这里写目录标题
- 1、捕获异常
- 2、退出程序
- 3、进程共享变量
- 4、multiprocessing的Pool所起的进程中再起进程
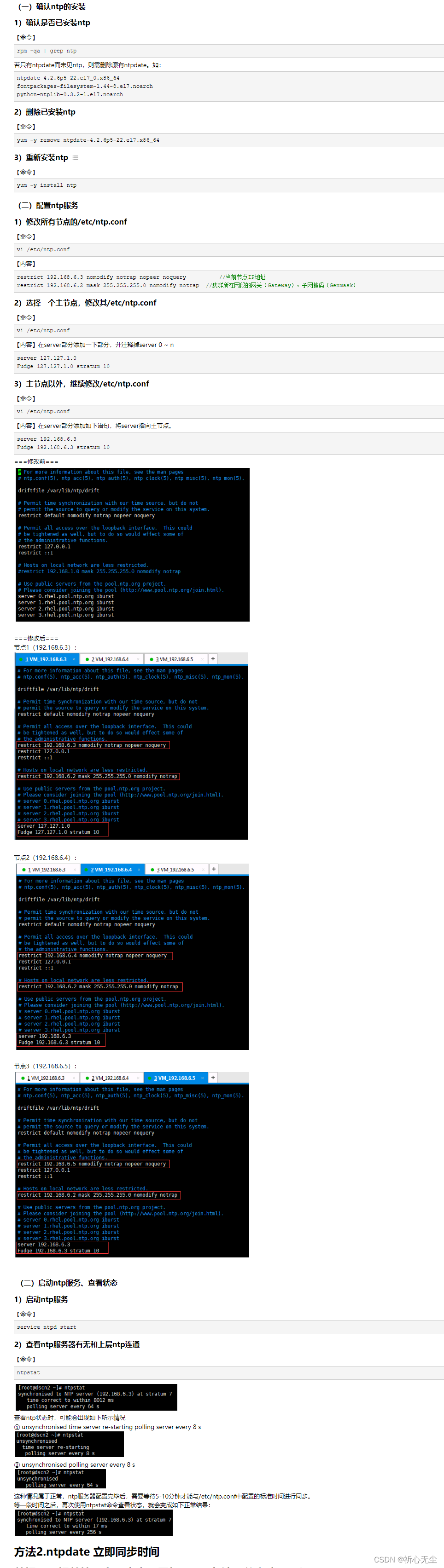
1、捕获异常

https://zhuanlan.zhihu.com/p/321408784
try:<语句>
except Exception as e:print('异常说明',e)
1 捕获所有异常
包括键盘中断和程序退出请求(用 sys.exit() 就无法退出程序了,因为异常被捕获了),因此慎用。try:<语句>
except:print('异常说明')
2 捕获指定异常
try:<语句>
except <异常名>:print('异常说明')
万能异常:try:<语句>
except Exception:print('异常说明')
一个例子:try:f = open("file-not-exists", "r")
except IOError as e:print("open exception: %s: %s" %(e.errno, e.strerror))
2、捕获并判断异常类型
参考:https://blog.csdn.net/weixin_35757704/article/details/128490868
异常的完整代码是:
try:raise Exception("wa")
except:print("报错")
else:print("没有报错")
finally:print("程序关闭")
当异常发生时,会将异常的信息保存到sys.exc_info()这个方法中
import sys
import ostry:raise RuntimeError('这里有个报错')
except Exception as e:except_type, except_value, except_traceback = sys.exc_info()except_file = os.path.split(except_traceback.tb_frame.f_code.co_filename)[1]exc_dict = {"报错类型": except_type,"报错信息": except_value,"报错文件": except_file,"报错行数": except_traceback.tb_lineno,}print(exc_dict)
主动抛出异常
raise Exception("0不能做分母")
2、退出程序
https://zhuanlan.zhihu.com/p/426492312
退出python进程,你可能听说过很多种方法,包括exit(),sys.exit(), os._exit(), quit(),这些方法都可以让进程退出,那么他们有什么区别呢。
下表是对这4种方法的对比
函数 适用场景 是否抛出SystemExit异常
exit 交互式环境 是
quit 交互式环境 是
sys.exit 主进程 是
os._exit 子进程 否
exit和quit都适用于在交互式环境下使用,他们都是内置函数,都抛出SystemExit异常
os._exit 不会抛出SystemExit 异常,一旦执行,进行就退出,因此你来不及做一些清理工作
sys.exit 会抛出SystemExit异常,你可以捕获这个异常,做一些请求工作
sys.exit是python退出程序最常用最正式的一种做法,你必须在调用时指明退出码,退出码为0表示正常退出,其他表示非正常退出。
import systry:sys.exit(3)
except SystemExit as e:print(f'进程退出,退出码是{e.code}')
使用e.code可以获得退出码,程序可以根据退出码不同执行相应的清理工作。
python终止代码运行
方法一:
import sys
sys.exit() # 退出当前程序,但不重启shell
方法二:
exit() # 退出当前程序,并重启shell
方法三:
quit() # 与exit()效果一样,退出并重启shell
3、进程共享变量
Value、Array是通过共享内存的方式共享数据
Manager是通过共享进程的方式共享数据。
'spawn’开启多进程程数据拷贝
num=multiprocessing.Value('d',1.0)#num=0arr=multiprocessing.Array('i',range(10))#arr=range(10)p=multiprocessing.Process(target=func1,args=(num,arr))
manager=Manager()list1=manager.list([1,2,3,4,5])dict1=manager.dict()array1=manager.Array('i',range(10))value1=manager.Value('i',1)
进程间共享变量
如果希望不同进程读写同一个变量,需要做特殊的声明。multiprocessing提供了两种实现方式,一种是共享内存,一种是使用服务进程。共享内存只支持两种数据结构Value和Array。
子进程和主进程访问的count在内存中的地址是相同的。这里有两点需要注意:
- 1.multiprocessing.Value对象和Process一起使用的时候,可以像上面那样作为全局变量使用,也可以作为传入参数使用。但是和Pool一起使用的时候,只能作为全局变量使用,作为传入参数使用会报错。 RuntimeError: Synchronized objects should only be shared between processes through inheritance
- 2.多个进程读写共享变量的时候,要注意操作是否是进程安全的。对于前面的累加计数器,虽然是一个语句,但是涉及到读和写,和进程的局域临时变量,这个操作不是进程安全的。多进程的累加的时候,会出现不正确的结果。需要给cls.count += 1加上锁。加锁的方式,可以使用外部的锁,也可以直接使用get_lock()方法。
- 3.共享内存支持的数据结构有限,另一种共享变量的方式是使用服务进程管理需要共享的变量,其他进程操作共享变量的时候通过和服务进程的交互实现。这种方式支持列表、字典等类型,而且可以实现多台机器之间共享变量。但是速度要比共享内存的方式慢。另外,这种方式可以用作Pool的传入参数。同样的,对于非进程安全的操作,也需要加锁。
4、进程异常捕获(非阻塞)
1.multiprocessing.Process捕获不了异常
p = multiprocessing.Process(target=taskimg_execute, args=(start_img,))
p.start()
2.pool捕获不了,只能通过函数接收
def throw_error(e):print("error回调方法: ", e)return {'code': 440, 'msg': '进程创建异常'+str(e), 'data': {'status': 400}}pool = multiprocessing.Pool(processes = 3)
pool.apply_async(taskimg_execute, (start_img,),rror_callback=throw_error) pool.close()
4、multiprocessing的Pool所起的进程中再起进程
众所周知,multiprocessing是Python内建的多进程库。似乎它的Pool有一个问题是,当起了多进程后,在这些进程中很难再起新的进程,因为会报错 - AssertionError: daemonic processes are not allowed to have children.
参考:https://blog.csdn.net/nirendao/article/details/128945428
而如果不使用 multiprocessing 的 Pool,只是使用其 Process,则相对简单很多,只要在创建 Process 的时候,令其daemon参数为False即可;或者完全不写daemon参数也可以,因为它默认就是False的。