本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
缓存系统的高效存在前提,在满足前提的情况下可以接受缺陷便没有理由不引入缓存系统,但是具体影响因素需要仔细权衡,时序数据库只有常态极端场景下缓存有显著效果。
时序数据库缓存系统的可行性
我曾在[1]中讨论过在DB前放置缓存的缺陷,即:
- 外部缓存会增加延迟
- 外部缓存增加了不必要的成本
- 外部缓存会降低可用性
- 外部缓存破坏了数据库缓存
- 外部缓存忽略了数据库缓存能力和资源
[3]中提到DAX类缓存适合的场景:
- 需要低响应时间的业务
- 热点明显的应用
- 读取请求占总请求比例较高
- 不需要强一致性
我们从Gorilla的视角去看这个问题,现有基于HBase的TSDB性能过差,但是存量数据2PB又不想迁移,如何可以快速满足日益增长的业务需求?现有的需求是这样的:
- 写的可用性极其重要
- 需要较强的容错能力,能够承受频繁的单机,网络故障和版本发布
- 查询峰值40000/s,要求基本在10ms级别,且宕机时读不中断
- 一致性不那么重要,数据能反映具体趋势即可
- 临近的数据点比老旧的数据点更有意义
- 百分之八十五的查询聚集在过去26h
- 二十亿时间序列,每秒产生1200万个数据点,每天产生 1 万亿个数据点(每个数据点 16 字节,那就占用 16TB 内存)
- 系统需要高效的扩容机制
- 现有监控系统依赖于TSDB做图表分析(分为交互式和接口拉取)和告警,但是基于Hbase的TSDB查询P90高达几秒,对于交互式系统可以容忍,但是接口分析和告警无法接受
考虑下这种情况下基于memcache/redis的write-through cache是否可以生效呢?
论文中提到这种方法在加入一个新的时间序列时需要先判断时间序列是否存在,再执行插入,这意味着一个插入需要两个请求,对memcache的流量负载较高,所以否定了这种做法。
我认为还有一些问题:
- 时序数据库的查询常态是分析需求,很少存在点查,且查询语句where条件中的时间范围始终变化,这意味着这层缓存需要有查询聚合能力,并不是简单的kv接口可以实现,也就是说使用现有系统的memcache/redis是无效的;
- 超过缓存系统时限乱序数据的写入性能依旧很差,因为cache的有效时间是有限的,数据仍旧需要写入底层Hbase;
- 云原生数据库我们需要在云上售卖,在使用cache是如何做租户隔离?在cache上花费的精力其实无法让小用户收益,其次运营非常复杂,在一个大集群中存在大小客户时cache的粒度又该如何设置?
- cache存储什么数据?时序数据库不同于kv没有明显热点,且写入均衡,但是查询上因为告警/监控业务的特殊性最近的数据被访问的概率更大,所以做cache肯定是存最近的原始数据,也就是现在的Gorilla
当解决了这些问题后会发现,我们其实就是实现了一个计算+存储层,老数据降冷Hbase。
现有的云原生时序数据库比如InfluxDB IOX,Lindorm都是存算分离的,存储节点本身就是内存写入,随后将数据/索引写入远端存储(对象存储,分布式文件系统),这其实意味着在写入的角度来看已经是cache了,而且计算上在拥有计算下推能力时单查询性能时非常出色,且存储节点也可以用类似于Gorilla缓存原始数据。从这个角度看,如果把Gorilla看作缓存,Hbase看作远端存储,事实上这个架构和现有的时序数据库分布式是相似的。
以Lindorm举例,即Gorilla=TsCore+TsProxy,Hbase=DFS,Gorilla优势只有26H以内小查询会快。
如果不存在DFS,TsCore走三副本保障一致性,即Gorilla=TsCore+TsProxy,Hbase=TsCore,一般现有的时序数据库写入性能极高,cache带来的高写入吞吐已然没有意义,查询上Gorilla对于26H以内有压倒性优势,但是26H以外现有架构的方法显然是更优秀的(现有架构会趋向于老数据的元信息下刷磁盘,所以初次读取需要大量IO,后续读取和26H以内一样快),除此之外现有的时序数据库在一致性,扩缩容上也更具优势。以我们的运营经验来看,并不存在显著的“26H”这种数字,周级别的分析非常常见,且存在和上个周期的对比需求,也就是说视图选择1d,实际会查询2d,两条曲线做对比分析。
所以这篇论文的架构其实是在解决诸多约束下的现实问题,不是一个所有公司通用分布式解决方案。但是这篇文章发表在2015,在八年前互联网规模在别人还在mysql/Cassandra时能有这样的监控系统解决方案已经非常优秀,而且这篇文章现在来看最具实践意义的其实是时间戳 delta-of-delta和浮点压缩算法XOR,到现在仍旧广泛使用在时序数据的列存压缩,从这个角度讲这篇文章其实非常经典。
回归题目的后半部分,时序数据库缓存系统的可行性如何?
以现有云原生数据库发展来看,不可行,原因如下:
- 时序数据库不存在明显访问热点,只是最近数据相对于历史数据访问频率更高,所以缓存中不能存数据项,只能存新的数据集合
- 因为部分业务时序数据的敏感性,一致性要求较高,不允许数据丢失,意味着缓存只能write-through,所以只能用于加速读
- 时序查询需要计算引擎,意味着缓存系统需要有计算能力(开发复杂性),那么时序需要的缓存系统实际就是缓存最近数据的计算节点,现有的架构存储节点已经可以承担这部分功能,无非是数据的缓存机制更加灵活,不是只缓存某个时间段的数据
所以在现代TSDB前放置缓存就是用RAM去换部分查询的高效,显著增加成本的同时增加系统复杂性。
总结下Gorilla优缺点:
优点:
- 26H以内小查询性能高
- 解决现实问题,开发成本低(不需要做引擎,不需要做数据搬迁)
缺点:
- 依赖于85%查询26H以内数据
- 一致性较差
- 单点故障写入可用性依靠客户端hold住1m以内数据,存在服务中断时间,有数据延迟写入风险,对监控视图有影响
- 26H以外查询Hbase,性能较差,且基本无法优化
- 查询无法做计算下推,大查询可预料的性能低下
- 26H以内数据降采样/流式计算目前的实现存在Hbase,仍旧查询性能差
论文细节
压缩算法

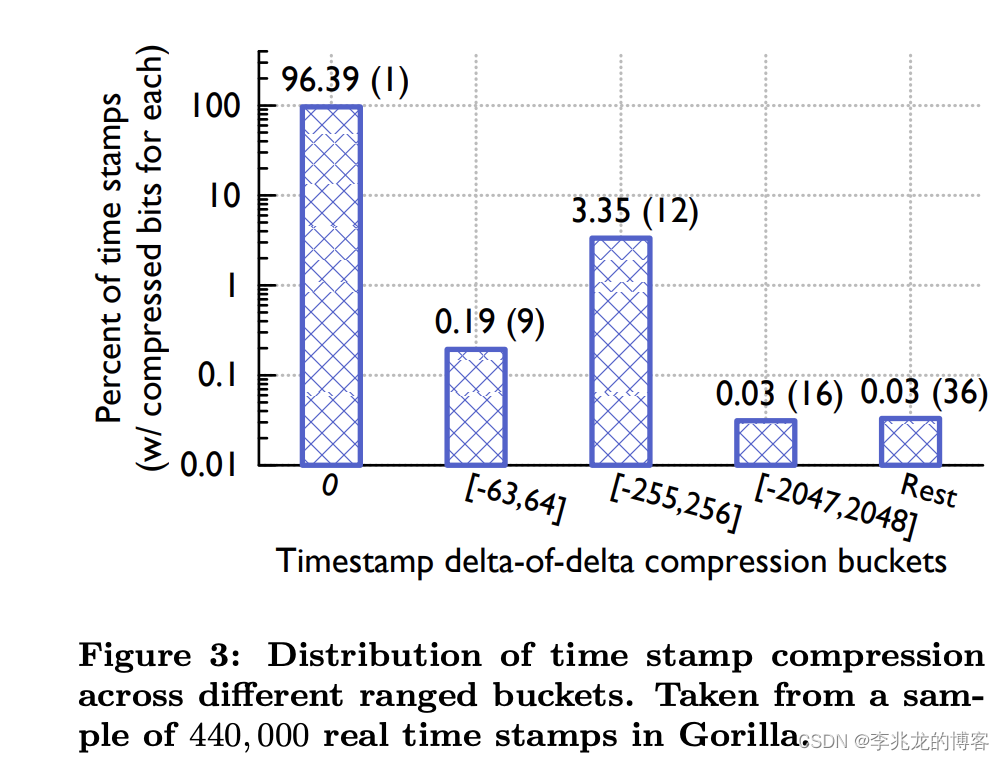
delta-of-delta
keypoints在于发现绝大多数数据点都是以固定间隔到达的。比如时间序列通常每 60 秒记录一个点,这样意味着单个时间序列的连续点时间戳是高度相似的,比如连续的时间60,60,59,61 只需要存储60,0,-1,2,稍加解析便可知道每个时间点具体值。
具体算法逻辑如下:

可以从下图看到效果非常显著,96%的数据点用一个比特就可以表示。
XOR
keypoint有两点:
- 发现大多数时间序列中的值与相邻数据点相比变化不大,这其实很好理解,很多时序数据的曲线基本是平缓的,比如成功率,请求数,利用率等。
- 数据相近的话sign, exponent, 以及尾部的几个比特基本一致
具体算法直接参考[2]即可,我就没必要搬运论文了。
memory / disk structures
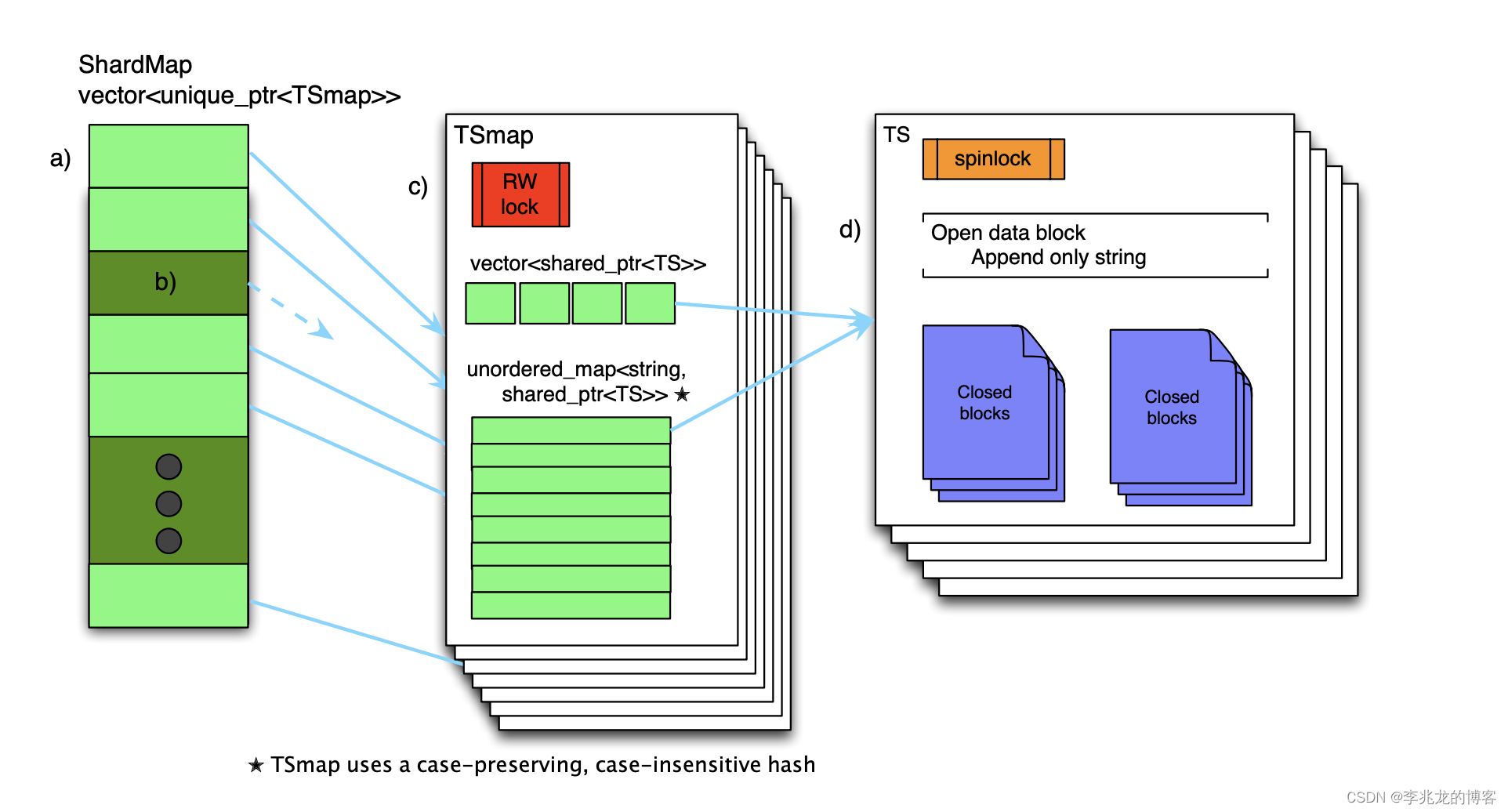
内存结构没有奇巧淫技:
- ShardMap存储两小时的shard,用于减小一个结构内时间线数量
- TSmap存储时间线到TS的指针,vector用于加速扫描数据
- TS用于存储append log和blocks,压缩章节中提到120个时间点一个block(平衡压缩和解析开销)
磁盘结构也相对简单:
- key lists:用于快速扫描数据,文中提到内存中封闭的block会执行重写,以重新分配内存,减少内存碎片
- append-only logs:用于单节点宕机时另外一个节点快速恢复非block的数据,在刷新之前数据缓冲64kB,所以宕机可能造成数据丢失
- complete block files:数据文件
- checkpoint files:用于标记完整的block文件何时刷新到磁盘,在进程崩溃时如果没有将block文件刷新到磁盘,当新进程启动时,checkpoint不存在,新进程读取append log
Handling failures
需要容忍单机故障(频繁发生,版本发布可以看作单点故障)和集群故障(需要在意外发生时保持运行)
主要措施有三点:
- multi region用于集群故障
- 单机故障时写请求:ShardManager 会将其故障节点负责的数据范围分配给集群中的其他节点,分配期间,客户端对接收到的数据进行缓冲。缓冲区的大小可容纳 1 分钟的数据,超过 1 分钟的数据点会被丢弃;当分配完成时接受写入。如果 Gorilla 主机以更可控的方式停机,它会在退出前将所有数据刷新到磁盘,所以软件升级不会丢失数据。
- 单机故障读:部分节点无法读取,查询将返回部分数据,并将结果标记为部分数据。当客户端库从故障区域查询中收到部分结果时,查询区域B,如果有完整的结果则返回。如果区域 A 和区域 B 都返回了部分结果,则这两个部分结果都会返回给调用者,并设置一个标志,说明某些错误导致了数据不完整。
Lessons learned
- Prioritize recent data over historical data
- Read latency matters
- High availability trumps resource efficiency
总结
基架的精髓是自我定位准确以及调教客户,切不可呈口舌之快,进而后患无穷。
参考:
- Don‘t Put a Cache in Front of Database
- Gorilla: 一个快速, 可扩展的, 内存式时序数据库
- In-memory acceleration with DynamoDB Accelerator (DAX)