Callable
这是一个接口,类似于Runnable。
Runnable用来描述一个任务,描述的任务没有返回值。
Callable也是用来描述一个任务,描述的任务是有返回值的。
如果需要使用一个线程单独的计算出某个结果来,此时用Callable是比较合适的。
 在new一个Callable之后,需要重写一个方法。就相当于是重写Runnable的Run方法,run方法的返回值是void,这里的call方法返回值是泛型参数。
在new一个Callable之后,需要重写一个方法。就相当于是重写Runnable的Run方法,run方法的返回值是void,这里的call方法返回值是泛型参数。

我们需要FutureTask的帮助:

这个FutureTask就相当于一个未来的任务,类似于我们吃麻辣烫时,给我们叫号牌。等到麻辣烫做好后,会通过叫号牌来叫我们。
Future表示一个任务的周期,并提供了相应的方法来判断是否已经完成或者取消,以及获取任务的结果和取消任务。
FutureTask实现了RunnableFuture接口,RunnableFuture接口又实现了Runnable接口和Future接口。所以FutureTask既可以被当做Runnable来执行,也可以被当做Future来获取Callable的返回结果。

和Runnable相比,Callable也是创建线程的一个方式,callable解决的是代码好不好看的问题,而不是结果对不对的问题。runnable也能得出结果,但是代码看起来比较乱。
ReentrantLock
这是标准库给我们提供的另一种锁,也是可重入锁。
synchronized是直接基于代码块的方式来加锁解锁的。
ReentrantLock更传统,使用了lock和unlock方法来加锁。

乍一看可能没什么问题,但是这样子加锁解锁可能会导致unlock执行不到。
那如果是lock后多用几个条件限制呢?
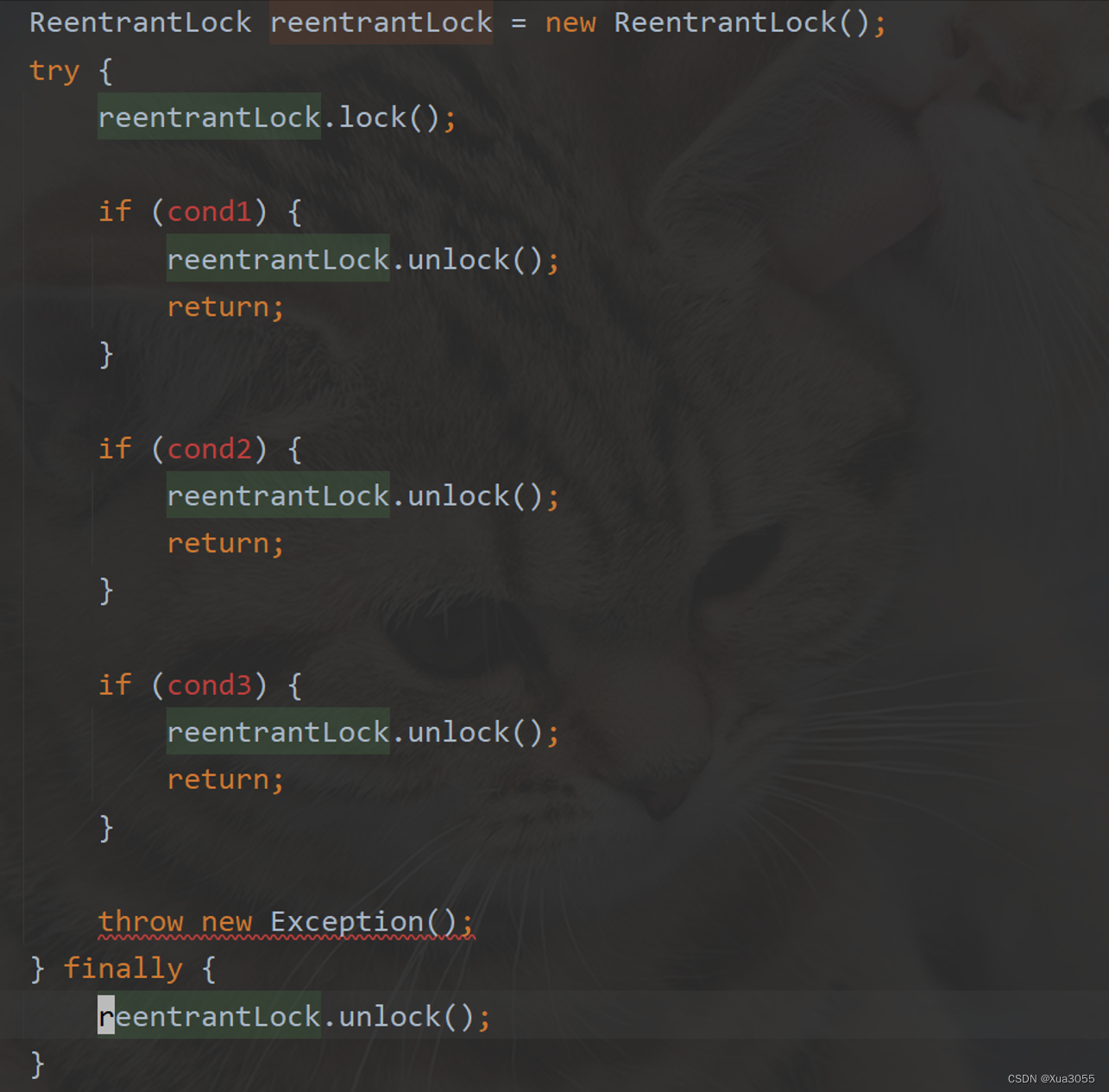
如果这中间存在return或者异常都可能导致unlock不能顺利执行~
建议的用法:
把unlock放到finally中。
try 关键字最后可以定义 finally 代码块。 finally 块中定义的代码,总是在 try 和任何 catch 块之后、方法完成之前运行。
正常情况下,不管是否抛出或捕获异常 finally 块都会执行。

这样就能保证unlock一定会执行。
上面的是ReentrantLock的劣势,但是也是有优势的:
1.ReentrantLock提供了公平锁版本的实现
ReentrantLock reentrantLock = new ReentrantLock(true);2.对于synchronized来说,提供的加锁操作就是死等,只要获取不到锁,就一直一直阻塞等待~
ReentrantLock提供了更灵活的等待方式:tryLock
reentrantLock.tryLock();无参数版本,能加锁就加,加不上就放弃。
有参数版本,指定了超时时间,加不上锁就等一会,如果等一会时间到了也没加上就放弃等待。
3.ReentrantLock提供了一个更强大,更方便的等待通知机制。
synchronized搭配的是 wait notify。notify的时候是随机唤醒一个wait的线程。ReentrantLock搭配一个Condition类,进行唤醒的时候可以唤醒指定的线程。
总结:虽然ReentrantLock有一定的优势,但是实际开发中,大部分情况下还是用的synchronized。
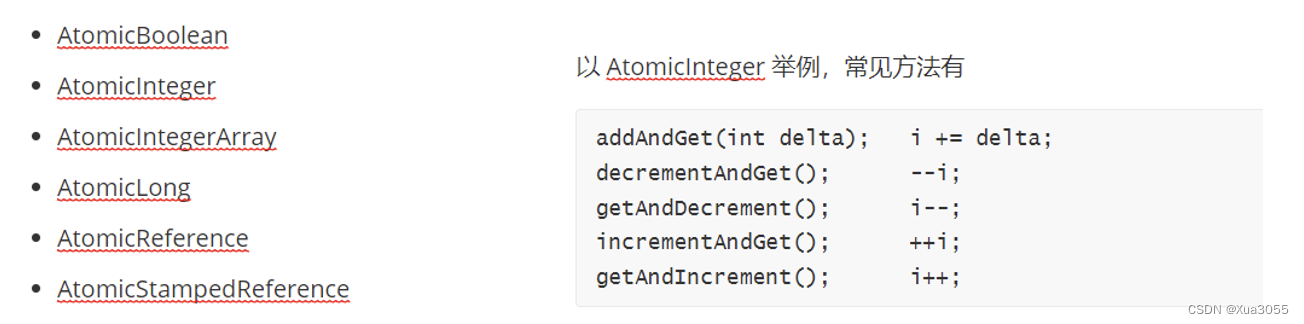
原子类
原子类内部用的是CAS,所以性能要比加锁实现i++要高很多
虽然CAS确实是更加高效的解决了线程安全问题,但是CAS不能代替锁,CAS的适用范围是有限的,不像锁的适用范围那么广。
信号量 Semaphore
这里的信号量和操作系统上的信号量是同一个东西,只不过这里的信号量是Java把操作系统原生的信号量封装了一下。
信号量这个东西在我们生活中经常可以见到:
信号量就是这个计数器,描述了“可用资源的个数”
P操作:申请一个可用资源,计数器就要-1
V操作:释放一个可用资源,计数器就要+1
P操作如果要是计数器为0,继续P操作,就会出现阻塞操作。直到下一个V操作以后才能继续进行P操作。

实际开发中,虽然锁是最常用的,但是信号量也是会偶尔用到的,主要还是看实际的需求场景。
CountDownLatch
有一场跑步比赛,开始时间是明确的(裁判的发令枪),但是结束时间是不明确的(所有的选手都冲过终点线),为了等待这个跑步比赛结束,就引入了这个CountDownLatch。
有两个方法:
1.await(wait是等待,a =>all)主线程来调用这个方法
2.countDown表示选手冲过了终点线
例如,有四个选手进行比赛,初始情况下,调用await就会阻塞,就代表进入了比赛时间,每个选手冲过终点的时候,都会调用countDown方法。
前三次countDown,await没有任何影响,第四次调用countDown,await就会被唤醒,返回(解除阻塞),此时就可以认为是整个比赛都结束了。
多线程环境下使用ArrayList
1.自己加锁,使用synchronized或者ReentrantLock
2.Collections.synchronizedList 这里面会提供一些ArrayList相关的方法,同时是带锁的。
3.CopyOnWriteArrayList,简称为COW,也叫做写时拷贝。
针对这个ArrayList进行读操作,不做任何额外的工作;
如果进行写操作,则拷贝一份新的ArrayList,针对新的进行修改。修改的过程中如果有读的操作,那么就继续读旧的这一份数据。当修改完毕了,使用新的替换旧的。
这种方案优点:不需要加锁
缺点:要求这个ArrayList不能太大,只是适用于数组比较小的情况下
多线程使用哈希表[重点、难点]
HashMap是线程不安全的,HashTable是线程安全的(因为给关键方案加了synchronized)
但是更推荐使用的是ConcurrentHashMap,这是更加优化的线程安全哈希表。
在这有几个重点:
1.ConcurrentHashMap进行了哪些优化?
2.比HashTable好在哪里?
3.和HashTable之间的区别是什么?
最大的优化之处:ConcurrentHashMap相比于HashTable大大缩小了锁冲突的概率,把一把大锁,转换成多把小锁了。

HashTable会在整个链表上加锁。

ConcurrentHashMap的做法是,每个链表有各自的锁,而不是共用一个锁
具体来说,就是用每个链表的头结点,作为锁对象。这样两个线程不针对同一个对象加锁,就不会有锁竞争。

JDK1.7和之前

但是呢,ConcurrentHashMap做了一个激进的操作:
针对读操作不加锁,只针对锁操作加锁。

并且,ConcurrentHashMap内部充分利用了CAS,通过这个来进一步削减加锁操作的数目。
针对扩容,采取“化整为零”的方式
HashMap/HashTable扩容:
创建一个更大的数组空间,把旧的数组上的链表上的每个元素搬运到新的数组上(删除+插入)
这个扩容操作会在某次put的时候进行触发,如果元素个数特别多,就会导致这样的搬运操作比较耗时。(比如某次put的时候,某个用户就卡了)
ConcurrentHashMap扩容:
每次搬运一小部分元素,创建新的数组,旧的数组也保留。每次put操作,都往新数组上添加,同时进行一部分搬运(把一小部分旧的元素搬运到新数组上)
每次get的时候,把新旧数组都查询,remove的时候,把旧数组的元素删了就行了
经过一段时间之后,所有的元素都搬运好了,再释放旧数组。