摘要
本周阅读了两篇论文,其一为一种基于空气质量时频域特征提取的hybrid预测方法,另一篇为基于烛台与视觉几何群模型的 PM2.5 变化趋势特征提取与分类预测方法。在第一篇文章中,通过小波变化,对数据进行分频,并设计了一种新模型用于空气质量的时频域特征提取和预测。在第二篇文章中,利用烛台图模拟PM2.5的浓度变化,寻找PM2.5的物理传输过程的特征。采用 VGG 分类方法对烛台图形式的连续污染数据进行分类,可以更全面地保留物理污染过程的特征,为准确预测PM2.5提供分类依据值。
This week,two papers are read,one is a hybrid prediction method based on time-frequency domain feature extraction of air quality,the other is a Method for Extracting and Classifying PM2.5 Trend Features Based on Candlestick and Visual Geometry Group Model.In the first article, data is divided into different frequencies through wavelet transformation.And a new model is designed for time-frequency domain feature extraction and prediction of air quality.In the second article, candlestick plots are used to simulate the concentration changes of PM2.5 and identify the characteristics of the physical transport process of PM2.5.The VGG classification method is used to classify continuous pollution data in the form of candlestick charts, which can more comprehensively preserve the characteristics of physical pollution processes and provide classification basis values for accurate prediction of PM2.5.
文献阅读1
1、标题和提出问题
标题:一种基于空气质量时频域特征提取的hybrid预测方法
提出的问题:空气质量与环境参数被作为单独的指标,但这些指标在长时序过程中,特征和相关性极为复杂,造成以统计学基础的模型缺乏可解释性,且效果难以控制。因此,如何将目标参数和输入变量进行时频域分析并提取相关性,是此类模型可解释性和提高精度的重要途径。物理模型设计中存在的一些理想化假设与复杂的真实环境存在偏差,导致物理模型难以预测复杂的非线性过程。同时直接从原始时间序列变量中发现时间相关性是不可靠的,因为相关性可能被纠缠的多频率数据掩盖。
2、小波变换
波变换是通过小波母函数,自适应地探索不同的频带,将不同频率信息从原数据中分离的数学工具。它克服了短时傅里叶变换的弱点和局限性。由于小波变换不受静态假设的限制,因此可以认为它是提取空气污染时间序列时频信息的有效工具。可定义为:

SWT将时序数据分为高频和低频信号,其中,高频信号代表序列的突变特征,即小波的细节系数;低频信号表示序列的一般特性,即小波的近似系数
3、Encoder和Decoder
Encoder能够自适应的学习输入变量间的相关性,计算流程可以概况为通过计算变量间的相关性矩阵,将输入V映射到输出。
self-attention可用数学语言描述为:
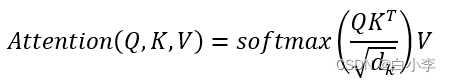
在原始的self-attention中, V被线性层映射至另一个向量空间,这可能导致原始空间中的信息被破坏,变量间的相关性被模糊,不利于模型的解释。另外,在Scaled Dot-Product Attention中,使用的激活函数是SoftMax,它的值域局限于(0,1),这在计算变量间相关性的时候会混淆负相关和弱相关关系。为了解决这些问题,取消了V上的线性层,并采用值域为(-1,1)的Tanh激活函数代替了SoftMax,新的self-attention结构如下所示:
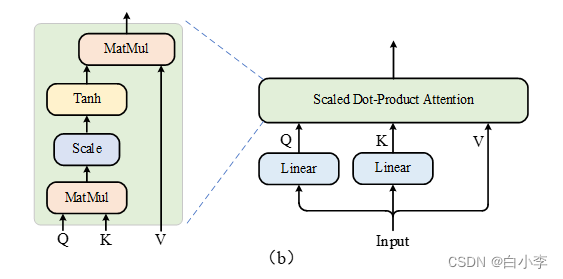
在Decoder的解码过程中,使用LSTM(长短时记忆)对时间信息进行解码,捕获时间依赖关系,并使用Attention网络从时间解码数据中自适应提取主要特征来预测PM2.5含量。
注意力机制区别于q-k-v型的自注意力,它的时间复杂度是O(n),相比于自注意力模块平方级的复杂度,注意力模型计算速度更快,但它不能发现变量间的相关性。在本研究中,注意力模块被用于在编码器中,让网络自适应的发现更重要的频段。
4、模型结构
结构:数据采集部分、频率分离部分、WTformer1模型构建部分、结果分析部分和相关性分析部分。
基于小波变换的频率分离器被设计用于将原数据中的低频和高频信号分离。常用的小波分频器为带通滤波器,通过父小波和母小波将时序数据分解为低频与高频分量,对于低频分量重复多次分解,每次分解后时序数据的长度减半,由于长度减半导致各频率数据形状不一致,不便于输入模型进行张量计算。本文采用了平稳小波变换,在分离高频和低频信号时,不会改变信号的长度,能保证分解后的高频与低频分量长度一致,便于模型的训练。
编码器设计被用于计算气象和污染物变量间的相关性矩阵,增强特征信息并编码。增强主要影响因素的特征信息,减少干扰信号的影响。
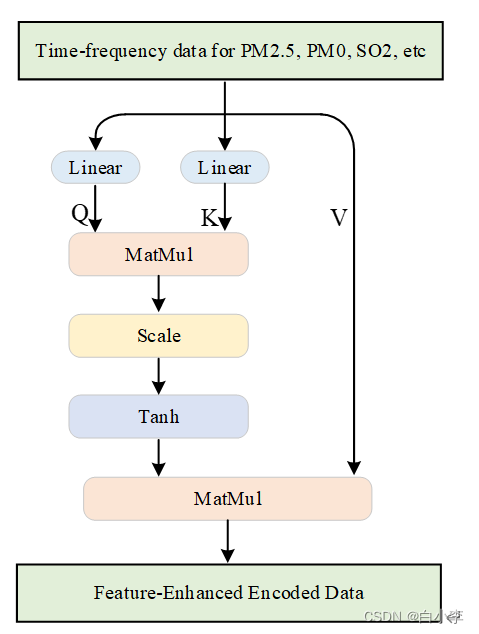
解码器被设计用于解码数据,提取主要特征信息,预测未来一段时间PM2.5的含量。
首先,使用LSTM神经网络在时间维度解码时间信息。第二,将时间解码后的数据输入Attention Network,使用卷积层提取各频域内的变量信息,得到特征长条。第三,输入Softmax层,得到各频域对于预测结果的相关性矩阵。第四,相关性矩阵与时间解码后的数据点乘,增强主要频段的特征信息。最后,通过一个加权求和的线性层融合信息,预测未来一段时间的PM2.5含量。
5、实验
数据集:2018-2021年61个站点的平均小时数据作为数据集。
样本区的PM2.5 作为模型的预测目标。由于桂林处于喀斯特地貌,大气湍流在不同季节和时段差异性很大,由此,存在明显的高低频波动。其特征是,在秋冬季受外源长距离传输影响较大,在春夏受local局部湍流影响较大,因此该地区的样本数据非常适合作为本模型的基础数据。
在整个预测范围内,WTformer都表现出了准确的预测性能。这表明WTformer即使在污染数据突然变化的情况下也表现出良好的性能。模型的良好性能表明,所建立的模型能够在不同情况下准确的预测数据。
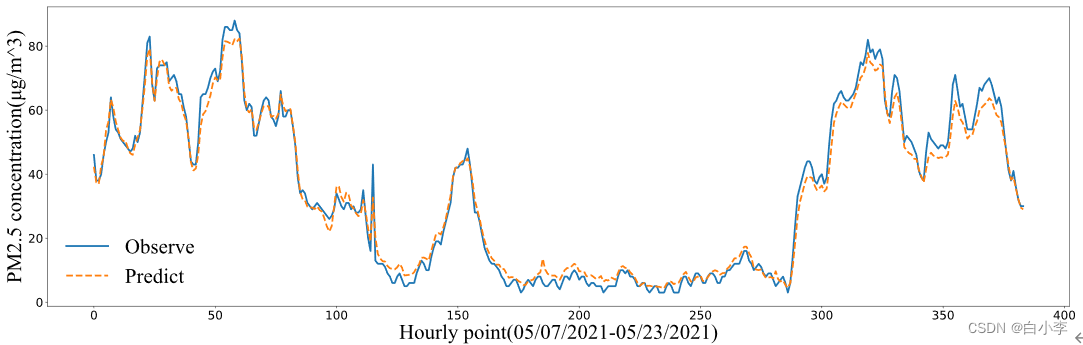
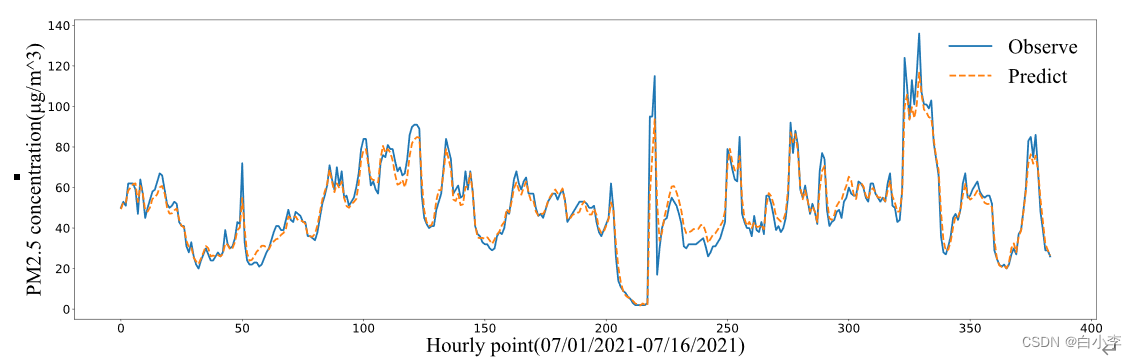
消融实验:
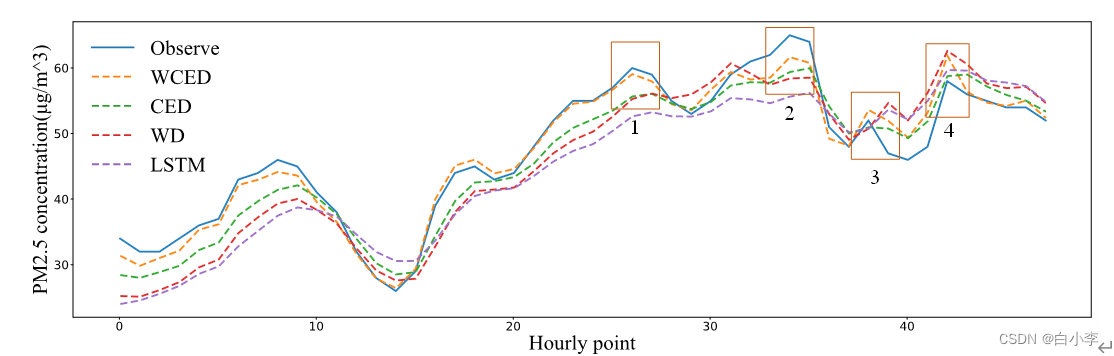
通过消融实现验证了,WTformer模型中每个模块都是有效的。其中,小波分解模块能提高模型对突变处的敏感性。特征增强模块可缓解LSTM模型在预测时的滞后性。
文献阅读2
1、标题和提出问题
标题:基于烛台与视觉几何群模型的 PM2.5 变化趋势特征提取与分类预测方法
提出问题:为了提高预测精度,有必要对 PM2.5 数据特征提取和特征分类进行研究。通过这些研究,PM2.5 预测过程将具有较好的反映物理规律的能力,从而达到提高预测精度的目的。因此,为了准确预测PM2.5,研究PM2.5传播过程的分类是非常重要的。
2、高斯扩散模型和烛台图
高斯扩散模型是一种适用于均匀大气的点源扩散模型:
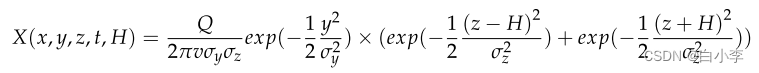
在不考虑空间模型的情况下,结合源强度、风向、风速,对站间 PM2.5 扩散过程进行一维分析。将位于目标站点逆风方向的站点作为 PM2.5 的发生位置。为简化目标站点逆风站点作为 PM2.5 的诞生地,将其称为强源。建立高斯扩散模型,模拟 PM2.5 扩散过程,并对目标站点的 PM2.5进行分析。
下表显示了烛台图九种形式对应的高斯过程。其中,风从污染源吹向目标场地时,风向(d)增大,无风从污染源吹向目标场地时,风向(d)减小。当来自污染源的风速增大时,风速(v)增大,当来自污染源的风速减小时,风速(v)减小。Y 表示该物品发生了变化,N表示该物品没有发生变化。

PM2.5 烛台图由初始值、终值、最大值和最小值组成。其中,红色烛台代表当天PM2.5 浓度整体下降趋势。绿色烛台代表这一天 PM2.5 浓度的总体增长。根据初值、终值、最大值、最小值这四个值,确定上阴影线、下阴影线、实体的长度。PM2.5 烛台图的九种基本形式是由上下阴影和实体的长度和颜色的差异得出的。
3、研究方法
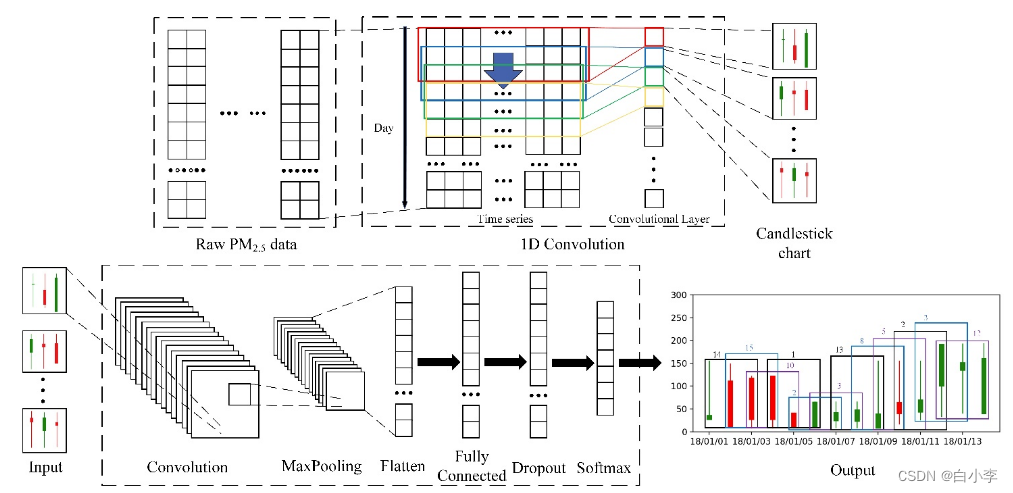
首先,设计了烛台图样本生成器,将 PM2.5 数据转换为三天烛台图格式。然后对这些烛台图进行分类,使用无监督分类方法找到可能的组合类型。此外,通过判断下一时期各类型 PM2.5 浓度的变化趋势,获得无监督分类的准确性。最后,使用 VGG模型对标记有分类标签的烛台图进行训练和分类。得到分类结果后,统计 VGG 模型的分类准确率,并与其他分类模型进行比较。

烛台图的实体由一天的初始值和结束值组成。烛台图的最大值是一天内 PM2.5 浓度的最高值,烛台图的最小值是一天内 PM2.5 浓度的最低值。这样,一天的 PM2.5 数据就转化成了一张烛台图。
烛台图样本生成器:

PM2.5数据通过设置滑动窗口大小为3天,滑动步长为1天,每隔3天形成一个烛台图。根据三天的PM2.5数据,形成了一个烛台图。在上图中,时间序列数据是以日为单位的连续PM2.5数据,每天有24个数据。烛台图样本生成器协同进化了时间序列。
针对烛台图形式的 PM2.5 数据分类实验,设计了包含 6 个基本隐含层的 VGG 模型;即一个卷积层、一个池化层、一个扁平层、一个完全连接层,以及另外两个功能层(即;即扁平层和 dropout 层):
4、实验准备
数据集:选取2013-2018年逐时PM2.5数据作为基础数据集,其中包括该站6年逐时PM2. 5数据。
评价指标:
总体精度(OA),OA是指正确分类的样本占所有样本的比例,其计算公式为:
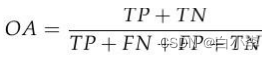
Kappa 系数是一种比率,表示分类与完全随机分类之间的误差减少比率。其计算公式:

超参数设置:

5、实验结果
使用这16个烛台图组合可以准确地获得未来 PM2.5的变化趋势:
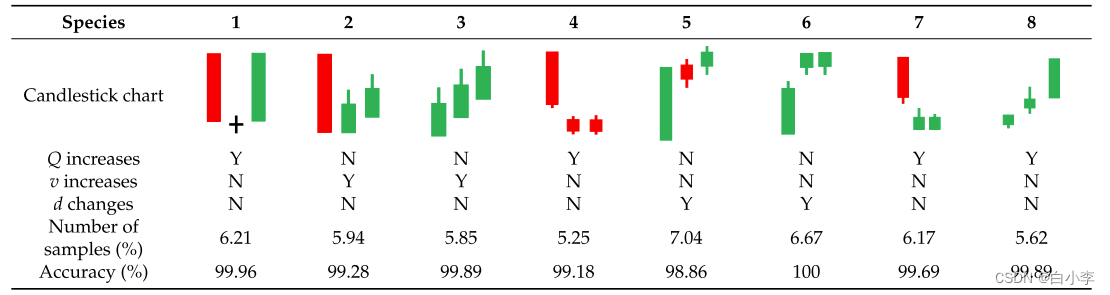
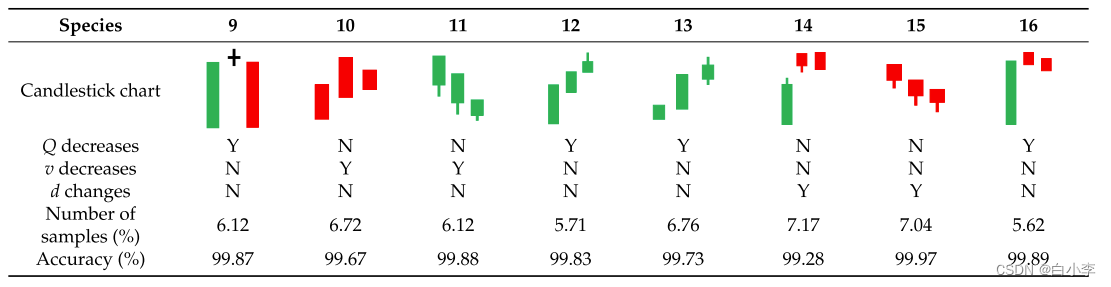
Hu 等人在 2019年提出了 103种烛台图组合,其中三天的烛台图组合有 29种。通过检查对比发现,在无监督分类得到的 16个烛台图组合中,都与这 29个三天烛台图组合相匹配。桂林监测站只有 16 个烛台图组合,因为桂林的 PM2.5 污染类型主要来自外部污染源,而不匹配的类型主要发生在自身污染下。
数据分类样本的数量和准确率:

16个类别的样本数量与上两个表中每个类别的样本数量接近。这表明了 16 个烛台图组合定义的准确性。进一步说明了用烛台图反映 PM2.5物理扩散特性的可行性。
比较实验:
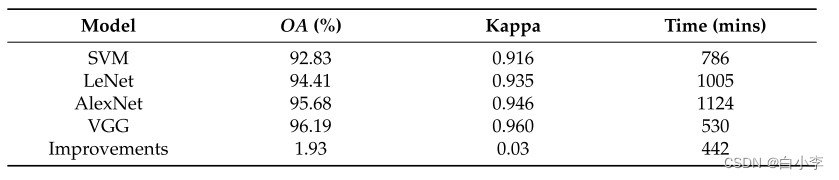
VGG模型的 OA 值、Kappa 值和训练次数是所有实验模型中最好的。相比之下,VGG模型的计算负担最小,因为该模型只包含六个基本功能层,而不包含更深层次的重复功能层。
总结
本周继续阅读了2篇同组文章,加大了对于团队方向的理解,对自己的论文写作思路也有了一个大致的概念,在下周将进行第一部分的写作以及总体框架的搭建,同时尝试对数据进行先行处理操作。

![[vue问题]开发中问题集合](https://img-blog.csdnimg.cn/5f73875ba75d400798ca525aa86ffd34.png)
![[计组03]进程详解2](https://img-blog.csdnimg.cn/52f8c8819651498ab1aa04a227530e88.png)





![[春秋云境] CVE-2022-32991](https://img-blog.csdnimg.cn/9cc50a4e469d43c8aa38fe40adbad2c7.png)