引言
今天带来微调LLM的第二篇论文笔记Prefix-Tuning。
作者提出了用于自然语言生成任务的prefix-tuning(前缀微调)的方法,固定语言模型的参数而优化一些连续的任务相关的向量,称为prefix。受到了语言模型提示词的启发,允许后续的token序列注意到这些prefix,当成虚拟token。
只需要修改0.1%的参数量,在全量数据设定下,前缀微调能获得较好的效果;而在少数据设定下,它的表示甚至超过了全量微调,并且泛化能力更好。
总体介绍
全量微调需要保存原始模型的完全参数拷贝,这是非常耗费资源的。一种解决这个问题的自然选择是轻量微调(lightweight fine-tuning),固定住大多数参数仅调整少部分。比如我们上次介绍的Adapter微调通过插入任务相关的额外层,在自然语言理解和生成任务上获得了不错的表现。
GPT-3通过上下文学习(in-context learning),一种提示词的形式,不需要调整任何LM的参数。比如针对摘要任务的TL;DR,以及添加少部分样本到输入中,然后LM生成任务相关的输出。然而这种方法受限于输入的长度,上下文学习只能限定少量的训练样本。
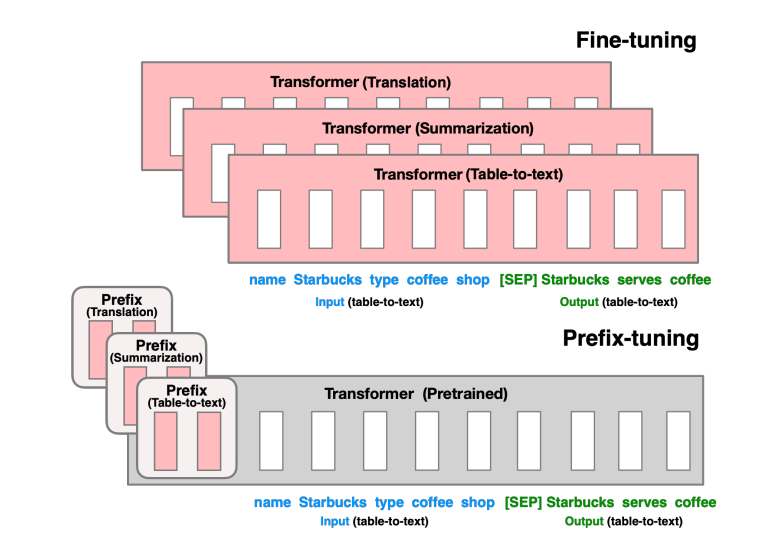
考虑生成一个关于表格数据描述内容的任务,如图1所示。输入是一个线性的表格,比如name: Starbucks | type: coffee s