前言
Puppeteer已经听说过很多次了,也见过一些与之相关的文章。但是一直没怎么研究过,现在来简单学习一下。
简介
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行,但是可以通过修改配置文件运行“有头”模式。
功能
- 生成页面 PDF。
- 抓取 SPA(单页应用)并生成预渲染内容(即“SSR”(服务器端渲染))。
- 自动提交表单,进行 UI 测试,键盘输入等。
- 创建一个时时更新的自动化测试环境。 使用最新的 JavaScript 和浏览器功能直接在最新版本的Chrome中执行测试。
- 捕获网站的 timeline trace,用来帮助分析性能问题。
- 测试浏览器扩展。
官方文档: https://puppeteer.bootcss.com/
推荐文章: 奶奶都能轻松入门的 Puppeteer 教程
准备
安装
npm i puppeteer
安装时会下载最新版的Chromium,以保证可以使用 API。
注: 默认下载时会下载最新版本,如果你的node版本过低会出现下面这个问题,要么升级node版本,要么下载旧版本的Puppeteer。我这里更新了一下node的版本
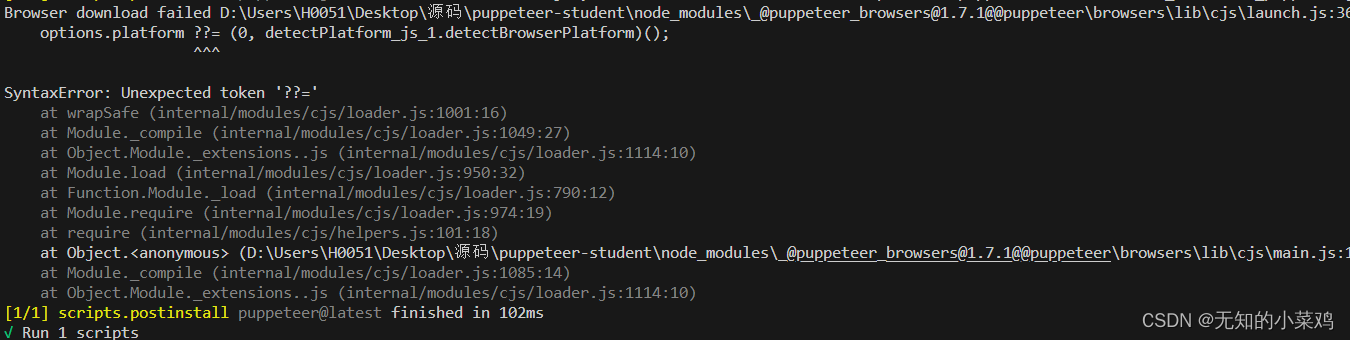

除了上面那个问题,如果你还遇到了类似ERROR: Failed to set up Chrome r116.0.5845.96! Set "PUPPETEER_SKIP_DOWNLOAD" env variable to skip download 这样的问题,这是因为 当你安装 Puppeteer 时,它会下载最新版本的Chromium(~170MB Mac,~282MB Linux,~280MB Win),以保证可以使用 API。
这说明下载Chromium失败了,我这里最终解决这个问题是通过安装低版本的Puppeteer
npm install puppeteer.11.1
执行官方示例,验证是否安装成功
下面我们执行一下官方提供的截图例子:
example.js
const puppeteer = require('puppeteer');(async () => {const browser = await puppeteer.launch();const page = await browser.newPage();await page.goto('https://example.com');await page.screenshot({path: 'example.png'});await browser.close();
})();
node example.js
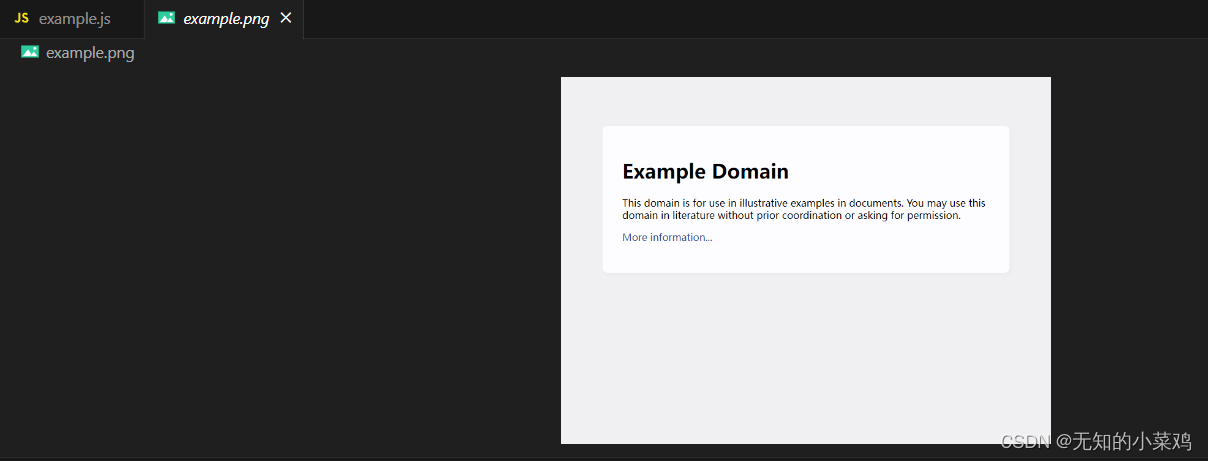
出现了以上这个图片,上面你已经安装成功了,下面进入正题
使用
基本使用
const puppeteer = require("puppeteer");// 初始化函数
const init = async () => {// 启动浏览器const browser = await puppeteer.launch({headless: false, // 是否以无头模式运行,默认为 true,除非选择开启了开发者工具devtools: true, // 是否自动打开开发者工具,默认为 falseargs: ["--start-maximized"], // 启动时传递给浏览器的额外参数});// 创建一个标签页const page = await browser.newPage();// 跳转到相应的网站await page.goto("https://example.com");// 截图等其他操作await page.screenshot({ path: "example.png" });// 关闭浏览器await browser.close();
};init();
无头模式和有头模式
无头模式和有头模式是Puppeteer中的两种不同的浏览器运行模式。
-
无头模式(Headless Mode):无头模式表示在后台运行浏览器,没有可见的用户界面。它在无需图形界面的场景下非常有用,比如进行自动化测试、爬取网页数据等。无头模式的优势是节省资源,提高性能,因为它不需要渲染和显示页面。
-
有头模式(Headful Mode):有头模式表示以常规的图形界面方式运行浏览器,可以看到实际的浏览器页面。这对于调试和开发过程中的可视化操作非常有帮助,比如查看页面布局、调试JavaScript等。有头模式通常会消耗更多的系统资源,因为它需要进行页面渲染和显示。
有头模式运行时如下,会出现一个图形界面,操作执行完成后会自动关闭
puppeteer.launch的其他常用配置属性
// <boolean> 是否在导航期间忽略 HTTPS 错误. 默认是 false。
// 当设置为true时,Puppeteer在导航过程中会忽略与 HTTPS 相关的错误,例如证书错误或安全警告。这在某些情况下很有用,例如当你访问的网站的 SSL 证书有问题或者过期时,仍然可以继续进行导航和操作。
// 忽略 HTTPS 错误的情况下,你的连接可能是不安全的。因此,在生产环境中,建议不要使用这个选项
ignoreHTTPSErrors// <?Object> 为每个页面设置一个默认视口大小。包括宽高、缩放的,默认为800 * 600
defaultViewport // <Array<string>> 传递给浏览器实例的其他参数。具体见官方文档
args
错误处理
const {TimeoutError} = require('puppeteer/Errors');try {// 等待获取dom元素await page.waitForSelector('.foo');
} catch (e) {if (e instanceof TimeoutError) {// 如果超时,做一些处理。}
}
page
Page 提供操作一个 tab 页或者 extension background page 的方法。一个 Browser 实例可以有多个 Page 实例。
在实际应用中,几乎所有常见的应用都是围绕着页面来使用的。如果想要玩好Puppeteer 就需要掌握好Page
事件
我们可以通过page.on 或者 page.once 来监听事件,通过page.removeListener来移除事件
function logRequest(interceptedRequest) {console.log('A request was made:', interceptedRequest.url());
}
page.on('request', logRequest);
// 一段时间后...
page.removeListener('request', logRequest);
常见的事件
- close:当页面关闭时触发
- domcontentloaded:当页面的
DOMContentLoaded(当 HTML 文档被完全解析,并且所有延迟脚本都已下载并执行时,将触发 DOMContentLoaded 事件。它不会等待图像、子帧和异步脚本等其他内容完成加载。)事件被触发时触发。 - error:当页面崩溃是触发
- load:当页面的 load 事件被触发时触发
- request:当页面发送一个请求时触发。参数 request 对象是只读的。 如果需要拦截并且改变请求,参考
page.setRequestInterception - requestfailed:当页面的请求失败时触发。比如某个请求超时了
- requestfinished:当页面的某个请求成功完成时触发。
- response:当页面的某个请求接收到对应的 response 时触发
常用方法
page.$(selector):此方法在页面内执行document.querySelector。如果没有元素匹配指定选择器,返回值是 null。page.$$(selector):此方法在页面内执行document.querySelectorAll。如果没有元素匹配指定选择器,返回值是 []。page.$eval(selector, pageFunction[, ...args]):此方法在页面内执行document.querySelector,然后把匹配到的元素作为第一个参数传给 pageFunction。如果 pageFunction 返回的是 Promise,那么此方法会等 promise 完成后返回其返回值。const searchValue = await page.$eval('#search', el => el.value);类似于找到这个dom元素,并对这个dom元素执行一些操作。page.$$eval(selector, pageFunction[, ...args]):此方法在页面内执行Array.from(document.querySelectorAll(selector)),然后把匹配到的元素数组作为第一个参数传给 pageFunction。如果 pageFunction 返回的是 Promise,那么此方法会等 promise 完成后返回其返回值。page.addScriptTag(options):往页面中注入脚本,await page.addScriptTag({ path: 'path/to/your/script.js' });跟浏览器插件中的脚本注入基本上是一样的,通过注入的脚本来修改页面page.addStyleTag(options):往页面中注入样式,await page.addStyleTag({ path: 'path/to/your/styles.css' });page.browser():得到当前 page 实例所属的 browser 实例。page.click(selector[, options]):点击指定的元素,如果有多个匹配的原生,点击第一个page.content():返回完整的html代码page.focus(selector):使指定元素获取焦点,如果有多个匹配的元素,焦点给第一个元素page.goBack([options]):导航到页面历史的前一个页面page.goForward([options]):导航到页面历史的后一个页面page.goto(url[, options]):跳转到指定url的网页page.isClosed():判断页面是否被关闭page.evaluate(pageFunction[, ...args]):在页面实例上下文中执行方法,返回方法执行的结果page.keyboard:用于与键盘进行交互的类page.mouse:用于与鼠标进行交互的类page.pdf([options]):生成当前页面的pdf文件,默认会返回一个二进制编码,具体配置见文档page.screenshot([options]):生成页面截图,默认会返回一个二进制编码,也可以设置为base64,具体配置见文档page.select(selector, ...values):用于选择页面中的下拉列表。它接受一个选择器参数和一个或多个值参数。该方法会在页面上找到匹配选择器的下拉列表元素,并将值参数中的选项选中。例如:`await page.select(‘select#myDropdown’, ‘option1’, ‘option2’);page.setExtraHTTPHeaders(headers):当前页面发起的每个请求都会带上这些请求头page.setRequestInterception(value):是否启用请求拦截器,启用请求拦截器,会激活request.abort,request.continue和request.respond方法。这提供了修改页面发出的网络请求的功能。一旦启用请求拦截,每个请求都将停止,除非它继续,响应或中止page.title():返回页面标题page.type(selector, text[, options]):用于输入内容,例如
page.type('#mytextarea', 'Hello'); // 立即输入
page.type('#mytextarea', 'World', {delay: 100}); // 输入变慢,像一个用户
page.waitForNavigation([options]):用于等待页面导航完成,只有当新页面加载完成后才可以继续进行后续操作。page.waitForSelector(selector[, options]):等待指定的选择器匹配的元素出现在页面中,如果调用此方法时已经有匹配的元素,那么此方法立即返回。 如果指定的选择器在超时时间后扔不出现,此方法会报错。
Keyboard
Keyboard 提供一个接口来管理虚拟键盘. 高级接口为 keyboard.type,,其接收原始字符, 然后在你的页面上生成对应的 keydown, keypress/input 和 keyup 事件
常用方法
page.type:接收字符
page.type('#mytextarea', 'Hello'); // 立即输入
page.type('#mytextarea', 'World', {delay: 100}); // 输入变慢,像一个用户
keyboard.down(key[, options]):按下指定键
await page.keyboard.down('Shift');
keyboard.up(key):释放按下的键
await page.keyboard.up('Shift');
使用keyboard.down按下的键必须使用keyboard.up进行释放,否则该键会一直保持按下的状态
keyboard.press(key[, options]):按下并里面释放该键,相当于keyboard.down和keyboard.up的组合,可以指定按下与释放之间的间隔时间
await page.keyboard.press('KeyA');
Mouse
Mouse用于模拟鼠标
常用方法
mouse.click(x, y, [options]):使用鼠标点击指定位置,默认左键,点击一次
mouse.down([options]) :鼠标按下,默认是左键,默认按下一次
mouse.up([options]):鼠标抬起,默认左键,默认一次
示例
做一个稍微复杂一点的例子:
步骤
1、打开菜鸟教程的主界面
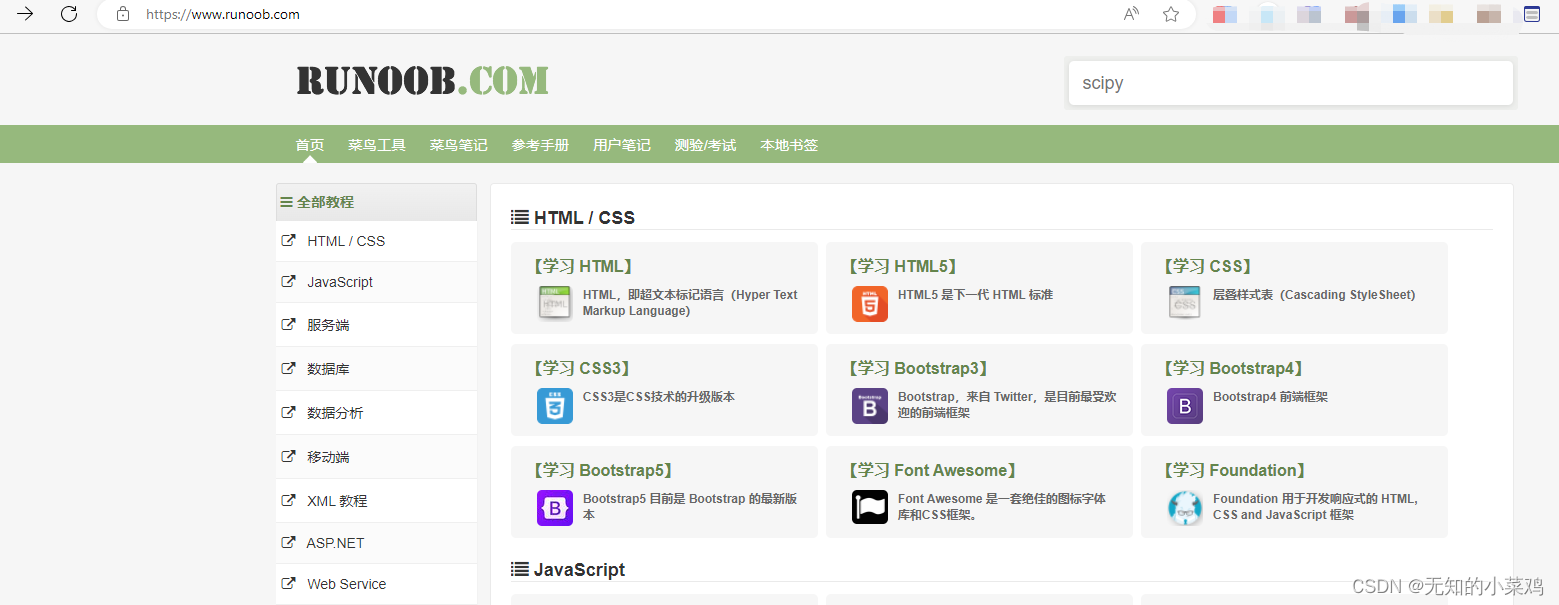
2、点击 学习HTML5这个标签,进入对应的页面

3、点击 HTML图像,进入对应的页面
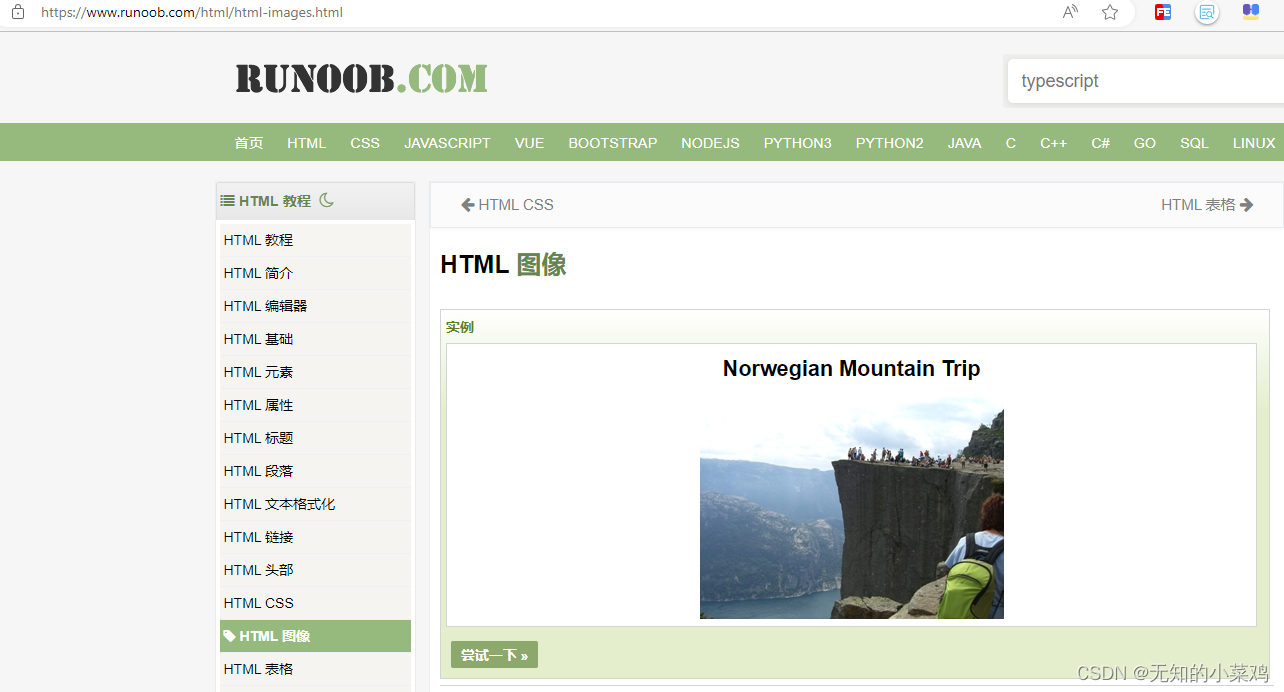
4、将这个图片下载到本地
代码
const puppeteer = require("puppeteer");// 初始化函数
const init = async () => {// 启动浏览器const browser = await puppeteer.launch({headless: false,});// 创建一个标签页const page = await browser.newPage();// 跳转到相应的网站await page.goto("https://www.runoob.com/");// 元素是动态生成的,需要等待元素完全加载await page.waitForSelector(".item-top.item-1");// 获取到 学习html5对应的标签const html5 = await page.$$(".item-top.item-1");// 返回值是CDPElementHandle { handle: CDPJSHandle {} },一个CDP元素句柄,指向浏览器中实际dom元素的引用// 需要使用 evaluate方法来获取对应的dom中的属性,比如元素的innerText属性是在浏览器环境中计算得出的,而不是直接在 Puppeteer 中可见的console.log("html5[1]:", html5[1]);// 点击该标签await html5[1].click();// 等待页面渲染出现a标签的元素await page.waitForSelector("a");// 获取HTML 图像并点击const htmlImg = await page.$('a[title="HTML 图像"]');console.log("htmlImg:", htmlImg);htmlImg.click();await page.waitForSelector(".example_result.notranslate img");// 获取到图片标签const img = await page.$(".example_result.notranslate img");const imageSrc = await img.evaluate((el) => el.src);console.log("图片地址:", imageSrc);// 图片截图await img.screenshot({ path: "example.png" });// 关闭浏览器await browser.close();
};init();
效果图
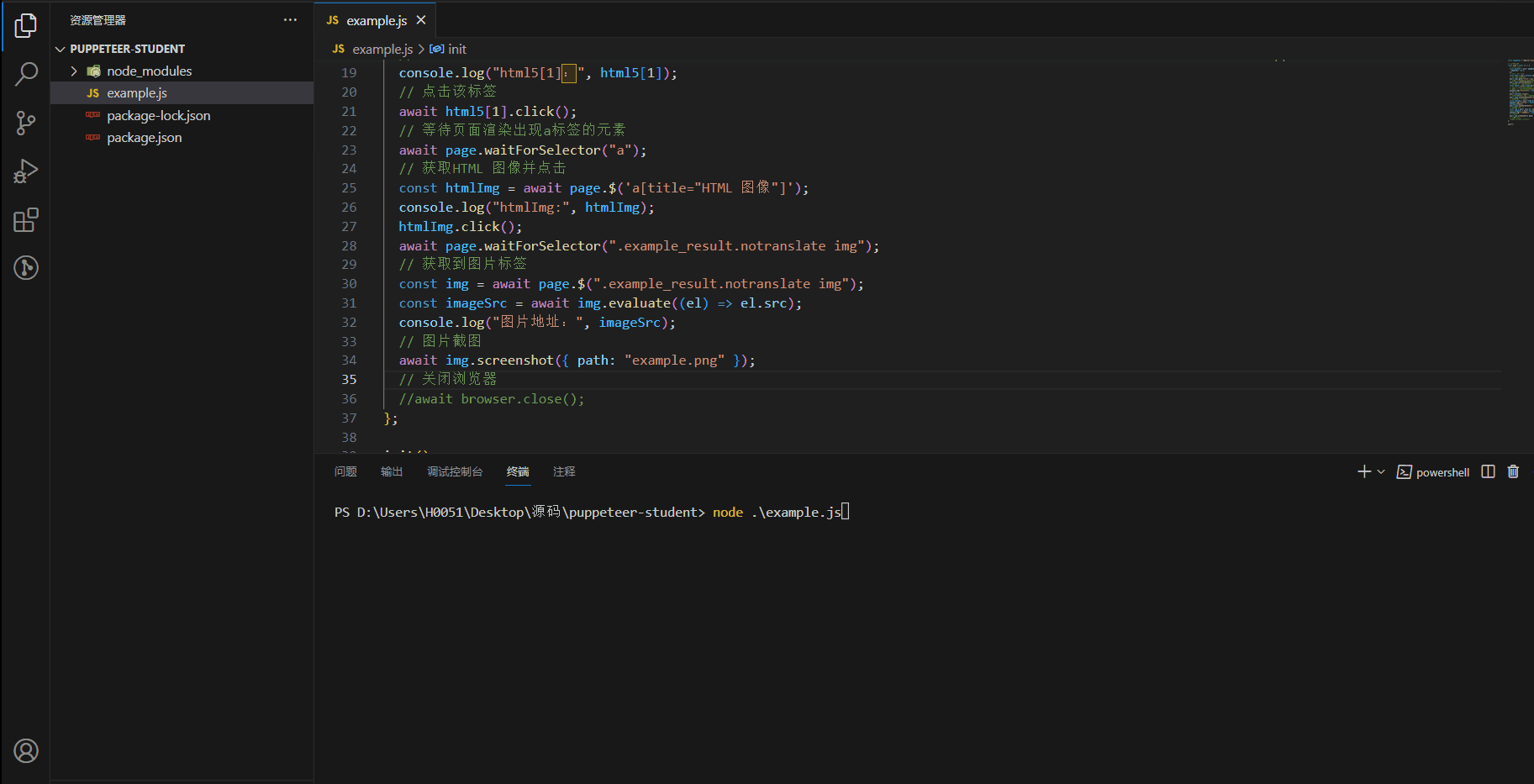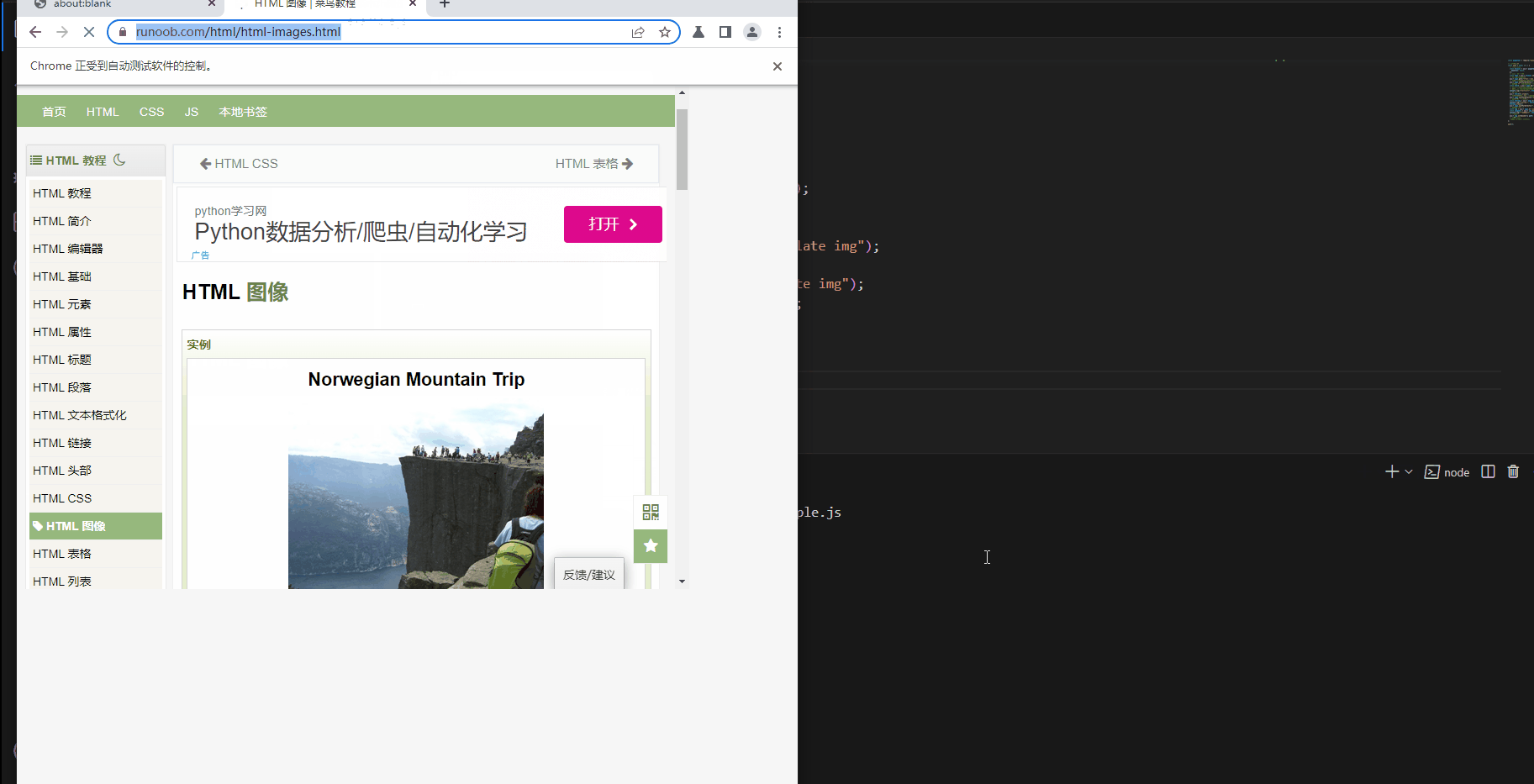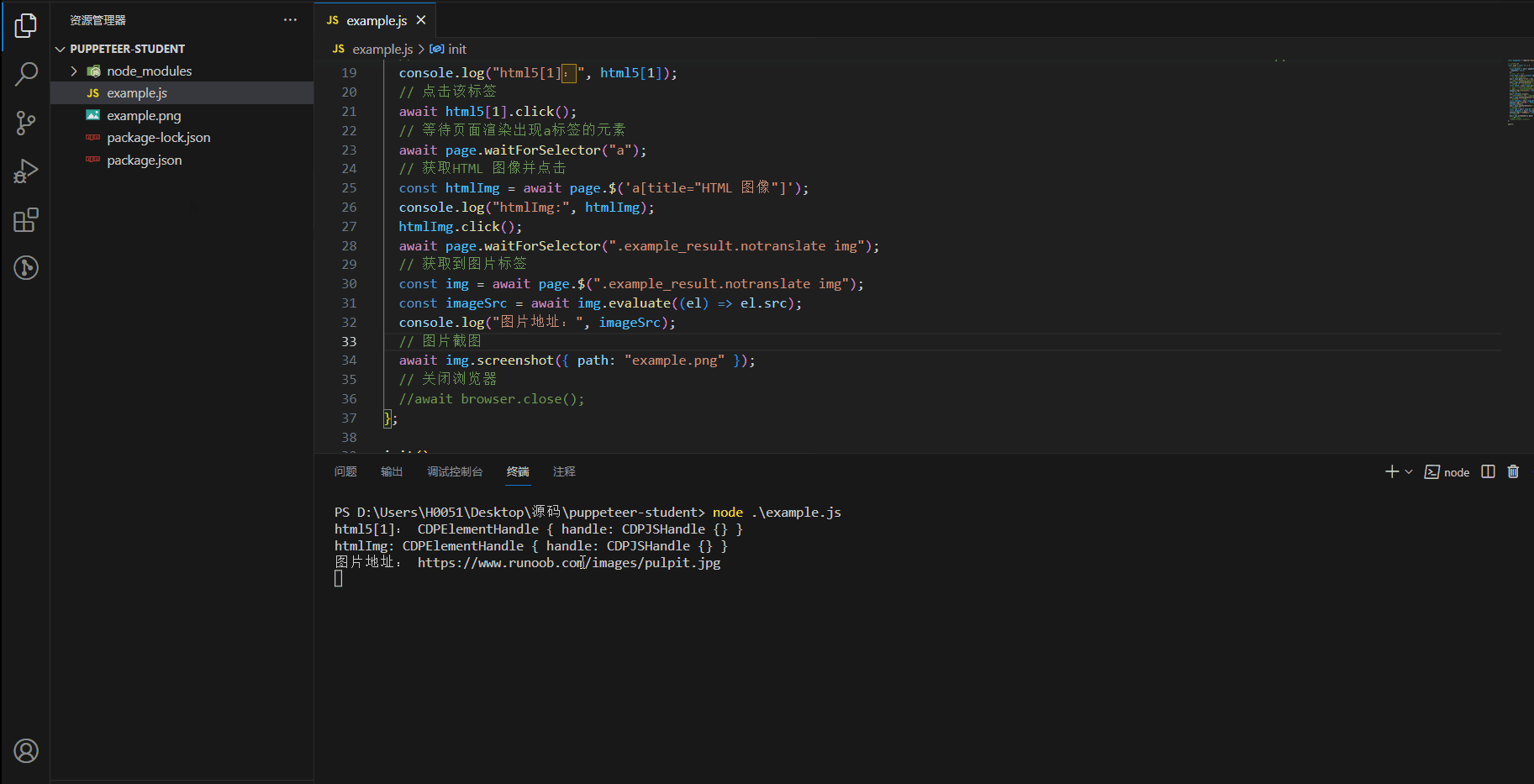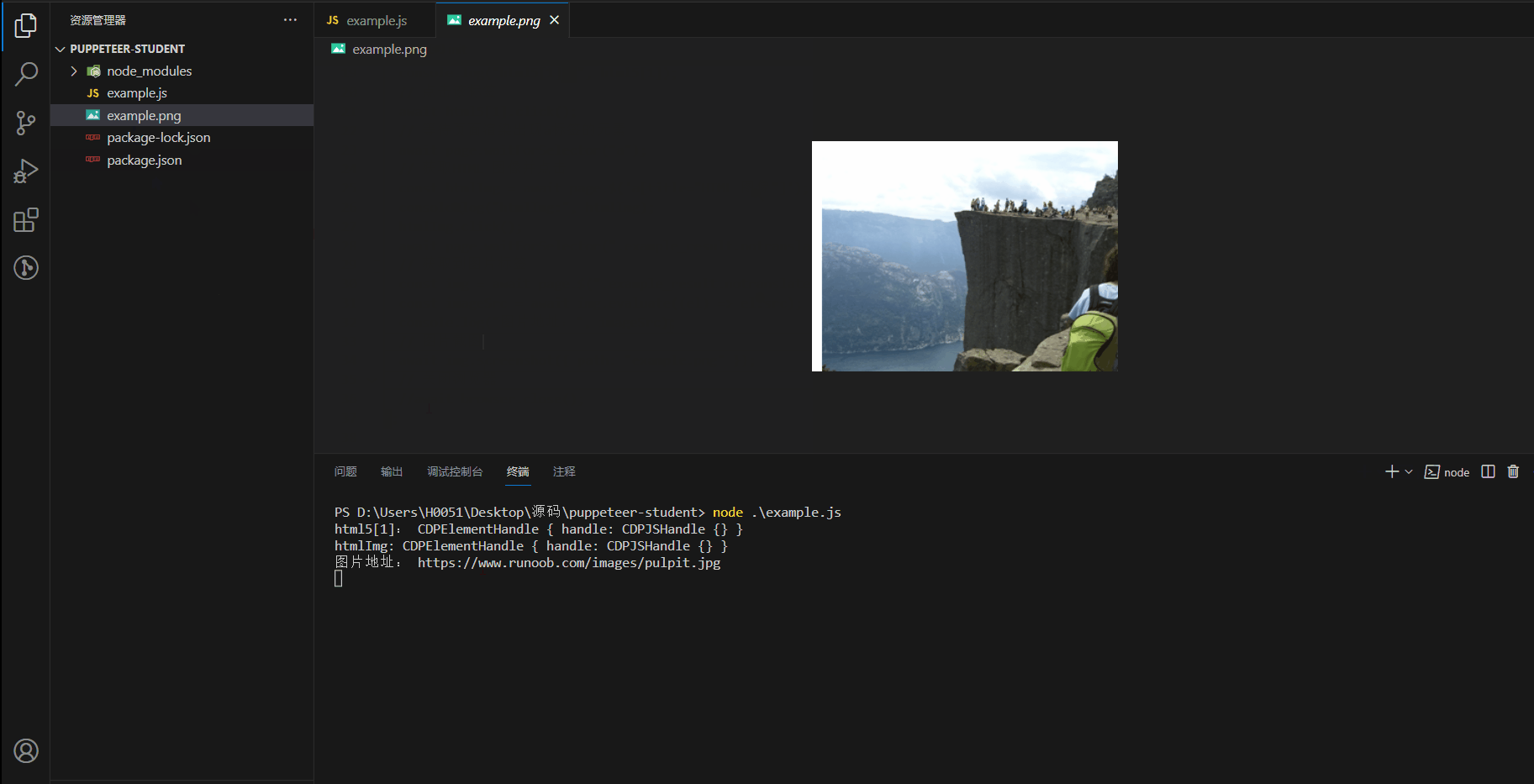
注意点:
- 为了方便开发,最好设置为
headless: false,另外不要关闭浏览器,这样方便查看具体效果,看一下是否有问题。当确认代码没问题后在设置为headless: true,并在最后关闭浏览器 page.$(".example_result.notranslate img")获取到的是一个CDPElementHandle { handle: CDPJSHandle {} }。这是一个CDP元素句柄,指向浏览器中实际dom元素的引用。你可以直接调用click等方法,但是无法直接获取到比如元素的innerText属性。查到的解释是元素的innerText属性是在浏览器环境中计算得出的,而不是直接在 Puppeteer 中可见的,可以通过evaluate方法来操纵上下文对象page.waitForSelector("a"),等待某个元素渲染出,因为是代码直接操作,可能会出现页面还没有渲染完成就开始执行下一步,导致代码报错img.evaluate((el) => el.src)执行上下文对象
利用谷歌插件编写Puppeteer脚本
什么,你不会写脚本?什么,你觉得写脚本麻烦?什么,可以让插件写脚本?
没错,你不会写脚本也没关系,可以使用谷歌插件让插件帮你写脚本。这里我们需要使用Headless Recorde
简介
Headless Recorder 是一个 Chrome 浏览器插件,它可以帮助你录制和回放你在浏览器中的操作。它的主要功能是将你在浏览器中的操作记录下来,并生成可重放的代码,以便你可以在任何时间重新执行这些操作。
Headless Recorder 是一个非常实用的工具,特别适用于自动化测试、网页演示和教学等场景。使用它可以快速生成可重放的代码,无需手动编写和调试脚本,节省了大量的开发和测试时间。
Headless Recorder 的工作原理是利用 Chrome 浏览器的 Headless 模式,它可以在后台运行浏览器并模拟用户的操作,包括点击、输入、滚动等等。通过插件的录制功能,你可以在浏览器中进行各种操作,同时插件会将这些操作记录下来,并生成对应的代码。
录制完成后,你可以将生成的代码导出为多种格式,如 JavaScript、Puppeteer、Playwright 等,以便在其他环境中运行和重放。这样你就可以在不同的环境中复现你在浏览器中的操作,而无需手动重复操作。
总之,Headless Recorder 是一个强大的工具,它可以帮助你快速记录和回放浏览器中的操作,提高开发效率和测试质量。无论是自动化测试还是网页演示,它都是一个非常有用的辅助工具。
官方地址
https://github.com/checkly/headless-recorder
基本操作
开启Headless Recorde插件后,Headless Recorde会录制你在浏览器中的操作,当结束录制后。会将你在浏览器中的操作转换为脚本,比如:
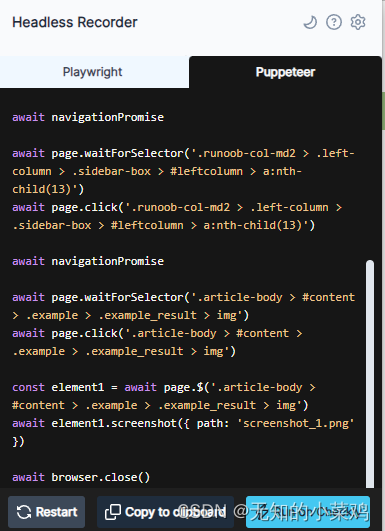
下面是生成的代码(需要稍微修改一下)
const init = async () => {const puppeteer = require("puppeteer");const browser = await puppeteer.launch();const page = await browser.newPage();const navigationPromise = page.waitForNavigation();await page.goto("https://www.runoob.com/");await page.setViewport({ width: 1920, height: 969 });await page.waitForSelector(".row > .col > .cate1 > .item-top:nth-child(3) > h4");await page.click(".row > .col > .cate1 > .item-top:nth-child(3) > h4");await navigationPromise;await page.waitForSelector(".runoob-col-md2 > .left-column > .sidebar-box > #leftcolumn > a:nth-child(13)");await page.click(".runoob-col-md2 > .left-column > .sidebar-box > #leftcolumn > a:nth-child(13)");await navigationPromise;await page.waitForSelector(".article-body > #content > .example > .example_result > img");await page.click(".article-body > #content > .example > .example_result > img");const element1 = await page.$(".article-body > #content > .example > .example_result > img");await element1.screenshot({ path: "screenshot_1.png" });await browser.close();
};init();
一对比,比自己写的脚本不知道牛逼了多少倍。
下载
下载谷歌商店里好像下架了该插件,你可以直接百度搜索,当然也可以下载我下载好了的插件,插件已经上传的百度云盘
链接:https://pan.baidu.com/s/1k8fvl-CemYOMUedsZmjBnQ
提取码:1234