书接上回Java核心知识点整理大全4-笔记_希斯奎的博客-CSDN博客
目录
3.4.1. HashMap(数组+链表+红黑树)
3.4.1.1. JAVA7 实现
3.4.1.2. JAVA8 实现
3.4.2. ConcurrentHashMap
3.4.2.1. Segment 段
3.4.2.2. 线程安全(Segment 继承 ReentrantLock 加锁)
3.4.2.3. 并行度(默认 16)
3.4.2.4. Java8 实现 (引入了红黑树)
3.4.3. HashTable(线程安全)
3.4.4. TreeMap(可排序)
3.4.5. LinkHashMap(记录插入顺序)
4.1.2. JAVA 线程实现/创建方式
4.1.2.1. 继承 Thread 类
4.1.2.2. 实现 Runnable 接口。
4.1.2.3. ExecutorService、Callable、Future 有返回值线程
4.1.2.4. 基于线程池的方式
4.1.3. 4 种线程池
4.1.3.1. newCachedThreadPool
4.1.3.2. newFixedThreadPool
4.1.3.3. newScheduledThreadPool
4.1.3.4. newSingleThreadExecutor

3.4.1. HashMap(数组+链表+红黑树)
HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快 的访问速度,但遍历顺序却是不确定的。 HashMap 最多只允许一条记录的键为 null,允许多条记 录的值为 null。HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导 致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。我们用下面这张图来介绍 HashMap 的结构
3.4.1.1. JAVA7 实现
大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色 的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
1. capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
2. loadFactor:负载因子,默认为 0.75。
3. threshold:扩容的阈值,等于 capacity * loadFactor
3.4.1.2. JAVA8 实现
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑 树 组成。 根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的 具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决 于链表的长度,为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后, 会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)
3.4.2. ConcurrentHashMap
3.4.2.1. Segment 段
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一 些。整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的 意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个 segment。
3.4.2.2. 线程安全(Segment 继承 ReentrantLock 加锁)
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每 个 Segment 是线程安全的,也就实现了全局的线程安全。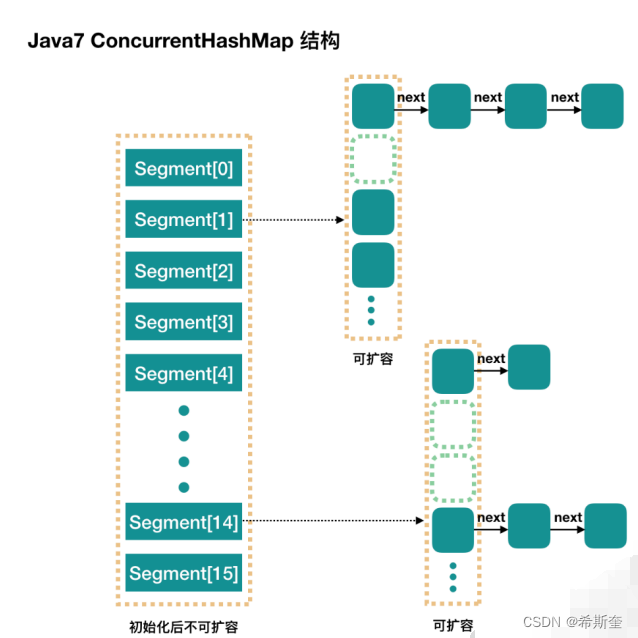
3.4.2.3. 并行度(默认 16)
concurrencyLevel:并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16, 也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支 持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时 候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实 每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
3.4.2.4. Java8 实现 (引入了红黑树)
Java8 对 ConcurrentHashMap 进行了比较大的改动,Java8 也引入了红黑树

3.4.3. HashTable(线程安全)
Hashtable 是遗留类,很多映射的常用功能与 HashMap 类似,不同的是它承自 Dictionary 类, 并且是线程安全的,任一时间只有一个线程能写 Hashtable,并发性不如 ConcurrentHashMap, 因为 ConcurrentHashMap 引入了分段锁。Hashtable 不建议在新代码中使用,不需要线程安全 的场合可以用 HashMap 替换,需要线程安全的场合可以用 ConcurrentHashMap 替换。
3.4.4. TreeMap(可排序)
TreeMap 实现 SortedMap 接口,能够把它保存的记录根据键排序,默认是按键值的升序排序, 也可以指定排序的比较器,当用 Iterator 遍历 TreeMap 时,得到的记录是排过序的。 如果使用排序的映射,建议使用 TreeMap。 在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的 Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常
参考:https://www.ibm.com/developerworks/cn/java/j-lo-tree/index.html
3.4.5. LinkHashMap(记录插入顺序)
LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序,在用 Iterator 遍历 LinkedHashMap 时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序
4. JAVA 多线程并发
4.1.2. JAVA 线程实现/创建方式
4.1.2.1. 继承 Thread 类
Thread 类本质上是实现了 Runnable 接口的一个实例,代表一个线程的实例。启动线程的唯一方 法就是通过 Thread 类的 start()实例方法。start()方法是一个 native 方法,它将启动一个新线 程,并执行 run()方法。
public class MyThread extends Thread {
public void run() {
System.out.println("MyThread.run()");
}
}
MyThread myThread1 = new MyThread();
myThread1.start();
4.1.2.2. 实现 Runnable 接口。
如果自己的类已经 extends 另一个类,就无法直接 extends Thread,此时,可以实现一个 Runnable 接口。
public class MyThread extends OtherClass implements Runnable {
public void run() {
System.out.println("MyThread.run()");
}
}
//启动 MyThread,需要首先实例化一个 Thread,并传入自己的 MyThread 实例:
MyThread myThread = new MyThread();
Thread thread = new Thread(myThread);
thread.start();
//事实上,当传入一个 Runnable target 参数给 Thread 后,Thread 的 run()方法就会调用 target.run()
public void run() {
if (target != null) {
target.run();
}
}
4.1.2.3. ExecutorService、Callable、Future 有返回值线程
返回值的任务必须实现 Callable 接口,类似的,无返回值的任务必须 Runnable 接口。执行 Callable 任务后,可以获取一个 Future 的对象,在该对象上调用 get 就可以获取到 Callable 任务 返回的 Object 了,再结合线程池接口 ExecutorService 就可以实现传说中有返回结果的多线程 了。
//创建一个线程池
ExecutorService pool = Executors.newFixedThreadPool(taskSize);
// 创建多个有返回值的任务
List list = new ArrayList();
for (int i = 0; i < taskSize; i++) {
Callable c = new MyCallable(i + " ");
// 执行任务并获取 Future 对象
Future f = pool.submit(c);
list.add(f); }
// 关闭线程池
pool.shutdown();
// 获取所有并发任务的运行结果
for (Future f : list) {
// 从 Future 对象上获取任务的返回值,并输出到控制台
System.out.println("res:" + f.get().toString());
}
4.1.2.4. 基于线程池的方式
线程和数据库连接这些资源都是非常宝贵的资源。那么每次需要的时候创建,不需要的时候销 毁,是非常浪费资源的。那么我们就可以使用缓存的策略,也就是使用线程池。
// 创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
while(true) {
threadPool.execute(new Runnable() { // 提交多个线程任务,并执行
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " is running ..");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
4.1.3. 4 种线程池
Java 里面线程池的顶级接口是 Executor,但是严格意义上讲 Executor 并不是一个线程池,而 只是一个执行线程的工具。真正的线程池接口是 ExecutorService。、
4.1.3.1. newCachedThreadPool
创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们。对于执行 很多短期异步任务的程序而言,这些线程池通常可提高程序性能。调用 execute 将重用以前构造 的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。终止并 从缓存中移除那些已有 60 秒钟未被使用的线程。因此,长时间保持空闲的线程池不会使用任何资、资源。
4.1.3.2. newFixedThreadPool
创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。在任意点,在大 多数 nThreads 线程会处于处理任务的活动状态。如果在所有线程处于活动状态时提交附加任务, 则在有可用线程之前,附加任务将在队列中等待。如果在关闭前的执行期间由于失败而导致任何 线程终止,那么一个新线程将代替它执行后续的任务(如果需要)。在某个线程被显式地关闭之 前,池中的线程将一直存在。
4.1.3.3. newScheduledThreadPool
创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
ScheduledExecutorService scheduledThreadPool=Executors.newScheduledThreadPool(3);
scheduledThreadPool.schedule(newRunnable(){
@Override
public void run() {
System.out.println("延迟三秒");
}
}, 3, TimeUnit.SECONDS);
scheduledThreadPool.scheduleAtFixedRate(newRunnable(){
@Override
public void run() { System.out.println("延迟 1 秒后每三秒执行一次");
}
},1,3,TimeUnit.SECONDS);
4.1.3.4. newSingleThreadExecutor
Executors.newSingleThreadExecutor()返回一个线程池(这个线程池只有一个线程),这个线程 池可以在线程死后(或发生异常时)重新启动一个线程来替代原来的线程继续执行下去!