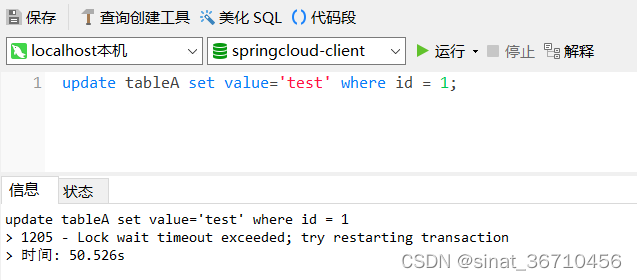
ASCII 码只需要 7 bit 就能完整地表示,但只能表示英文字母在内的 128 个字符,为了表示世界上大部分的文字系统,发明了 Unicode ,它是 ASCII 的超集,包含世界上书写系统中存在的所有字符,并且为每个代码分配一个标准编号(称为 Unicode CodePoint),在 go 语言中称为 rune,是 int32 的别名。
go 语言中 ,字符串的底层表示是 byte(8 bit) 序列,而不是 rune( 32 bit )序列。
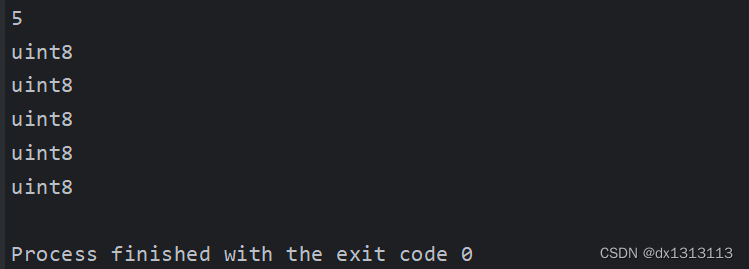
func main() {str := "nihao"length := len(str)fmt.Println(length)for i, _ := range str {fmt.Println(reflect.TypeOf(str[i]))}
}
运行结果为:
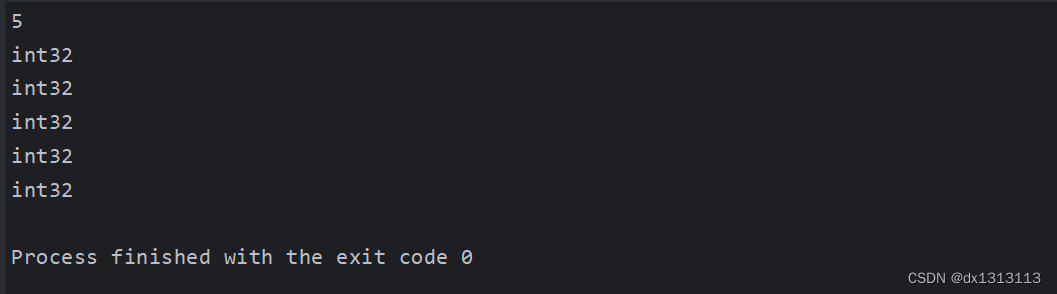
但是,如果使用 for range 遍历字符串取值的时候,得到的 value 类型为 rune 类型(3字符),也就是 int32 类型,对应 Unicode 字符型。
func main() {str := "nihao"length := len(str)fmt.Println(length)for _, v := range str {fmt.Println(reflect.TypeOf(v))}
}
运行结果:
修改字符串
所以在go语言中修改字符串的时候,针对不同的情况来进行编写:
当字符串中有中文字符:
此时需要将字符串转换为 []rune 切片进行操作
func main() {str := "你好"fmt.Printf("修改前:%s", str)fmt.Println()strr := []rune(str)strr[0] = '我'fmt.Printf("修改后:%s", string(strr))
}
结果:

如果使用 []byte 的话编译会不通过
当字符串中只有英文时:
此时使用 []rune 或者 []byte 都可以,但是一般会使用 []byte:
func main() {str := "nihao"fmt.Printf("修改前:%s", str)fmt.Println()strr := []rune(str)strr[0] = 'w'fmt.Printf("[]rune修改后:%s", string(strr))fmt.Println()strrr := []byte(str)strrr[0] = 'w'fmt.Printf("[]byte修改后:%s", string(strr))fmt.Println()
}运行结果: