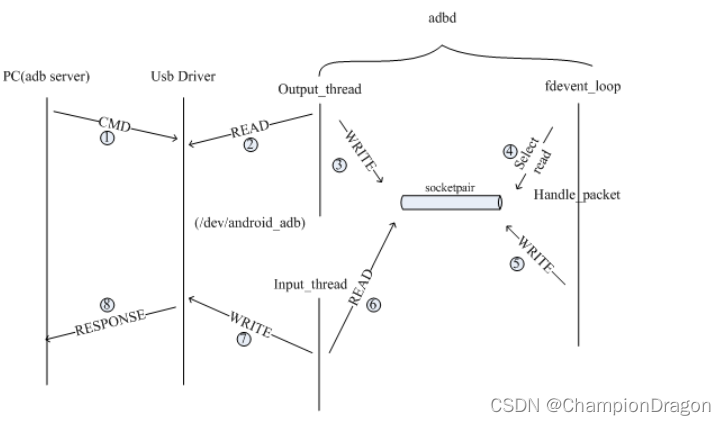
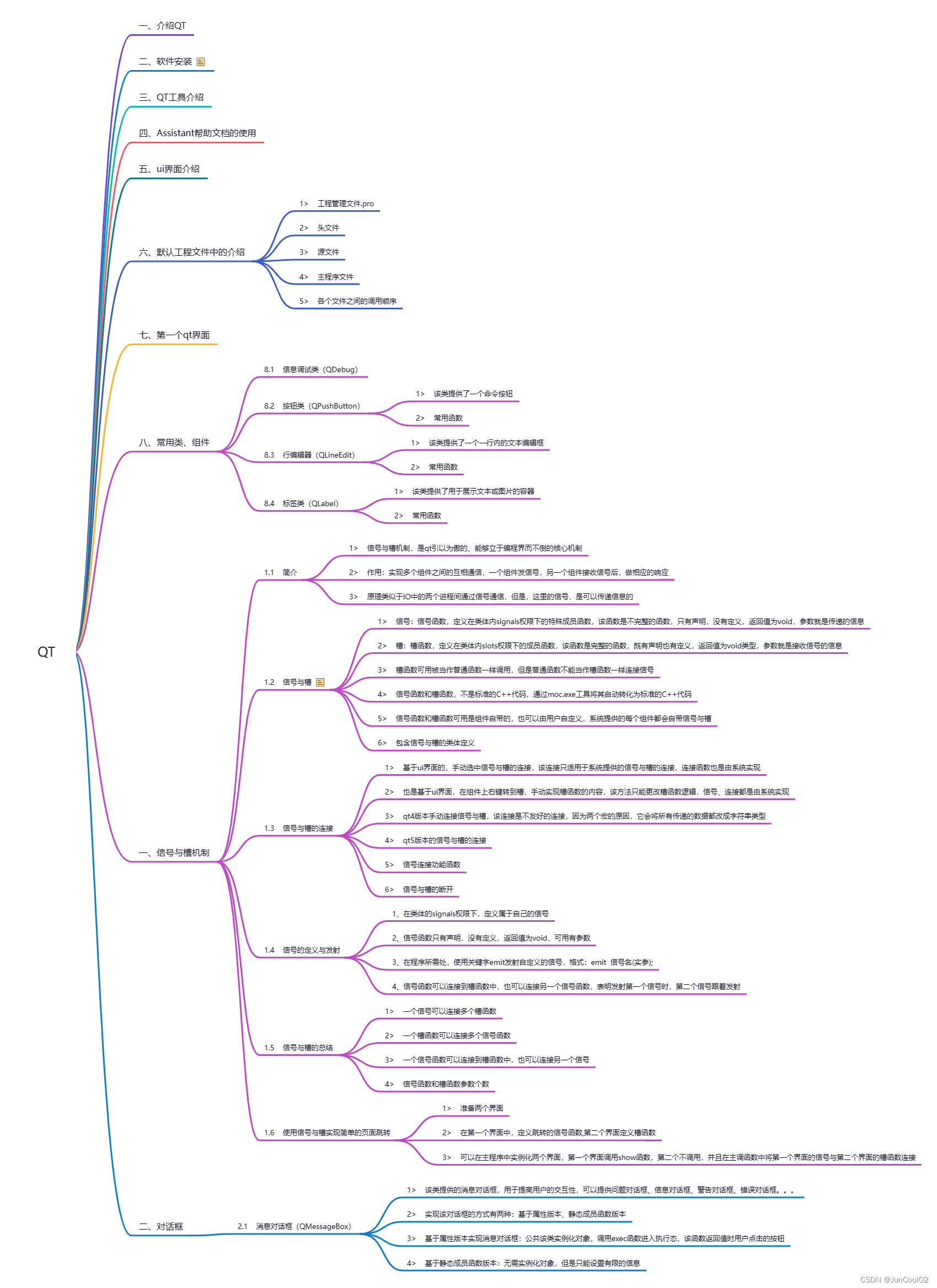
语言本质上是一个由语法规则控制的复杂、精密的人类表达系统,开发能够理解和掌握语言的AI 算法是一个重大挑战。作为一种主要方法,语言建模在过去两十年中已被广泛研究,从统计语言模型发展到神经语言模型,用于语言理解和生成。从技术上讲,语言建模(LM)是提高机器语言智能的主要方法之一。语言模型旨在对单词序列的生成可能性进行建模,以预测未来词出现的概率。人们一般将 LM 的研究分为四个发展阶段。
- 统计语言模型(SLM):基于 1990 年代兴起的统计学习方法开发的,其基本思想是基于马尔科夫假设的词预测模型,其根据最近的上下文预测下一个词。比如统计机器翻译(SMT)和说话人识别(ASR)领域中经常用 到的高斯混合模型(GMM)和隐马尔可夫模型(HMM)。
- 神经语言模型(NLM):通过神经网络表征词序列的概率,例如循环神经网络(RNNs),长短时序记忆网络(LSTM)和门控循环网络 (GRU)。
- 预训练语言模型(PLM): 大部分基于具有自注意机制的高度可并行化的 Transformer 架构,通过在大规模未标记语料库上进行预训练,然后进行优调以适配不同的下游任务。例如 BERT,BART,T5 等。

- 大型语言模型(LLM):在 PLM 的基础上,增大模型参数,使得 LLM 出现 PLM 不具有的涌现能力,其同样采用预训练 + 微调的形式,不过这个范式逐渐向上下文学习(in-context-learning)转变。近年来 LLM 的发展历程如下图所示,其中就包括了最近热门的 chatGPT 和 GPT4。

最近,通过在大规模语料库上预训练Transformer 模型,提出了预训练语言模型(PLMs),在解决各种自然语言处理(NLP)任务方面表现出强大的能力。研究人员发现,模型规模越大,性能也会提高, 因此他们进一步将模型大小增加到更大的规模,研究了规模效应。有趣的是,当参数规模超过一定水平时,这些大型语言模型不仅能够显著提高性能,还展现了一些小型语言模型所没有的特殊能力。为了区分参数规模差异, 研究界为这些规模显著的 PLMs 创造了大型语言模型(LLM)这一术语。最近,学术界和工业界都取得了大量关于 LLMs 的研究进展,其中一个显著进展是 ChatGPT 的发布,引起了社会的广泛关注。LLMs 技术的进化对整个 AI 社区都产生了重要的影响,这将彻底改变本文开发和使用 AI 算法的方式。
通常,大型语言模型(LLM)是指包含数百亿(或更多)参数的语言模型,这些参数是在大量无标注文本数据上自监督学习方法训练的,例如模型 GPT-3、PaLM、Galactica 和 LLaMA。2019 年大模型呈现爆发式的增长,特别是 2022 年 11 月ChatGPT(Chat Generative Pre-trained Transformer)发布后,更是引起了全世界的广泛关注。具体来说,LLM 建立在Transformer 架构之上,其中多头注意力层堆叠在一个非常深的神经网络中。现有的LLM 主要采用与小语言模型类似的模型架构(即Transformer)和预训练目标(即语言建模)。作为主要区别, LLM 在很大程度上扩展了模型大小、预训练数据和总计算量(扩大倍数)。他们可以更好地理解自然语言,并根据给定的上下文(例如 prompt)生成高质量的文本。这种容量改进可以用标度律进行部分地描述,其中性能大致遵循模型大小的大幅增加而增加。然而根据标度律,某些能力(例如,上下文学习)是不可预测的,只有当模型大小超过某个水平时才能观察到。
ps: 欢迎扫码关注微信公众号^-^.






![buuctf web [极客大挑战 2019]Secret File](https://img-blog.csdnimg.cn/429d742b40714b79967e78cc72fe7f06.png)