原文链接:
https://aclanthology.org/2023.findings-acl.672.pdf
ACL 2023
介绍
问题
作者认为,一个好的span表征对于NER任务是非常重要的,而之前的工作都是将第一个或最后一个的表征简单的进行组合后,没有进行充分的交互就送入到实体分类器中进行分类,不利于长实体的识别,并且对于嵌套实体中共享token的情况下,会导致产生的span是相似的。
IDEA
作者提出了DSpERT模型,该模型包括了一个transformer和一个span transformer(用于span 表征和token表征之间的交互),来获取span的深层表征。
方法
整体的结构如下图所示:

Deep Token Representations
第l层的token表征为:

最初的由token embedding、positional embedding和segmentation embedding组成。
TrBlock由一个多头注意力模块和一个position-wise前馈网络(FFN)组成,并在其中加入了残差连接和层归一化。经过L层计算得到的token表征被认为是包含了深层且丰富的语义,可用于各种任务,因此在典型的NLP范式中,只对顶层的
计算损失和解码。
Deep Span Representations
在大小为k的span transformer中,使用对应的token embedding进行初始化,

覆盖了(i,i+k)这个span中的token embedding。
span表征高层的计算与标准的transformer相似,对于每个span transformer block,query是低层的span 表征,k和value是上述span的position向量。第l层的span表征表示为:

将最后一层的span 表征用于实体分类。另外,这里的SpanTrBlock与token中的TrBlock的结构一致,并且初始化参数也是一致的。作者尝试将这两个模块共享同一个transformer,但这样会导致模型性能下降。
Entity Classifier
在进行解码前,先对span进行了降维,整个分类过程如下所示:
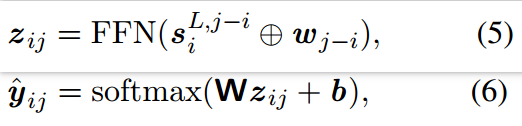
使用one-hot对ground truth标签进行编码,计算每个span的loss:

实验
对比实验
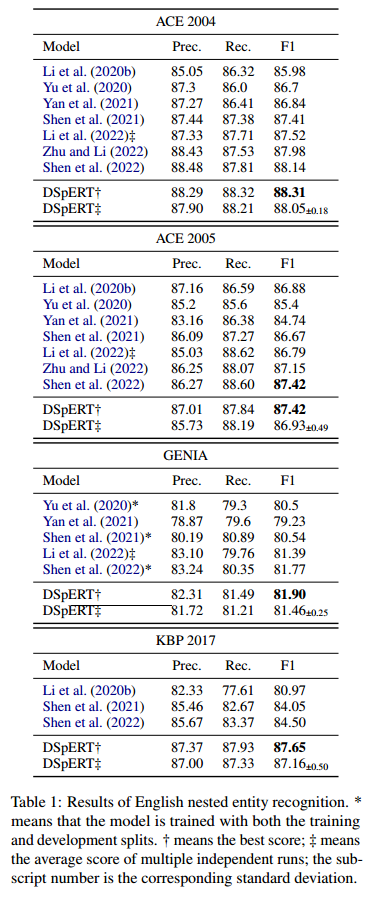
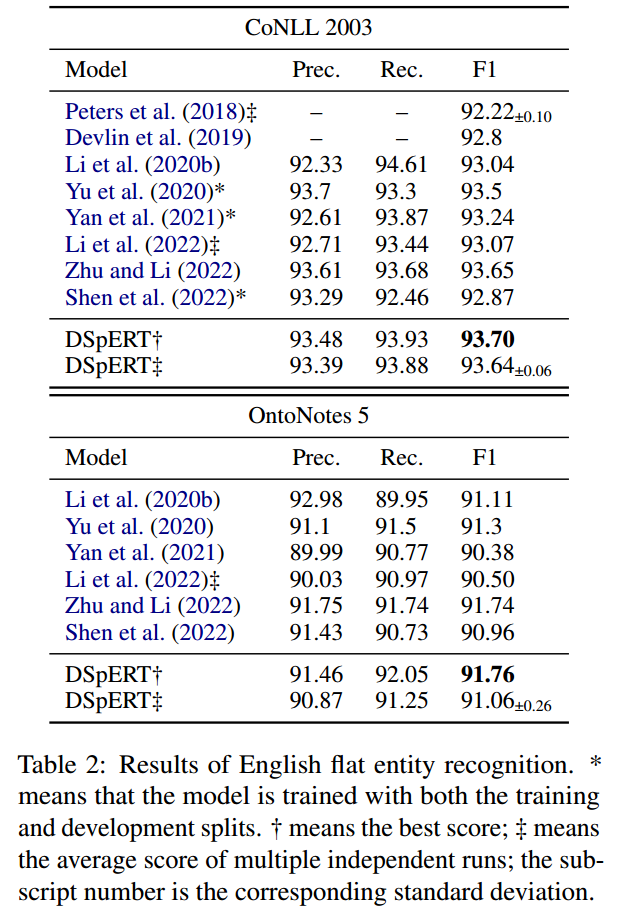
在多个英文嵌套实体数据集上进行实验,结果如下所示:
在falt数据集上进行实验,结果如下所示:
消融实验
作者对span representation的深度进行了消融实验,结果如下所示:

为了更好的严重模型在嵌套实体上的表现,作者将nest ner分为两类:
1)被嵌套在其他真实实体中;
2)覆盖在其他真实实体中;
比如“New York University”,作者认为一个好的模型要能够做到:1)将“New York”与外部实体“New York University”内的其他span区分开来;2)将“New York University”与涵盖的内部实体“new York”的其他span区分开。
对模型在不同长度span上的表现进行了实验,如下所示:

可以看出在长实体上,作者提出的模型明显优于简单的span 表征。
在不同嵌套结构下的实验结果:

分析
对于神经网络中的分类模型,logits只和预定的分类类别有关,而pre-logit(我理解为在算分数前的表征)表征包含了更丰富的信息。作者通过研究pre-logit span表征,来探究为什么深度的span 表征会比简单表征更好的。
通过计算实体共享的token个数来表示两个实体之间的重叠率,计算实体与其邻居实体之间的余弦相似度。
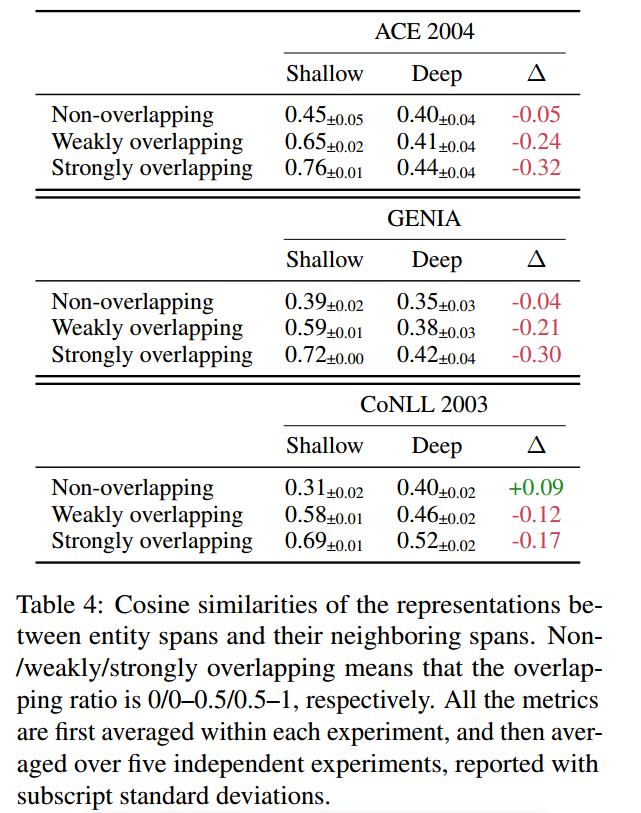
可以看出,DSpERT与简单模型在非嵌套上的表现相近,然而对于嵌套率越高的实体,简单模型生成的表征要比DSpERT相似度更高,即简单模型会产生跨度重叠的表示,而DSpERT生成的表征之间相似率更低,在嵌套实体上产生更好的性能。
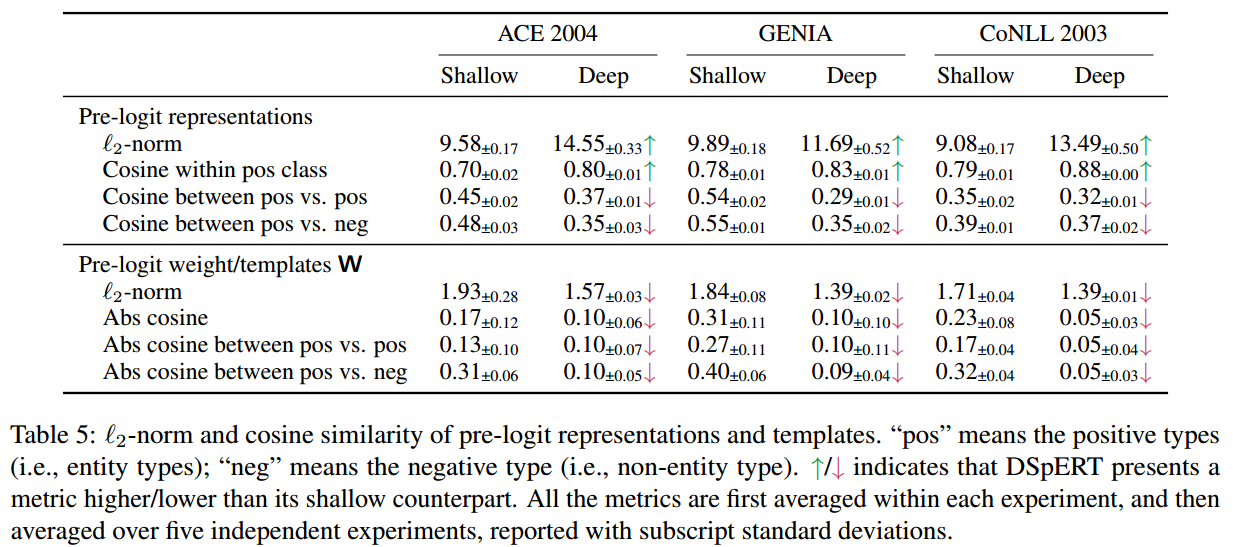
计算了不同类别(positive和negative)之间的L2范式和余弦相似度,可以看出深度表征在类别之间具有较低的相似度、在类别内具有较高的相似度。
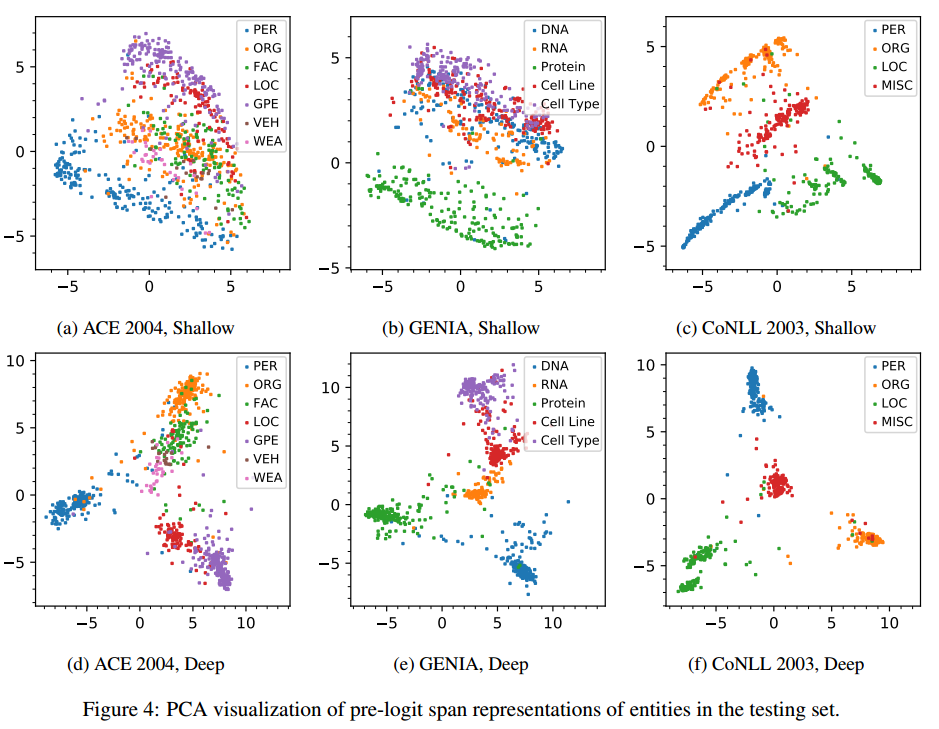
对span的表征进行PCA降维进行可视化,也可以看出作者提出的deep 表征在别类之间有更明显的界限,各个类别联系也更加紧密。
总结
作者认为在span NER中,最小的建模单元应该是span而不是token,并且作者探讨了该模型的局限性,时间开销很大,是普通模型的5倍。因此可以看作该模型是用了时间来换取了精度,并且只是对表征进行了处理,其他地方都没有什么创新点,12层的transf,这是往死里丰富span啊,,