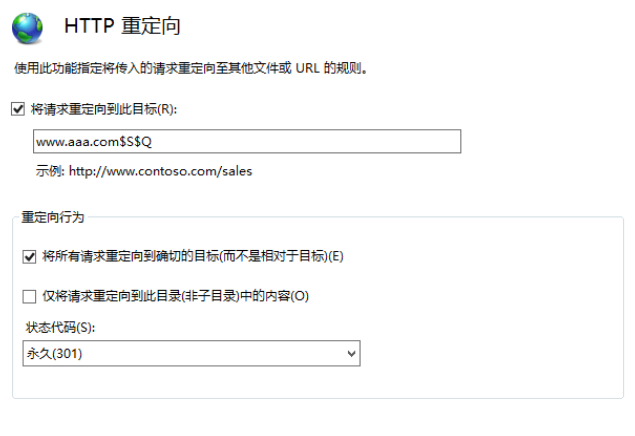
推荐:使用 NSDT场景编辑器快速搭建3D应用场景
若要正确查看音频生成的强大功能,请考虑以下方案。我们只需要提供一个简单的指令,描述场景和场景设置,模型就会生成一个扣人心弦的音频脚本,突出与原始指令的最高上下文相关性。
指令: 在科幻小说主题中生成音频:火星新闻报道人类向半人马座阿尔法星发送光速探测器。从新闻主播开始,然后是记者采访由联合地球和火星政府创立的建造这个探测器的组织的总工程师,最后再次以新闻主播结束。
生成的音频:https://audio-agi.github.io/WavJourney_demopage/sci-fi/sci-fi%20news.mp4
为了真正了解这个奇迹的内部运作,让我们深入了解生成过程的方法和实现细节。
生成过程
下图在一个简单的流程图中总结了整个过程。
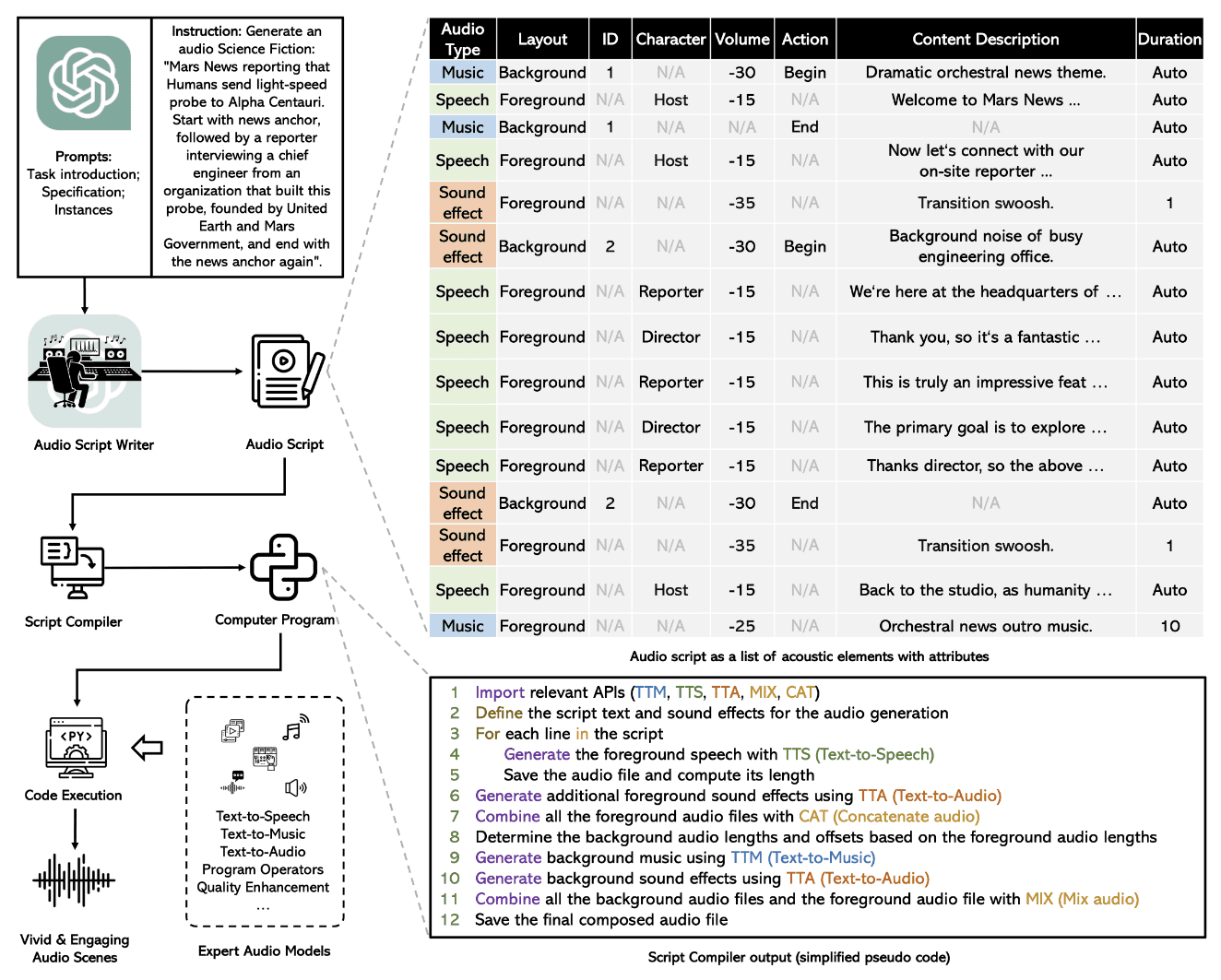
端到端音频生成过程由多个子模块组成,这些子模块按顺序执行,用于完整的文本到音频模型。
音频脚本生成
WavJourney利用GPT-4模型和预定义的提示模板来生成脚本。提示模板将输出限制为简单的 JSON 格式,以后计算机程序可以轻松解析。每个脚本都有 3 种不同的音频类型,如上图所示:语音、音效和音乐。然后,每种音频类型都可以作为前景音频运行,也可以作为背景声音效果覆盖在其他音频上。其他属性(如内容描述、长度和字符)足以正式定义脚本生成的音频设置。
脚本解析
然后,输出脚本通过计算机程序传递,该程序解析预定义 JSON 脚本格式中的相关信息。它将每个描述和字符与预设的语音音频相关联。此过程有助于将音频生成过程分解为单独的步骤,包括文本到语音转换、音乐和声音添加。
音频生成
解析后的脚本作为 Python 程序执行。首先生成前景语音,由背景音乐和音效覆盖。对于语音生成,该模型使用预先训练的 Bark 模型和 VoiceFixer 恢复模型来提高音频质量。AudioLDM和MusicGen模型用于声音效果和音乐叠加。所有三种型号的输出组合在一起,形成最终的音频输出。
人机共创
该过程维护生成的脚本的上下文,并且可以类似于 GPT 模型进行提示。您可以使用 GPT 模型的人工反馈和聊天功能轻松修改生成的脚本。
添加特定的细节和音效再简单不过了。下面的流程图显示了添加或修改生成的脚本的特定详细信息是多么简单。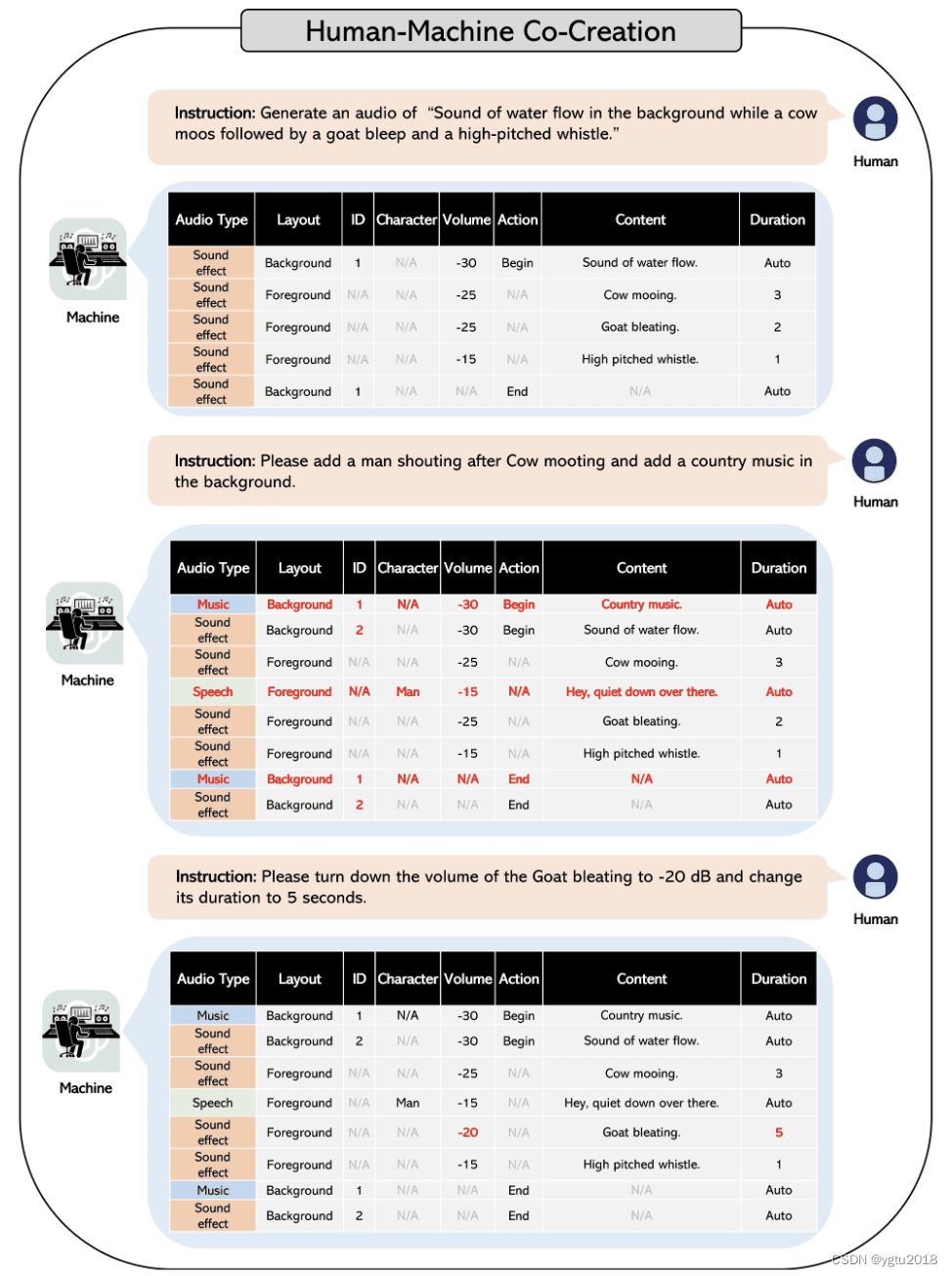
结论
音频生成模式可以改变娱乐行业的游戏规则。该过程能够生成引人入胜的叙述和故事,可用于教育和娱乐目的,自动化繁琐的画外音和视频生成过程。
有关详细理解,请在此处概述论文。该代码将很快在GitHub上提供。
原文链接:WavJourney:进入音频故事情节生成世界的旅程 (mvrlink.com)






![[k8s] pod的创建过程](https://img-blog.csdnimg.cn/b8d3e1f217344535923aea80ca95e56e.png#pic_center)

