开源库源码分析:OkHttp源码分析(二)
导言
上一篇文章中我们已经分析到了OkHttp对于网络请求采取了责任链模式,所谓责任链模式就是有多个对象都有机会处理请求,从而避免请求发送者和接收者之间的紧密耦合关系。这篇文章我们将着重分析OkHttp中这个责任链的行为逻辑。
责任链中拦截器的位置
既然是责任链,那么每个拦截器自然有其位置,决定它是先处理请求还是后处理请求。这个请求是在构造责任链的时候确定的,更具体来说是在构造拦截器集合的时候确定的:
val interceptors = mutableListOf<Interceptor>()interceptors += client.interceptorsinterceptors += RetryAndFollowUpInterceptor(client)interceptors += BridgeInterceptor(client.cookieJar)interceptors += CacheInterceptor(client.cache)interceptors += ConnectInterceptorif (!forWebSocket) {interceptors += client.networkInterceptors}interceptors += CallServerInterceptor(forWebSocket)
因为我们知道责任链中访问拦截器的顺序就是每次将索引+1访问下一个拦截器,所以构造拦截器集合的时候确定了各个拦截器的上下级关系。从代码中我们可以清楚了解每一个拦截器的位置:
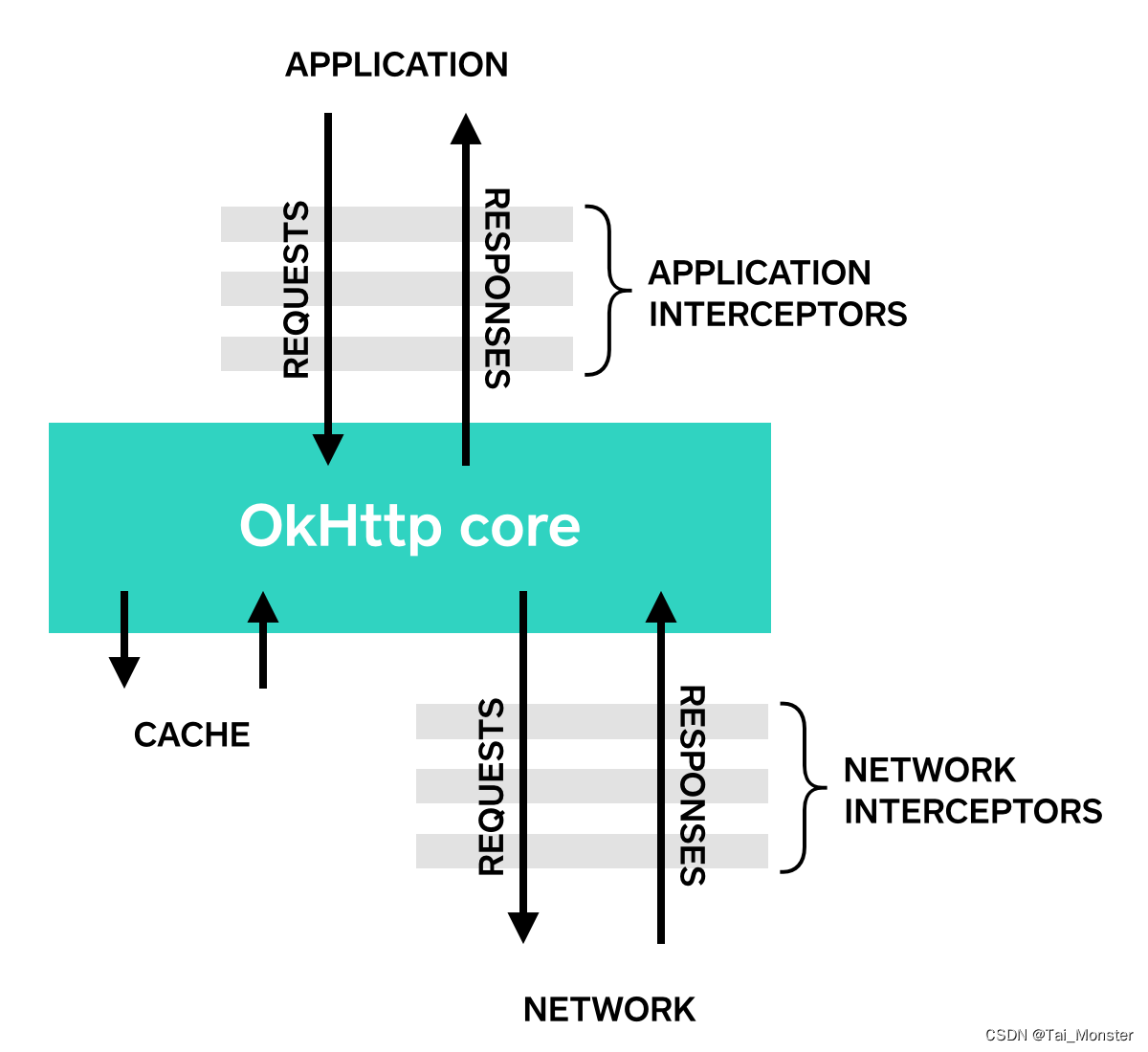
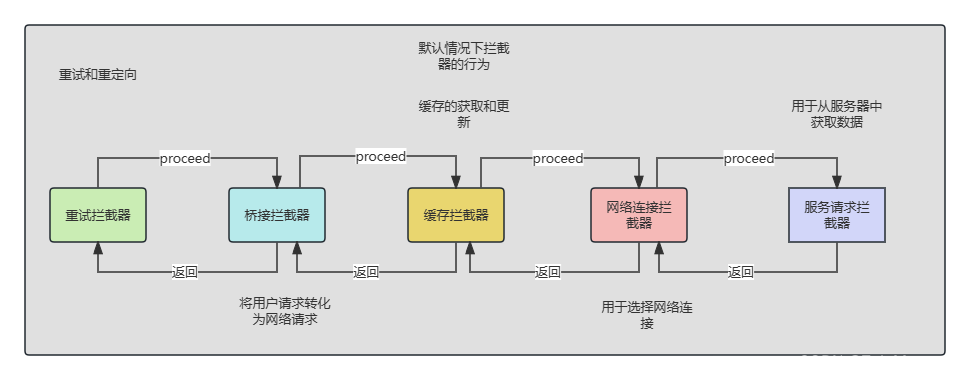
用户应用拦截器->重试拦截器->桥接拦截器->缓存拦截器->连接拦截器->网络拦截器->请求服务拦截器
还记得这每个拦截器的作用吗:
- interceptor:应用拦截器,通过Client设置
- RetryAndFollowUpInterceptor:重试拦截器,负责网络请求中的重试和重定向。比如网络请求过程中出现异常的时候就需要进行重试。
- BridgeInterceptor:桥接拦截器,用于桥接应用层和网络层的数据。请求时将应用层的数据类型转化为网络层的数据类型,响应时则将网络层的数据类型转化为应用层的数据类型。
- CacheInterceptor:缓存拦截器,负责读取和更新缓存。可以配置自定义的缓存拦截器。
- ConnectInterceptor:网络连接拦截器,其内部会获取一个连接。
- networkInterceptor:网络拦截器,通过Client设置。
- CallServerInterceptor:请求服务拦截器。它是拦截器中处于末尾的拦截器,用于向服务端发送数据并获取响应。
请求传递过去时的拦截器行为
重试拦截器
第一个用户应用拦截器是我们传入的,这里先忽略,所以照理来说第一个拦截事件的就是重试拦截器RetryAndFollowUpInterceptor了,这个拦截器主要是用来处理网络请求过程中的异常情况的,其拦截方法如下:
override fun intercept(chain: Interceptor.Chain): Response {val realChain = chain as RealInterceptorChainvar request = chain.requestval call = realChain.callvar followUpCount = 0var priorResponse: Response? = nullvar newExchangeFinder = truevar recoveredFailures = listOf<IOException>()while (true) {//做一些潜在的准备工作call.enterNetworkInterceptorExchange(request, newExchangeFinder)var response: Responsevar closeActiveExchange = truetry {if (call.isCanceled()) {throw IOException("Canceled")}try {response = realChain.proceed(request)//传递给下一个拦截器newExchangeFinder = true} catch (e: RouteException) {........} finally {call.exitNetworkInterceptorExchange(closeActiveExchange)}}}
可以看到如果是第一次请求的话该拦截器做的事情就是调用enterNetworkInterceptorExchange设置一些参数,然后直接将其传递给下一个拦截器处理,等到后面的拦截器都处理完了再对这个返回出来的Response进行处理,所以我们到后面的拦截器行为分析完了再回过来分析后面的内容。这里实际上就是一个栈式调用,和递归一样。
在while循环的第一句话会调用enterNetworkInterceptorExchange进行一些工作的准备,在这里第一次调用的情况下的话,它会为Call设置一个Exchange:
//RealCall.ktif (newExchangeFinder) {this.exchangeFinder = ExchangeFinder(connectionPool,createAddress(request.url),this,eventListener)
看里面传入的参数就知道不简单,显然这和具体的网络请求的发起有关。
Exchange和ExchangeFinder
首先是Exchange类:

在OkHttp中用Exchange来描述传输一个单独的HTTP请求和响应对。它在处理实际的I/O的ExchangeCodec上添加了连接管理和事件处理的功能。ExchangeCodec负责处理底层的I/O操作,而这段代码建立在其之上,处理HTTP请求和响应的传输和管理。这一层的功能包括连接的建立、请求的发送、响应的接收以及与底层I/O的交互,以确保HTTP请求得到正确处理并获得响应。
总结一下,这个Exchange类就可以用来代表一个可以控制与所需要的服务器进行交流的类,我将它视作一个连接,在这里我们就不继续往下分析底层的ExchangeCodec的实现了。
接下来是ExchangeFinder类:

这段代码的主要作用是尝试查找与一个请求交互相关的连接以及可能的重试。它采用以下策略:
-
如果当前的请求已经有一个可以满足的连接,就会使用这个连接。对于初始请求和后续的请求都使用同一个连接,可以提高连接的局部性。
-
如果连接池中有一个可以满足请求的连接,也会使用它。需要注意的是,共享的请求可能会针对不同的主机名进行请求!有关详细信息,请参阅RealConnection.isEligible。
-
如果没有现有的连接可用,将创建一个路由列表(可能需要阻塞的DNS查找),并尝试与这些路由建立新的连接。当发生失败时,重试会迭代可用路由列表。
-
如果连接池在DNS、TCP或TLS工作进行中获取了一个符合条件的连接,该查找器将优先使用池中的连接。只有池中的HTTP/2连接才会用于这种去重。
-
此外,这段代码还具有取消查找过程的能力。
需要注意的是,这个类的实例不是线程安全的,每个实例都限定在执行调用的线程中。
也就是说,这个类是用来管理与连接有关的东西的,它针对请求来查找可用的连接,按照他的上下文来看,这个链接指的应该就是ExchangeCodec,因为我们可以在RealCall的initExchange方法中找到相关的语句:
internal fun initExchange(chain: RealInterceptorChain): Exchange {synchronized(this) {check(expectMoreExchanges) { "released" }check(!responseBodyOpen)check(!requestBodyOpen)}val exchangeFinder = this.exchangeFinder!!val codec = exchangeFinder.find(client, chain).......}
桥接拦截器
言归正传,之前的重试拦截器将请求向下传递了,接下来轮到的就是桥接拦截器,在之前的介绍中也提到过了,这个拦截器主要负责用户代码与网络代码之间的转化,更具体来说它会将用户请求转化为网络请求,其拦截方法如下:
override fun intercept(chain: Interceptor.Chain): Response {val userRequest = chain.request() //获得用于请求val requestBuilder = userRequest.newBuilder() //根据用户请求获得一个RequestBuilderval body = userRequest.body//获得请求体if (body != null) { .//若请求体不为空,处理用户的各种请求,将其转化为网络请求val contentType = body.contentType()if (contentType != null) {requestBuilder.header("Content-Type", contentType.toString())}val contentLength = body.contentLength()if (contentLength != -1L) {requestBuilder.header("Content-Length", contentLength.toString())requestBuilder.removeHeader("Transfer-Encoding")} else {requestBuilder.header("Transfer-Encoding", "chunked")requestBuilder.removeHeader("Content-Length")}}if (userRequest.header("Host") == null) { //如果Host为空,将用户的url转化为HostHead添加进去requestBuilder.header("Host", userRequest.url.toHostHeader())}if (userRequest.header("Connection") == null) { //如果Connection为空,将其设置为'Keep-Alive'requestBuilder.header("Connection", "Keep-Alive")}// If we add an "Accept-Encoding: gzip" header field we're responsible for also decompressing// the transfer stream.//翻译过来就是如果需要解压缩,那么我们也要进行处理var transparentGzip = falseif (userRequest.header("Accept-Encoding") == null && userRequest.header("Range") == null) {transparentGzip = truerequestBuilder.header("Accept-Encoding", "gzip")}val cookies = cookieJar.loadForRequest(userRequest.url) //获取Cookiesif (cookies.isNotEmpty()) {requestBuilder.header("Cookie", cookieHeader(cookies))}if (userRequest.header("User-Agent") == null) {requestBuilder.header("User-Agent", userAgent)}//将转化好的网络请求向下传递给下一个拦截器val networkResponse = chain.proceed(requestBuilder.build())cookieJar.receiveHeaders(userRequest.url, networkResponse.headers)val responseBuilder = networkResponse.newBuilder().request(userRequest)//获得一个响应体构造器//解压缩的情况if (transparentGzip &&"gzip".equals(networkResponse.header("Content-Encoding"), ignoreCase = true) &&networkResponse.promisesBody()) {val responseBody = networkResponse.bodyif (responseBody != null) {val gzipSource = GzipSource(responseBody.source())val strippedHeaders = networkResponse.headers.newBuilder().removeAll("Content-Encoding").removeAll("Content-Length").build()responseBuilder.headers(strippedHeaders)val contentType = networkResponse.header("Content-Type")responseBuilder.body(RealResponseBody(contentType, -1L, gzipSource.buffer()))}}//将响应返回return responseBuilder.build()}
上面源码中我已经将重要的部分做了注释,可以说这个网络桥接拦截器的作用就是根据我们在请求中设置的参数来生成一个真正的网络请求体然后发送给下一个拦截器。可以看到,他也是先将请求发送给下一个拦截器等待其相应,也是一个栈式的调用,后面拦截器返回之后会重新返回到这个拦截器中。
缓存拦截器
接下来就是各个网络库中绕不过去的缓存了,这是为了提高性能而必须的。缓存拦截器将从缓存中返回请求并将新的请求(响应)写入缓存中,我们来看其拦截方法:
override fun intercept(chain: Interceptor.Chain): Response {val call = chain.call() //获得Callval cacheCandidate = cache?.get(chain.request())//根据请求在缓存中获得缓存候选val now = System.currentTimeMillis()//获得当前时间//通过缓存策略工厂构造出一个策略,然后用这个策略计算出结果val strategy = CacheStrategy.Factory(now, chain.request(), cacheCandidate).compute()val networkRequest = strategy.networkRequest//结果中的网络请求部分val cacheResponse = strategy.cacheResponse//结果中的缓存响应部分cache?.trackResponse(strategy)val listener = (call as? RealCall)?.eventListener ?: EventListener.NONE//设置事件监听器if (cacheCandidate != null && cacheResponse == null) { //如果缓存候选存在但是没有缓存响应//和换句话说就是缓存候选不可用// The cache candidate wasn't applicable. Close it.cacheCandidate.body?.closeQuietly() //将缓存候选给关闭}// If we're forbidden from using the network and the cache is insufficient, fail.if (networkRequest == null && cacheResponse == null) {//如果网络请求体为空且缓存响应也为空,这里说是网络不可用且缓存不足return Response.Builder() //直接返回一个响应,说明响应失败.request(chain.request()).protocol(Protocol.HTTP_1_1).code(HTTP_GATEWAY_TIMEOUT).message("Unsatisfiable Request (only-if-cached)").body(EMPTY_RESPONSE).sentRequestAtMillis(-1L).receivedResponseAtMillis(System.currentTimeMillis()).build().also {listener.satisfactionFailure(call, it) //回调事件监听器中的方法}}// If we don't need the network, we're done.if (networkRequest == null) { //虽然网络请求为空,但是有缓存响应,说明缓存命中return cacheResponse!!.newBuilder() //返回命中的缓存响应.cacheResponse(stripBody(cacheResponse)).build().also {listener.cacheHit(call, it)//回调事件监听器中的方法}}if (cacheResponse != null) { //此时是网络请求不为空且缓存请求也不为空的情况listener.cacheConditionalHit(call, cacheResponse)//回调监听器中的方法} else if (cache != null) { //此时是网络请求不为空但是缓存响应为空的情况listener.cacheMiss(call)//说明缓存未命中,执行事件监听器中的方法}var networkResponse: Response? = null //新创建一个网络响应体,这显然是在缓存未命中的情况下才会发生的try {networkResponse = chain.proceed(networkRequest) //向下将该网络请求传递下去并获得网络响应} finally {// If we're crashing on I/O or otherwise, don't leak the cache body.if (networkResponse == null && cacheCandidate != null) {cacheCandidate.body?.closeQuietly()}}.......}return response}
这里我们先分析到缓存拦截器将网络请求发送给下一个拦截器的代码处,之后会掉的部分我们等等在分析,上面的代码处我已经将重要的部分加上了注释,这个缓存的逻辑也很简单,简单来说就是缓存命中且可用就返回缓存中的响应,若缓存未命中之后才请求网络。
网络连接拦截器

从介绍来看这个拦截器是用来打开一个与目标服务器进行数据交流的连接,这段代码的主要作用是打开与目标服务器的连接并继续执行下一个拦截器。这个连接可能会用于返回的响应,或者用于通过条件GET验证缓存的响应。下面是它的拦截方法:
override fun intercept(chain: Interceptor.Chain): Response {val realChain = chain as RealInterceptorChainval exchange = realChain.call.initExchange(chain)val connectedChain = realChain.copy(exchange = exchange)return connectedChain.proceed(realChain.request)}
可以看到这个方法就很短了,它会获得一个我们之前提到过的Exchange对象,我们说过这个对象中的ExchangeCodec就是实现底层与网络进行I/O流的类。该方法中将Exchange对象初始化然后将其传入了RealChain副本中,最后调用了该副本的proceed方法将该请求传递给了之后的拦截器。
网络拦截器
由于网络拦截器也是由用户设置的,默认情况下并没有被设置,所以我们跳过这个先。
请求服务拦截器
注释中提到了这是责任链中的最后一环的拦截器,它是用来对服务器发起Call的,下面是他的拦截方法:
override fun intercept(chain: Interceptor.Chain): Response {val realChain = chain as RealInterceptorChainval exchange = realChain.exchange!! //获得Exchangeval request = realChain.request //获得请求val requestBody = request.body //获得请求体val sentRequestMillis = System.currentTimeMillis()//获得当前时间exchange.writeRequestHeaders(request)//通过exchange将请求中的请求头写入var invokeStartEvent = true//设置开始执行事件标志位为truevar responseBuilder: Response.Builder? = null//确保方法不是‘GET’或者‘Head’if (HttpMethod.permitsRequestBody(request.method) && requestBody != null) {// If there's a "Expect: 100-continue" header on the request, wait for a "HTTP/1.1 100// Continue" response before transmitting the request body. If we don't get that, return// what we did get (such as a 4xx response) without ever transmitting the request body.if ("100-continue".equals(request.header("Expect"), ignoreCase = true)) {exchange.flushRequest()responseBuilder = exchange.readResponseHeaders(expectContinue = true)exchange.responseHeadersStart()invokeStartEvent = false}if (responseBuilder == null) {if (requestBody.isDuplex()) { //如果请求是双工的// Prepare a duplex body so that the application can send a request body later.exchange.flushRequest()val bufferedRequestBody = exchange.createRequestBody(request, true).buffer()requestBody.writeTo(bufferedRequestBody)} else {// Write the request body if the "Expect: 100-continue" expectation was met.val bufferedRequestBody = exchange.createRequestBody(request, false).buffer()requestBody.writeTo(bufferedRequestBody)bufferedRequestBody.close()}} else {exchange.noRequestBody()if (!exchange.connection.isMultiplexed) {// If the "Expect: 100-continue" expectation wasn't met, prevent the HTTP/1 connection// from being reused. Otherwise we're still obligated to transmit the request body to// leave the connection in a consistent state.exchange.noNewExchangesOnConnection()}}} else {exchange.noRequestBody()}if (requestBody == null || !requestBody.isDuplex()) {exchange.finishRequest()//完成请求}if (responseBuilder == null) {responseBuilder = exchange.readResponseHeaders(expectContinue = false)!!//去读响应头if (invokeStartEvent) {exchange.responseHeadersStart()//响应头开始--具体就是执行事件监听器中的回调方法invokeStartEvent = false}}var response = responseBuilder //获得响应.request(request).handshake(exchange.connection.handshake())//握手.sentRequestAtMillis(sentRequestMillis).receivedResponseAtMillis(System.currentTimeMillis()).build()var code = response.code//这里就是各种响应码if (code == 100) {// Server sent a 100-continue even though we did not request one. Try again to read the actual// response status.responseBuilder = exchange.readResponseHeaders(expectContinue = false)!!if (invokeStartEvent) {exchange.responseHeadersStart()}response = responseBuilder.request(request).handshake(exchange.connection.handshake()).sentRequestAtMillis(sentRequestMillis).receivedResponseAtMillis(System.currentTimeMillis()).build()code = response.code}exchange.responseHeadersEnd(response)response = if (forWebSocket && code == 101) {// Connection is upgrading, but we need to ensure interceptors see a non-null response body.response.newBuilder().body(EMPTY_RESPONSE).build()} else {response.newBuilder().body(exchange.openResponseBody(response)).build()}if ("close".equals(response.request.header("Connection"), ignoreCase = true) ||"close".equals(response.header("Connection"), ignoreCase = true)) {exchange.noNewExchangesOnConnection()}if ((code == 204 || code == 205) && response.body?.contentLength() ?: -1L > 0L) {throw ProtocolException("HTTP $code had non-zero Content-Length: ${response.body?.contentLength()}")}return response//返回最终的响应}
这里我们也没必要死扣它是如何运作的,毕竟我们只是分析一个大致的结构。这个方法中做的一句话来说就是用Exchange来获得网络响应,然后将该响应进行一些处理返回出去。
请求回调时的拦截器行为
之前提到了这整个拦截器链上的拦截方法都是栈式调用的,也就是说他们在执行完后一个拦截器的行为之后还会回调到前一个拦截器的拦截方法之中,接下来我们从最后开始看他们拦截回调时的行为。
首先最后一个拦截方法是在请求服务拦截器之中的,它会返回它的前一个拦截器的拦截方法之中,也就是网络连接拦截器之中,不过网络连接拦截器之中直接返回了:
override fun intercept(chain: Interceptor.Chain): Response {val realChain = chain as RealInterceptorChainval exchange = realChain.call.initExchange(chain)val connectedChain = realChain.copy(exchange = exchange)return connectedChain.proceed(realChain.request)}
所以我们继续往前推,它的前一个拦截器是缓存拦截器,我们接下来看缓存拦截器的拦截方法的下半部分:
var networkResponse: Response? = nulltry {networkResponse = chain.proceed(networkRequest)} finally {// If we're crashing on I/O or otherwise, don't leak the cache body.if (networkResponse == null && cacheCandidate != null) {cacheCandidate.body?.closeQuietly()}}// If we have a cache response too, then we're doing a conditional get.if (cacheResponse != null) {if (networkResponse?.code == HTTP_NOT_MODIFIED) {val response = cacheResponse.newBuilder().headers(combine(cacheResponse.headers, networkResponse.headers)).sentRequestAtMillis(networkResponse.sentRequestAtMillis).receivedResponseAtMillis(networkResponse.receivedResponseAtMillis).cacheResponse(stripBody(cacheResponse)).networkResponse(stripBody(networkResponse)).build()networkResponse.body!!.close()// Update the cache after combining headers but before stripping the// Content-Encoding header (as performed by initContentStream()).cache!!.trackConditionalCacheHit()cache.update(cacheResponse, response)return response.also {listener.cacheHit(call, it)}} else {cacheResponse.body?.closeQuietly()}}val response = networkResponse!!.newBuilder().cacheResponse(stripBody(cacheResponse)).networkResponse(stripBody(networkResponse)).build()if (cache != null) {if (response.promisesBody() && CacheStrategy.isCacheable(response, networkRequest)) {// Offer this request to the cache.val cacheRequest = cache.put(response)return cacheWritingResponse(cacheRequest, response).also {if (cacheResponse != null) {// This will log a conditional cache miss only.listener.cacheMiss(call)}}}if (HttpMethod.invalidatesCache(networkRequest.method)) {try {cache.remove(networkRequest)} catch (_: IOException) {// The cache cannot be written.}}}return response
这后半部分最重要的部分就是那个update方法,用这个方法去更新缓存中的内容,然后会检查之前缓存中的数据的有效性,如果失效了就会将其移除,最后将Response返回到之前的一个拦截器中。缓存拦截器之前的是桥接拦截器:
cookieJar.receiveHeaders(userRequest.url, networkResponse.headers)val responseBuilder = networkResponse.newBuilder().request(userRequest)if (transparentGzip &&"gzip".equals(networkResponse.header("Content-Encoding"), ignoreCase = true) &&networkResponse.promisesBody()) {val responseBody = networkResponse.bodyif (responseBody != null) {val gzipSource = GzipSource(responseBody.source())val strippedHeaders = networkResponse.headers.newBuilder().removeAll("Content-Encoding").removeAll("Content-Length").build()responseBuilder.headers(strippedHeaders)val contentType = networkResponse.header("Content-Type")responseBuilder.body(RealResponseBody(contentType, -1L, gzipSource.buffer()))}}return responseBuilder.build()
这里就是涉及到Cookies的处理和关于解压缩的工作,最后返回到最开始的重试拦截器,重试拦截器中涉及到的就是一些失败重试和重定向的处理,里面有一些关于重试最大的次数,如果超过了最大次数仍然失败的话就会抛出异常。
整个过程如图所示:
连接
最后我们来讲一讲连接。
OkHttp有三种方式连接服务器:URLs,Address和Route。
具体来说,当我们在OKhttp使用URL时,它是这样运作的:
- 1.使用URL和配置好的OkHttpClient创建一个
Address,这个Address说明了我们如何连接服务器。 - 2.它首先会尝试从连接池中获取一个连接。
- 3.如果无法在连接池中找到一条可用的连接,它会尝试选择一条
route,这通常意味着将会发送一个DNS请求获得服务器的IP地址。 - 4.如果它是一条新
route,它通过构建直接套接字连接,TLS隧道,或直接TLS连接进行连接。 - 5.发送HTTP请求并接受请求。
当连接过程中出现以外的时候,OkHttp将选择另一条route再次进行尝试,一旦响应被接受了,连接就会被回收进入连接池中以便复用。我们需要记住除了缓存之外,OkHttp还有连接池来优化性能。