最近在做面向大模型的文本标注工作,涉及到多人协同的问题,因此用到了doccano工具。
这个工具可以使用docker进行安装,安装之后的启动也都比较简单。
关于基础使用(例如管理员登录、新建任务、上传数据集等),可以参照这篇博客进行操作。
本文主要介绍多人协作场景下(包括新建用户、标注与质检、标注结果导出),如何针对多篇文档进行问答。
假设现在有4篇文档,有两位同学进行标注,一人进行质检,一人负责验收,还有一个admin,只有admin可以进行标注数据的导出。
1.Docker安装和启动
参照doccano官网的示例,可以下载并运行相关的镜像:
docker pull doccano/doccanodocker container create --name doccano \-e "ADMIN_USERNAME=admin" \-e "ADMIN_EMAIL=admin@example.com" \-e "ADMIN_PASSWORD=password" \-v doccano-db:/data \-p 8000:8000 doccano/doccanodocker container start doccano
然后执行docker ps 命令,确认已经开启doccano服务,对应的显示如下:
(base) xxx@xxx:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
756ac64acf56 doccano/doccano "/doccano/tools/run.…" 6 hours ago Up 4 seconds 0.0.0.0:8090->8000/tcp doccano
之后可以访问http://0.0.0.0:8090/并看到对应的界面。
2.基础使用
接下来介绍管理员登录、新建任务、上传数据集等基础操作。
2.1管理员登陆
使用上面docker container create中的账户和密码即可。
2.2新建任务
只需要点击登录之后左上角的“create”按钮即可。不同版本的“create”按钮可能会略有不同。我选择了新建“Sequence to sequence”任务。
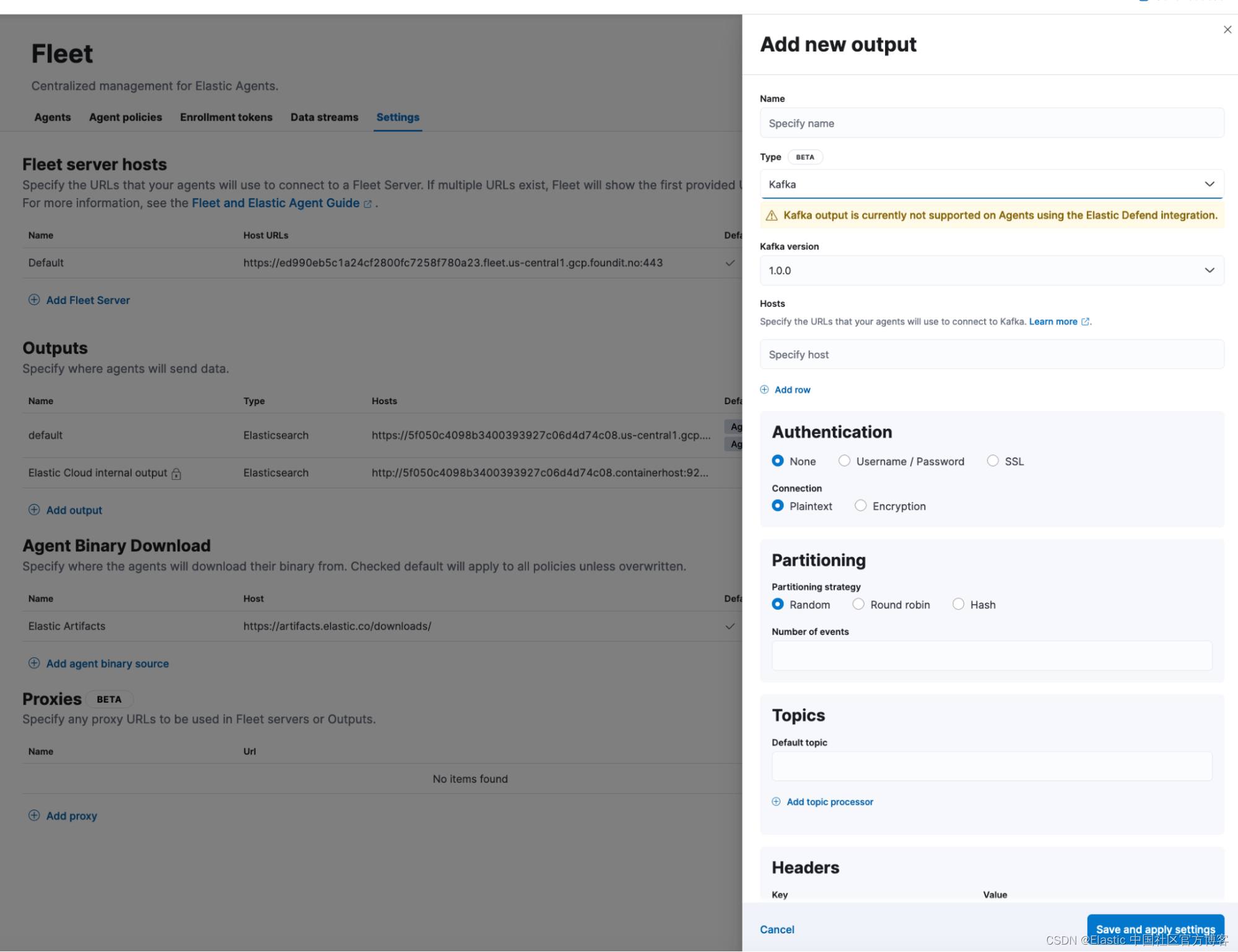
 创建完成后,可以自行填写项目名称和说明信息,然后参照如下进行设置,最下面两个设置代表打乱图片顺序、在标注小组内共享标注成果。当勾选共享时,就可以进行多人标注,每个人都可以看到其他人的标注结果,并且可以将任务量平均的分到每个人身上。
创建完成后,可以自行填写项目名称和说明信息,然后参照如下进行设置,最下面两个设置代表打乱图片顺序、在标注小组内共享标注成果。当勾选共享时,就可以进行多人标注,每个人都可以看到其他人的标注结果,并且可以将任务量平均的分到每个人身上。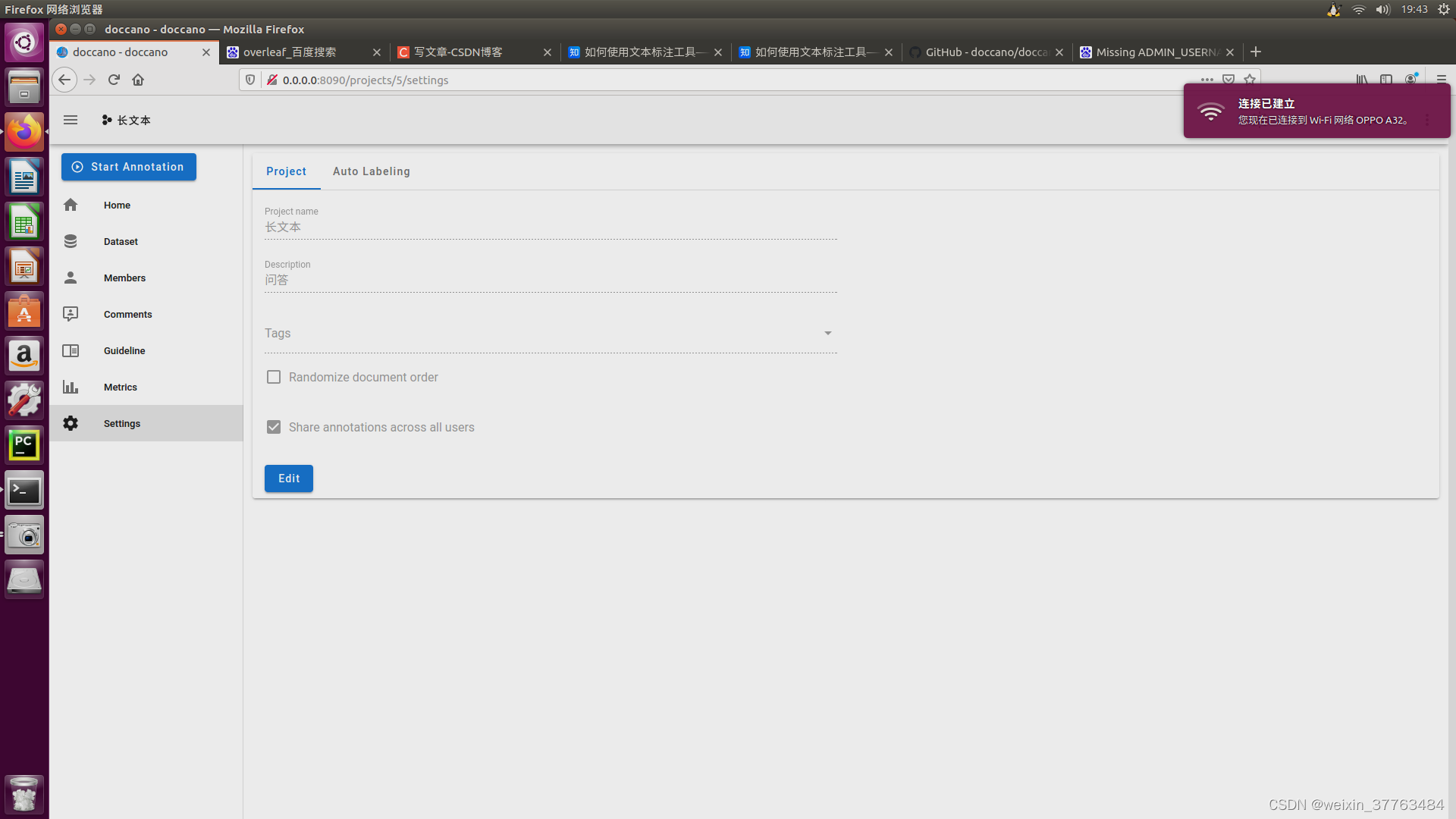
2.3上传数据集
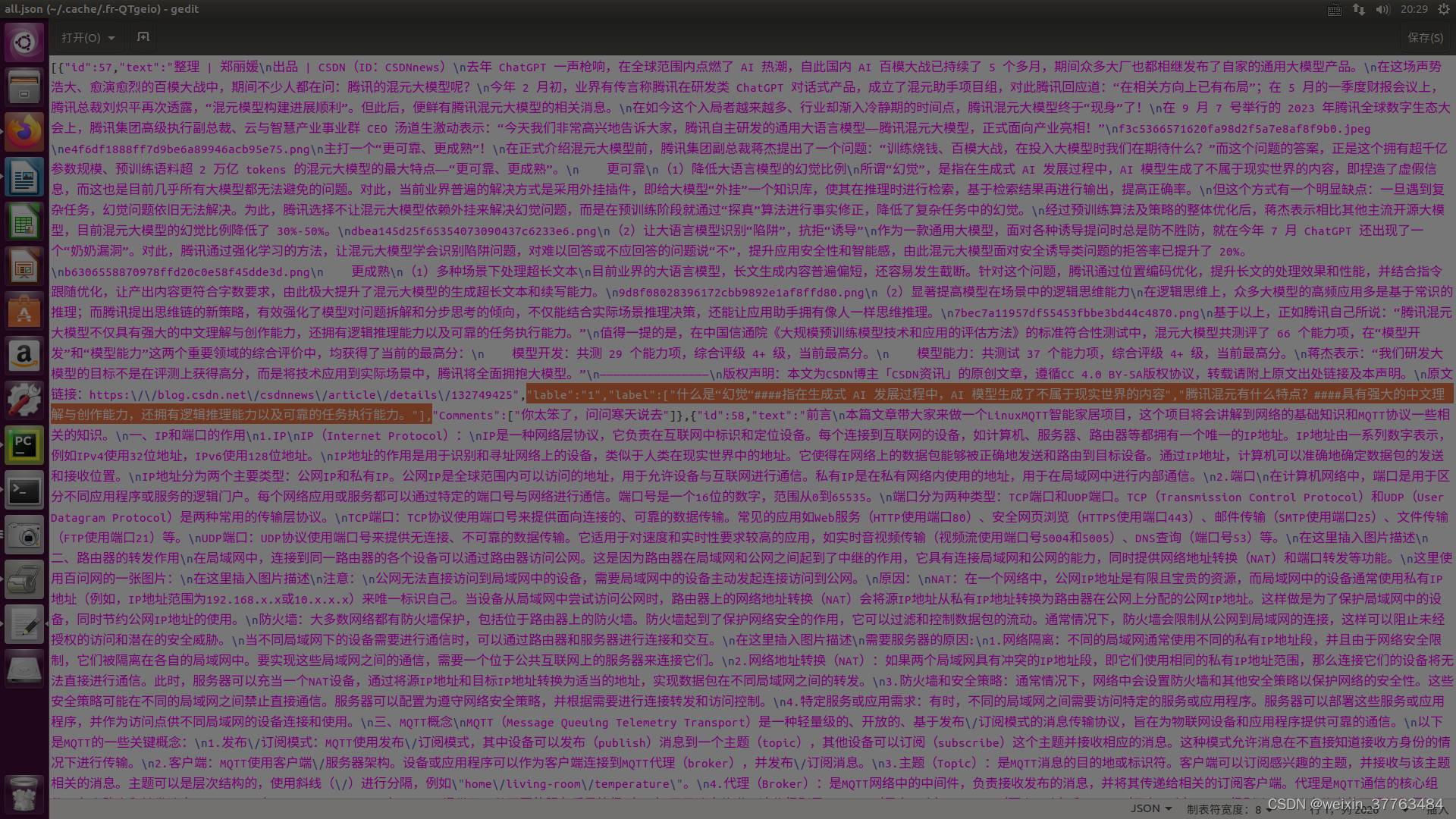
由于我的任务是在一些文档上进行提问,因此我把数据转化为了json格式,其中的text是文本内容,label可以换为其他内容,例如标注人员的编号或姓名。其中一条数据示例如下:
[{"label": "1", "text": "去年 ChatGPT 一声枪响,在全球范围内点燃了深度学习的热潮......”}]
人工标注的内容也会被放到label字段中,你可以通过添加字符串来方便区分(我用了4个#)。假设你增加了一个问题“gpt是什么时候发布的####去年”,那么上面的这条数据,在最终输出时,就会变为下面的样子:
[{"label": ["1","gpt是什么时候发布的####去年"], "text": "去年 ChatGPT 一声枪响,在全球范围内点燃了深度学习的热潮......”}]
原始数据就是我从csdn上随便找的四篇文章,我把他们复制到了txt_folder下的4个txt中,生成的json文件存放于all_data.json中。json有两个字段,text是原始内容,label可以用来区分该条数据具体由哪位标注人员负责。由txt生成json的代码如下:
import os
import jsonif __name__=="__main__":paths = os.walk(r'./txt_folder/')data=[]index=1for path, dir_lst, file_lst in paths:for file_name in file_lst:article={}tmp_str = ""with open(os.path.join(path, file_name)) as f:for line in f.readlines():tmp_str+=linearticle["text"]=tmp_str.replace("\n\n","\n")article["lable"]=str(index)index+=1data.append(article)json_str=json.dumps(data,ensure_ascii=False)with open("all_data.json", "w") as file:file.write(json_str)
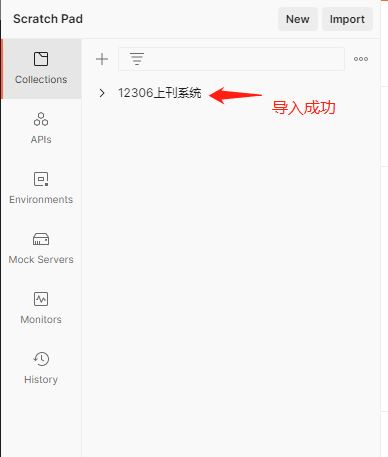
制作好数据集之后,点击下图的import dataset选项,导入刚才制作好的数据集。我选择的是json类型。图片中已经有了我制作好的数据集,正常情况下图中的绿色标签是看不到的。
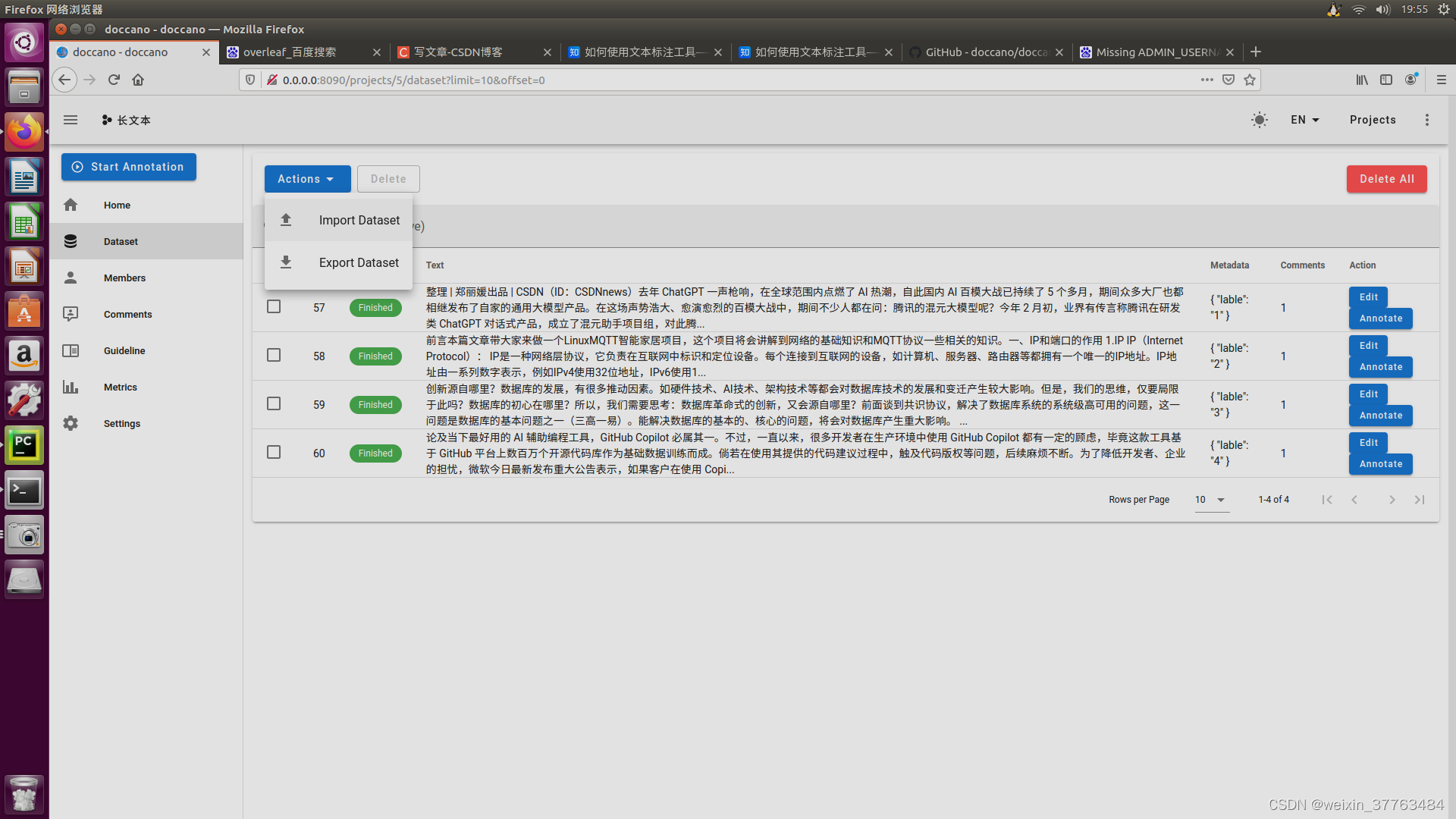
3多人标注
3.1 新建用户
多人标注首先需要新建用户。可以访问 http://0.0.0.0:8090/admin/auth/user/add/并创建用户。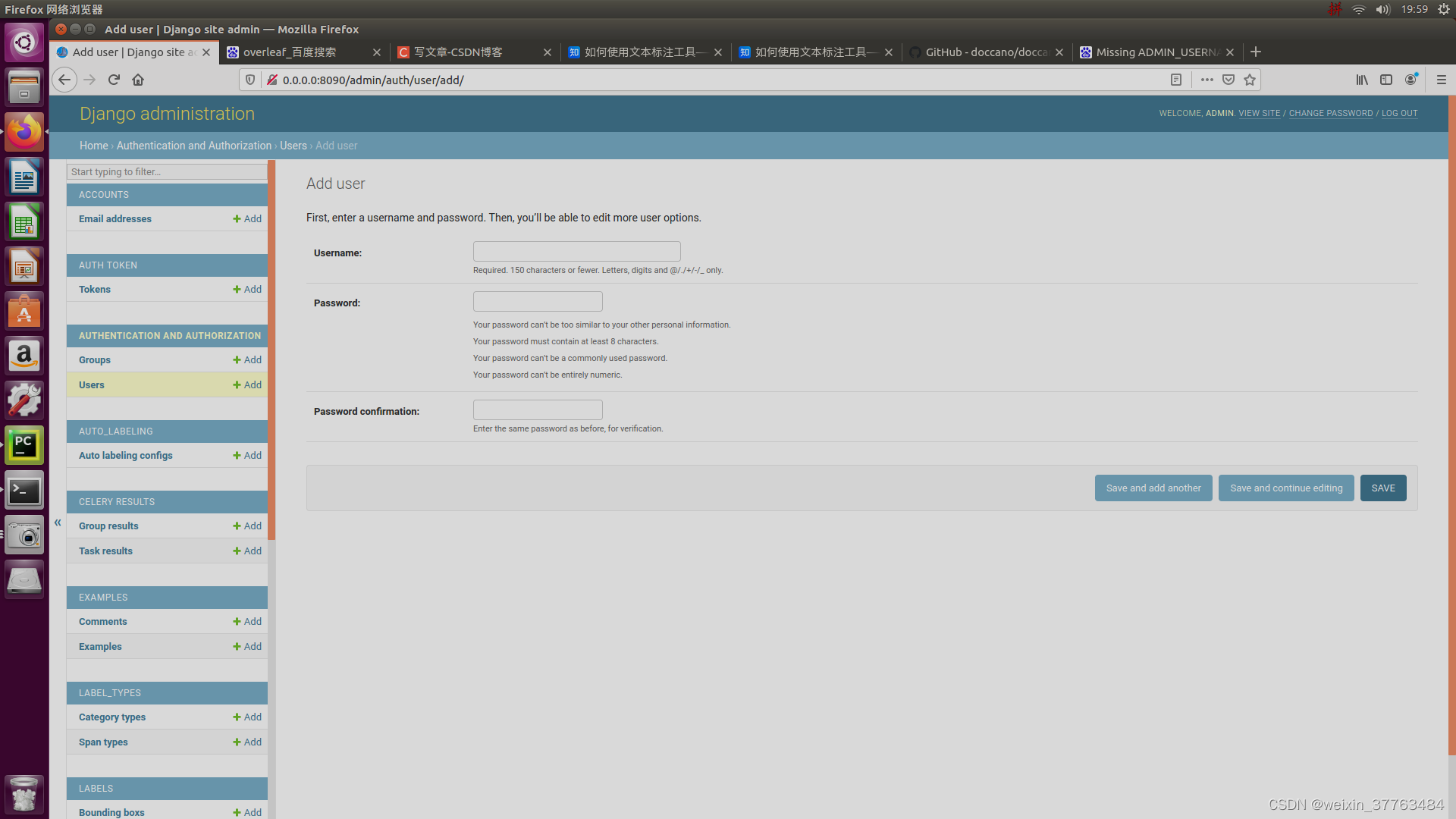
然后切换回新建的工程,点击左侧的members,然后再弹出的页面中点击add按钮,添加人员并指定角色。其中的annotator可以进行数据标注,annotation approver可以进行审核与修改,project admin可以进行标注结果的下载。
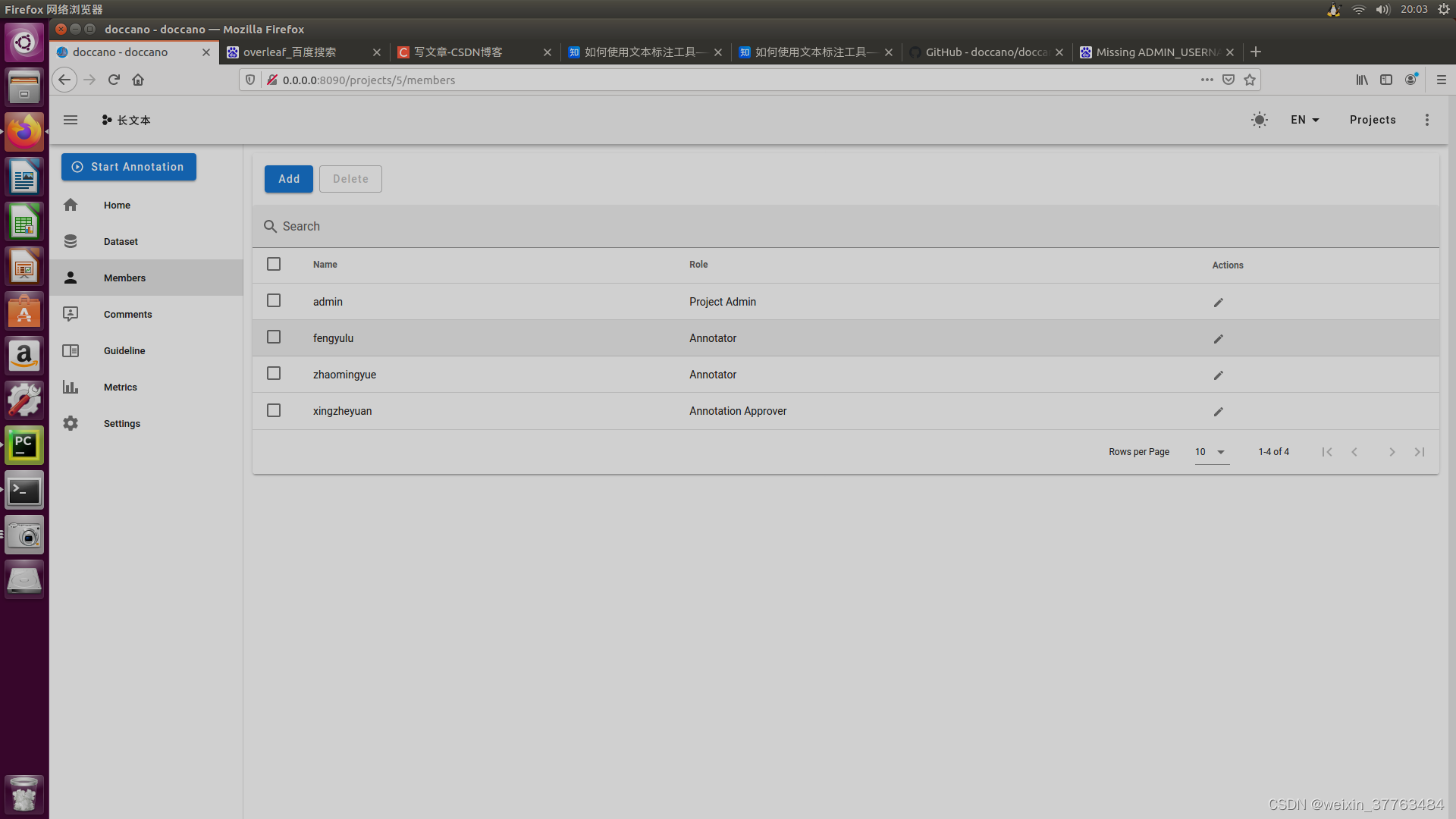
3.2 标注与质检
标注时,切换到相应annotator的账户,点击图片右侧的“annotate”即可进行标注。
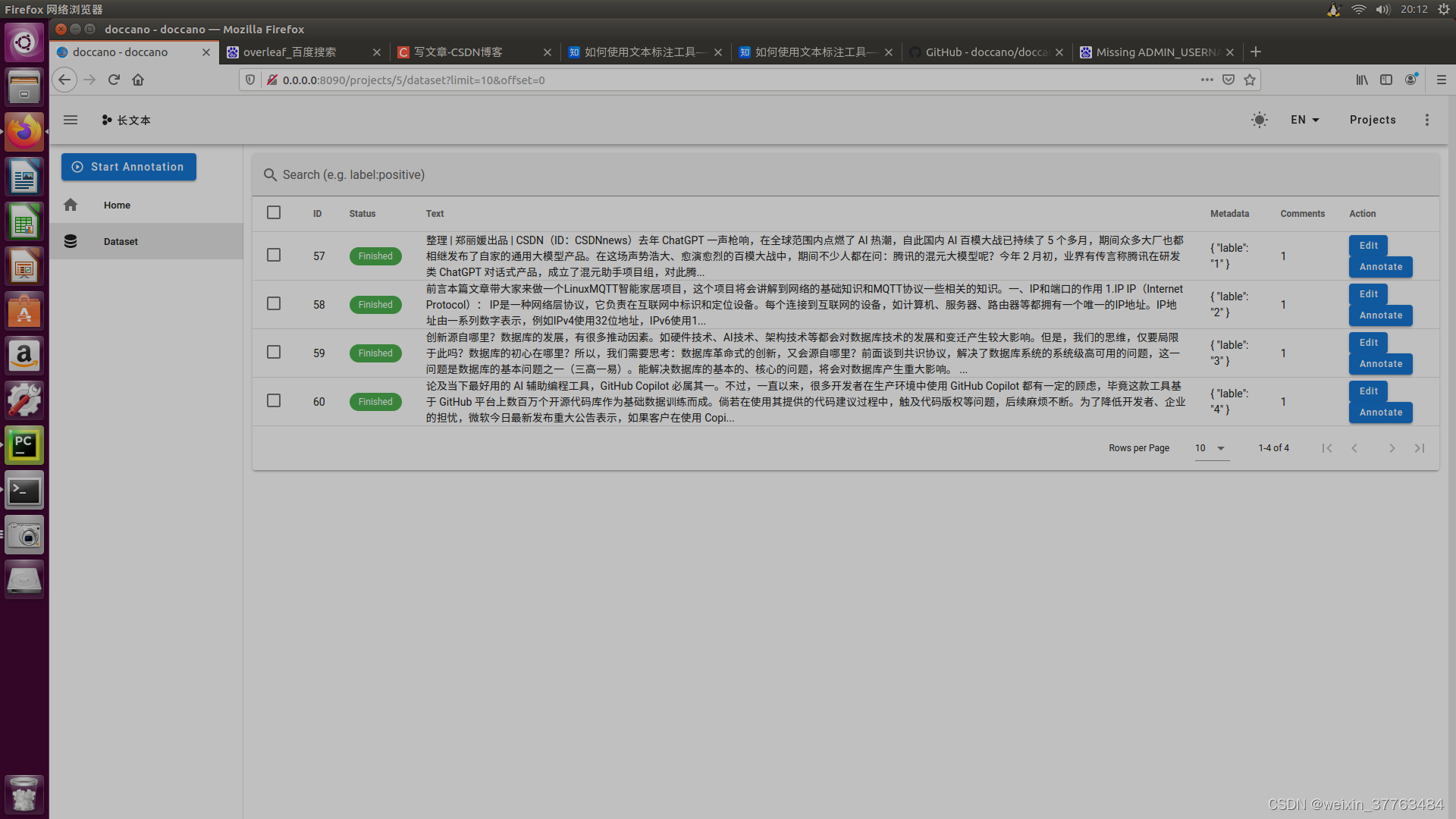
点击之后,上方是数据集中的“text”中的内容,可以在下方的输入框中进行提问。我用####隔开了问题和答案,后续可以用代码分开。你也可以尝试加入更多的内容,以满足不同的标注需求。注意标注人员不要点击页面中左上角的对勾和叉子,这需要留给质检人员处理。
假设现在有两个标注人员,共有四个标注文档要处理,可以通过在上传数据时设置label来区分不同的任务的负责人。他们按照label的指引,完成自己负责部分的标注后就可以质检了。
现在切换到质检人员的帐号,确认无误后点击左上角的叉子,并使其变为对勾。每改掉一个叉子,右侧的绿色进度条就会有变化。达到100%即代表任务完成质检。
3.3标注结果导出
切换到admin账户,点击action下的export dataset,即可导出数据。
我选择了导出为json数据,可以看到,文件中多了一些标注人员提出的问答对,在下图中用黄色标出: