【数据结构】二叉树的链式存储结构
二叉树的存储结构
typedef int BTDataType;
// 二叉树的结构
typedef struct BinaryTreeNode {BTDataType data; // 树的值struct BinaryTreeNode *left; // 左孩子struct BinaryTreeNode *right;// 右孩子
} BinaryTreeNode;
二叉树的深度优先遍历
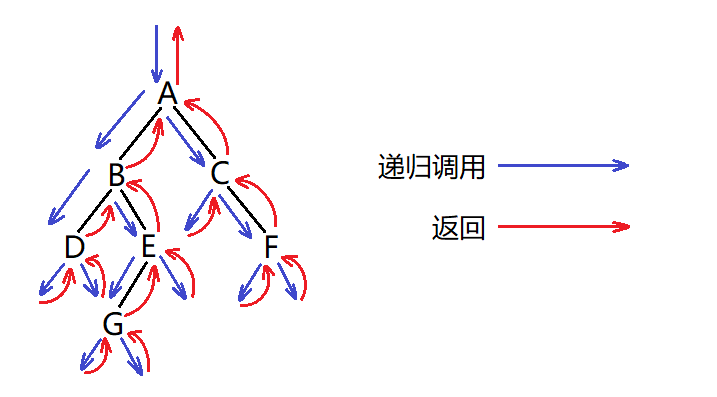
前序遍历
前序遍历,又叫先根遍历。
遍历顺序:根 -> 左子树 -> 右子树
代码:
// 前序遍历
void BinaryTreePrevOrder(BinaryTreeNode *root) {// 前序遍历 根、左子树、右子树// 如果root为空,递归结束if (root == NULL) {printf("NULL ");return;}printf("%d ", root->data);BinaryTreePrevOrder(root->left);BinaryTreePrevOrder(root->right);
}
中序遍历
中序遍历,又叫中根遍历。
遍历顺序:左子树 -> 根 -> 右子树
代码:
// 中序遍历
void BinaryTreeInOrder(BinaryTreeNode *root) {// 中序遍历 - 左子树、根、右子树if (root == NULL) {printf("NULL ");return;}BinaryTreeInOrder(root->left);printf("%d ", root->data);BinaryTreeInOrder(root->right);
}
后序遍历
后序遍历,又叫后根遍历。
遍历顺序:左子树 -> 右子树 -> 根
代码:
// 后序遍历
void BinaryPostOrder(BinaryTreeNode *root) {// 后序遍历 - 左子树、右子树、根if (root == NULL) {printf("NULL ");return;}BinaryPostOrder(root->left);BinaryPostOrder(root->right);printf("%d ", root->data);
}
二叉树的广度优先遍历
层序遍历
除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层 上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
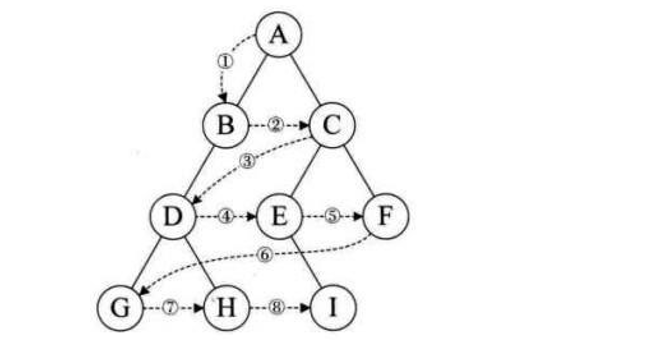
思路(借助一个队列):
- 先把根入队列,然后开始从队头出数据。
- 出队头的数据,把它的左孩子和右孩子依次从队尾入队列(NULL不入队列)。
- 重复进行步骤2,直到队列为空为止。

特点:借助队列先进先出的性质,上一层数据出队列的时候带入下一层数据。
// 层序遍历 - 利用队列
void BinaryTreeLevelOrder(BinaryTreeNode *root) {// 创建一个队列,队列中入数据,取队头,然后带左右子树,出一个数,带一个树的所有子树Queue q;QueueInit(&q);if (root) {// root不为NULL,就入队列QueuePush(&q, root);}while (!QueueEmpty(&q)) {// 取队头,打印BinaryTreeNode *front = QueueFront(&q);printf("%d ", front->data);// 取完POPQueuePop(&q);// 取队头,带下一层,if (front->left) {QueuePush(&q, front->left);}if (front->right) {QueuePush(&q, front->right);}}printf("\n");QueueDestroy(&q);
}
二叉树的节点个数
求解树的节点总数时,可以将问题拆解成子问题:
- 若为空,则结点个数为0。
- 若不为空,则结点个数 = 左子树节点个数 + 右子树节点个数 + 1(自己)。
代码:
// 求二叉树节点个数
int BinaryTreeSize(BinaryTreeNode *root) {if (root == NULL) {return 0;}return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right);
}
二叉树的叶子节点个数
子问题拆解:
- 若为空,则叶子结点个数为0。
- 若结点的左指针和右指针均为空,则叶子结点个数为1。
- 除上述两种情况外,说明该树存在子树,其叶子结点个数 = 左子树的叶子结点个数 + 右子树的叶子结点个数。
代码:
// 求二叉树的叶子节点个数
int BinaryTreeLeafSize(BinaryTreeNode *root) {if (root == NULL) {return 0;}if (root->left == NULL && root->right == NULL) {return 1;}return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}
第K层节点的个数
思路:
相对于根结点的第k层结点的个数 = 相对于以其左孩子为根的第k-1层结点的个数 + 相对于以其右孩子为根的第k-1层结点的个数。

代码:
// 求第k层的节点个数 k>=1
int BinaryTreeLevelSize(BinaryTreeNode *root, int k) {if (root == NULL) {return 0;}if (k == 1) {return 1;}return BinaryTreeLevelSize(root->left, k - 1) + BinaryTreeLevelSize(root->right, k - 1);
}
值为x的节点
子问题:
- 先判断根结点是否是目标结点。
- 再去左子树中寻找。
- 最后去右子树中寻找。
代码:
// 二叉树查找值为x的节点
BinaryTreeNode *BinaryTreeFind(BinaryTreeNode *root, BTDataType x) {if (root == NULL) {return NULL;}if (root->data == x) {return root;}// 左子树递归的节点保存到leftTree中,如果leftTree不为NULL,则return leftTreeBinaryTreeNode *leftTree = BinaryTreeFind(root->left, x);if (leftTree) {return leftTree;}// 右子树递归的节点保存到rightTree中,如果rightTree不为NULL,则return rightTreeBinaryTreeNode *rightTree = BinaryTreeFind(root->right, x);if (rightTree) {return rightTree;}// 找不到,返回NULLreturn NULL;
}
树的高度
子问题:
- 若为空,则深度为0。
- 若不为空,则树的最大深度 = 左右子树中深度较大的值 + 1。
代码:
// 求二叉树的高度
int BinaryTreeHeight(BinaryTreeNode *root) {// 求左子树的高度,右子树的高度// 取最大的if (root == NULL) {return 0;}int leftHeight = BinaryTreeHeight(root->left);int rightHeight = BinaryTreeHeight(root->right);//如果左右子树两边相等就取左边的高度,所以大于等于return leftHeight >= rightHeight ? leftHeight + 1 : rightHeight + 1;
}
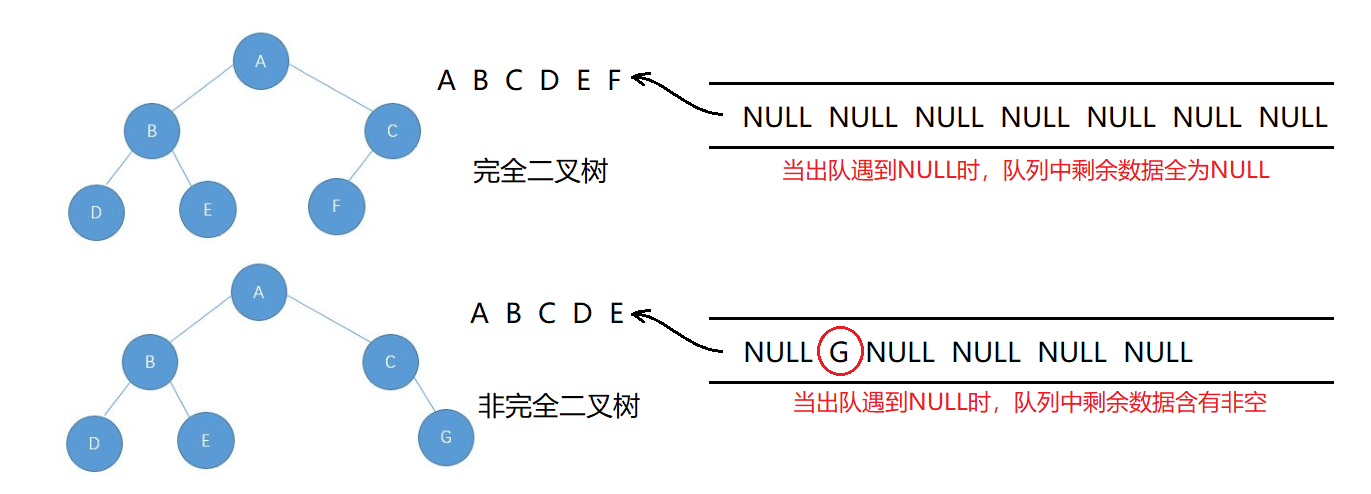
判断二叉树是否是完全二叉树
判断二叉树是否是完全二叉树的方法与二叉树的层序遍历类似,但又有一些不同。
思路(借助一个队列):
- 先把根入队列,然后开始从队头出数据。
- 出队头的数据,把它的左孩子和右孩子依次从队尾入队列(NULL也入队列)。
- 重复进行步骤2,直到读取到的队头数据为NULL时停止入队列。
- 检查队列中剩余数据,若全为NULL,则是完全二叉树;若其中有一个非空的数据,则不是完全二叉树。
代码:
// 判断二叉树是否是完全二叉树
bool BinaryTreeComplete(BinaryTreeNode *root) {// 层序走,走到第一个为空的时候,就跳出去,如果是满二叉树,后面的节点都应该为空Queue q;QueueInit(&q);if (root) {QueuePush(&q, root);}while (!QueueEmpty(&q)) {BinaryTreeNode *front = QueueFront(&q);QueuePop(&q);if (front == NULL) {break;} else {QueuePush(&q, front->left);QueuePush(&q, front->right);}}// 出到空以后,如果后面全是空,则是完全二叉树while (!QueueEmpty(&q)) {BinaryTreeNode *front = QueueFront(&q);QueuePop(&q);if (front != NULL) {QueueDestroy(&q);return false;}}QueueDestroy(&q);return true;
}
判断二叉树是否是单值二叉树
单值二叉树,所有节点的值都相同的二叉树即为单值二叉树,判断某一棵二叉树是否是单值二叉树的一般步骤如下:
- 判断根的左孩子的值与根结点是否相同。
- 判断根的右孩子的值与根结点是否相同。
- 判断以根的左孩子为根的二叉树是否是单值二叉树。
- 判断以根的右孩子为根的二叉树是否是单值二叉树。
若满足以上情况,则是单值二叉树。
注:空树也是单值二叉树。
代码:
//求单值二叉树
bool isUnivalTree(BinaryTreeNode *root) {if (root == nullptr) {return true;}if (root->left && root->data != root->left->data) {return false;}if (root->right && root->data != root->right->data) {return false;}return isUnivalTree(root->left) && isUnivalTree(root->right);
}
判断二叉树是否是对称二叉树
对称二叉树,这里所说的对称是指镜像对称:
要判断某二叉树是否是对称二叉树,则判断其根结点的左子树和右子树是否是镜像对称即可。因为是镜像对称,所以左子树的遍历方式和右子树的遍历方式是不同的,准确来说,左子树和右子树的遍历是反方向进行的。
代码:
//求对称二叉树
bool _isSymmetric(BinaryTreeNode *left, BinaryTreeNode *right) {// 两个都为NULL,对称if (left == NULL && right == NULL)return true;// 两个其中一个为NULL,一个不为NULL,不对称if (left == NULL || right == NULL)return false;// left的左孩子的值和right的值不相等,不对称if (left->data != right->data)return false;// 左子树的左孩子,和右子树的右孩子对比,然后左子树的右孩子和右子树的左孩子在对比return _isSymmetric(left->left, right->right) && _isSymmetric(left->right, right->left);
}bool isSymmetric(BinaryTreeNode *root) {if (root == nullptr) {return true;}return _isSymmetric(root->left, root->right);
}
翻转二叉树
思路:
- 翻转左子树。
- 翻转右子树。
- 交换左右子树的位置。
代码:
BinaryTreeNode *invertTree(BinaryTreeNode *root) {if (root == nullptr) {return nullptr;}BinaryTreeNode *leftTree = invertTree(root->left);BinaryTreeNode *rightTree = invertTree(root->right);root->left = rightTree;root->right = leftTree;return root;
}
二叉树的构建和销毁
// 申请树节点
BinaryTreeNode *BuyBinaryTreeNode(BTDataType x) {BinaryTreeNode *newnode = (BinaryTreeNode *) malloc(sizeof(BinaryTreeNode));if (newnode == NULL) {perror("malloc fail");exit(-1);}newnode->data = x;newnode->left = newnode->right = NULL;return newnode;
}// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BinaryTreeNode *BinaryTreeCreate(BTDataType *a, int *pi) {if (a[*pi] == '#') {(*pi)++;return NULL;}BinaryTreeNode *root = (BinaryTreeNode *) malloc(sizeof(BinaryTreeNode));if (root == NULL) {perror("malloc fail");exit(-1);}root->data = a[(*pi)++];root->left = BinaryTreeCreate(a, pi);root->right = BinaryTreeCreate(a, pi);return root;
}
销毁:
// 二叉树销毁
void BinaryTreeDestory(BinaryTreeNode **root) {if (*root == NULL) {return;}// 后序遍历销毁,根要最后释放BinaryTreeDestory(&(*root)->left);BinaryTreeDestory(&(*root)->right);free(*root);*root = NULL;
}










![深度学习-全连接神经网络-训练过程-欠拟合、过拟合和Dropout- [北邮鲁鹏]](https://img-blog.csdnimg.cn/335ba2d4b4b3432fb8863d88060031ef.png)