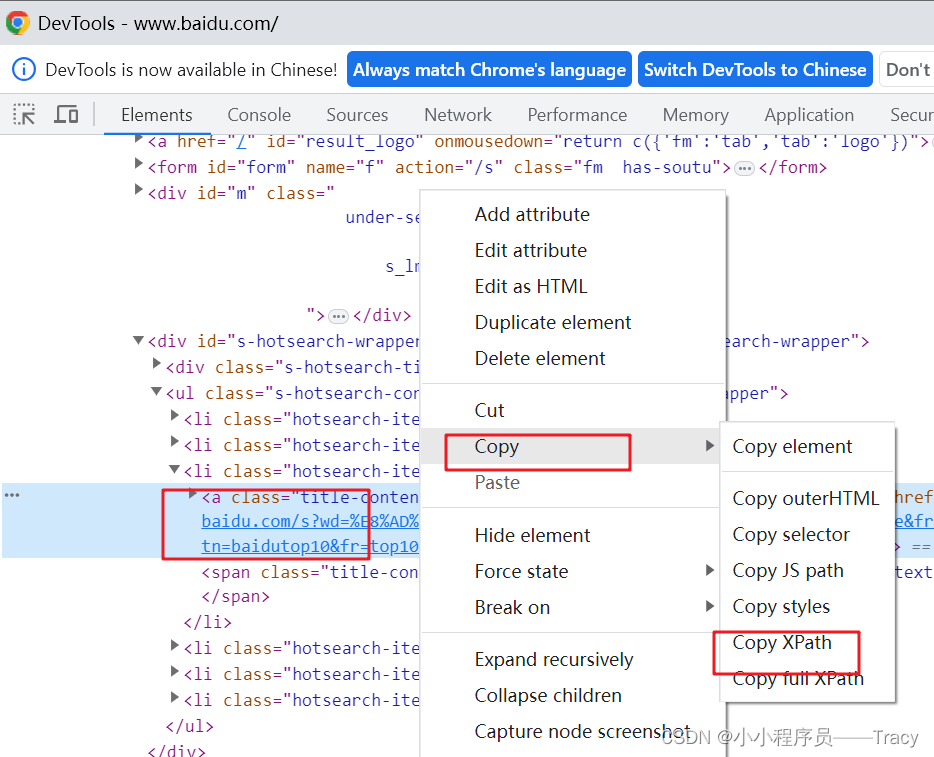
By.TAG_NAME.使用标签名定位
el = driver.find_element(By.TAG_NAME,')
el = driver.find element by_tag_name()a_list = driver.find_elements(By.TAG_NAME,"a") //查找所有 a 标签
By.LINK_TEXT使用超链接文本定位
el = driver.find_element(ByTLINK_TEXT,'')
el = driver.find _element by_link_text()driver.find_elements(By.LINK_TEXT,"下载豆瓣 App")By.PARTIAL LINK TEXT 使用部分超链接文本定位
比如模糊搜索 百度的百
el = driver.find_element(By.PARTIAL LINK TEX, '百')Tel = driver.find_element_by_partial_link_text(“百”)By.NAME 使用name属性值定位
el = driver.find_element(By.NAME, '')
el = driver.find_element_by_name()
By.CLASS_NAME使用class属性值定位
el = driver.find_element(By.CLASS NAME, '')
el = driver.find_element_by_class_name()driver.find_elements(By.CLASS_NAME, "box')
By.CSS_SELECTOR 使用css选择器定位
el = driver.find_element(By.CSS_SELECTOR,'')
el = driver.find_element_by_css_selector()
2、元素的操作
1.从定位到的元素中获取数据
el.get_attribufe(key) # 获取key属性名对应的属性值
el.text # 获取开闭标签之间的文本内容demo:
el.get_attribute("href")
href对应的链接,只对find_element()有效,列表对象没有这个属性
所以不能用 find_elements().get_arrtribute...1.对定位到的元素的操作
el.click() #对元素执行点击操作
el.submit() #对元素执行提交操作 比如说一个搜索框,输入文字之后,直接提交开始搜索方法
el.clear() # 清空可输入元素中的数据
el.send_keys(data) #向可输入元素输入数据
Cookie
获取cookie
dictCookies = driver.get cookies()设置cookie
driver.add_cookie(dictCookies)删除cookie
#删除一条cookie
driver.delete_cookie("CookieName")
# 删除所有的cookie
driver.delete_all_cookies()页面等等
为什么需要等待
如果网站采用了动态html技术,那么页面上的部分元素出现时间便不能确定,这个时候就可以设置一个时间,强制等待指定时间,等待结束之后进行元素定位,如果还是无法定位到则报错
也就是等待页面加载,放置还没有 load 完
显式等待(自动化web测试使用,爬虫基本不用)
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected conditions as ECWebDriverWait(driver,10,0.5).until( EC.presence of_element located((By.ID,"myDynamicElement")
#显式等待指定某个条件,然后设置最长等待时间19,在19秒内每隔8.5秒使用指定条件去定位元素,如果定位到元素则直接结束等待,如果在19秒结束之后仍未定位到元素则报错隐式等待 隐式等待设置之后代码中的所有元素定位都会做隐式等待
driver.implicitly_wait(10)# 在指定的n秒内每隔一段时间尝试定位元素,如果n秒结束还未被定位出
来则报错注意:
Selenium显示等待和隐式等待的区别
1I selenium的显示等待
原理,显示等待,就是明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception
(简而言之,就是直到元素出现才去操作,如果超时则报异常)
2、selenium的隐式等待
原理:隐式等待,就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段
时间,直到拿到某个元素位置。
注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素
3、switch方法切换的操作
3.1一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换。切换窗口的方法如下:
也可以使用 window handles 方法来获取每个窗口的操作对象。例如:
#1.获取当前所有的窗口
current windows = driver.window handles
#2.根据窗口索引进行切换
driver.switch_to.window(current_windows[1])
driver.switch_to.window(web.window handles[-1]) # 跳转到最后一个窗口driver.switch_to.window(current windows[o]) # 回到第一个窗口
iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是网不ameTw内容的,对应的解决思路是
传入的参数可以使iframe对应的id值,也可以是用元素定位之后的元素对象
driver.switch to.frame(name/el/id)
3.3 当你触发了某个事件之后,页面出现了弹窗提示,处理这个提示或者获取提示信息方法如下:
alert = driver.switch_to_alert()
页面前进和后退
driver.forward() # 前进
driver.back() # 后退
driver.refresh() # 刷新
driver.close() # 关闭当前窗口
设置浏览器最大窗口
driver.maximize window()#最大化浏览器窗口
模拟登录
//方式1,直接输入用户名密码验证码进行登录:
driver.find_element(byID, '验证码图片id').screenshot('code.png') //得到验证码图片//使用转码平台翻译这个验证码平台,这个基本是要花钱转译的。所以我们这里其实可以弄一个半自动自己来输入这个验证码
image_code = 一个转义的接口一般需要输入这个图片 url, 用户名,密码等driver.find_element(byID, '验证码输入框id').send_key(image_code)// 方式2, 保存 cookie 就不用每次登录了
cookies = driver.get_cookies() // 获取 cookies 模拟登录
console.log(cookies)
console.log(typeof(cookies))// 往文件里写入 cookies
写入文件方法1:
global.fs = require("fs");
fs.appendFileSync('tracy.json', stringify(cookies,null,4));
写入文件方法2:
with open('gsw.txt','w') as f
f.write(json.dumps(cookies)) //使用本地 cookies 进行登录
//读文件
with open('gsw.txt','r') as f
cookies = json.loads(f.read())这里可能还需要处理下 cookies 格式之类的
比如原来的cookie 是一个数组 那么需要遍历一下
for(cookie in cookits)
{cookit_dict = {};for( k, v in cookit.items){cookit_dict[k] = v}driver.add_cookie(cookit_dict)
}处理之后
driver.add_cookie(cookie) //把本地 cookies 存入网页 cookie 中
driver.refrech() //页面刷新 不刷新 cookie 可能没加载进去 会出现问题, 所以要刷新一下
刷新相当于重新访问服务器,这次携带了 cookie 来访问服务器 driver.get("登录成功之后进入的 url, 如个人中心")
异步加载的数据的访问
如:页面下滑加载更多
需要判断一下 是否已经到最后了,有些页面是一开始鼠标下滑往下请求然后需要点击加载更多按钮,然后会出现类似于“已经到最后啦”
import time
// driver.execute_script()
seLenium执行js代码
这里执行js滚动条的事件time.sleep(5)
driver.execute_script('window.scrollBy(0, 1000)')滚动步长
step_length = 2000
需要滚动的距离,这里自己估计大概的数值
stop_length = 3000
// 开始滚动
scroll_window(driver,stop_length, step_length)//封装一个循环的滚动函数
function scroll_window(driver, stop_length=0, step_length=2000){if (!stop_lengt) breakif stop_length - step_length <= 0 break;// seLenium执行js代码driver.execute_script('window.scrollBy(' + step_length' + ')')stop_Length -= step_Length // 减去每次滚动的步长time.sleep(1)
}const more = driver.find_element(....) // 得到加载更多按钮
more.click();//有的时候点击事件报错,有可能是因为点击的这个标签有一层我们看不见的遮罩层
//我们就可以用 js 进行点击
driver.execute_script('arguments[0].click();',more)循环点击自己估计点击次数
for (i in 6){console.log("第" + i + "次点击")
time.sleep(3)}等上面的东西都加载好之后driver.page_sourcer // 获取之前滚动啊 加载啊 之后的所有数据selenium的优缺点
优点
- oselenium能够执行页面上的is,对于is渲染的数据和模拟登陆处理起来非常容易
- 使用难度简单
- 爬取速度慢,爬取频率更像人的行为,天生能够应对一些反爬措施
缺点
- 由于selenium操作浏览器,因此会将发送所有的请求,因此占用网络带宽。由于操作浏览器,因此占用的内存非常大(相比较之前的爬虫)
- 速度慢,对干效率要求高的话不建议使用
selenium的配置
https://blog.csdn.net/qg 35999017/article/details/123922952
https://blog.csdn.net/qg 27109535/article/details/125468643
无头浏览器
我们已经基本了解了selenium的基本使用了.但是呢,不知各位有没有发现,每次打开浏览器的时间都比较长,这就比较耗时了.我们写的是爬虫程序.目的是数据.并不是想看网页.那能不能让浏览器在后台跑呢? 答案是可以的
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
opt = Options()
opt.add argument("_-headless")
opt.add argument('--disable-gpu')
opt.add argument(“_-window-size=40,1600") # 设置窗口大小driver = Chrome(options=opt)