公号:数元斋
数字化转型、数据治理、解决方案、信息化内容、大数据、技术架构、技术文章、咨询服务、专业培训等内容分享
今天我们提及数据治理、数字化等已经身处其中,认为理所当然。任何事物的发展都被趋势裹挟向前。但想站的高,一定要对整体体系有深入的理解。眼下涉及到的数据技术五花八门百花齐放。各种数据治理的框架概念也已逐渐被人熟知,比如元数据、数据质量、主数据、数据标准、数据转化、数据资产等等。有意思的是从我们每个人自身的知识体系去看数据的门槛似乎有又似乎不高,根据自己或主动或被动的学习及理解,貌似理解了其中大部门内容并感觉懂得其中深意。可另一方面,数据治理、数字化转型的成功案例却鲜有出现,认真贯彻数字化战略,将数据价值发挥出来的又凤毛麟角。这似乎形成了一种畸形的矛盾,一方面提及数据治理,接触过的都感觉自身有相当的理解而另一方面在落地实施时又没有人能找到清晰的逻辑思路并一以贯之的执行下去。真正打通任督二脉的企业已经一骑绝尘在数字化的道路上形成良性循环越发主动且彻底,没有摸到门道的单位还在一只脚踏入数字的世界大门上进进出出。这之前的差距我们从一个简单的角度试着分析,希望找到其中的桎梏。
当我们在谈论数字化、数据治理时如果心里对大数据技术的提出及发展历史有相当的认知及掌握时,或许这其中的更迭变换对未来方向的思考及本行业的落地推进会起到以史为鉴的作用。只有清晰掌握事物发展的基本规律再结合现状,或许当局的部分人会先形成数字化思维并逐渐引导新的变革落地。真因为数据与我们每个人的生活息息相关所以人人都可以有数字化思维,也因为数据变化莫测虚无缥缈,发挥它的价值变得难以落地。今天我们试图勾勒大数据技术的发展及设计的技术内核来启发数字化从业人员,尤其是企业内部的数据管理部门甚至大部分是信息化部门兼任的各位人士能够更加体系化的思考这一重大课题。
大数据产生的原因
从字面上看,大数据就是数量巨大的数据,或者称为海量数据。实际上,大数据是一个较为抽象的概念,数量巨大只是其中的一个表面的特性。大数据是网络信息时代的客观存在,其产生的意义并不在于掌握庞大的数据量,而在于对这些数据进行专业存储和处理,并从中挖掘和提取所需要的知识和信息。
技术突破来源于实际的产品需求,如果将大数据比作一种产业,那么降低存储成本,提升运行速度和计算速度,以及对数据进行多维度的分析加工,实现并提升数据的价值,这是大数据这种产业实现盈利的关键,也是大数据产生的真正原因。
1. 存储成本的大幅下降与积累
以往存储数据的成本非常高,许多大型的互联网公司各自为政,为了保证数据的存储安全性和传输通畅性,需要进行定期维护和数据清理,机房部署和人力成本昂贵。新型的数据存储服务出现后,衍生了很多新的商业模式,集中建设数据中心,大大降低了单位计算和存储的成本。并形成了海量的数据积累。这里的量一方面是物理层面的多,一方面是相对含义的跨度广。在信息技术的推进过程中,数据的积累从单一业务系统到现在几乎所有的流程信息化,它的跨度实现了全业务级别的覆盖。未被覆盖的业务也在信息化数字化的迭代浪潮中不断的被卷入其中。现在系统的建造甚至已经不需要购买服务器,也不需要聘用管理人员,通过大数据云计算的商业模式即可获得资源,而存储成本的下降,也改变了人们对数据的看法,更愿意将久远的历史数据保存下来。有了这些数据的沉淀,人们才会想着如何加以利用,通过时间对比,发现其价值与关联。
2. 运行、计算速度的提升
20世纪90年代,传输一个20MB的文件需要花费约一天的时间,如今仅需数秒即可完成传输。分布式系统框架Hadoop、Spark、Storm,并行运行机制HDFS、MapReduce,为海量数据提供了计算的便利性,大大提升了对原始数据进行清洗、挖掘、分析的运行效率,使得数据的价值得到进一步提升。
3. 脑力劳动的解放
今天我们看到的AI的逐步普及,智能应用的推广,chatgpt的大火,其背后都有大数据的支撑。也就是说,大数据让计算机变得更加智慧,大数据为计算机灌输了人类的思想,大数据带来了智慧的价值,从而有效解放了人类的脑力劳动。
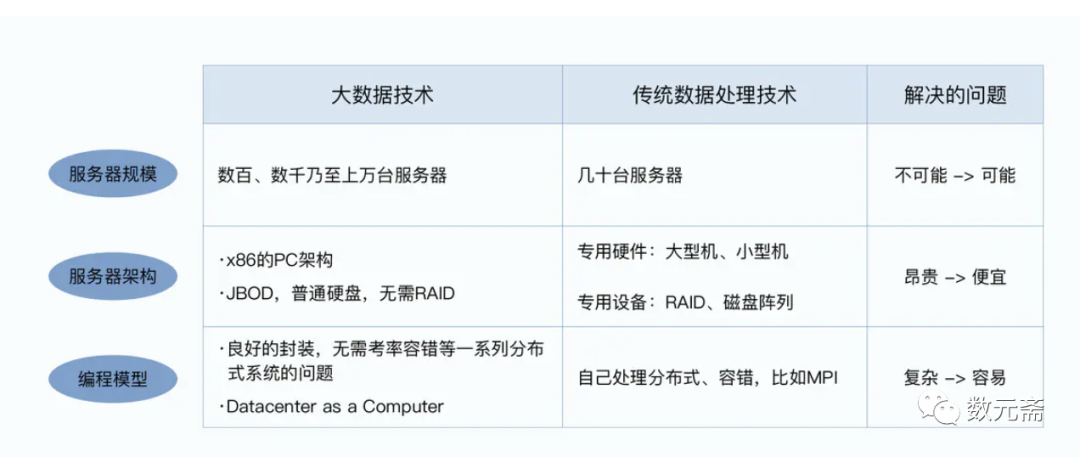
由此基础上大数据从三个方面完成了历史积累并开始推进相应的技术发展:
1、数量级:能够收缩到一千台服务器以上的分布式数据处理集群的技术。这个定义来源于谷歌的GFS论文,里面的集群规模可以达到上千。
2、成本:上千个节点的集群,采用廉价的PC架构搭建起来。正是由于搭建成本变低,任何一个程序员都可以用自己的PC开发,贡献代码,才使得大数据生态异常繁荣。
3、高度抽象:把数据中心当做一台计算机。大数据的最终目的,就是把集群抽象成一台能处理海量数据的计算的,所有的”大数据框架“,都希望就算没有大数据底层技术知识的工程师,也能很容易的处理海量数据。
大数据技术的提出
要了解大数据技术,就要知道大数据技术的发展过程。大数据技术的出现起源于Google,Google由于搜索业务量剧增,而对存储、计算、在线服务三个需求的探索,从而在2003、2004、2006分别提出了对应的解决方案,即大数据的开端-三驾马车。
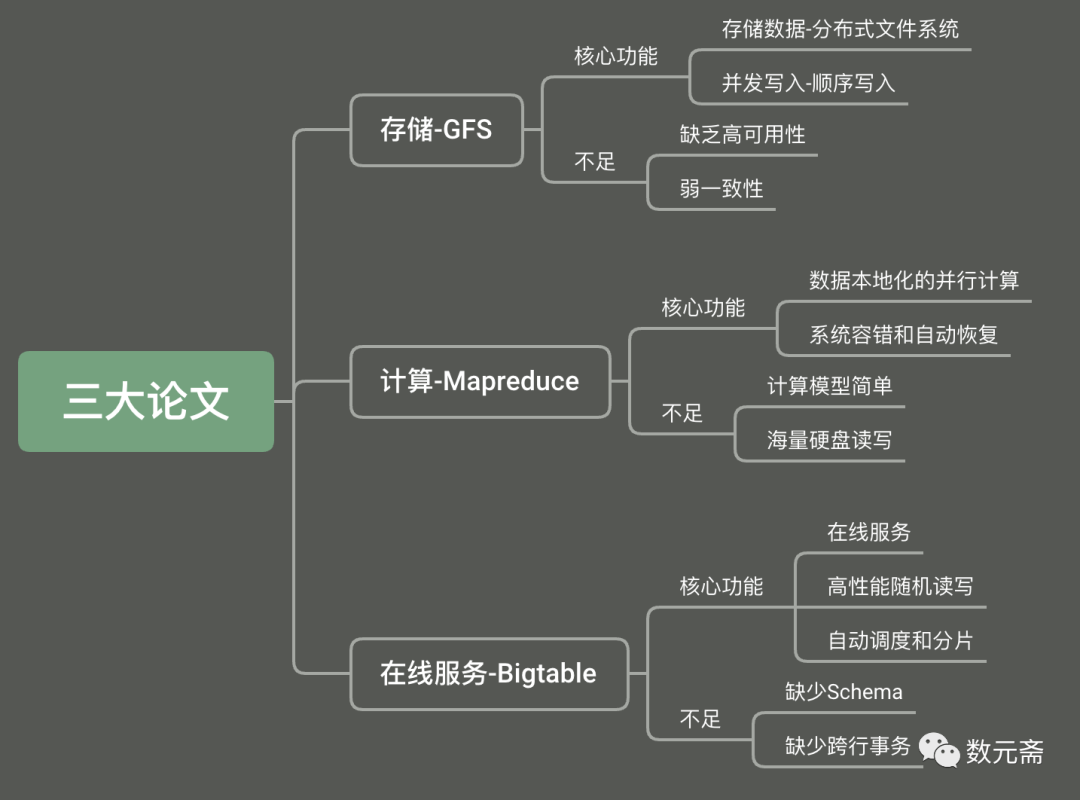
三大论文中,GFS主要解决数据的存储问题,作为一个上千节点的分布式文件系统,Google可以把所有需要的数据很容易的存储下来。
MapReduce主要是为了解决数据的计算问题,通过Map和Reduce两个函数,对海量数据计算进行一次抽象,让处理的数据的技术人员不需要掌握分布式系统的开发技术就可以完成海量数据计算。
Bigtable主要解决的是数据的高性能随机读写问题,用以满足业务场景下的在线服务需求,它直接使用了GFS作为底层存储,做了集群的分片调度,再利用MemTable+SSTable的底层存储格式,解决大集群、机械硬盘下的高性能随机读写问题。
最后,除了三驾马车,初始的大数据技术还依赖于两个基础设施。第一个是保障数据一致性的基于Paxos算法的分布式锁Chubby。第二个是为了解决数据序列化和分布式系统之间通信问题的Thrift。
大数据系统的进化
到这里,由三驾马车和两个基础设施组成最基本的大数据系统就算完备了。但是相对于实际需求来说,这个大数据系统还略显粗糙。于是他们在不同的方向开始进化延续。致力于大数据计算的OLAP(基于分析)MapReduce,出现了Hive、Spark、Dremel等计算引擎。致力于大数据在线服务的OLTP(基于事务)Bigtable,出现了Megastore、Spanner等技术。
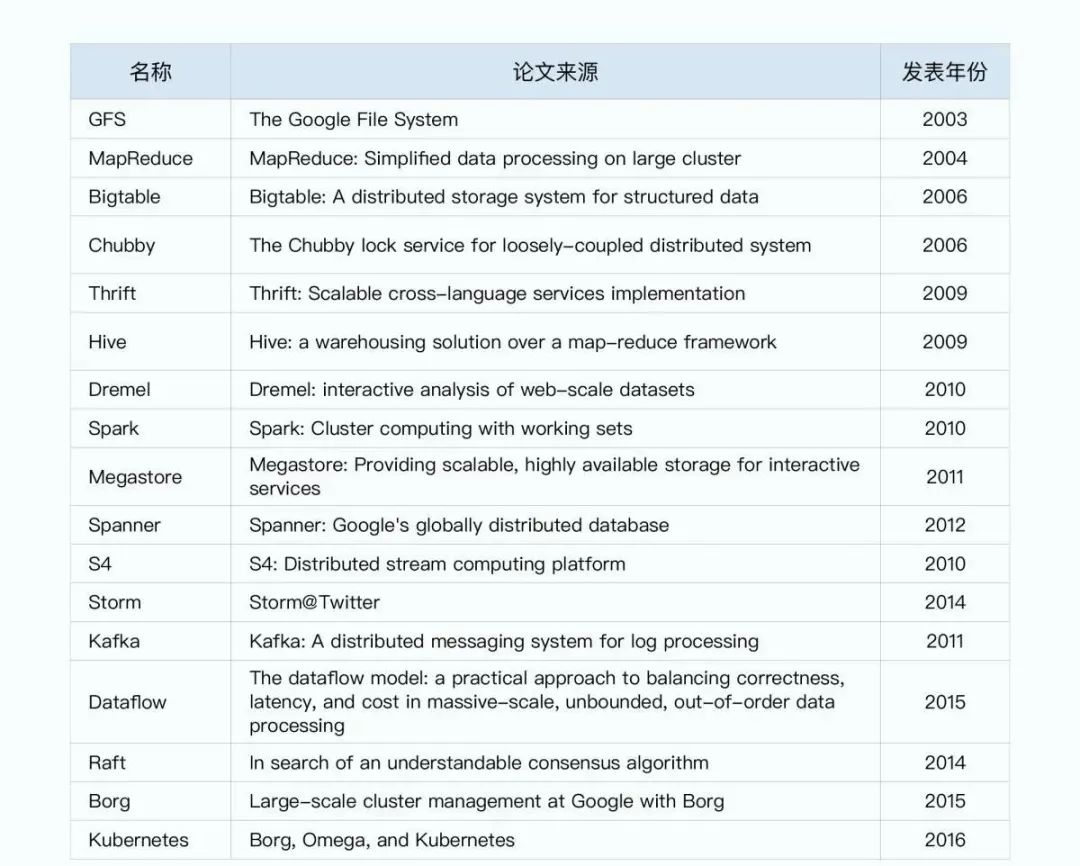
大数据经典论文
最后,由于大数据生态的不断发展和丰富,传统的服务器调度算法就变得很吃力,于是出现了Multi-Paxos协议和Raft协议,基于Raft协议,使整个分布式系统由虚拟机转变成为容器化,也就是Kubernetes的出现。
Yahoo 优化改编
当 Hadoop 发布之后,另一个当时的搜素引擎巨头 Yahoo 很快就使用了起来;
到了2007年,国内的百度也开始使用了 Hadoop 进行大数据存储与计算了。
又过了一年,2008年,Hadoop 正式成为 Apache 的顶级项目,自此,Hadoop 彻底火了起来,也被更多的人熟知。
当然任何系统都不可能是完美的,也不可能是通用的,并非适用于每个公司。Yahho 使用了 MapReduce 进行大数据计算时,觉得开发太繁琐,于是他们自己便开发了一个新的系统--Pig。
Pig是一个基于 Hadoop 类 SQL 语句的脚本语言。经过编译后,直接生成 MapReduce 程序,在 Hadoop系统上运行。所以 Yahho 也是在Hadoop 基础上进行了 编程上的优化使用。
Facebook 的数据分析 Hive
Yahho 的 Pig 是一种类似于 SQL 语句的脚本语言,相比于直接编写 MapReduce 简单许多。但是使用者还是要学习这种新的脚本语言。
又一家巨头公司出现了 Facebook 为了数据分析也开发一种新的分析工具,叫做 Hive 的东西,hHive 能直接使用SQL语句进行大数据计算,这样,只要是具有数据库关系型语言的开发人员就能直接使用大数据平台。大大的降低了使用的门槛,又将大数据技术推进了一步。
至此,大数据主要的技术栈基本形成。包括 HDFS、MapReduce、Pig、Hive.
Yarn的出现
此时,MapReduce 一个资源调度框架,又是一个执行引擎。为了责任单一化,将这两种功能进行了分离,Yarn 项目启动了。
2012年, Yarn 成为了独立的项目,开始运营,被各大数据厂商的产品支持,成为了主流的资源管理调度系统。
效率还是效率 Spark
同年,UC 伯克利 AMP 实验室的一位博士,在使用 MapReduce 进行大数据实验计算时,发现性能非常差,不能满足其计算需求。
为了改进这种效率低下的工作方式,于是开发出了一个性能优越的替代产品,叫做 Spark 。由于Spark 性能卓著,一经推出,就受到了业界的认可,开始全面替代 MapReduce。
批处理计算和流式计算
大数据计算根据分析数据的方式不同,有两个类别。一种叫做批处理计算,比如 MapReduce、Spark 这种,针对的是某个时间段的数据进行计算(比如“天”“小时”的单位)。
这种计算由于数据量大,需要花费几十分钟甚至更长。同时这种计算的数据是非在线实时获取的数据,也就是历史积累的数据,也就是离线数据,这种计算又被称为“离线计算”。
离线计算针对的是历史数据,相对的就有针对的实时数据进行计算,也就是系统接收到数据就进行计算,这种计算叫做“流式计算”。
由于处理的数据是实时在线产生的,又被称为“实时计算”。
流式计算技术 Storm、Flink、 Spark Streaming
怎么理解流式计算呢?很简单的,把批处理计算的时间单元缩小到数据产生的间隔就是了。“流式计算”具有代表性的框架,比如:Storm、Flink、 Spark Streaming。
流批一体的进化
为了解决数据实时处理的问题,大数据系统中出现了流式数据处理技术,首先,Yahoo在2004年发表了S4的论文,并在2011年开源了S4的技术。Twitter的工程师又开发并开源了Storm。并且南森基于Storm和MapReduce提出了Lambda架构,它可以称之为第一个“流批协同”的大数据处理架构。接着在2011年,Kafka的论文也被发表了,2014年Kafka的作者Jay Krepson提出了Kappa架构,可以称为第一代“流批一体”的大数据处理架构。随之而然,2015年Google发表了Dataflow模型,基于流式数据处理做了最好的总结和抽象,后来基于此,开源了Flink和Apache Beam。
非关系型数据库
在2011年 左右 NoSQL 非常火爆,其中 HBase 是从Hadoop中分拆出去的,也就是底层还是HFDS 技术。所以 NoSQL 系统在大数据环境下,提供海量数据的存储和访问功能,也算是大数据技术栈一员。
数据分析,数据挖掘,机器学习
有了大数据这个底层的技术基础,更广的应用也就能实现了。大数据平台,继承了数据分析和数据挖掘技术,以及在大数据基础上,更高级的机器学习技术。
数据分析主要是数据专员的工作,一般不需要开发能力,会使用简单的 SQL 基本上够用了。一些公司的运营人员,也要求具有数据分析的能力。数据分析主要是利用上面提到的 Hive、Spark SQL 等 数据库脚本语言;
有了大数据的存储和计算能力,就能进行数据挖掘和机器学习。当然也有成熟的框架,比如Mahout、Google 的 TersorFlow等框架。
最后,有了基础的存储功能,大数据批处理,流失处理计算能力,之上的大数据分析,以及更高级的挖掘和机器学习。至此一个大数据平台就构成了。
大数据应用的发展过程
大数据技术不断的更迭,同样的,在技术之上的应用,也经历了一个发展过程。
从最早的 Google公司,解决搜索引擎业务,到目前最火的AI技术。大数据应用越来越广泛。
Google 搜索引擎时代
在Google 之前,一直是 Yahho 在搜索引擎领域领先。从 Google 发布三篇大数据论文开始,Google 扭转了局面。
通过HDFS 对海量数据的存储,运用 MapReduce 技术高效的计算网页内容,提高用户的检索能力,正是这些大数据技术的发展,让 Google 傲立搜索引擎之巅。
后续的人工智能,无人驾驶技术 Google 也一直推动行业发展。
数据仓储、大数据分析时代
稍具规模的公司,都会有数据专员这种角色,不管是给老板提供数据,还是为产品人员提供数据支持。原来的工作方式,以传统的关系型数据库为主,跑一些 SQL 语句出报表数据。
大数据提供了保存海量的数据能力,除了业务数据,日志数据,爬虫数据等都成了数据的来源,也就构成了数据仓库。数据专员同学可以利用大数据的技术,在海量数据上进行分析,分析的维度更多,效率也大大提高。以前一条大的 SQL 也许需要跑一天,现在数据量更大,但是效率提成倍提高。
简单来说,数据人员利用 Hive 可以在 Hadoop 上进行 SQL 操作,实现数据统计与分析。
大数据挖掘时代
“买尿不湿的人通常也会买啤酒” 这个梗又要抬出来了。也许这个最能体会数据挖掘的作用。
帮助用户发现自己都不知道需要的需求,帮助电商平台推荐最适合用户的产品,更好销售自己的产品,帮助社交平台根据用户的画像更好的挖掘出最优关联性社交关系。
机器学习时代
有了大数据技术,可以把历史数据收集起来,统计其中的规律,进而预测正在发生的事情,这就是机器学习。AlohaGo 战胜世界冠军为起点,机器学习迎来了一波高潮,小米的小爱同学,天猫盒子,等语音聊天也将机器学习推广到了寻常百姓家。
AI(人工智能) 时代
将全部的数据,通过机器学习得到统计规律,进而模拟人的行为,是机器能像人类一样的思考,这就是人工智能。以AI为主题的电影电视也层出不穷,还有人会担心,人工智能的发展会超过人来的智能。当下大火的Chatgpt背后也离不开以大数据为基础的深度训练。


![[云炬商业计划书阅读分享] 珠江啤酒公司企业文化调查](https://img-blog.csdnimg.cn/065d542b5b8d4f94bb893d17060e13d6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eR5aSn5LqR54Ks,size_20,color_FFFFFF,t_70,g_se,x_16)