目录
一、信任表中加入指定的普通用户(使其能使用sudo)
二、vim的使用
(一)基本概念
1. 正常/普通/命令模式(Normal mode)
2. 插入模式(Insert mode)
3. 末行模式(last line mode)
(二)vim正常模式命令集
1. 移动光标
2. 翻页
3. 删除文字
4. 复制
5. 剪切
6. 大小写转换
7. 替换
8. 更改
9. 撤销
10. 注释
(三)vim末行模式命令集
1. 行号设置
2. 保存和退出
3. 分屏
4. 不退出vim执行
三、gcc/g++的使用
(一)预处理(进行宏替换)
(二)编译(生成汇编)
(三)汇编(生成机器可识别代码)
(四)链接(生成可执行文件或库文件)
(五)动态库和静态库
1. 库的命名
2. 动态库和静态库
3. 动态链接和静态链接的优缺点
4. 安装c和c++静态库
5. 动态链接和静态链接分别生成的文件
四、自动化构建工具-make/Makefile
(一)依赖关系和依赖方法
(二)make原理
(三)项目清理
(四)make,makefile是具有依赖性的推导能力的
(五)一些小技巧
1. @符号
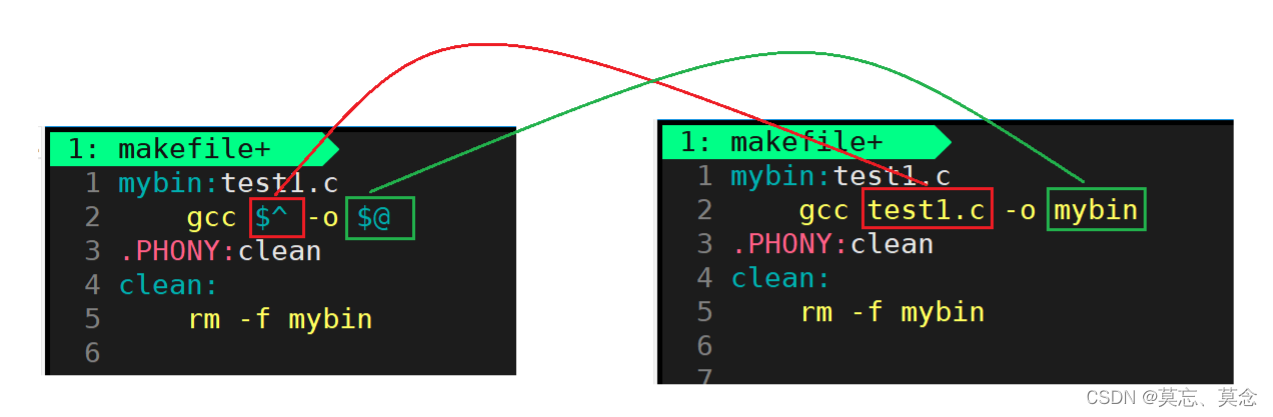
2. $(变量名)
(六)Makefile中一些常用变量的简写方式
五、文件或者目录的时间属性
六、实现进度条
(一)行缓冲区
(二)进度条
一、信任表中加入指定的普通用户(使其能使用sudo)
- 允许普通用户以超级用户(或系统管理员)的身份执行命令
sudo ls的意思是以超级用户的权限来执行ls命令,这样即使普通用户没有权限访问某些文件或目录,也可以列出它们的信息
vim /etc/sudoers//在root账号下打开信任表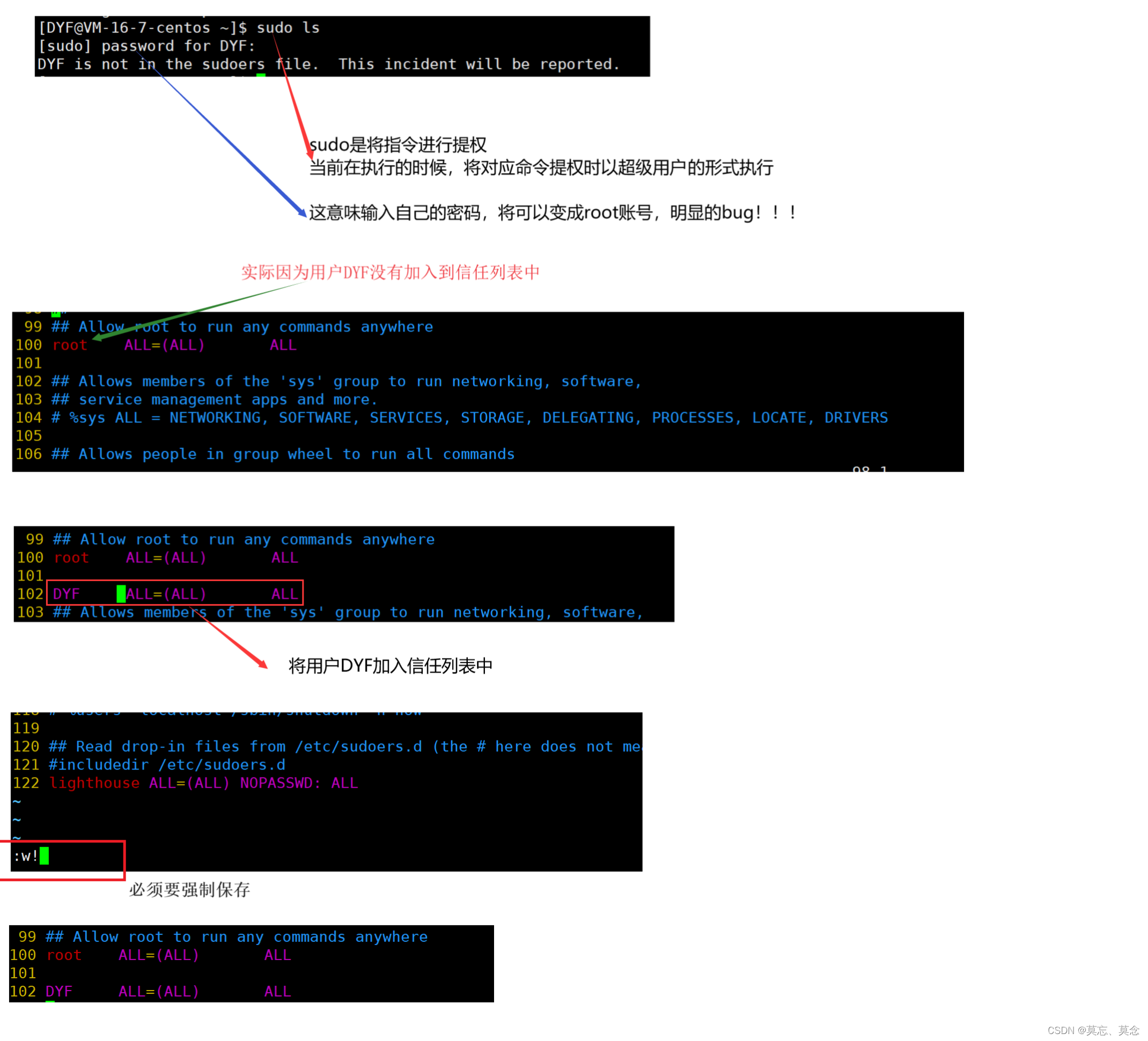

二、vim的使用
(一)基本概念
- vim最常用的三种模式:命令模式、插入模式、底行模式
1. 正常/普通/命令模式(Normal mode)
- 控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode
2. 插入模式(Insert mode)
- 只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。
3. 末行模式(last line mode)
- 文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。 在命令模式下,shift+: 即可进入该模式。要查看你的所有模式:打开vim,底行模式直接输入

(二)vim正常模式命令集
1. 移动光标
- vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、「l」,分别控制光标左、下、上、右移一格
- 按「G」:移动到文章的最后
- 按「Shift+$ 」:移动到光标所在行的“行尾”
- 按「Shift+^」:移动到光标所在行的“行首”
- 按「w」:光标跳到下个字的开头
- 按「e」:光标跳到下个字的字尾
- 按「b」:光标回到上个字的开头
- 按「#l」:光标移到该行的第#个位置,如:5l,56l
- 按[gg]:进入到文本开始
- 按「Shift+g」:移动到文本末尾
- 按「n+Shift+g」:移动到第n行行首
- 按「n+Shift+g」:移动到第n行行首
2. 翻页
- 按[shift+g]:进入文本末端
- 按「ctrl」+「b」:向上翻一页
- 按「ctrl」+「f」:向下翻一页
- 按「ctrl」+「u」:向上翻半页
- 按「ctrl」+「d」:向下翻半页
3. 删除文字
- 按「x」:删除光标所在位置的字符
- 按「nx」:删除光标所在位置开始往后的n个字符
- 按「X」:删除光标所在位置的前一个字符
- 按「nX」:删除光标所在位置的前n个字符
- 按「dd」:删除光标所在行
- 按「ndd」:删除光标所在行开始往下的n行
4. 复制
- 按「yy」:复制光标所在行到缓冲区
- 按「nyy」:复制光标所在行开始往下的n行到缓冲区。
- 按「yw」:将光标所在位置开始到字尾的字符复制到缓冲区
- 按「nyw」:将光标所在位置开始往后的n个字复制到缓冲区

- 按「p」:将已复制的内容在光标的下一行粘贴上
- 按「np」:将已复制的内容在光标的下一行粘贴n次
5. 剪切
- 按「dd」:剪切光标所在行
- 按「ndd」:剪切光标所在行开始往下的n行
- 按「p」:将已剪切的内容在光标的下一行粘贴上
- 按「np」:将已剪切的内容在光标的下一行粘贴n次

6. 大小写转换
- 按「Shift+~」:完成光标所在位置字符的大小写切换

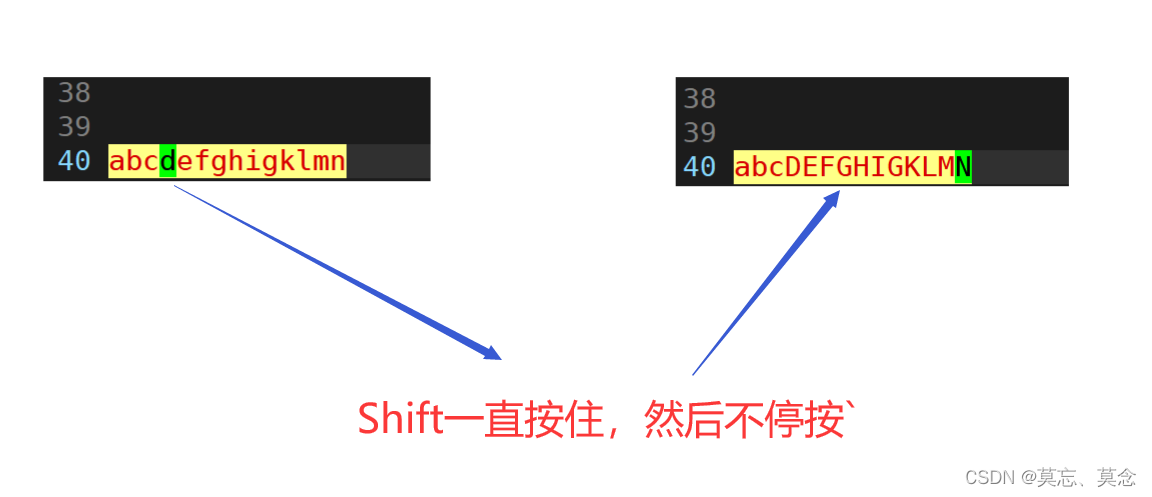
7. 替换
- 按「r」:替换光标所在位置的字符。
注意:先切换到命令模式,然后按r,然后再按任意字符即可替换成 字符
- 按「R」:替换光标所到位置的字符,直到按下「Esc」键为止
8. 更改
- 按「cw」:将光标所在位置开始到字尾的字符删除,并进入插入模式
- 按「cnw」:将光标所在位置开始往后的n个字删除,并进入插入模式


9. 撤销
- 按「u」:撤销。
- 按「Ctrl+r」:撤销刚才的撤销
10. 注释
- 批量化注释:
- ctrl+v --->j/k两个按键上下选中区域---> shift+i(I)---> // --->Esc
- 批量化删除注释:
- ctrl+v ---> hjkl选中区域 --->d即可
(三)vim末行模式命令集
1. 行号设置
- 「set nu」:列出行号
- 「set nonu」:取消行号
2. 保存和退出
- 「w」:保存文件。
- 「q」:退出vim
- 「wq」:保存退出
- 「wq!」:强制保存并退出
3. 分屏
- 「vs 文件名」:实现多文件的编辑
- 「Ctrl+ww」:光标在多屏幕下进行切换
4. 不退出vim执行
「!+指令」:在不退出vim的情况下,执行Linux的指令
三、gcc/g++的使用
- c++中对应的文件后缀有cpp,cc和cxx
(一)预处理(进行宏替换)
- 预处理功能主要包括宏定义、文件包含、条件编译、去注释等
- 预处理指令是以#号开头的代码行
- 选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程
- 选项“-o”是指目标文件,“.i”文件为已经过预处理的C原始程序
gcc -E test1.c -o test1.i

(二)编译(生成汇编)
- 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
-
用户可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码
- 编译过程为 扫描程序-->语法分析-->语义分析-->源代码优化-->代码生成器-->目标代码优化
- 扫描程序进行词法分析,从左向右,从上往下扫描源程序字符,识别出各个单词,确定单词类型
- 语法分析是根据语法规则,将输入的语句构建出分析树,或者语法树,也就是我们答案中提到的分析树parse tree或者语法树syntax tree
- 语义分析是根据上下文分析函数返回值类型是否对应这种语义检测,可以理解语法分析就是描述一个句子主宾谓是否符合规则,而语义用于检测句子的意思是否是正确的
- 目标代码生成指的是,把中间代码变换成为特定机器上的低级语言代码。
gcc -S test1.i -o test1.s
(三)汇编(生成机器可识别代码)
- 汇编阶段是把编译阶段生成的“.s”文件转成目标文件
- 在此可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码
- 此时的test1.o虽然的二进制文件但是不能执行
gcc -c test1.s -o test1.o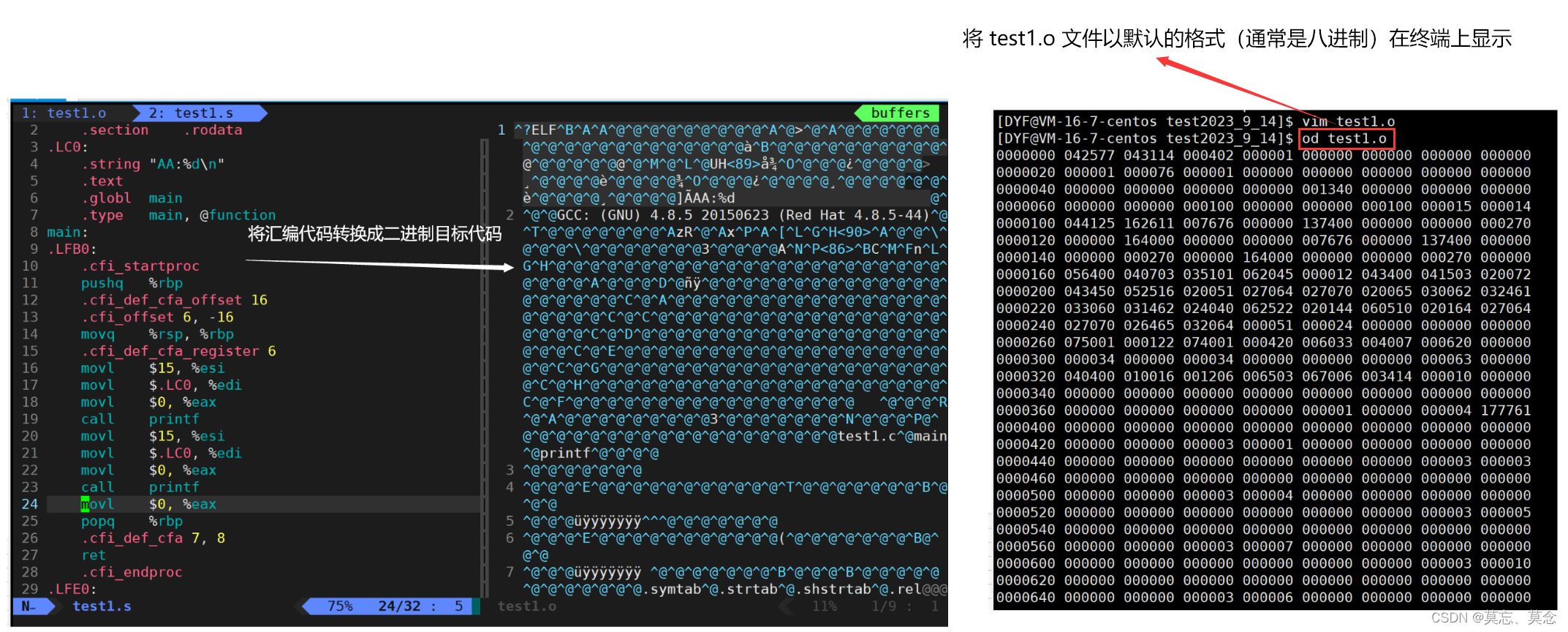
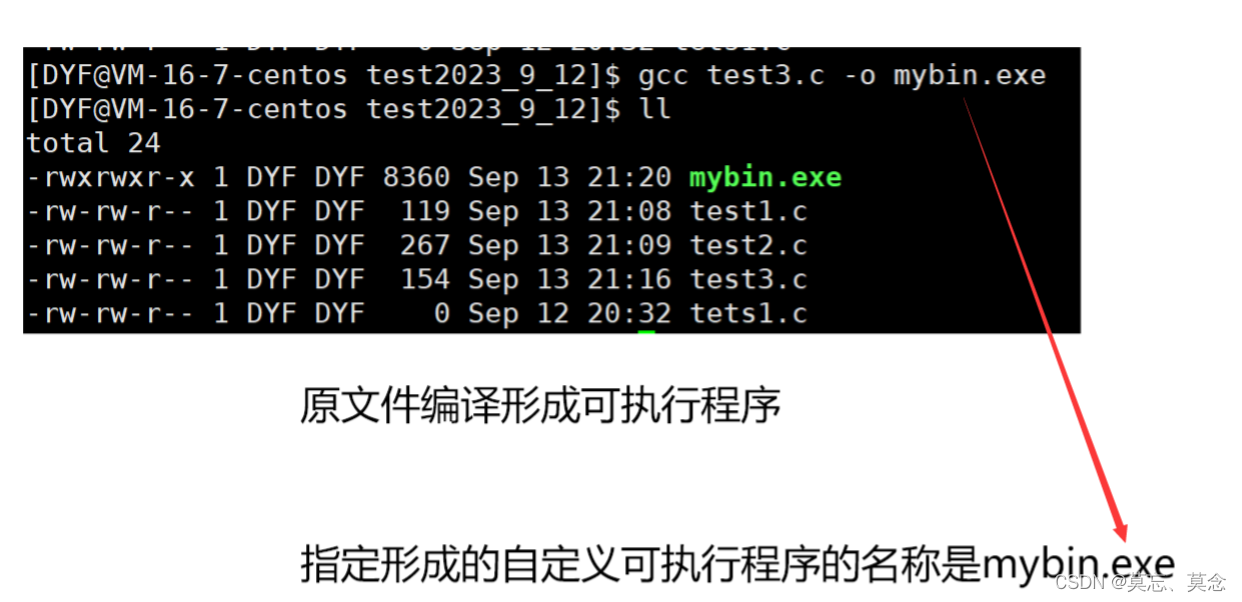
(四)链接(生成可执行文件或库文件)
gcc test1.o -o mybin//将目标文件 test1.o 链接成一个可执行文件,并将可执行文件命名为mybin
(五)动态库和静态库
1. 库的命名

2. 动态库和静态库
- 动态库:在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为“.so”,如前面所述的 libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件
- 静态库:是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”
3. 动态链接和静态链接的优缺点
动态链接:
优点:形成的可执行程序提交比较小,比较节省资源
缺点:稍慢一些,依赖动态库,程序可移植性较差
静态链接:
优点:无视库,可以独立运行
缺点:体积太大,浪费资源
4. 安装c和c++静态库
sudo yum install glibc-static//c静态库 sudo yum install -y libstdc++-static//c++静态库5. 动态链接和静态链接分别生成的文件
gcc test1.c -o test1_move//默认动态链接生成gcc test1.c -o test1_quiet -static//静态链接生成
四、自动化构建工具-make/Makefile
- make:是一个命令
- makefile:是一个在当前目录下存在的一个具有特定格式的文本文件
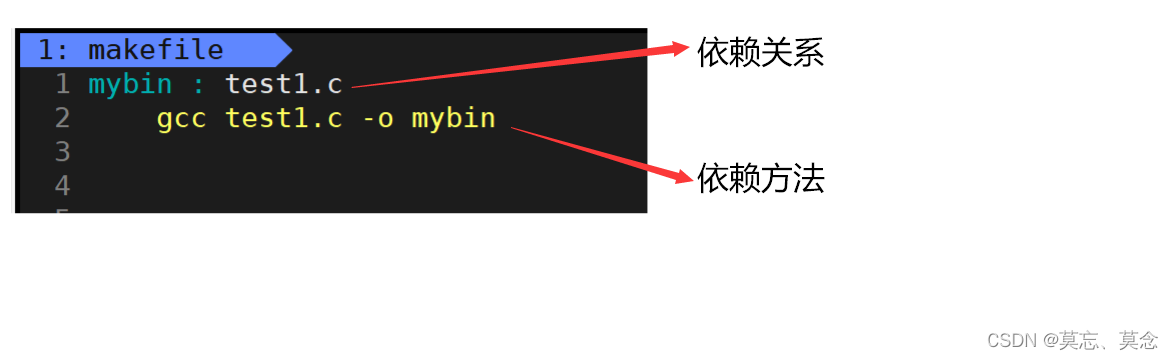
(一)依赖关系和依赖方法
依赖关系:
- 上面的文件 mybin ,它依赖 test1.o
- test1.o , 它依赖 test1.s
- test1.s , 它依赖 test1.i
- test1.i , 它依赖 test1.c
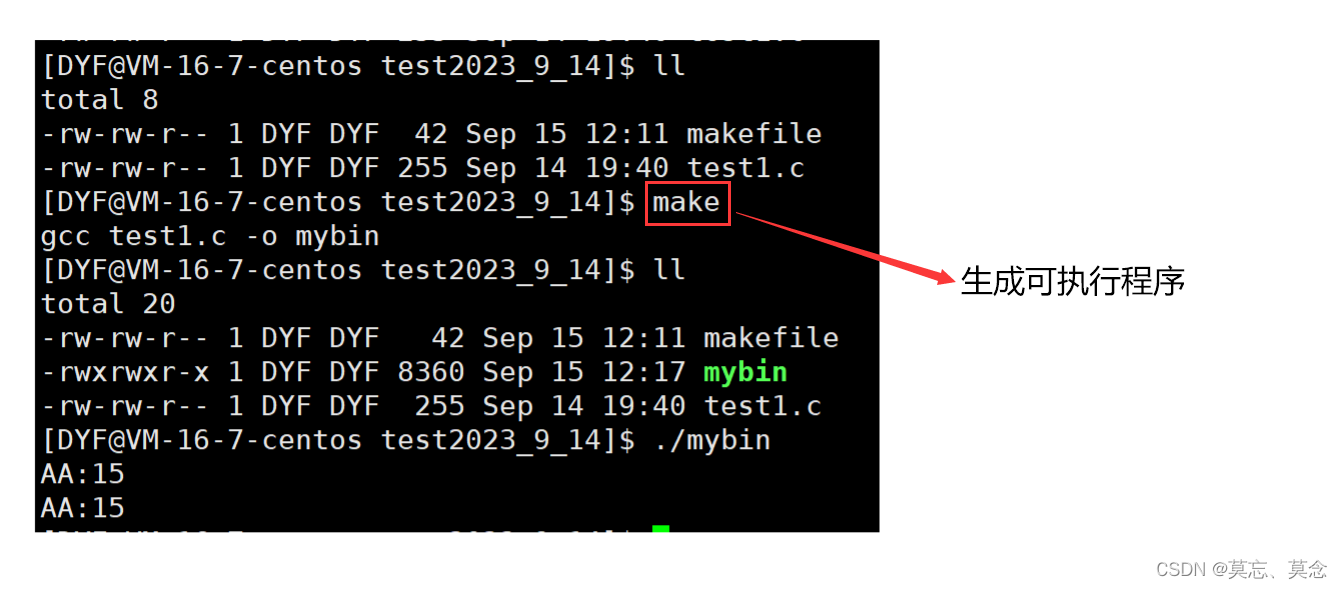
(二)make原理
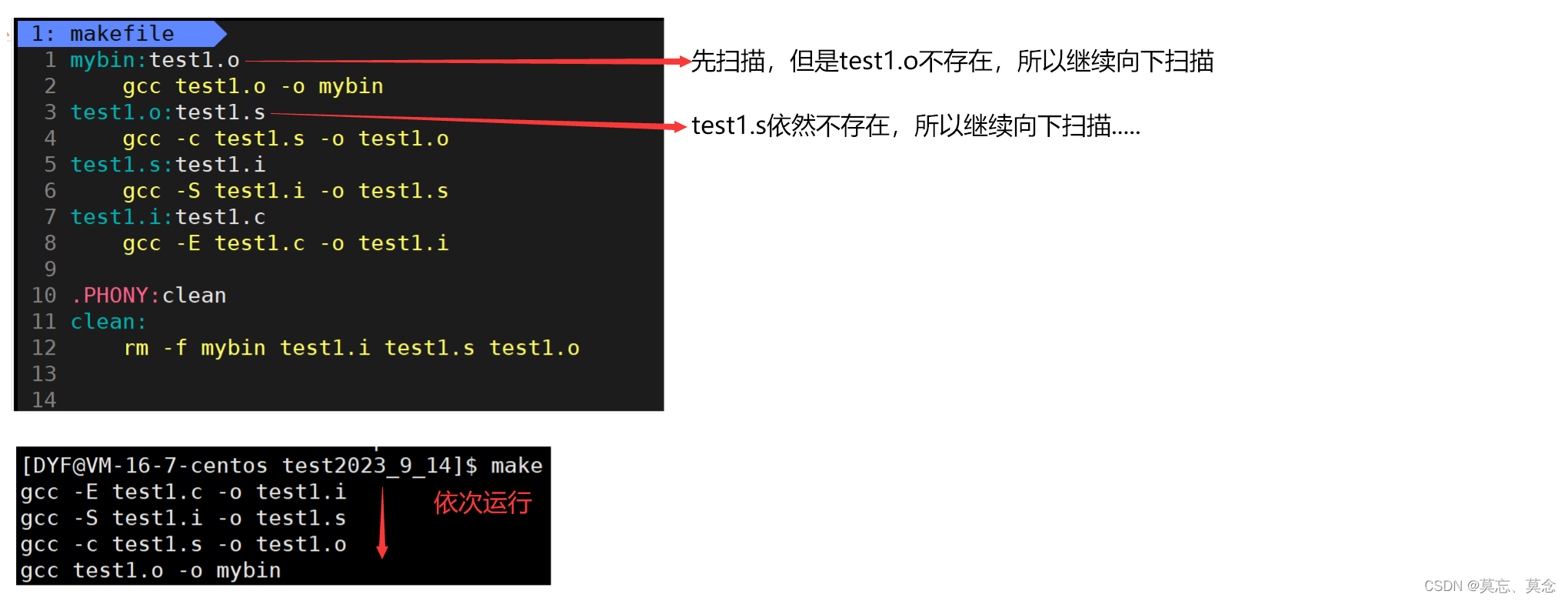
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件,在下面的例子中,他会找到mybin这个文件,并把这个文件作为最终的目标文件。
- 如果mybin文件不存在,或是mybin所依赖的后面的test1.o文件的文件修改时间要比mybin这个文件新,那么,他就会执行后面所定义的命令来生成mybin这个文件。
- 如果mybin所依赖的test1.o文件不存在,那么make会在当前文件中找目标为test1.o文件的依赖性,如果找到则再根据那一个规则生成test1.o文件。(这有点像一个堆栈的过程)
- 当然,test1.c是存在的,于是make会生成test1.o文件,然后再用test1.o文件声明make的终极任务,也就是执行文件mybin了。
- 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
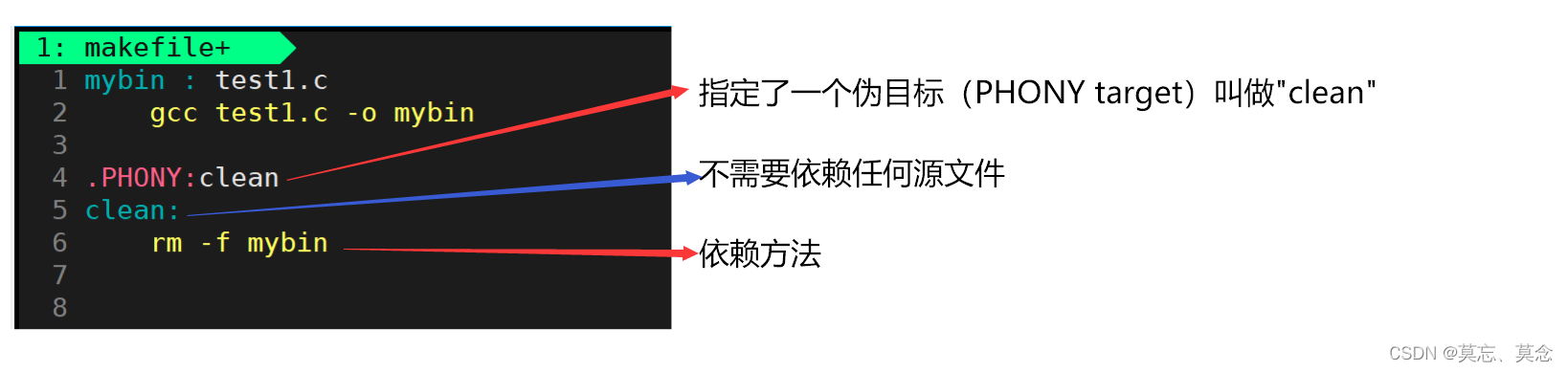
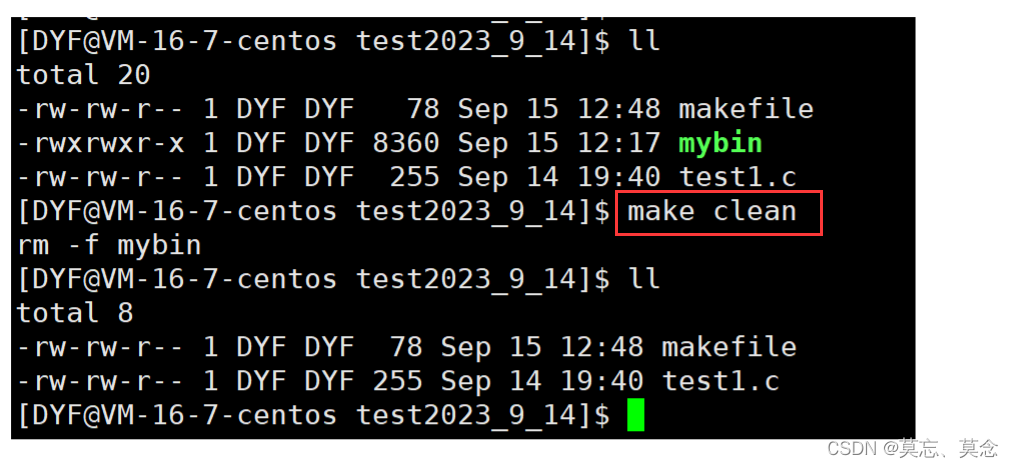
(三)项目清理
(四)make,makefile是具有依赖性的推导能力的
(五)一些小技巧
1. @符号
- 用于抑制命令的输出,使得在执行该命令时不会在终端上显示具体的命令内容

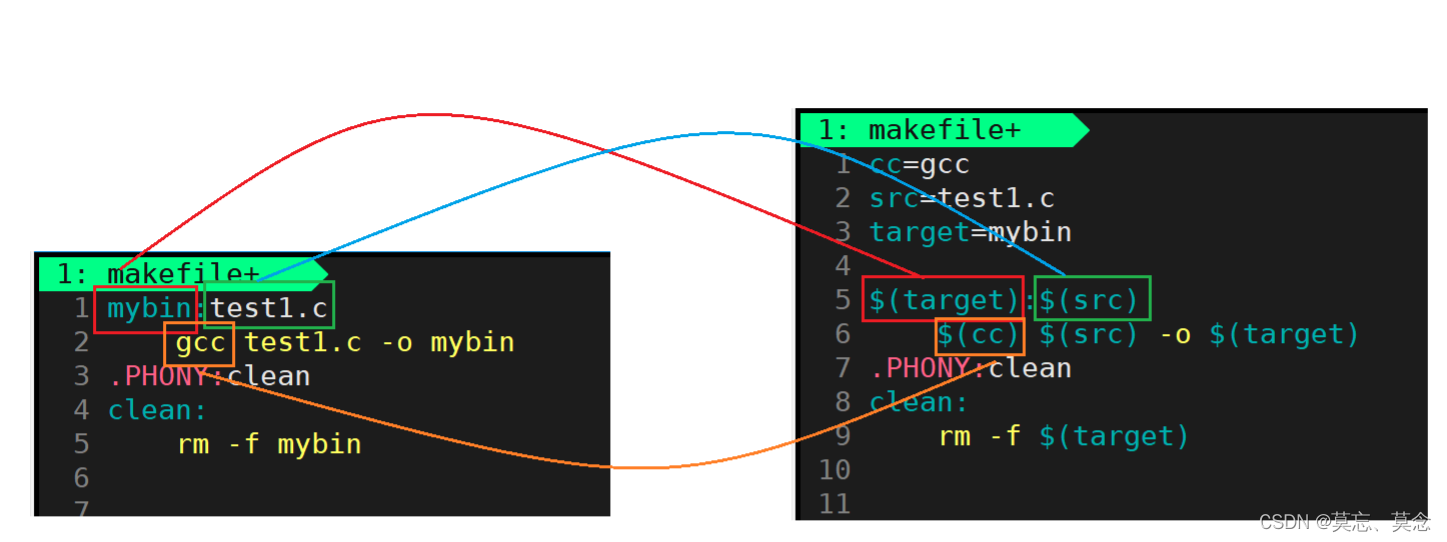
2. $(变量名)
cc=gcc
src=test1.c
target=mybin$(target):$(src)$(cc) $(src) -o $(target)
.PHONY:clean
clean:rm -f $(target)
(六)Makefile中一些常用变量的简写方式
$@:表示目标文件(冒号左侧的文件名)$^:表示所有的依赖文件列表(冒号右侧的文件列表)$<:表示依赖关系中的第一个依赖文件
五、文件或者目录的时间属性
- Access Time (atime):指的是文件或目录最后一次被访问的时间。例如,当你打开一个文件或者读取它时,它的访问时间就会被更新。
- Modify Time (mtime):指的是文件或目录的内容最后一次被修改的时间。当你编辑或者写入文件时,它的修改时间就会被更新。
- Change Time (ctime):指的是文件或目录的状态最后一次被修改的时间。这包括文件或目录的内容、权限、所有者等信息的变更。
stat mybin//获取关于文件或目录的详细信息,包括访问时间、修改时间、状态改变时间等 
六、实现进度条
(一)行缓冲区
- 行缓冲(line buffering)是一种I/O缓冲策略,这意味着在遇到换行符(\n)或者缓冲区满之前,输出的文本都会被暂时存储在缓冲区中,而不会立即显示在屏幕上
- 没有换行


- 利用fflush


(二)进度条
\r:是回车
\n:是换行





![[hive]搭建hive3.1.2hiveserver2高可用可hive metastore高可用](https://img-blog.csdnimg.cn/b36e0643ebb545ff875c8a963c960f3e.png)




![读书笔记-《ON JAVA 中文版》-摘要25[第二十二章 枚举]](https://img-blog.csdnimg.cn/4606b2bdbe5649baa6dc96e5fbf95382.png)